

Redis 入门
-
选择
我们通常使用 Redis 做缓存,原因在于它的高性能、高可靠、高可扩展。
高性能:
Redis 是基于内存的,所以很快。
Redis 使用的是基于多路复用的高性能 I/O 模型,此机制(select/epoll 机制)允许单线程处理多个 IO 流,即允许内核中,同时存在多个监听套接字和已连接套接字。内核会一直监听这些套接字上的连接请求或数据请求。一旦有请求到达,就会交给 Redis 线程处理,这就实现了一个 Redis 线程处理多个 IO 流的效果。当有多个客户端请求时,会产生多个套接字,此时 Redis 线程不会阻塞在某一个特定的监听或已连接套接字上,从而 Redis 可以同时和多个客户端连接并且处理请求,提升并发性能。当监测到套接字上有请求到达时,就会触发相应的事件(如 AcceptEvent 连接请求事件、ReadEvent 读数据请求事件、WriteEvent 写数据请求事件)。这些事件会被放到一个事件队列,Redis 单线程对该事件队列不断进行处理,处理的时候,会调用相应的处理函数,这就实现了基于事件的回调。因为 Redis 一直在对事件队列进行处理,所以能及时响应客户端请求,提升 Redis 的响应性能。Redis 6.0 之后,官方推出了多线程处理网络请求(在此之前,Redis 网络请求都是单线程)。
I/O 多路复用延伸阅读:https://draveness.me/redis-io-multiplexing/
Redis 采用全局哈希表,查找键值对的时间复杂度是 O(1),部分常用的数据结构如 String、Hash 和 Set,复杂度也基本由哈希表决定。高效的数据结构保证了 Redis 的高性能。
此外,Redis 还有 RDB、AOF、RDB/AOF 三种持久化方式,使得宕机后大多数数据不丢失,重启后能快速恢复到内存。这里简单说一下这三种持久方式:
RDB 是内存快照,在一定的频率内,将此时刻内存中的数据写到磁盘上。如果发生宕机,则能直接快速把 RDB 文件读入内存恢复数据。Redis 提供了两个命令来生成 RDB 文件,分别是 save 和 bgsave。save 在主线程中执行,会导致阻塞。bgsave 创建一个子进程,专门用于写入 RDB 文件,避免主线程的阻塞,也是 Redis RDB 文件生成的默认配置。bgsave 子进程是由主线程 fork 生成的,可以共享主线程的所有内存数据。bgsave 子进程运行后,开始读取主线程的内存数据,并把它们写入 RDB 文件。此时,如果如果主线程对这些数据也都是读操作,那么主线程和 bgsave 子进程互相不影响。但是,如果主线程要修改一块数据,那么,这块数据就会被复制一份,生成该数据的副本。然后,bgsave 子进程会把这个副本数据写入 RDB 文件,而在这个过程中,主线程仍然可以直接修改原来的数据。这里用到了操作系统提供的写时复制技术(Copy-On-Write, COW)。这既保证了快照的完整性,也允许主线程同时对数据进行修改,避免了对正常业务的影响。
AOF 是写后日志,Redis 先执行命令,然后才记录日志。这样做的好处是不会阻塞当前的写操作,避免了额外的检查开销,凡是写到日志里面的,都是正确的命令。坏处是存在数据丢失的风险,比如刚执行完一个命令,还没有来得及写日志就宕机了,那么这数据就永久丢失了。其次,AOF 虽然避免了对当前命令的阻塞,但可能会给下一个操作带来阻塞风险。这是因为,AOF 日志也是在主线程中执行的,如果在把日志文件写入磁盘时,磁盘写压力大,就会导致写盘很慢,进而导致后续的操作也无法执行了。日志写回磁盘有三种策略,由 AOF 配置项 appendfsync 的三个可选值决定。
- Always,同步写回:每个写命令执行完,立马同步地将日志写回磁盘;
- Everysec,每秒写回:每个写命令执行完,只是先把日志写到 AOF 文件的内存缓冲区,每隔一秒把缓冲区中的内容写入磁盘;
- No,操作系统控制的写回:每个写命令执行完,只是先把日志写到 AOF 文件的内存缓冲区,由操作系统决定何时将缓冲区内容写回磁盘。
Redis 4.0 中提出了一个混合使用 AOF 日志和内存快照的方法。简单来说,内存快照以一定的频率执行,在两次快照之间,使用 AOF 日志记录这期间的所有命令操作。这样一来,快照不用很频繁地执行,这就避免了频繁 fork 对主线程的影响。而且,AOF 日志也只用记录两次快照间的操作,也就是说,不需要记录所有操作了,因此,就不会出现文件过大的情况了,也可以避免重写开销。
高可靠:
Redis 可以配置成主从库模式,主库可读可写,从库只读。
当我们启动多个 Redis 实例的时候,它们相互之间就可以通过 replicaof(Redis 5.0 之前使用 slaveof,新版本用 replicaof)命令形成主库和从库的关系,之后会按照三个阶段完成数据的第一次同步。
第一阶段是主从库间建立连接、协商同步的过程,主要是为全量复制做准备。在这一步,从库和主库建立起连接,并告诉主库即将进行同步,主库确认回复后,主从库间就可以开始同步了。具体来说,从库给主库发送 psync 命令,表示要进行数据同步,主库根据这个命令的参数来启动复制。psync 命令包含了主库的 runID 和复制进度 offset 两个参数。
- runID,是每个 Redis 实例启动时都会自动生成的一个随机 ID,用来唯一标记这个实例。当从库和主库第一次复制时,因为不知道主库的 runID,所以将 runID 设为“?”。
- offset,此时设为 -1,表示第一次复制。
主库收到 psync 命令后,会用 FULLRESYNC 响应命令带上两个参数:主库 runID 和主库目前的复制进度 offset,返回给从库。从库收到响应后,会记录下这两个参数。这里有个地方需要注意,FULLRESYNC 响应表示第一次复制采用的全量复制,也就是说,主库会把当前所有的数据都复制给从库。

