数据结构堆(Heap)&排序&树&二叉树
在我们描述堆之前,我们首先要明白一个概念,什么是树?
树的概念及结构
1.树的概念
树就是一种类似现实生活中的树的数据结构(倒置的树)。任何一颗非空树只有一个根节点。
一棵树具有以下特点:
- 一棵树中的任意两个结点有且仅有唯一的一条路径连通。
- 一棵树如果有 n 个结点,那么它一定恰好有 n-1 条边。
- 一棵树不包含回路。
树是一种非线性的数据结构,它是由n(n>=0)个有限结点组成一个具有层次关系的集合。把它叫做树是因为它看起来像一棵倒挂的树,也就是说它是根在上,而叶在下的。
有一个特殊的结点,称为根结点,根节点没有前驱结点。除根节点外,其余结点被分成m(m > 0)个互不相交的集合T1、T2、…… 、Tm,其中每一个集合Ti(1 <= i <= m)又是一棵结构与树类似的子树。每棵子树的根结点有且只有一个前驱,但可以有0个或多个后继。
由此可知,树是递归定义的。
下图就是一颗树,并且是一颗二叉树。

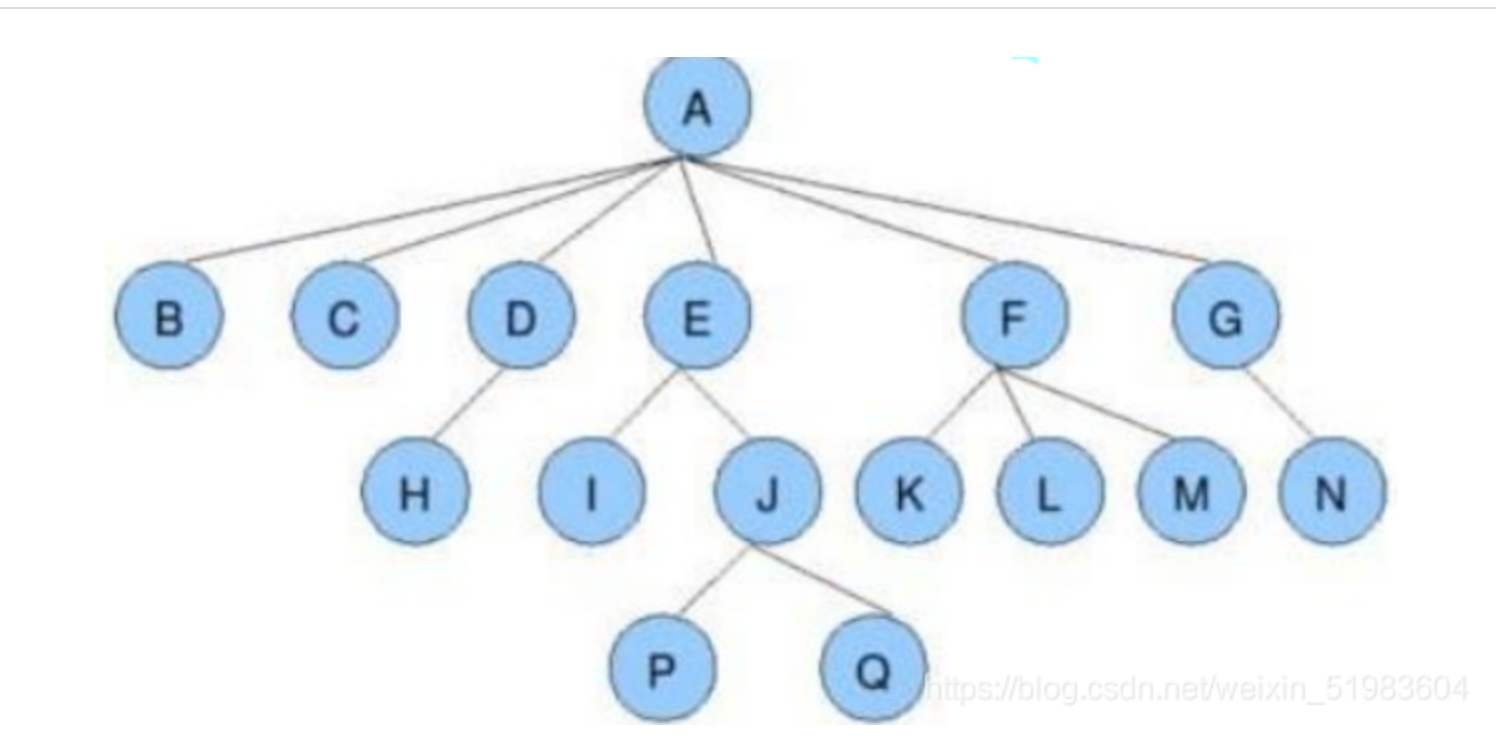
下面介绍一些与树相关的概念(以上面的树为例):
(1)结点的度:一个节点含有的子树的个数称为该节点的度;如上图:A的为6,即B、C、D、E、F、G。
(2)叶结点:度为0的节点称为叶结点;如上图:B、C、H、I、K、L、M、N、P、Q 为叶结点。
(3)双亲结点或父结点:若一个节点含有子结点,则这个结点称为其子结点的父结点;如上图:A是B的父结点。
(4)孩子结点或子结点:一个结点含有的子树的根结点称为该结点的子结点;如上图:B是A的孩子节点。
(5)兄弟结点:具有相同父结点的结点互称为兄弟结点; 如上图:B、C是兄弟结点。
(6)树的度:一棵树中,最大的节点的度称为树的度; 如上图:树的度为6。
(7)结点的层次:从根开始定义起,根为第1层,根的子结点为第2层,以此类推。
(8)树的高度或深度:树中结点的最大层次; 如上图:树的高度为4。
(9)节点的祖先:从根到某一结点所经分支上的所有结点;如上图:D、A是H的祖先;A是所有结点的公共祖先。
(10)子孙:以某节点为根的子树中任一节点都称为该节点的子孙。如上图:所有节点都是A的子孙。
(11)森林:多棵互不相交的树的集合称为森林。
2.树的表示方法
树由于不是线性结构,所以相对线性表,要存储、表示就相对麻烦,实际中树有很多种表示方式,如:双亲表示法,孩子表示法、孩子兄弟表示法等等。这里简单地介绍其中最常用的孩子兄弟表示法。
孩子兄弟表示法就是用孩子结点来找到下一层的结点,用兄弟结点来找到这一层其余的结点,结构如下。
typedef int DataType; struct Node { struct Node* firstChild1; // 第一个孩子结点 struct Node* pNextBrother; // 指向其下一个兄弟结点 DataType data; // 结点中的数据域 };

二叉树
1.二叉树概念及结构
二叉树(Binary tree)是每个节点最多只有两个分支(即不存在分支度大于 2 的节点)的树结构。
二叉树 的分支通常被称作“左子树”或“右子树”。并且,二叉树 的分支具有左右次序,不能随意颠倒。
概念:一棵二叉树是结点的一个有限集合,该集合为空,或者是由一个根节点加上两棵称为左子树和右子树的二叉树组成。
特殊的二叉树:
(1)满二叉树(Perfect Binary Tree)
每一层的结点数都达到最大值,则这个二叉树就是满二叉树。
也就是说,如果一个二叉树的层数为K(根节点是第1层),且结点总数是(2^k) -1 ,则它就是满二叉树,也称为完美二叉树

(2)完全二叉树(Complete Binary Tree)
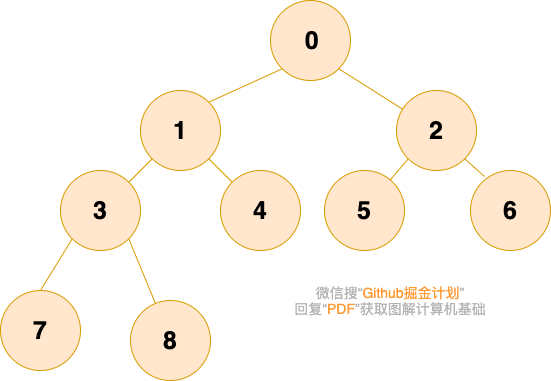
完全二叉树是由满二叉树而引出来的。对于深度为K的、有n个结点的二叉树,当且仅当其每一个结点都与深度为K的满二叉树中编号从1至n的结点一一对应时称之为完全二叉树。 满二叉树是一种特殊的完全二叉树。
完全二叉树的叶子结点只能出现在最下层和次下层,且最下层的叶子结点从左到右连续;前K-1层是满的二叉树。
换句话说,
除最后一层外,若其余层都是满的,并且最后一层或者是满的,或者是在右边缺少连续若干节点,则这个二叉树就是 完全二叉树 。
大家可以想象为一棵树从根结点开始扩展,扩展完左子节点才能开始扩展右子节点,每扩展完一层,才能继续扩展下一层。如下图所示:
(3)平衡二叉树
平衡二叉树 是一棵二叉排序树,且具有以下性质:
- 可以是一棵空树
- 如果不是空树,它的左右两个子树的高度差的绝对值不超过 1,并且左右两个子树都是一棵平衡二叉树。
平衡二叉树的常用实现方法有 红黑树、AVL 树、替罪羊树、加权平衡树、伸展树 等。
在给大家展示平衡二叉树之前,先给大家看一棵树:

