
MySQL查询性能优化
一、是否查询了不需要的数据
1.多使用limit来分页
2.不要用select *,特别是在多表关联的时候
3.避免重复查询相同的数据,可以多使用缓存
二、正确使用索引
如何正确使用索引见上一篇文章《MySQL索引》,这里再补充几个索引失效的案例:
key(last_name, first_name, dob)
1.select * from blog_user where last_name like '%A%'; //使用like时通配符在前
2.select * from blog_user where last_name is null; //is null或is not null会放弃使用索引
3.select * from blog_user where UPPER(last_name) like 'A%'; //对索引列做了函数计算
4.select * from blog_user where last_name like 'A%' or first_name = 'b'; //使用or会导致索引失效,除非or的左右两边都分别正确使用索引。如select * from blog_user where last_name like 'A%' or last_name = 'b';
5.隐式类型转换

6.隐式字符编码转换
创建blog_name表:
CREATE TABLE `blog_name` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`last_name` varchar(40) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL,
`first_name` varchar(40) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL,
PRIMARY KEY (`id`),
KEY `last_name` (`last_name`),
KEY `first_name` (`first_name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
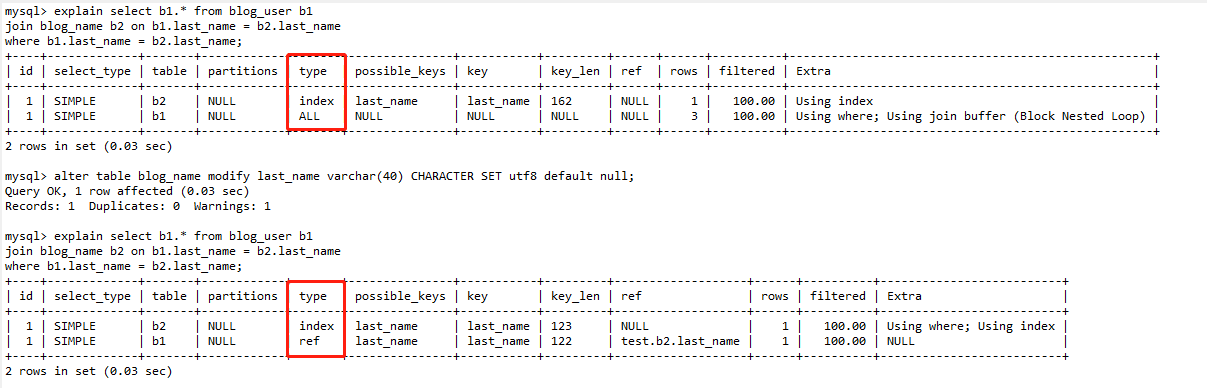
7.MySQL选错索引
先向blog_name插入10万条数据:
delimiter ;;
create procedure Adata()
begin
declare i int;
set i=1;
while(i<=100000)do
insert into blog_name values(null, i, i);
set i=i+1;
end while;
end;;
delimiter ;
call Adata();
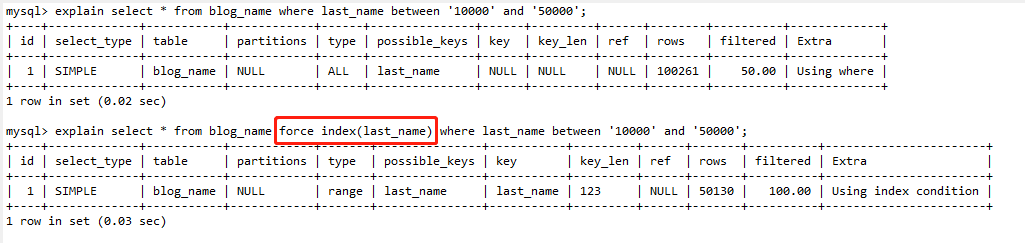
这里虽然有索引但是却没有使用索引而是走的全表扫描,因为MySQL优化器认为直接扫描主键索引更快,如果使用索引last_name,每次从索引last_name上拿到一个值,都要返回主键索引查出整行数据,这个代价优化器也要算进去。而如果全表扫描,是直接在主键索引上扫描的,没有额外代价。这种情况可以通过force index来指定使用索引,从而避免索引失效。(如果指定使用索引更快的话)
三、减少锁争用
1.避免大事务
2.避免一次操作太多行
如delete from logs limit 10000;可以做出如下优化:
for (i = 0; i < 20; i++) {
delete from logs limit 500;
}
参考资料:《高性能MySQL第三版》、《MySQL实战45讲》

 浙公网安备 33010602011771号
浙公网安备 33010602011771号