在第二阶段,主库将所有数据同步给从库。从库收到数据后,在本地完成数据加载。这个过程依赖于内存快照生成的 RDB 文件。具体来说,主库执行 bgsave 命令,生成 RDB 文件,接着将文件发给从库。从库接收到 RDB 文件后,会先清空当前数据库,然后加载 RDB 文件。这是因为从库在通过 replicaof 命令开始和主库同步前,可能保存了其他数据。为了避免之前数据的影响,从库需要先把当前数据库清空。在主库将数据同步给从库的过程中,主库不会被阻塞,仍然可以正常接收请求。否则,Redis 的服务就被中断了。但是,这些请求中的写操作并没有记录到刚刚生成的 RDB 文件中。为了保证主从库的数据一致性,主库会在内存中用专门的 replication buffer,记录 RDB 文件生成后收到的所有写操作。
最后,也就是第三个阶段,主库会把第二阶段执行过程中新收到的写命令,再发送给从库。具体的操作是,当主库完成 RDB 文件发送后,就会把此时 replication buffer 中的修改操作发给从库,从库再重新执行这些操作。这样一来,主从库就实现同步了。
一旦主从库完成了全量复制,它们之间就会一直维护一个网络连接,主库会通过这个连接将后续陆续收到的命令操作再同步给从库,这个过程也称为基于长连接的命令传播,可以避免频繁建立连接的开销。此时,如果主从库之间网络断了,则主从库会采用增量复制的方式继续同步。当主从库断连后,主库会把断连期间收到的写操作命令,写入 replication buffer,同时也会把这些操作命令也写入 repl_backlog_buffer 这个缓冲区。repl_backlog_buffer 是一个环形缓冲区,主库会记录自己写到的位置,从库则会记录自己已经读到的位置。刚开始的时候,主库和从库的写读位置在一起,这算是它们的起始位置。随着主库不断接收新的写操作,它在缓冲区中的写位置会逐步偏离起始位置,我们通常用偏移量来衡量这个偏移距离的大小,对主库来说,对应的偏移量就是 master_repl_offset。主库接收的新写操作越多,这个值就会越大。同样,从库在复制完写操作命令后,它在缓冲区中的读位置也开始逐步偏移刚才的起始位置,此时,从库已复制的偏移量 slave_repl_offset 也在不断增加。正常情况下,这两个偏移量基本相等。主从库的连接恢复之后,从库首先会给主库发送 psync 命令,并把自己当前的 slave_repl_offset 发给主库,主库会判断自己的 master_repl_offset 和 slave_repl_offset 之间的差距。在网络断连阶段,主库可能会收到新的写操作命令,所以,一般来说,master_repl_offset 会大于 slave_repl_offset。此时,主库只用把 master_repl_offset 和 slave_repl_offset 之间的命令操作同步给从库就行。不过,如果一个从库和主库的断连时间过长,造成它在主库 repl_backlog_buffer 的 slave_repl_offset 位置上的数据已经被覆盖掉了,此时从库和主库间将进行全量复制。每个从库会记录自己的 slave_repl_offset ,各个从库的复制进度也不一定相同。在重连进行恢复时,从库会通过 psync 命令把自己的 slave_repl_offset 发送给主库,主库会根据从库的复制进度决定从库是进行增量复制,还是全量复制。
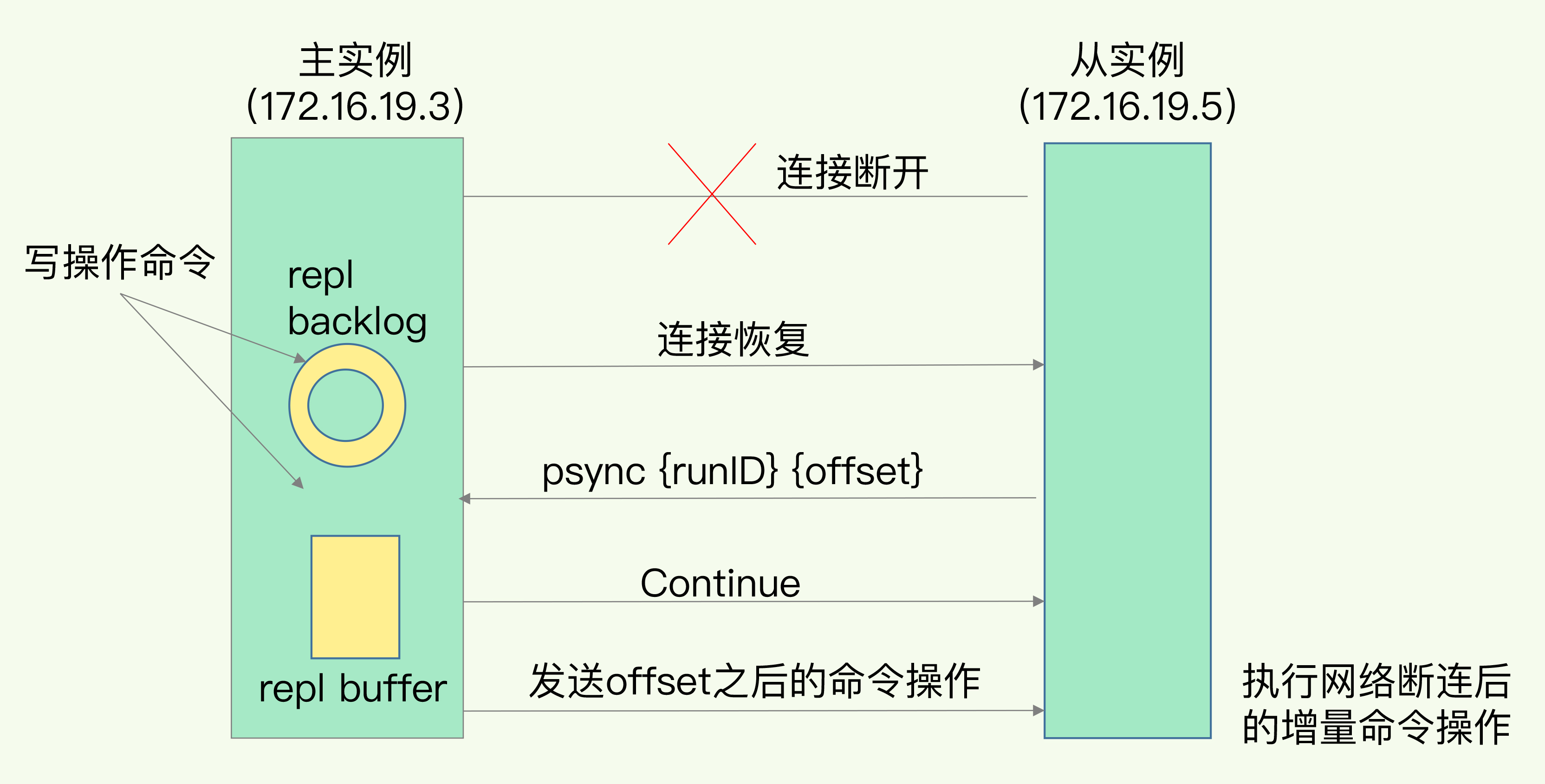
不过,有一个地方要强调一下,因为 repl_backlog_buffer 是一个环形缓冲区,所以在缓冲区写满后,主库会继续写入,此时,就会覆盖掉之前写入的操作。如果从库的读取速度比较慢,就有可能导致从库还未读取的操作被主库新写的操作覆盖了,这会导致主从库间的数据不一致。我们可以调整 repl_backlog_size 这个参数,repl_backlog_size = 缓冲空间大小 * 2 为宜。缓冲空间的计算公式是:缓冲空间大小 = 主库写入命令速度 * 操作大小 - 主从库间网络传输命令速度 * 操作大小。举个例子,如果主库每秒写入 2000 个操作,每个操作的大小为 2KB,网络每秒能传输 1000 个操作,那么,有 1000 个操作需要缓冲起来,这就至少需要 2MB 的缓冲空间。否则,新写的命令就会覆盖掉旧操作了。为了应对可能的突发压力,我们最终把 repl_backlog_size 设为 4MB。
Redis 主从库模式还引入了哨兵机制,以保证主库挂了之后从库迅速升主库,对外保持服务。哨兵其实就是一个运行在特殊模式下的 Redis 进程,主要负责三个任务:监控、选主和通知。
监控是指哨兵进程在运行时,周期性地给所有的主从库发送 PING 命令,检测它们是否仍然在线运行。如果从库没有在规定时间内响应哨兵的 PING 命令,哨兵就会把它标记为“下线状态”;同样,如果主库也没有在规定时间内响应哨兵的 PING 命令,哨兵就会判定主库下线,然后开始自动切换主库的流程。
这个流程首先是执行哨兵的第二个任务,选主。主库挂了以后,哨兵就需要从很多个从库里,按照一定的规则选择一个从库实例,把它作为新的主库。这一步完成后,现在的集群里就有了新主库。
然后,哨兵会执行最后一个任务:通知。在执行通知任务时,哨兵会把新主库的连接信息发给其他从库,让它们执行 replicaof 命令,和新主库建立连接,并进行数据复制。同时,哨兵会把新主库的连接信息通知给客户端,让它们把请求操作发到新主库上。

在这三个任务中,通知任务相对来说比较简单,哨兵只需要把新主库信息发给从库和客户端,让它们和新主库建立连接就行,并不涉及决策的逻辑。但是,在监控和选主这两个任务中,哨兵需要做出两个决策:
- 在监控任务中,哨兵需要判断主库是否处于下线状态;
- 在选主任务中,哨兵也要决定选择哪个从库实例作为主库。
哨兵对主库的下线判断有主观下线和客观下线两种。主观下线就是 PING 不通了,标记主观下线。对于从库,PING 不通了就 PING 不通了,简单标记为主观下线即可。但是对于主库,还要避免误判,因为 PING 不通可能是哨兵自己网络的问题。因为自己的原因,导致 PING 不通,然后标记成主观下线导致直接选主那肯定是万万不可的。 所以还需要引入多个哨兵,只有大多数哨兵都判断主库主观下线,主库才会被标记为客观下线。此时才会触发哨兵开始主从切换流程。
哨兵选主的流程是先按照一定的筛选条件筛选掉不符合条件的,然后再按照一定的规则,给剩下的从库打分,将得分最高的从库选为新主库。