你管这玩意儿叫树???
没错,这玩意儿还真叫树,只不过这棵树已经退化为一个链表了,我们管它叫 斜树。
如果这样,那我为啥不直接用链表呢?
谁说不是呢?
二叉树相比于链表,由于父子节点以及兄弟节点之间往往具有某种特殊的关系,这种关系使得我们在树中对数据进行搜索和修改时,相对于链表更加快捷便利。
但是,如果二叉树退化为一个链表了,那么树所具有的优秀性质就难以表现出来,效率也会大打折,为了避免这样的情况,我们希望每个做 “家长”(父结点) 的,都 一碗水端平,分给左儿子和分给右儿子的尽可能一样多,相差最多不超过一层,如下图所示:

(4)完满二叉树(Full Binary Tree)
换句话说,所有非叶子结点的度都是2。(只要你有孩子,你就必然是有两个孩子。)
注:Full Binary Tree又叫做Strictly Binary Tree。
二叉树的存储
二叉树的存储主要分为 链式存储 和 顺序存储 两种:
链式存储
和链表类似,二叉树的链式存储依靠指针将各个节点串联起来,不需要连续的存储空间。
每个节点包括三个属性:
- 数据 data。data 不一定是单一的数据,根据不同情况,可以是多个具有不同类型的数据。
- 左节点指针 left
- 右节点指针 right。
可是 JAVA 没有指针啊!那就直接引用对象呗

顺序存储
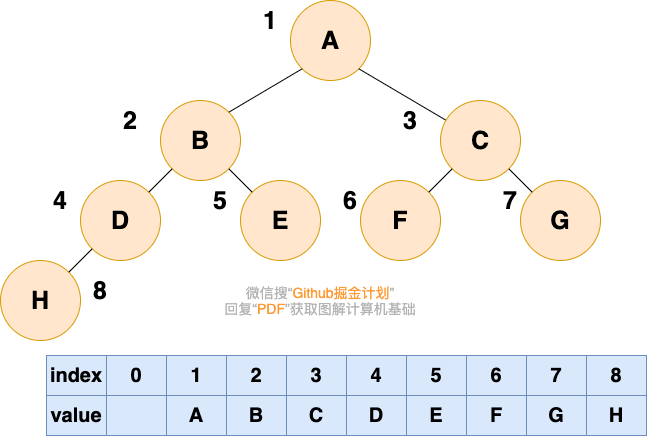
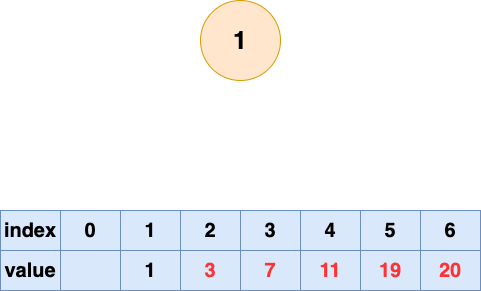
顺序存储就是利用数组进行存储,数组中的每一个位置仅存储节点的 data,不存储左右子节点的指针,子节点的索引通过数组下标完成。根结点的序号为 1,对于每个节点 Node,假设它存储在数组中下标为 i 的位置,那么它的左子节点就存储在 2i 的位置,它的右子节点存储在下标为 2i+1 的位置。
一棵完全二叉树的数组顺序存储如下图所示:
大家可以试着填写一下存储如下二叉树的数组,比较一下和完全二叉树的顺序存储有何区别:

可以看到,如果我们要存储的二叉树不是完全二叉树,在数组中就会出现空隙,导致内存利用率降低。
二叉树的遍历
递归序:
public void preOrder(Node root){
if(root == null){
return;
}
system.out.println(root.data);
preOrder(root.left);
preOrder(root.right);
}1,2,4,4(left==null),4(right ==null),2,5,5(left==null),5(right ==null),2,1,3,6,6,6,3,7,7,7,3,1
先序(头、左、右)第一次出现:1,2, 4,5,3,6,7
中序(左、头、右)第二次出现:4,2,5,1,6,3,7
后序 (左、右、头)第三次出现:4,5,2,6,7,3,1

任何递归函数都可以改为非递归函数。
1 2 3 4 5 | class Node<V>{ V value; Node left; Node right; } |
先序遍历:
二叉树的先序遍历,就是先输出根结点,再遍历左子树,最后遍历右子树,遍历左子树和右子树的时候,同样遵循先序遍历的规则,也就是说,我们可以递归实现先序遍历。
先把头节点放到栈里面,
1.每次在栈中弹出一个节点current
2.打印current
3.先压右 再压左,如果有的话。没有什么都不做。
4.重复上面操作。
1节点 弹出,打印1 ,先压3 再压2,弹出2,打印2,先压5,再压4,弹出4 ,打印4,没有什么都不做。弹出5.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | public static void preOrderUnRecur(Node head){ System.out.println("pre-order:"); if(head != null){ Stack<Node> stack = new Stack<Node>(); stack.add(head); while (!stack.isEmpty()){ head = stack.pop(); System.out.println(head.value+""); if(head.right != null){ stack.push(head.right); } if(head.left != null){ stack.push(head.left); } } } System.out.println();} |
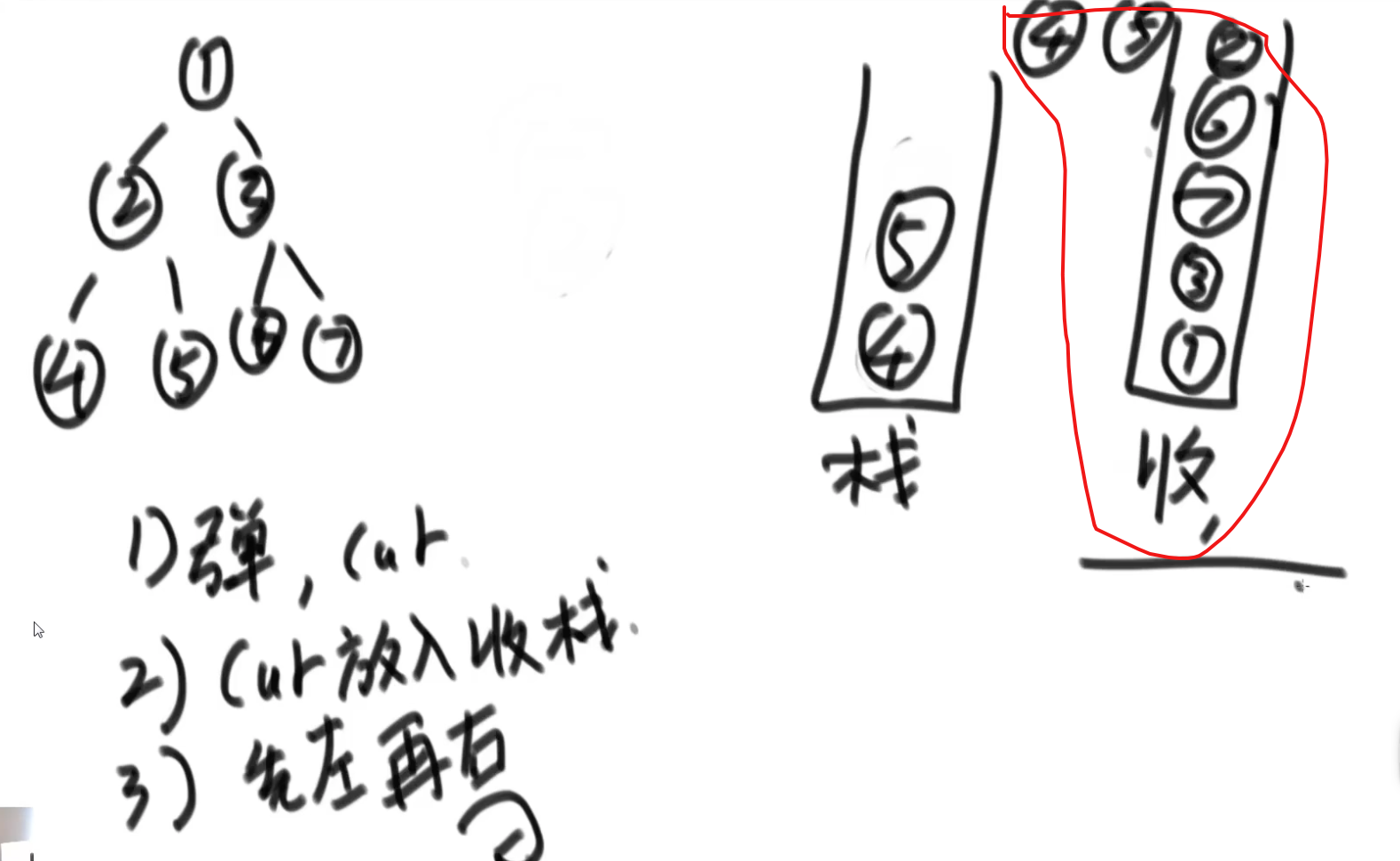
后序遍历:
1.当前节点current 弹出
2.把当前节点放到收集栈
3.先压左,再压右,没有左右直接走
4.周而复始
5.收集完之后,单独打印收集栈里面的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 | //后序遍历public static void posOrderUnRecur(Node head){ System.out.println("pos-order:"); if(head != null){ Stack<Node> stack = new Stack<Node>(); Stack<Node> newStack = new Stack<Node>(); stack.push(head); while (!stack.isEmpty()){ head = stack.pop(); newStack.push(head); System.out.println(head.value+""); if(head.left!= null){ stack.push(head.left); } if(head.right!= null){ stack.push(head.right); } } while (!newStack.isEmpty()){ System.out.println(newStack.pop().value +""); } } System.out.println();} |
1 2 3 4 5 6 7 8 | public void postOrder(TreeNode root){ if(root == null){ return; } postOrder(root.left); postOrder(root.right); system.out.println(root.data);} |
中序遍历:
先左,再头,再右
每棵子树 ,整棵树左边界进栈,依次弹出的过程中,打印,对弹出节点的右树重复。
4,2,5,1,6,3,7
1,2,4 进栈,每一次弹一个节点,4弹出,打印4 ,4 没有右树,弹出2,打印,2有右树5,5 进栈,5 弹出,打印5 ,5没有右树,弹出1,打印1,1有右树3,3,6 进栈。
弹出6,打印6 ,6没有右树,弹出3,打印3,3有右树7,弹出7 打印7, 7无右树,整个栈弹空。