当前不在线的从库肯定不符合条件,过去老是掉线的从库肯定也不符合条件。配置项 down-after-milliseconds * 10 就是用来判断的。其中,down-after-milliseconds 是我们认定主从库断连的最大连接超时时间。与已下线主节点连接断开超过 down-after-milliseconds * 10 毫秒的从节点,将失去选举资格。
之后,将按照如下规则进行打分。
-
优先级最高的从库得分。
我们可以通过 slave-priority 配置项,给不同的从库设置不同优先级。slave-priority 默认为100,此值越小则优先被推荐为 master 节点。如果为0,则不会被推荐。
-
和旧主库同步程度最接近的从库得分高。
主从同步时,主库会用 master_repl_offset 记录当前的最新写操作在 repl_backlog_buffer 中的位置,而从库会用 slave_repl_offset 这个值记录当前的复制进度。此时,slave_repl_offset 最接近 master_repl_offset 的从库得分最高。
-
ID 号小的从库得分高。
每个实例都会有一个 ID,这个 ID 就类似于这里的从库的编号。目前,Redis 在选主库时,有一个默认的规定:在优先级和复制进度都相同的情况下,ID 号最小的从库得分最高,会被选为新主库。
高可扩展:
单台机器的内存是有限的,而且 Redis 储存的数据越多,持久化的代价就越大。在使用 RDB 进行持久化时,Redis 会 fork 子进程来完成,fork 操作的用时和 Redis 的数据量是正相关的,而 fork 在执行时会阻塞主线程。数据量越大,fork 操作造成的主线程阻塞的时间越长。这里推荐单个实例存储的数据不超过8G。所以,为了保存更多的数据,我们一定要选择横向扩展。
Redis 3.0 之后,官方推出了 Redis Cluster 切片集群方案,支持 Redis 的横向扩展。具体来说,Redis Cluster 方案采用哈希槽(Hash Slot),来处理数据和实例之间的映射关系。在 Redis Cluster 方案中,一个切片集群共有 16384 个哈希槽,这些哈希槽类似于数据分区,每个键值对都会根据它的 key,被映射到一个哈希槽中。具体的映射过程分为两大步:首先根据键值对的 key,按照 CRC16 算法计算一个 16 bit 的值;然后,再用这个 16bit 值对 16384 取模,得到 0~16383 范围内的模数,每个模数代表一个相应编号的哈希槽。
我们使用 cluster create 命令创建切片集群,此时,Redis 会自动把这些槽平均分布在集群实例上。假如集群中有 N 个实例,那么,每个实例上的槽个数为 16384/N 个。当集群建立连接的时候,Redis 实例会把自己的哈希槽信息发送给和它相连接的其他实例,来完成哈希槽分配信息的扩散。当实例之间相互连接后,每个实例就有所有哈希槽的映射关系了。当客户端和集群建立连接后,实例就会把哈希槽的分配信息发送给客户端,客户端收到哈希槽信息后,会把哈希槽信息缓存在本地。当客户端请求键值对时,会先计算键所对应的哈希槽,然后就可以给相应的实例发送请求了。不过,在集群中,实例和哈希槽的对应关系并不是一成不变的,最常见的变化有两个:
- 在集群中,实例有新增或删除,Redis 需要重新分配哈希槽;
- 为了负载均衡,Redis 需要把哈希槽在所有实例上重新分布一遍。
此时,实例之间还可以通过相互传递消息,获得最新的哈希槽分配信息,但是,客户端是无法主动感知这些变化的。因此,Redis Cluster 方案提供了一种重定向机制,所谓的“重定向”,就是指,客户端给一个实例发送数据读写操作时,这个实例上并没有相应的数据,客户端要再给一个新实例发送操作命令。就是,当客户端请求某个实例上的 Key 时,该实例上并没有这个键值对映射的哈希槽,那么,这个实例就会给客户端返回 MOVED 命令响应结果,这个结果中就包含了新实例的访问地址。此时,客户端会访问新的地址,并且更新本地缓存。
GET hello:key
(error) MOVED 13320 172.16.19.5:6379
上面说的是槽中的数据已经全部迁移好了的情况,如果槽中数据没有完全迁移好,客户端会收到一条 ASK 报错信息,如下所示:
GET hello:key
(error) ASK 13320 172.16.19.5:6379
这个结果中的 ASK 命令就表示,客户端请求的键值对所在的哈希槽 13320,在 172.16.19.5 这个实例上,但是这个哈希槽正在迁移。此时,客户端需要先给 172.16.19.5 这个实例发送一个 ASKING 命令。这个命令的意思是,让这个实例允许执行客户端接下来发送的命令。然后,客户端再向这个实例发送 GET 命令,以读取数据。和 MOVED 命令不同,ASK 命令并不会更新客户端缓存的哈希槽分配信息。想要更新本地缓存,只能等全部迁移完之后再请求一次,然后返回 MOVED 以及新的地址,再更新。
-
单例
一个最简单的 Redis 实例(这里是 6.0.10 版本),你只需要这样配置:
port 6379 # 设置端口号 protected-mode no # 关闭保护模式 appendonly yes # 开启 AOF 持久化protected-mode 默认是 yes,代表外部客户端无法连接到本实例,除非使用 bind 绑定 IP。一般情况下,我们都会关闭保护模式,如果觉得不安全,可以使用 requirepass 给 Redis 设置密码。
在开启 AOF 持久化后,以下参数都是默认的:
appendfilename "appendonly.aof" # AOF 日志文件命名,默认 "appendonly.aof" appendfsync everysec # AOF 日志同步频率,默认 everysec no-appendfsync-on-rewrite no # AOF 重写时阻塞 AOF 日志追加 auto-aof-rewrite-percentage 100 # AOF 比上次重写后的体量增加了100%,默认 100 auto-aof-rewrite-min-size 64mb # AOF 重写时文件的最小大小,默认 64mb aof-load-truncated yes # 当发生 AOF 文件末尾截断时,加载文件还是报错退出AOF 三种落盘方式上文已经介绍过了,Redis 的持久化并不能保证数据的强不丢失,
appendfsync always会导致 Redis 性能急剧下降,appendfsync no从不主动写磁盘,等系统自动写,会导致 Redis 丢失大量数据。所以综合下来appendfsync everysec是最合理的,也是 Redis 默认的 AOF 持久化方式。随着 Redis 数据越来越多,AOF 日志文件就会被撑得越来越大,写入新的命令也就越来越慢,宕机后数据恢复的过程也会变得异常缓慢。这个时候 AOF 重写机制,就派上用场了。简单来说,重写机制就是将多条旧命令变成一条新命令。如下图所示:
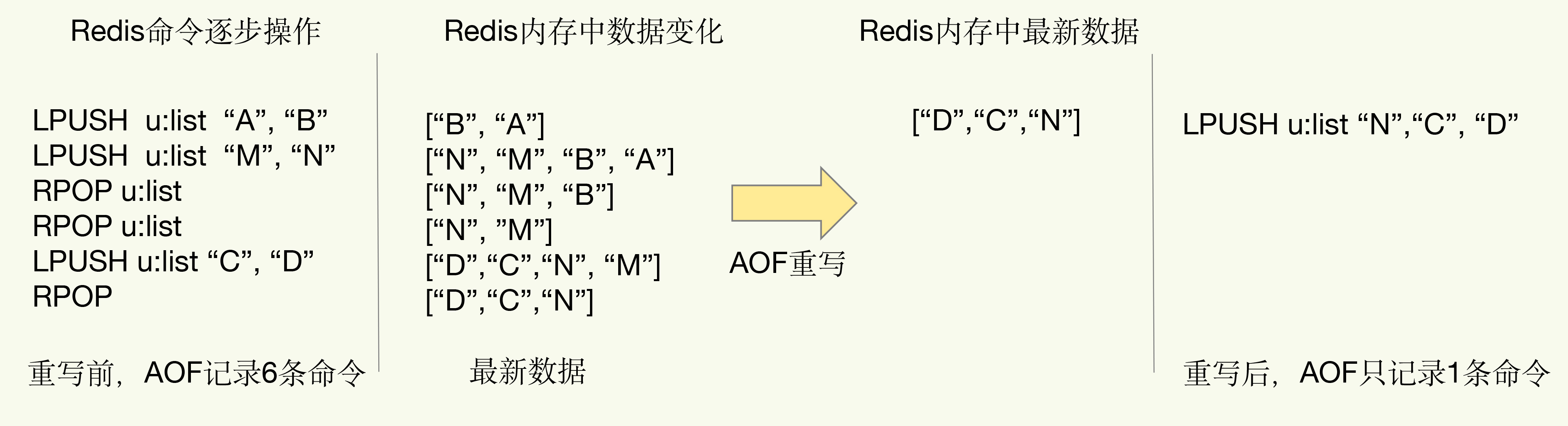
Redis AOF 重写是由主线程 fork 出后台的 bgrewriteaof 子进程来完成的。子进程不会影响到主线程,不过 fork 这个瞬间一定是会阻塞主线程的。fork 采用操作系统提供的写实复制(Copy On Write)机制,避免一次性拷贝大量内存数据给子进程造成的长时间阻塞问题,不过还是需要拷贝必要的数据结构,其中有一项就是拷贝内存页表(虚拟内存和物理内存的映射索引表),这个拷贝过程会消耗大量 CPU 资源,拷贝完成之前整个进程是会阻塞的,阻塞时间取决于整个实例的内存大小,实例越大,内存页表越大,fork 阻塞时间越久。拷贝内存页表完成后,子进程与父进程指向相同的内存地址空间(子进程复制了父进程页表,也能共享访问父进程的内存数据了),也就是说此时虽然产生了子进程,但是并没有申请与父进程相同的内存大小。此时子进程就可以执行 AOF 重写,把内存中的所有数据写入到新的 AOF 文件中(内存快照)。与此同时父进程依旧是会有流量写入的,如果父进程操作的是一个已经存在的 key,那么这个时候父进程才会真正拷贝这个 key 对应的内存数据,申请新的内存空间(给子进程),这样父子进程开始分离,逐渐拥有各自独立的内存空间。如果父进程操作的是一个不存在的 key,则正常申请内存(给自己,与子进程无关)。fork 之后,父进程的操作不会影响到子进程。AOF 重写时,主线程未阻塞,仍然可以处理新来的操作。如果有写操作,同时在 AOF 日志缓冲区和 AOF 重写日志缓冲区写入操作,这样,即使宕机,AOF 日志的操作仍然是齐全的,AOF 重写日志也不会丢失最新的操作。等到拷贝数据的所有操作记录重写完成后,重写日志记录的这些最新操作也会写入新的 AOF 文件,以保证数据库最新状态的记录。此时,我们就可以用新的 AOF 文件替代旧文件了。
写时拷贝延伸阅读:https://www.cnblogs.com/biyeymyhjob/archive/2012/07/20/2601655.html
AOF 重写时,需要注意这几个参数:
no-appendfsync-on-rewrite no,AOF 日志重写会进行大量 I/O 操作,此时有可能会阻塞 fsync 操作,将参数改为 yes 可以避免阻塞,但是可能会导致数据丢失。如果你有延迟问题,将选项改为 yes,否则,从持久性的角度来看,no 是最安全的。auto-aof-rewrite-percentage 100和auto-aof-rewrite-min-size 64mb是一起的,代表 AOF 重写时,AOF 文件大小比上一次重写时大 100%,且至少是 64mb。aof-load-truncated yes,如果Redis所在的机器运行崩溃,就可能导致该现象。特别是在不使用data=ordered选项挂载 ext4 文件系统时(但是Redis本身崩溃而操作系统正常运行则不会出现该情况)。当发生了末尾截断,yes 代表继续加载 AOF 文件,并打印日志通知用户。no 代表报错并拒绝启动,这时用户需要使用redis-check-aof工具修复 AOF 文件再重启。
在 Redis 中 RDB 是默认打开的,不过在上文最简单的配置中,我们并没有开启自动写 RDB。
127.0.0.1:6379> config get save
1) "save"
2) ""
此时可以手动 save 生成 RDB 文件,但是不会以一定的频率 bgsave 生成 RDB 文件,如果想要开启,需要如下配置:
save 900 1 # 在 900 秒(15分钟)后,如果至少有一个键改变
save 300 10 # 在 300 秒(5分钟)后,如果至少有 10 个键改变
save 60 10000 # 在 60 秒后,如果至少更改了 10000 个键
127.0.0.1:6379> config get save
1) "save"
2) "900 1 300 10 60 10000"
与 RDB 相关的还有以下几个参数,都是给的默认值:
stop-writes-on-bgsave-error yes # 生成快照失败拒绝写入
rdbcompression yes # RDB 使用 LZF 压缩
rdbchecksum yes # 开启校验 RDB 文件
dbfilename dump.rdb # RDB 文件名
rdb-del-sync-files no # 没有持久化也不删除 RDB 文件
具体的参数说明还是需要看官方文档:https://raw.githubusercontent.com/redis/redis/6.0/redis.conf
当 AOF 和 RDB 同时开启的时候,我们一定要将这个参数设置为 yes。
aof-use-rdb-preamble yes # 开启混动模式
aof-use-rdb-preamble yes 代表当重写 AOF 文件时,Redis 能使用 RDB 的前文,使得 AOF 文件可以更快地重写和恢复。在开启了这个功能之后,AOF 重写产生的 AOF 文件将同时包含 RDB 格式的内容和 AOF 格式的内容,其中 RDB 格式的内容用于记录已有的数据,而 AOF 格式的内容则用于记录最近发生了变化的数据。主进程先 fork 出子进程将现有内存副本全量以 RDB 方式写入 AOF 文件中,然后将缓冲区中的增量命令以 AOF 方式写入 AOF 文件中,写入完成后通知主进程更新相关信息,并将新的含有 RDB 和 AOF 两种格式的 AOF 文件替换旧的 AOF 文件。
所以,最终我的 Redis 单例精简版配置文件是这个样子的:
port 6379