1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 | //中序遍历public static void inOrderUnRecur(Node head){ System.out.println("in-order:"); if(head != null){ Stack<Node> stack = new Stack<Node>(); while (!stack.isEmpty() || head != null) { if (head != null) { stack.push(head); //左边界进栈 head = head.left;//左边界全压 } else { head = stack.pop();//没有左边界,弹出节点 System.out.println(head.value + ""); head = head.right;//移动到右 压右 } } } System.out.println();}<br><br> |
1 2 3 4 5 6 7 8 | public void inOrder(TreeNode root){ if(root == null){ return; } inOrder(root.left); system.out.println(root.data); inOrder(root.right);} |
二叉树的先序遍历,就是深度遍历。
宽度遍历用队列,先进先出。
先左 后右,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | public static void wide(Node head){ if (head ==null) { return; } Queue<Node> queue = new LinkedList<>(); queue.add(head); while (!queue.isEmpty()){ Node cur = queue.poll(); System.out.println(cur.value); if(cur.left !=null){ queue.add(cur.left); } if(cur.right !=null){ queue.add(cur.right); } }} |
求一棵二叉树的最大宽度:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 | public static int maxWidth(Node head){ if (head ==null) { return 0; } Queue<Node> queue = new LinkedList<>(); queue.add(head); HashMap<Node,Integer> levelMap = new HashMap<>(); levelMap.put(head,1); int curLevel = 1; int curLevelNodes = 0; int max = Integer.MIN_VALUE; while (!queue.isEmpty()){ Node cur = queue.poll(); int curNodeLevel = levelMap.get(cur); if(curNodeLevel == curLevel){ curLevelNodes++; }else{ max = Math.max(max,curLevelNodes); curLevel++; curLevelNodes = 1; } // System.out.println(cur.value); if(cur.left !=null){ levelMap.put(cur.left,curNodeLevel+1); queue.add(cur.left); } if(cur.right !=null){ levelMap.put(cur.right,curNodeLevel+1); queue.add(cur.right); } } return max;} |
什么是堆?
堆(英语:heap)是计算机科学中一类特殊的数据结构的统称。堆通常是一个可以被看做一棵树的数组对象。堆总是满足下列性质:
堆中的每一个节点值都大于等于(或小于等于)子树中所有节点的值。或者说,任意一个节点的值都大于等于(或小于等于)所有子节点的值。
1 | 大家可以把堆(最大堆)理解为一个公司,这个公司很公平,谁能力强谁就当老大,不存在弱的人当老大,老大手底下的人一定不会比他强。这样有助于理解后续堆的操作。 |
!!!特别提示:
- 很多博客说堆是完全二叉树,其实并非如此,堆不一定是完全二叉树,只是为了方便存储和索引,我们通常用完全二叉树的形式来表示堆,事实上,广为人知的斐波那契堆和二项堆就不是完全二叉树,它们甚至都不是二叉树。
- (二叉)堆是一个数组,它可以被看成是一个 近似的完全二叉树。——《算法导论》第三版
将根节点最大的堆叫做最大堆或大根堆,根节点最小的堆叫做最小堆或小根堆。常见的堆有二叉堆、斐波那契堆等。
大家可以尝试判断下面给出的图是否是堆?
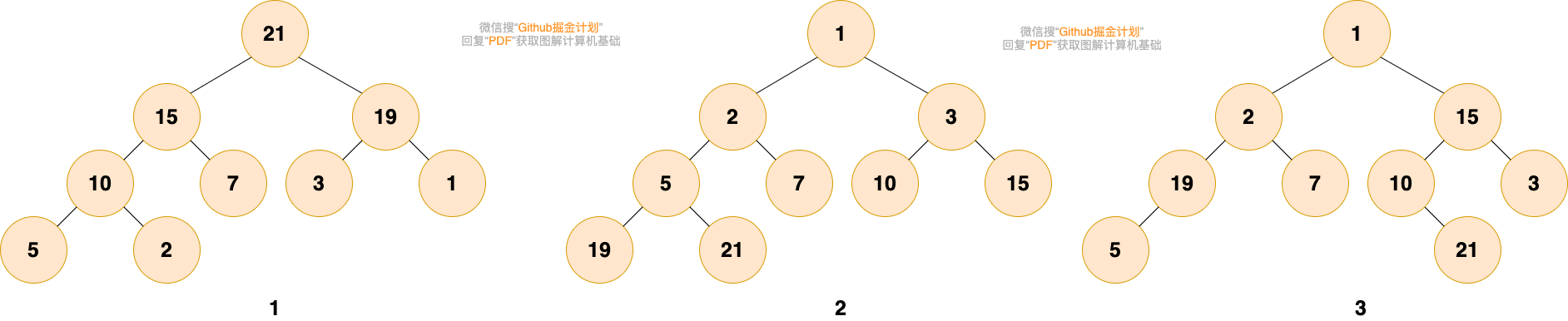
第1个和第2个是堆。第1个是最大堆,每个节点都比子树中所有节点大。第2个是最小堆,每个节点都比子树中所有节点小。
第3个不是,第三个中,根结点1比2和15小,而15却比3大,19比5大,不满足堆的性质。
堆的用途
当我们只关心所有数据中的最大值或者最小值,存在多次获取最大值或者最小值,多次插入或删除数据时,就可以使用堆。
有小伙伴可能会想到用有序数组,初始化一个有序数组时间复杂度是 O(nlog(n)),查找最大值或者最小值时间复杂度都是 O(1),但是,涉及到更新(插入或删除)数据时,时间复杂度为 O(n),即使是使用复杂度为 O(log(n)) 的二分法找到要插入或者删除的数据,在移动数据时也需要 O(n) 的时间复杂度。
相对于有序数组而言,堆的主要优势在于更新数据效率较高。 堆的初始化时间复杂度为 O(nlog(n)),堆可以做到O(1)时间复杂度取出最大值或者最小值,O(log(n))时间复杂度插入或者删除数据,具体操作在后续章节详细介绍。
堆的分类
堆分为 最大堆 和 最小堆。二者的区别在于节点的排序方式。
- 最大堆 :堆中的每一个节点的值都大于等于子树中所有节点的值
- 最小堆 :堆中的每一个节点的值都小于等于子树中所有节点的值
如下图所示,图1是最大堆,图2是最小堆