protected-mode no
appendonly yes
save 900 1
save 300 10
save 60 10000
aof-use-rdb-preamble yes
logfile /redis/redis.log
docker-compose 配置文件:
version: "3.7"
services:
redis:
image: redis:6.0.10
container_name: redis
restart: always
ports:
- "6379:6379"
volumes:
- /work/docker/redis/conf/redis.conf:/usr/local/etc/redis/redis.conf
- /work/docker/redis/data:/data
- /work/docker/redis/log/redis.log:/redis/redis.log
command: redis-server /usr/local/etc/redis/redis.conf --requirepass 111111
-
集群
单个实例宕机,只能用恢复数据来解决,那我们是否可以部署多个 Redis 实例,然后让这些实例数据保持实时同步,这样当一个实例宕机时,我们在剩下的实例中选择一个继续提供服务就好了。这个方案就是主从复制。主从复制可以是一主一从,也可以是一主多从。其中主库可写可读,从库只读(Redis 2.6 之后,从库默认 read-only)。要配置主从同步,只需要在从库配置文件中添加以下两行:
replicaof redis-master 6379 # 主库的 IP 和端口号 masterauth 111111 # 主库的密码从库启动后:
1:S 17 Mar 2021 06:04:01.697 * Ready to accept connections 1:S 17 Mar 2021 06:04:01.697 * Connecting to MASTER redis-master:6379 1:S 17 Mar 2021 06:04:01.699 * MASTER <-> REPLICA sync started 1:S 17 Mar 2021 06:04:01.701 * Non blocking connect for SYNC fired the event. 1:S 17 Mar 2021 06:04:01.701 * Master replied to PING, replication can continue... 1:S 17 Mar 2021 06:04:01.701 * Partial resynchronization not possible (no cached master) 1:S 17 Mar 2021 06:04:01.703 * Full resync from master: cc0cc0ec16ae6de6b0eecb0fefd2ca20072488cd:11867 1:S 17 Mar 2021 06:04:01.793 * MASTER <-> REPLICA sync: receiving 201 bytes from master to disk 1:S 17 Mar 2021 06:04:01.793 * MASTER <-> REPLICA sync: Flushing old data 1:S 17 Mar 2021 06:04:01.799 * MASTER <-> REPLICA sync: Loading DB in memory 1:S 17 Mar 2021 06:04:01.834 * Loading RDB produced by version 6.0.10 1:S 17 Mar 2021 06:04:01.834 * RDB age 0 seconds 1:S 17 Mar 2021 06:04:01.834 * RDB memory usage when created 1.83 Mb 1:S 17 Mar 2021 06:04:01.834 * MASTER <-> REPLICA sync: Finished with success 1:S 17 Mar 2021 06:04:01.835 * Background append only file rewriting started by pid 17 1:S 17 Mar 2021 06:04:01.899 * AOF rewrite child asks to stop sending diffs. 17:C 17 Mar 2021 06:04:01.899 * Parent agreed to stop sending diffs. Finalizing AOF... 17:C 17 Mar 2021 06:04:01.899 * Concatenating 0.00 MB of AOF diff received from parent. 17:C 17 Mar 2021 06:04:01.899 * SYNC append only file rewrite performed 17:C 17 Mar 2021 06:04:01.900 * AOF rewrite: 0 MB of memory used by copy-on-write 1:S 17 Mar 2021 06:04:01.935 * Background AOF rewrite terminated with success 1:S 17 Mar 2021 06:04:01.935 * Residual parent diff successfully flushed to the rewritten AOF (0.00 MB) 1:S 17 Mar 2021 06:04:01.935 * Background AOF rewrite finished successfully我们也可以使用
info replication命令查看主从库状态:127.0.0.1:6379> info replication # Replication role:slave master_host:redis-master master_port:6379 master_link_status:up master_last_io_seconds_ago:4 master_sync_in_progress:0 slave_repl_offset:12007 slave_priority:100 slave_read_only:1 connected_slaves:0 master_replid:cc0cc0ec16ae6de6b0eecb0fefd2ca20072488cd master_replid2:0000000000000000000000000000000000000000 master_repl_offset:12007 second_repl_offset:-1 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:11868 repl_backlog_histlen:140如此一来,主库专门写,从库专门读,读写分离,性能更强悍。缺点是万一主库挂了,需要手动将从库升主库。那么,能不能自动化呢?这里就需要引入哨兵机制。
为了避免单个哨兵因为网络堵塞而误判,我们使用哨兵集群。哨兵配置文件如下(一式三份):
# sentinel.conf port 26379 # 端口号 sentinel monitor mymaster redis-master 6379 2 # 主库 IP、端口、法定人数 sentinel auth-pass mymaster 111111 # master 密码 sentinel down-after-milliseconds mymaster 3000 # 主观下线时间 sentinel failover-timeout mymaster 60000 # 主备切换超时时间 sentinel parallel-syncs mymaster 1 # 主备切换后同时同步新主库的副本数详细的哨兵配置参数见官方文档:https://redis.io/topics/sentinel
docker-compose 配置文件(需要给 conf0、conf1、conf2 文件夹写的权限):
version: "3.7" services: redis-master: image: redis:6.0.10 container_name: redis-master restart: always ports: - "6379:6379" volumes: - /work/docker/redis-master/conf/redis.conf:/usr/local/etc/redis/redis.conf - /work/docker/redis-master/data:/data - /work/docker/redis-master/log/redis.log:/redis/redis.log command: redis-server /usr/local/etc/redis/redis.conf --requirepass 111111 networks: - dev-net redis-slave: image: redis:6.0.10 container_name: redis-slave restart: always ports: - "6380:6379" volumes: - /work/docker/redis-slave/conf/redis.conf:/usr/local/etc/redis/redis.conf - /work/docker/redis-slave/data:/data - /work/docker/redis-slave/log/redis.log:/redis/redis.log command: redis-server /usr/local/etc/redis/redis.conf --requirepass 111111 networks: - dev-net redis-sentinel0: image: redis:6.0.10 container_name: redis-sentinel0 ports: - "26379:26379" volumes: - /work/docker/redis-sentinel/conf0:/usr/local/etc/redis command: redis-sentinel /usr/local/etc/redis/sentinel.conf networks: - dev-net redis-sentinel1: image: redis:6.0.10 container_name: redis-sentinel1 ports: - "26380:26379" volumes: - /work/docker/redis-sentinel/conf1:/usr/local/etc/redis command: redis-sentinel /usr/local/etc/redis/sentinel.conf networks: - dev-net redis-sentinel2: image: redis:6.0.10 container_name: redis-sentinel2 ports: - "26381:26379" volumes: - /work/docker/redis-sentinel/conf2:/usr/local/etc/redis command: redis-sentinel /usr/local/etc/redis/sentinel.conf networks: - dev-net networks: dev-net: driver: bridge哨兵集群启动后:
[root@VM-0-6-centos docker-compose]# docker logs redis-sentinel0 -f 1:X 17 Mar 2021 10:13:10.951 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo 1:X 17 Mar 2021 10:13:10.951 # Redis version=6.0.10, bits=64, commit=00000000, modified=0, pid=1, just started 1:X 17 Mar 2021 10:13:10.951 # Configuration loaded 1:X 17 Mar 2021 10:13:10.954 * Running mode=sentinel, port=26379. 1:X 17 Mar 2021 10:13:10.954 # WARNING: The TCP backlog setting of 511 cannot be enforced because /proc/sys/net/core/somaxconn is set to the lower value of 128. 1:X 17 Mar 2021 10:13:11.022 # Sentinel ID is 77863f81f0823e54d48822b917adbdecb8103ede 1:X 17 Mar 2021 10:13:11.022 # +monitor master mymaster 172.20.0.2 6379 quorum 2 1:X 17 Mar 2021 10:13:11.024 * +slave slave 172.20.0.3:6379 172.20.0.3 6379 @ mymaster 172.20.0.2 6379 1:X 17 Mar 2021 10:13:12.530 * +sentinel sentinel 84b1a6bde7a8527c3cde839719131669aeeeebcd 172.20.0.4 26379 @ mymaster 172.20.0.2 6379 1:X 17 Mar 2021 10:13:12.843 * +sentinel sentinel f3794c50e051e177a6e9cf632b37b931ab7d64e4 172.20.0.6 26379 @ mymaster 172.20.0.2 6379此时如果主库挂了,则从库自动升级为主库,主库降级为从库(如果新的主库需要验证,老的主库配置文件一定要加 masterauth):
1:X 17 Mar 2021 10:23:38.227 # +sdown master mymaster 172.20.0.2 6379 1:X 17 Mar 2021 10:23:38.298 # +odown master mymaster 172.20.0.2 6379 #quorum 2/2 1:X 17 Mar 2021 10:23:38.298 # +new-epoch 1 1:X 17 Mar 2021 10:23:38.298 # +try-failover master mymaster 172.20.0.2 6379 1:X 17 Mar 2021 10:23:38.310 # +vote-for-leader 77863f81f0823e54d48822b917adbdecb8103ede 1 1:X 17 Mar 2021 10:23:38.334 # f3794c50e051e177a6e9cf632b37b931ab7d64e4 voted for 77863f81f0823e54d48822b917adbdecb8103ede 1 1:X 17 Mar 2021 10:23:38.334 # 84b1a6bde7a8527c3cde839719131669aeeeebcd voted for 77863f81f0823e54d48822b917adbdecb8103ede 1 1:X 17 Mar 2021 10:23:38.363 # +elected-leader master mymaster 172.20.0.2 6379 1:X 17 Mar 2021 10:23:38.363 # +failover-state-select-slave master mymaster 172.20.0.2 6379 1:X 17 Mar 2021 10:23:38.425 # +selected-slave slave 172.20.0.3:6379 172.20.0.3 6379 @ mymaster 172.20.0.2 6379 1:X 17 Mar 2021 10:23:38.425 * +failover-state-send-slaveof-noone slave 172.20.0.3:6379 172.20.0.3 6379 @ mymaster 172.20.0.2 6379 1:X 17 Mar 2021 10:23:38.477 * +failover-state-wait-promotion slave 172.20.0.3:6379 172.20.0.3 6379 @ mymaster 172.20.0.2 6379 1:X 17 Mar 2021 10:23:39.360 # +promoted-slave slave 172.20.0.3:6379 172.20.0.3 6379 @ mymaster 172.20.0.2 6379 1:X 17 Mar 2021 10:23:39.360 # +failover-state-reconf-slaves master mymaster 172.20.0.2 6379 1:X 17 Mar 2021 10:23:39.419 # +failover-end master mymaster 172.20.0.2 6379 1:X 17 Mar 2021 10:23:39.419 # +switch-master mymaster 172.20.0.2 6379 172.20.0.3 6379 1:X 17 Mar 2021 10:23:39.419 * +slave slave 172.20.0.2:6379 172.20.0.2 6379 @ mymaster 172.20.0.3 6379 1:X 17 Mar 2021 10:23:42.467 # +sdown slave 172.20.0.2:6379 172.20.0.2 6379 @ mymaster 172.20.0.3 6379 1:X 17 Mar 2021 10:25:26.377 # -sdown slave 172.20.0.2:6379 172.20.0.2 6379 @ mymaster 172.20.0.3 6379在大多数情况下,使用主从同步的 Redis 集群就够用了。但是在拥有大量数据的场景下,一主多从很明显已经不太适用,因为单台机器的内存是有限的,而且昂贵。过多的数据会导致 fork 阻塞主线程,新增从库数据同步时也会变得缓慢无比。因此 Redis 还提供了可支持横向扩展的切片集群。