堆的存储
之前介绍树的时候说过,由于完全二叉树的优秀性质,利用数组存储二叉树即节省空间,又方便索引(若根结点的序号为1,那么对于树中任意节点i,其左子节点序号为 2*i,右子节点序号为 2*i+1)。
为了方便存储和索引,(二叉)堆可以用完全二叉树的形式进行存储。存储的方式如下图所示:

堆的操作
堆的更新操作主要包括两种 : 插入元素 和 删除堆顶元素。操作过程需要着重掌握和理解。
在进入正题之前,再重申一遍,堆是一个公平的公司,有能力的人自然会走到与他能力所匹配的位置
插入元素
插入元素,作为一个新入职的员工,初来乍到,这个员工需要从基层做起
每次插入都是将先将新数据放在数组最后,由于从这个新数据的父结点到根结点必然为一个有序的序列,现在的任务是将这个新数据插入到这个有序序列中——这就类似于直接插入排序中将一个数据并入到有序区间中。
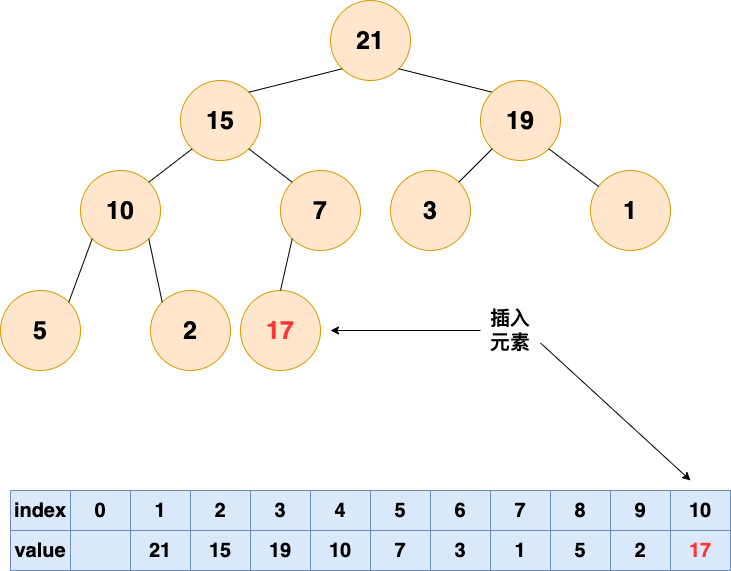
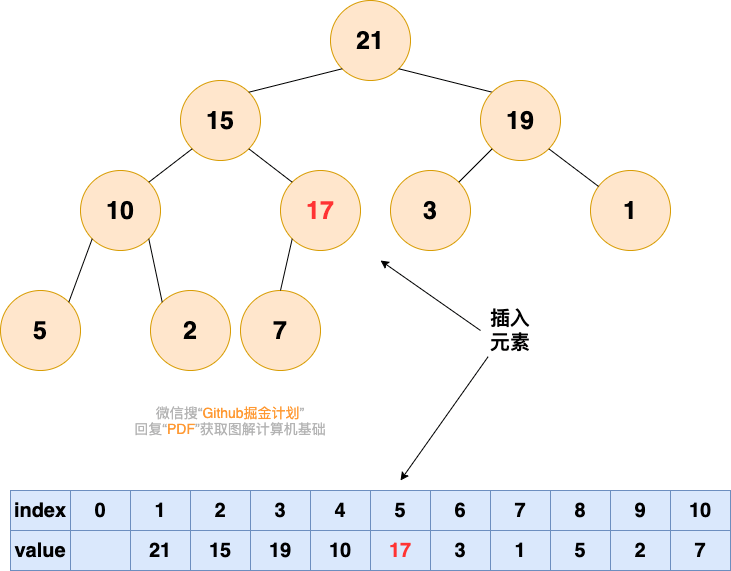
我们通过一个插入例子来看看插入操作的细节。我们将数字 16 插入到这个堆中:
堆的数组是: [ 10, 7, 2, 5, 1 ]。
第一步是将新的元素插入到数组的尾部,数组变成:[ 10, 7, 2, 5, 1, 16 ];
相应的树变成了:
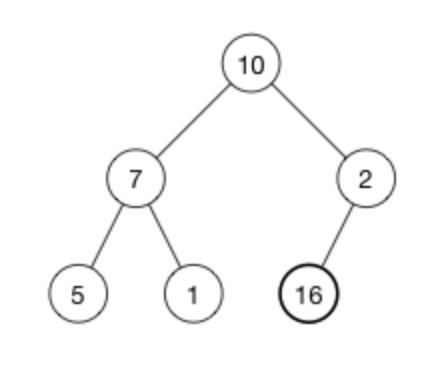
16 被添加最后一行的第一个空位。
不行的是,现在堆属性不满足,因为 2 在 16 的上面,我们需要将大的数字在上面(这是一个最大堆)
为了恢复堆属性,我们需要交换 16 和 2。

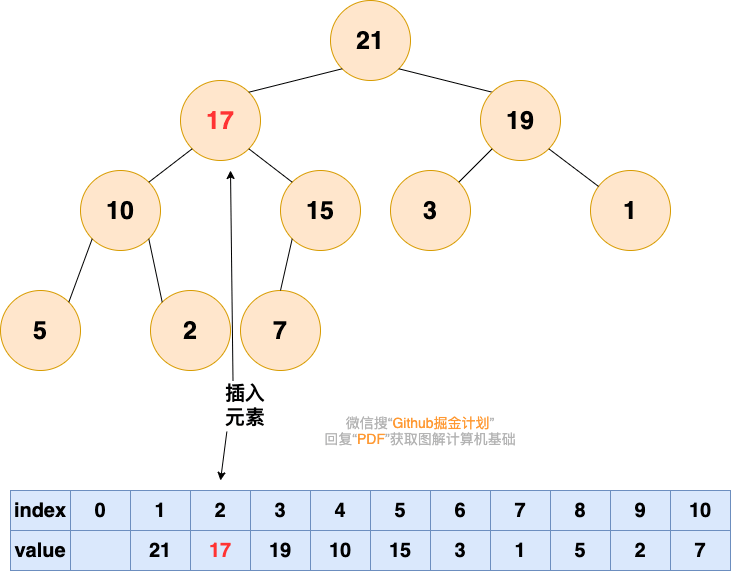
现在还没有完成,因为 10 也比 16 小。我们继续交换我们的插入元素和它的父节点,直到它的父节点比它大或者我们到达树的顶部。这就是所谓的 shift-up,每一次插入操作后都需要进行。它将一个太大或者太小的数字“浮起”到树的顶部。
最后我们得到的堆:

现在每一个父节点都比它的子节点大。
再举个例子:
1.将要插入的元素放到最后
有能力的人会逐渐升职加薪,是金子总会发光的!!!
2.从底向上,如果父结点比该元素小,则该节点和父结点交换,直到无法交换
堆的删除:
删除堆顶元素
根据堆的性质可知,最大堆的堆顶元素为所有元素中最大的,最小堆的堆顶元素是所有元素中最小的。当我们需要多次查找最大元素或者最小元素的时候,可以利用堆来实现。
删除堆顶元素后,为了保持堆的性质,需要对堆的结构进行调整,我们将这个过程称之为"堆化",堆化的方法分为两种:
- 一种是自底向上的堆化,上述的插入元素所使用的就是自底向上的堆化,元素从最底部向上移动。
- 另一种是自顶向下堆化,元素由最顶部向下移动。在讲解删除堆顶元素的方法时,我将阐述这两种操作的过程,大家可以体会一下二者的不同。
自底向上堆化
在堆这个公司中,会出现老大离职的现象,老大离职之后,他的位置就空出来了
首先删除堆顶元素,使得数组中下标为1的位置空出。
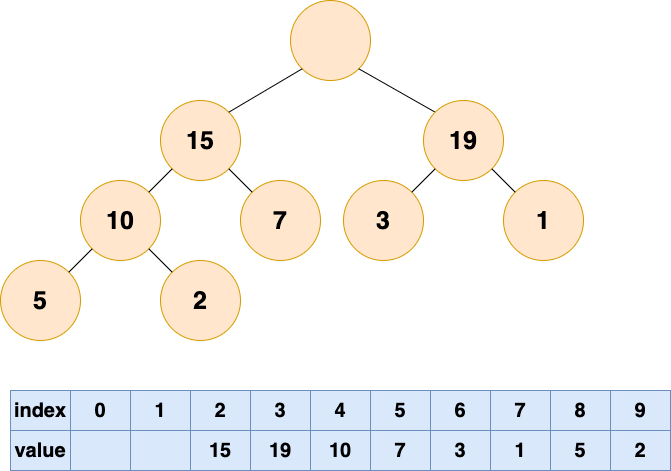
那么他的位置由谁来接替呢,当然是他的直接下属了,谁能力强就让谁上呗
比较根结点的左子节点和右子节点,也就是下标为2,3的数组元素,将较大的元素填充到根结点(下标为1)的位置。