切片集群的配置文件需要在单例的基础上添加如下几行:
cluster-enabled yes cluster-config-file nodes.conf cluster-node-timeout 5000更多配置直接看文档:https://redis.io/topics/cluster-tutorial
使用如下命令创建 Redis Cluster 集群(三主三从):
redis-cli -a 111111 --cluster create 172.20.0.2:6379 172.20.0.3:6379 172.20.0.4:6379 172.20.0.5:6379 172.20.0.6:6379 172.20.0.7:6379 --cluster-replicas 1--cluster-replicas 1代表一个主节点对应一个从节点。
搭建成功:
>>> Performing hash slots allocation on 6 nodes... Master[0] -> Slots 0 - 5460 Master[1] -> Slots 5461 - 10922 Master[2] -> Slots 10923 - 16383 Adding replica 172.20.0.6:6379 to 172.20.0.2:6379 Adding replica 172.20.0.7:6379 to 172.20.0.3:6379 Adding replica 172.20.0.5:6379 to 172.20.0.4:6379 M: 1e1710a007f619d116edc28ec6fc899677c08801 172.20.0.2:6379 slots:[0-5460] (5461 slots) master M: 59380ec9078d79eeceb55f43433f911c9fe57371 172.20.0.3:6379 slots:[5461-10922] (5462 slots) master M: d298640cf201a937956cf2709e19245c1c5c5eb0 172.20.0.4:6379 slots:[10923-16383] (5461 slots) master S: 8e6c7593f6044a7710415712b01dc3226b21fc64 172.20.0.5:6379 replicates d298640cf201a937956cf2709e19245c1c5c5eb0 S: 1c82eae62055b7006c5890608345263b2c6072d4 172.20.0.6:6379 replicates 1e1710a007f619d116edc28ec6fc899677c08801 S: 3179ec28a2ada74b70cb138a4b342551edde98b6 172.20.0.7:6379 replicates 59380ec9078d79eeceb55f43433f911c9fe57371 Can I set the above configuration? (type 'yes' to accept): yes >>> Nodes configuration updated >>> Assign a different config epoch to each node >>> Sending CLUSTER MEET messages to join the cluster Waiting for the cluster to join . >>> Performing Cluster Check (using node 172.20.0.2:6379) M: 1e1710a007f619d116edc28ec6fc899677c08801 172.20.0.2:6379 slots:[0-5460] (5461 slots) master 1 additional replica(s) M: 59380ec9078d79eeceb55f43433f911c9fe57371 172.20.0.3:6379 slots:[5461-10922] (5462 slots) master 1 additional replica(s) S: 3179ec28a2ada74b70cb138a4b342551edde98b6 172.20.0.7:6379 slots: (0 slots) slave replicates 59380ec9078d79eeceb55f43433f911c9fe57371 M: d298640cf201a937956cf2709e19245c1c5c5eb0 172.20.0.4:6379 slots:[10923-16383] (5461 slots) master 1 additional replica(s) S: 1c82eae62055b7006c5890608345263b2c6072d4 172.20.0.6:6379 slots: (0 slots) slave replicates 1e1710a007f619d116edc28ec6fc899677c08801 S: 8e6c7593f6044a7710415712b01dc3226b21fc64 172.20.0.5:6379 slots: (0 slots) slave replicates d298640cf201a937956cf2709e19245c1c5c5eb0 [OK] All nodes agree about slots configuration. >>> Check for open slots... >>> Check slots coverage... [OK] All 16384 slots covered.
参考资料:《Redis核心技术与实战》