这个时候又空出一个位置了,老规矩,谁有能力谁上
一直循环比较空出位置的左右子节点,并将较大者移至空位,直到堆的最底部

这个时候已经完成了自底向上的堆化,没有元素可以填补空缺了,但是,我们可以看到数组中出现了“气泡”,这会导致存储空间的浪费。接下来我们试试自顶向下堆化。
自顶向下堆化
自顶向下的堆化用一个词形容就是“石沉大海”,那么第一件事情,就是把石头抬起来,从海面扔下去。这个石头就是堆的最后一个元素,我们将最后一个元素移动到堆顶。
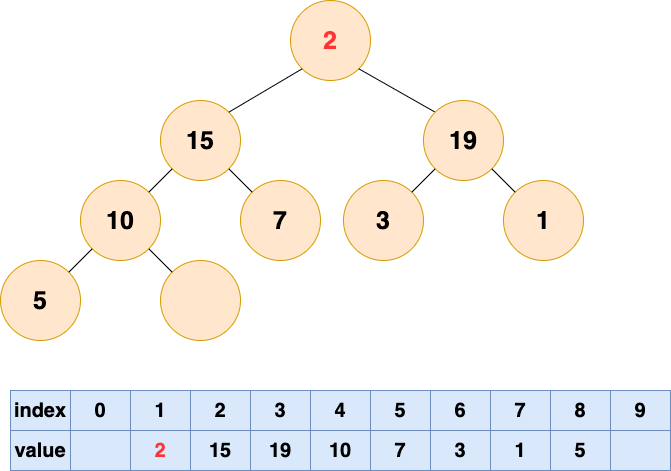
然后开始将这个石头沉入海底,不停与左右子节点的值进行比较,和较大的子节点交换位置,直到无法交换位置。
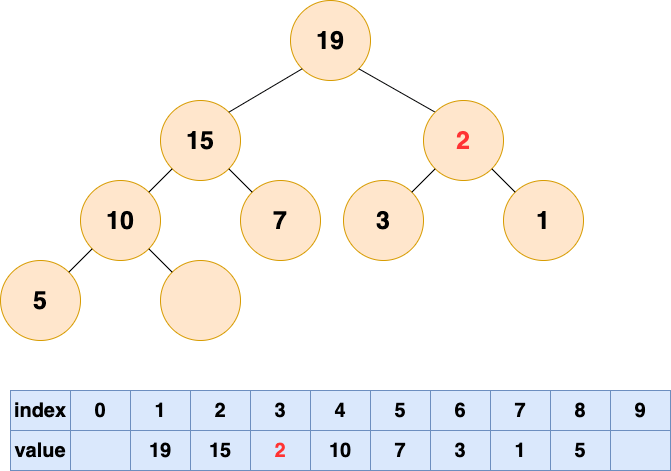
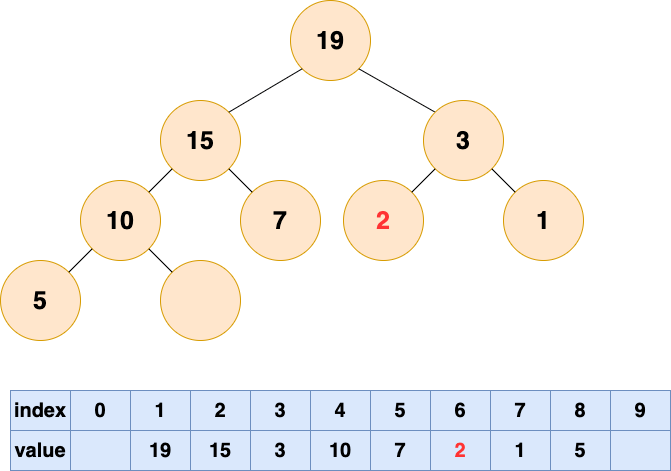
堆的操作总结
- 插入元素 :先将元素放至数组末尾,再自底向上堆化,将末尾元素上浮
- 删除堆顶元素 :删除堆顶元素,将末尾元素放至堆顶,再自顶向下堆化,将堆顶元素下沉。也可以自底向上堆化,只是会产生“气泡”,浪费存储空间。最好采用自顶向下堆化的方式。
堆排序
堆排序的过程分为两步:
- 第一步是建堆,将一个无序的数组建立为一个堆
- 第二步是排序,将堆顶元素取出,然后对剩下的元素进行堆化,反复迭代,直到所有元素被取出为止。
建堆
如果你已经足够了解堆化的过程,那么建堆的过程掌握起来就比较容易了。建堆的过程就是一个对所有非叶节点的自顶向下堆化过程。
首先要了解哪些是非叶节点,最后一个节点的父结点及它之前的元素,都是非叶节点。也就是说,如果节点个数为n,那么我们需要对n/2到1的节点进行自顶向下(沉底)堆化。
具体过程如下图:
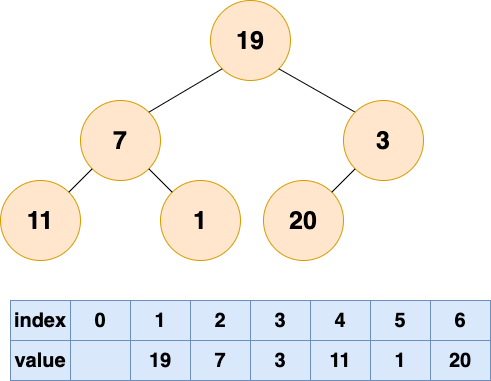
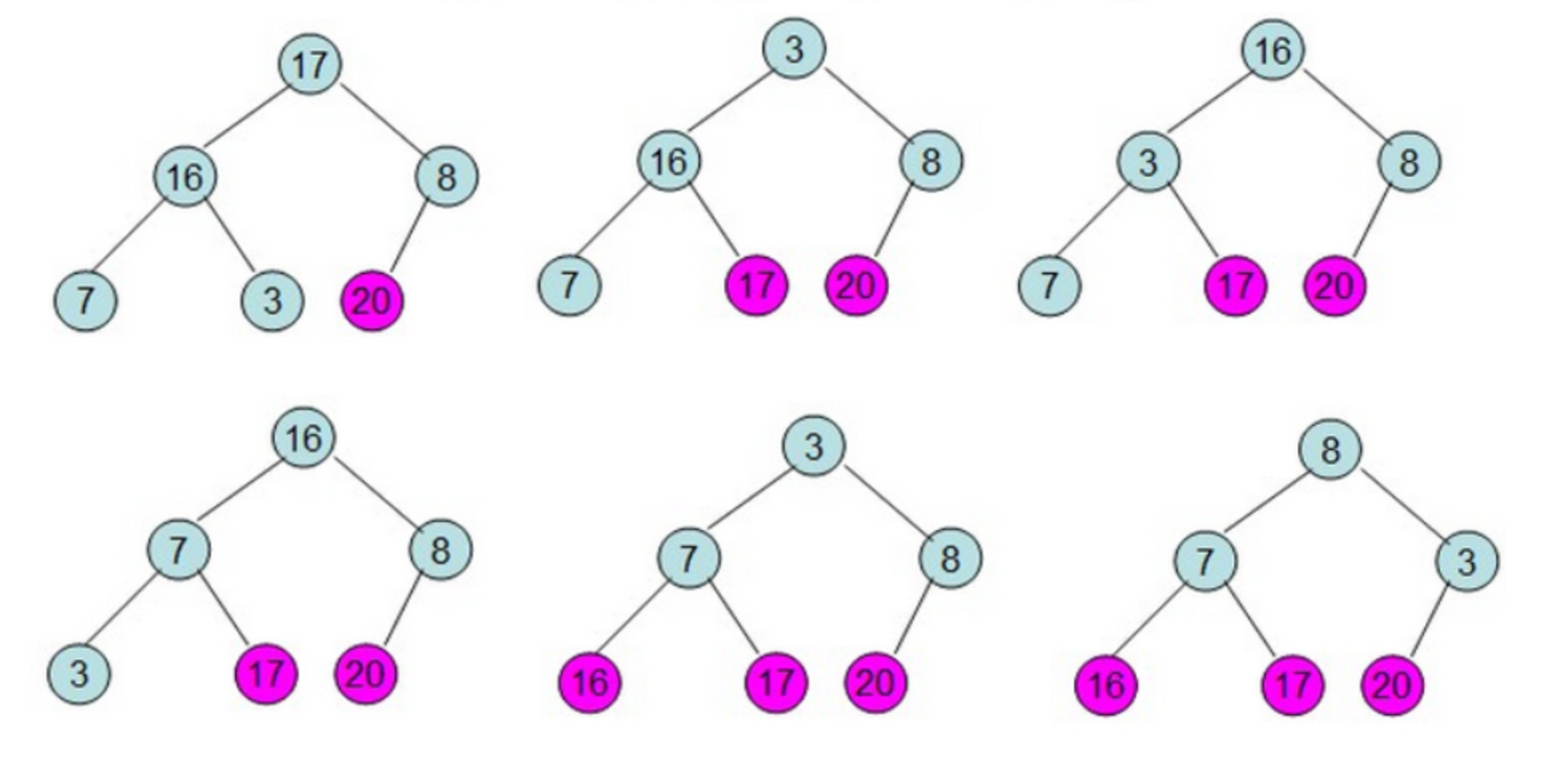
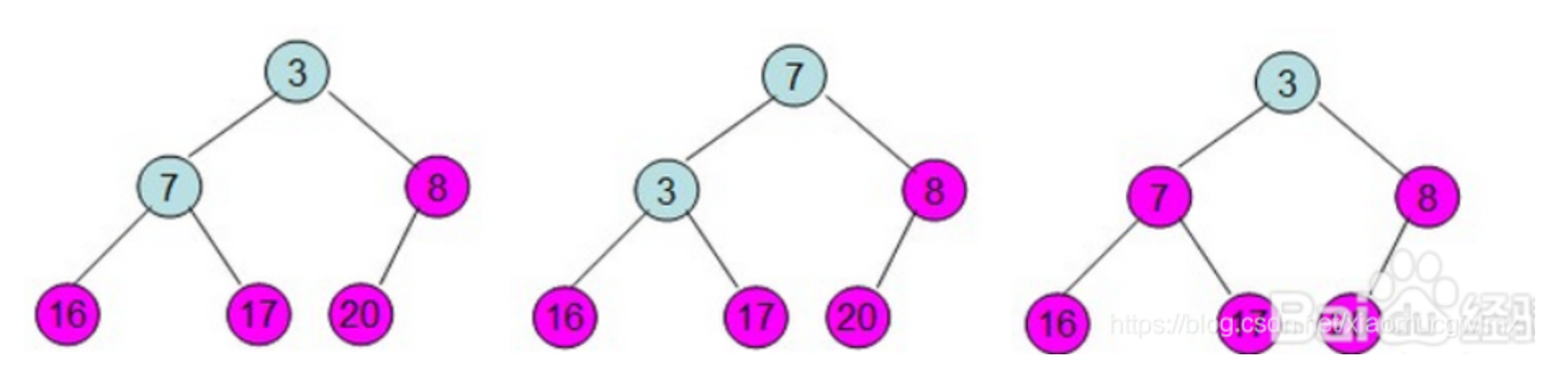
将初始的无序数组抽象为一棵树,图中的节点个数为6,所以4,5,6节点为叶节点,1,2,3节点为非叶节点,所以要对1-3号节点进行自顶向下(沉底)堆化,注意,顺序是从后往前堆化,从3号节点开始,一直到1号节点。 3号节点堆化结果:

2号节点堆化结果:

1号节点堆化结果:
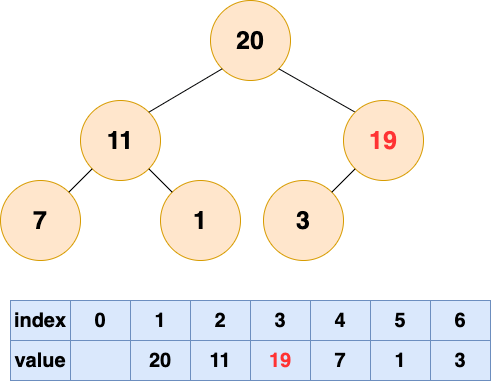
至此,数组所对应的树已经成为了一个最大堆,建堆完成!
基本思想:
首先将每个叶子节点视为一个堆,再将每个叶子节点与其父节点一起构造成一个包含更多节点的对。所以,在构造堆的时候,首先需要找到最后一个节点的父节点,从这个节点开始构造最大堆;直到该节点前面所有分支节点都处理完毕,这样最大堆就构造完毕了。
假设树的节点个数为n,以1为下标开始编号,直到n结束。对于节点i,其父节点为i/2;左孩子节点为i*2,右孩子节点为i*2+1。最后一个节点的下标为n,其父节点的下标为n/2。
我们边针对上边数组操作如下图所示,最后一个节点为7,其父节点为16,从16这个节点开始构造最大堆;构造完毕之后,转移到下一个父节点2,直到所有父节点都构造完毕。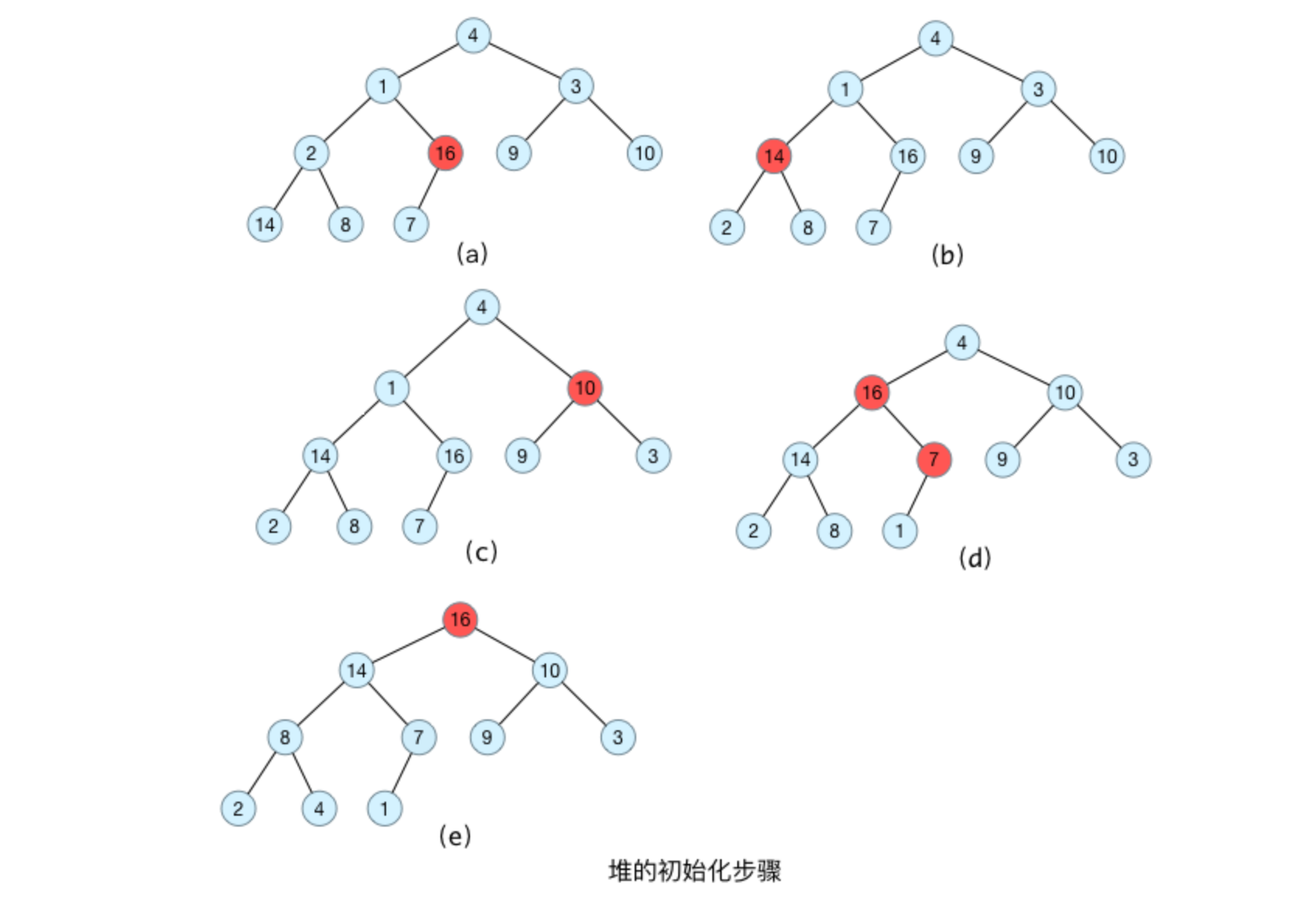
代码实现如下:

strcut MaxHeap { Etype *heap; //数据元素存放的空间,下标从1开始存数数据,下标为0的作为工作空间,存储临时数据 int HeapSize;//数据元素的个数 int MaxSize; //存放数据元素空间的大小 }; MaxHeap H; void MaxHeapInit (MaxHeap &H) { for(int i = H.HeapSize/2; i>=1; i--) { H.heap[0] = H.heap[i]; int son = i*2; while(son <= H.HeapSize) { if(son < H.HeapSize && H.heap[son] < H.heap[son+1]) son++; if(H.heap[0] >= H.heap[son]) break; else { H.heap[son/2] = H.heap[son]; son *= 2; } } H.heap[son/2] = H.heap[0]; } }
排序
由于堆顶元素是所有元素中最大的,所以我们重复取出堆顶元素,将这个最大的堆顶元素放至数组末尾,并对剩下的元素进行堆化即可。
现在思考两个问题:
- 删除堆顶元素后需要执行自顶向下(沉底)堆化还是自底向上(上浮)堆化?
- 取出的堆顶元素存在哪,新建一个数组存?
先回答第一个问题,我们需要执行自顶向下(沉底)堆化,这个堆化一开始要将末尾元素移动至堆顶,这个时候末尾的位置就空出来了,由于堆中元素已经减小,这个位置不会再被使用,所以我们可以将取出的元素放在末尾。
机智的小伙伴已经发现了,这其实是做了一次交换操作,将堆顶和末尾元素调换位置,从而将取出堆顶元素和堆化的第一步(将末尾元素放至根结点位置)进行合并。
详细过程如下图所示:
取出第一个元素并堆化:
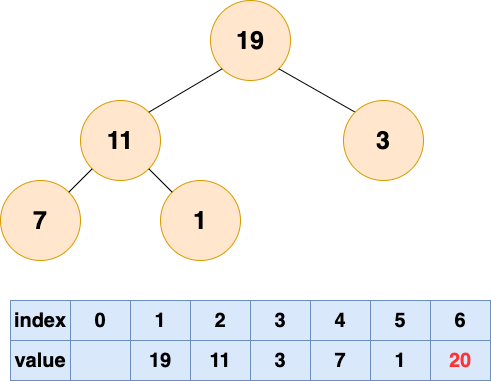
取出第二个元素并堆化:
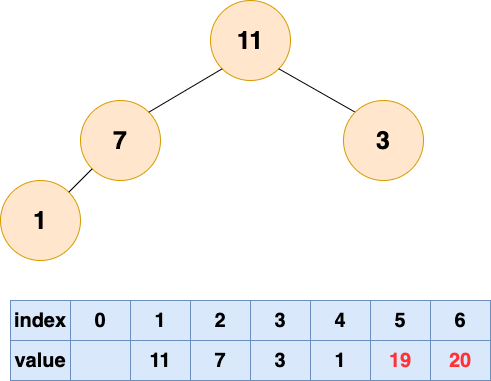
取出第三个元素并堆化:

取出第四个元素并堆化:
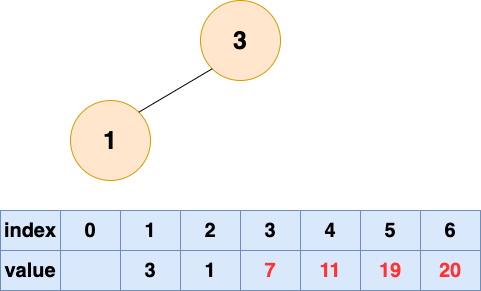
取出第五个元素并堆化:
取出第六个元素并堆化:

堆排序完成!
下面我们举个例子:
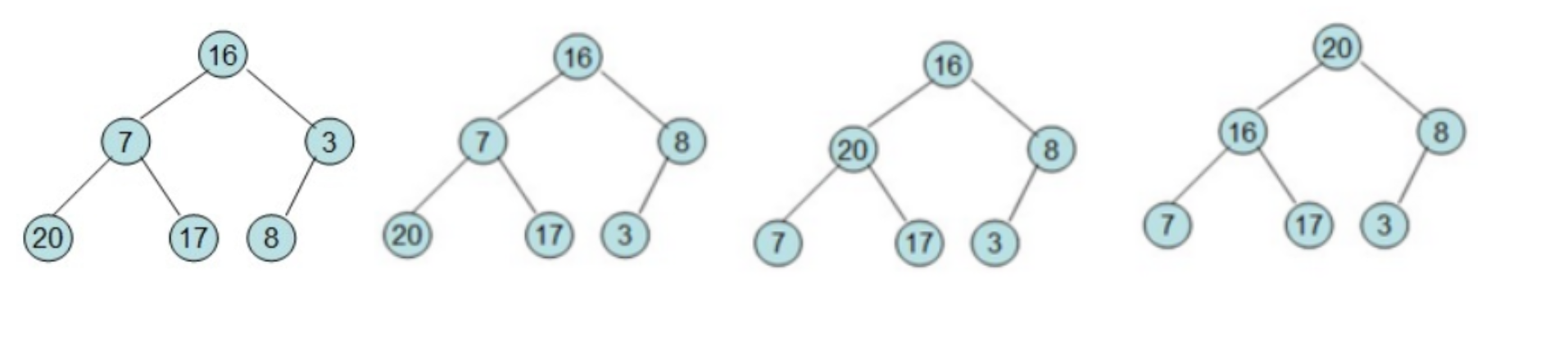
给定一个整形数组a[]={16,7,3,20,17,8},对其进行堆排序。
堆排序是借助堆来实现的选择排序,思想同简单的选择排序,以下以大顶堆为例。注意:如果想升序排序就使用大顶堆,反之使用小顶堆。原因是堆顶元素需要交换到序列尾部。
首先,实现堆排序需要解决两个问题:
1. 如何由一个无序序列键成一个堆?
2. 如何在输出堆顶元素之后,调整剩余元素成为一个新的堆?
第一个问题,可以直接使用线性数组来表示一个堆,由初始的无序序列建成一个堆就需要自底向上从第一个非叶元素开始挨个调整成一个堆。
第二个问题,怎么调整成堆?首先是将堆顶元素和最后一个元素交换。然后比较当前堆顶元素的左右孩子节点,因为除了当前的堆顶元素,左右孩子堆均满足条件,这时需要选择当前堆顶元素与左右孩子节点的较大者(大顶堆)交换,直至叶子节点。我们称这个自堆顶自叶子的调整成为筛选。
从一个无序序列建堆的过程就是一个反复筛选的过程。若将此序列看成是一个完全二叉树,则最后一个非终端节点是n/2取底个元素,由此筛选即可。举个栗子:
49,38,65,97,76,13,27,49序列的堆排序建初始堆和调整的过程如下:
动图演示:
(1)动画从一排数字开始
(2)先将一排数字放入数组(这个数组看做堆),显然这个堆是不满足条件的
(3)从最后一个父节点开始对堆进行调整(heapify)使其满足堆的性质(绿色代表调整好了,浅蓝色表示正在调整)
(4)堆构建结束后将堆顶元素与最后一个节点交换,将最大值放在最后(红色元素),剩下的n-1个元素堆的性质被破坏,需要重新做一次heapify使前n-1个元素满足堆的性质,从而循环(4)这个过程实现堆排序
首先根据该数组元素构建一个完全二叉树,具体过程如下(从左到右,从上到下按顺序一步一步的详细过程):

2.最大堆插入节点
最大堆的插入节点的思想就是先在堆的最后添加一个节点,然后沿着堆树上升。跟最大堆的初始化过程大致相同。
1 2 3 4 5 6 7 8 9 10 11 12 13 | void MaxHeapInsert (MaxHeap &H, EType &x){ if(H.HeapSize == H.MaxSize) return false; int i = ++H.HeapSize; while(i!=1 && x>H.heap[i/2]) { H.heap[i] = H.heap[i/2]; i = i/2; } H.heap[i] = x; return true;} |
3.最大堆堆顶节点删除
最大堆堆顶节点删除思想如下:将堆树的最后的节点提到根结点,然后删除最大值,然后再把新的根节点放到合适的位置。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | void MaxHeapDelete (MaxHeap &H, EType &x){ if(H.HeapSize == 0) return false; x = H.heap[1]; H.heap[0] = H.heap[H.HeapSize--]; int i = 1, son = i*2; while(son <= H.HeapSize) { if(son <= H.HeapSize && H.heap[0] < H.heap[son+1]) son++; if(H.heap[0] >= H.heap[son]) break; H.heap[i] = H.heap[son]; i = son; son = son*2; } H.heap[i] = H.heap[0]; return true;} |
最小堆
整体操作和最大堆类似,这里不做赘述。
应用场景:
海量数据中找出前k大数(topk问题)
先拿10000个数建堆,然后依次添加剩余元素,如果大于堆顶的数(10000中最小的),将这个数替换堆顶,并调整结构使之仍然是一个最小堆,这样,遍历完后,堆中的10000个数就是所需的最大的10000个。建堆时间复杂度是O(mlogm),算法的时间复杂度为O(nmlogm)(n为10亿,m为10000)。
优化的方法:可以把所有10亿个数据分组存放,比如分别放在1000个文件中。这样处理就可以分别在每个文件的10^6个数据中找出最大的10000个数,合并到一起在再找出最终的结果。
下面整理一下这方面的问题:
top K问题
在大规模数据处理中,经常会遇到的一类问题:在海量数据中找出出现频率最好的前k个数,或者从海量数据中找出最大的前k个数,这类问题通常被称为top K问题。例如,在搜索引擎中,统计搜索最热门的10个查询词;在歌曲库中统计下载最高的前10首歌等。
针对top K类问题,通常比较好的方案是分治+Trie树/hash+小顶堆(就是上面提到的最小堆),即先将数据集按照Hash方法分解成多个小数据集,然后使用Trie树活着Hash统计每个小数据集中的query词频,之后用小顶堆求出每个数据集中出现频率最高的前K个数,最后在所有top K中求出最终的top K。
例如:有1亿个浮点数,如果找出其中最大的10000个?
最容易想到的方法是将数据全部排序,然后在排序后的集合中进行查找,最快的排序算法的时间复杂度一般为O(nlogn),如快速排序。但是在32位的机器上,每个float类型占4个字节,1亿个浮点数就要占用400MB的存储空间,对于一些可用内存小于400M的计算机而言,很显然是不能一次将全部数据读入内存进行排序的。其实即使内存能够满足要求(我机器内存都是8GB),该方法也并不高效,因为题目的目的是寻找出最大的10000个数即可,而排序却是将所有的元素都排序了,做了很多的无用功。
第二种方法为局部淘汰法,该方法与排序方法类似,用一个容器保存前10000个数,然后将剩余的所有数字——与容器内的最小数字相比,如果所有后续的元素都比容器内的10000个数还小,那么容器内这个10000个数就是最大10000个数。如果某一后续元素比容器内最小数字大,则删掉容器内最小元素,并将该元素插入容器,最后遍历完这1亿个数,得到的结果容器中保存的数即为最终结果了。此时的时间复杂度为O(n+m^2),其中m为容器的大小,即10000。
第三种方法是分治法,将1亿个数据分成100份,每份100万个数据,找到每份数据中最大的10000个,最后在剩下的100*10000个数据里面找出最大的10000个。如果100万数据选择足够理想,那么可以过滤掉1亿数据里面99%的数据。100万个数据里面查找最大的10000个数据的方法如下:用快速排序的方法,将数据分为2堆,如果大的那堆个数N大于10000个,继续对大堆快速排序一次分成2堆,如果大的那堆个数N大于10000个,继续对大堆快速排序一次分成2堆,如果大堆个数N小于10000个,就在小的那堆里面快速排序一次,找第10000-n大的数字;递归以上过程,就可以找到第1w大的数。参考上面的找出第1w大数字,就可以类似的方法找到前10000大数字了。此种方法需要每次的内存空间为10^6*4=4MB,一共需要101次这样的比较。
第四种方法是Hash法。如果这1亿个书里面有很多重复的数,先通过Hash法,把这1亿个数字去重复,这样如果重复率很高的话,会减少很大的内存用量,从而缩小运算空间,然后通过分治法或最小堆法查找最大的10000个数。
第五种方法采用最小堆。首先读入前10000个数来创建大小为10000的最小堆,建堆的时间复杂度为O(mlogm)(m为数组的大小即为10000),然后遍历后续的数字,并于堆顶(最小)数字进行比较。如果比最小的数小,则继续读取后续数字;如果比堆顶数字大,则替换堆顶元素并重新调整堆为最小堆。整个过程直至1亿个数全部遍历完为止。然后按照中序遍历的方式输出当前堆中的所有10000个数字。该算法的时间复杂度为O(nmlogm),空间复杂度是10000(常数)。
实际运行:
实际上,最优的解决方案应该是最符合实际设计需求的方案,在时间应用中,可能有足够大的内存,那么直接将数据扔到内存中一次性处理即可,也可能机器有多个核,这样可以采用多线程处理整个数据集。
下面针对不容的应用场景,分析了适合相应应用场景的解决方案。(1)单机+单核+足够大内存
如果需要查找10亿个查询次(每个占8B)中出现频率最高的10个,考虑到每个查询词占8B,则10亿个查询次所需的内存大约是10^9 * 8B=8GB内存。如果有这么大内存,直接在内存中对查询次进行排序,顺序遍历找出10个出现频率最大的即可。这种方法简单快速,使用。然后,也可以先用HashMap求出每个词出现的频率,然后求出频率最大的10个词。
(2)单机+多核+足够大内存
这时可以直接在内存总使用Hash方法将数据划分成n个partition,每个partition交给一个线程处理,线程的处理逻辑同(1)类似,最后一个线程将结果归并。
该方法存在一个瓶颈会明显影响效率,即数据倾斜。每个线程的处理速度可能不同,快的线程需要等待慢的线程,最终的处理速度取决于慢的线程。而针对此问题,解决的方法是,将数据划分成c×n个partition(c>1),
每个线程处理完当前partition后主动取下一个partition继续处理,知道所有数据处理完毕,最后由一个线程进行归并。(3)单机+单核+受限内存
这种情况下,需要将原数据文件切割成一个一个小文件,如次啊用hash(x)%M,将原文件中的数据切割成M小文件,如果小文件仍大于内存大小,继续采用Hash的方法对数据文件进行分割,知道每个小文件小于内存大小,这样每个文件可放到内存中处理。采用(1)的方法依次处理每个小文件。
(4)多机+受限内存
这种情况,为了合理利用多台机器的资源,可将数据分发到多台机器上,每台机器采用(3)中的策略解决本地的数据。可采用hash+socket方法进行数据分发。
从实际应用的角度考虑,(1)(2)(3)(4)方案并不可行,因为在大规模数据处理环境下,作业效率并不是首要考虑的问题,算法的扩展性和容错性才是首要考虑的。算法应该具有良好的扩展性,以便数据量进一步加大(随着业务的发展,数据量加大是必然的)时,在不修改算法框架的前提下,可达到近似的线性比;算法应该具有容错性,即当前某个文件处理失败后,能自动将其交给另外一个线程继续处理,而不是从头开始处理。
top K问题很适合采用MapReduce框架解决,用户只需编写一个Map函数和两个Reduce 函数,然后提交到Hadoop(采用Mapchain和Reducechain)上即可解决该问题。具体而言,就是首先根据数据值或者把数据hash(MD5)后的值按照范围划分到不同的机器上,最好可以让数据划分后一次读入内存,这样不同的机器负责处理不同的数值范围,实际上就是Map。得到结果后,各个机器只需拿出各自出现次数最多的前N个数据,然后汇总,选出所有的数据中出现次数最多的前N个数据,这实际上就是Reduce过程。对于Map函数,采用Hash算法,将Hash值相同的数据交给同一个Reduce task;对于第一个Reduce函数,采用HashMap统计出每个词出现的频率,对于第二个Reduce 函数,统计所有Reduce task,输出数据中的top K即可。
直接将数据均分到不同的机器上进行处理是无法得到正确的结果的。因为一个数据可能被均分到不同的机器上,而另一个则可能完全聚集到一个机器上,同时还可能存在具有相同数目的数据。
以下是一些经常被提及的该类问题。
(1)有10000000个记录,这些查询串的重复度比较高,如果除去重复后,不超过3000000个。一个查询串的重复度越高,说明查询它的用户越多,也就是越热门。请统计最热门的10个查询串,要求使用的内存不能超过1GB。
(2)有10个文件,每个文件1GB,每个文件的每一行存放的都是用户的query,每个文件的query都可能重复。按照query的频度排序。
(3)有一个1GB大小的文件,里面的每一行是一个词,词的大小不超过16个字节,内存限制大小是1MB。返回频数最高的100个词。
(4)提取某日访问网站次数最多的那个IP。
(5)10亿个整数找出重复次数最多的100个整数。
(6)搜索的输入信息是一个字符串,统计300万条输入信息中最热门的前10条,每次输入的一个字符串为不超过255B,内存使用只有1GB。
(7)有1000万个身份证号以及他们对应的数据,身份证号可能重复,找出出现次数最多的身份证号。
重复问题
在海量数据中查找出重复出现的元素或者去除重复出现的元素也是常考的问题。针对此类问题,一般可以通过位图法实现。例如,已知某个文件内包含一些电话号码,每个号码为8位数字,统计不同号码的个数。
本题最好的解决方法是通过使用位图法来实现。8位整数可以表示的最大十进制数值为99999999。如果每个数字对应于位图中一个bit位,那么存储8位整数大约需要99MB。因为1B=8bit,所以99Mbit折合成内存为99/8=12.375MB的内存,即可以只用12.375MB的内存表示所有的8位数电话号码的内容。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix