1.2 个人作业:软件案例分析
1.2 个人作业:软件案例分析
| 项目 | 内容 |
|---|---|
| 这个作业属于哪个课程 | 2025年春季软件工程(罗杰、任健) |
| 这个作业的要求在哪里 | [I.2] 个人作业:软件案例分析 |
| 我在这个课程的目标是 | 学习较为完整基础的软件开发流程,以及如何在软件工程中进行良好的团队协作 |
| 这个作业在哪个具体方面帮助我实现目标 | 帮助我理解RAG的核心组件,让我在后续团队开发的过程中可以更加高效 |
第一部分 调研与评测
一、选题
我选择的题目是“团队项目选题所针对的软件的案例分析”。主要分析的是由David Smiley开发的txtai,并分析了斯坦福大学开发的STORM,进行对比分析。
二、软件评测
txtai是由David Smiley开发的一款轻量级AI驱动的文本搜索和NLP处理库,主要功能有:语义搜索、向量检索、问答、分类摘要等。由于txtai结合了Faiss、Transformers以及pytorch等技术,适用于本地环境和云端部署。
1.本地环境部署
部署环境要求:
操作系统:
兼容Windows、Linux、macOS,推荐使用Linux服务器进行生产部署。
Python 版本:
支持Python 3.7及以上,推荐Python 3.9+以获得最佳性能。
部署指令:
在python终端,运行pip install txtai即可安装
2.软件使用
由于txtai的主要功能有:语义搜索、向量检索、问答、分类摘要等。所以在使用过程中,我尝试了不同的使用方法。
2.1语义搜索
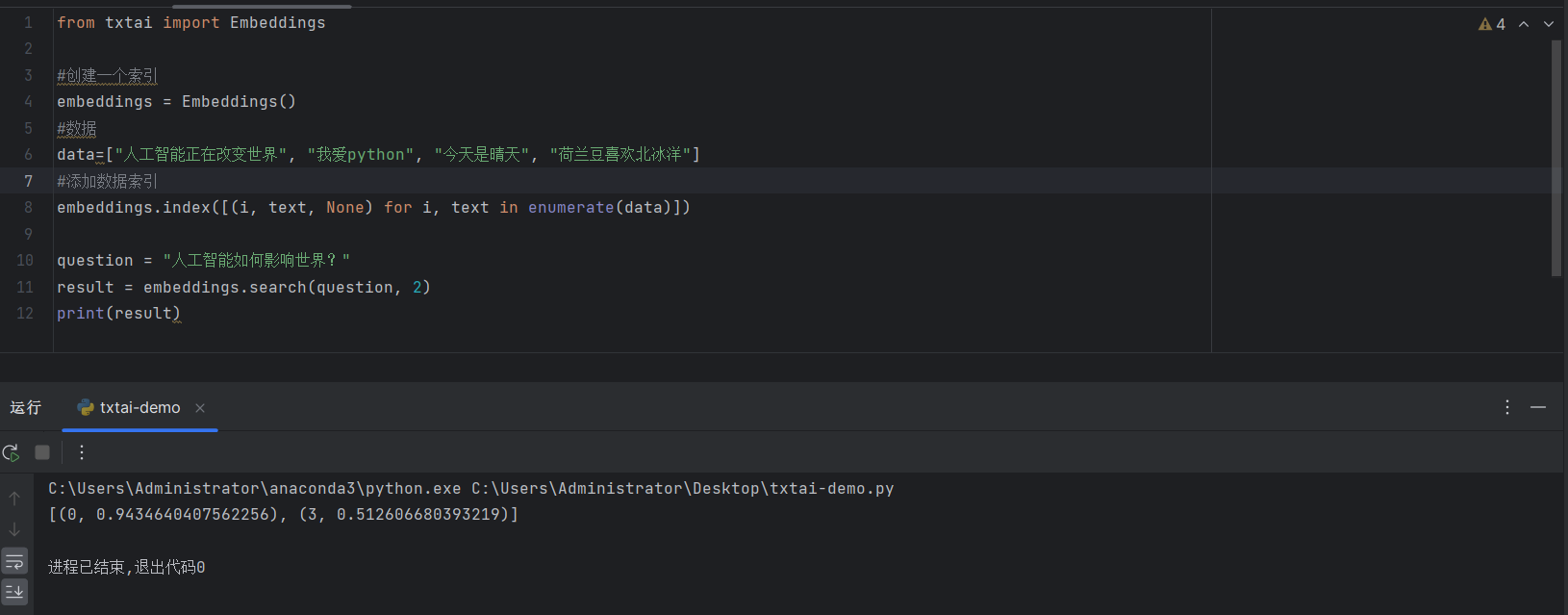
from txtai import Embeddings
#创建一个索引
embeddings = Embeddings()
#数据
data=["人工智能正在改变世界", "我爱python", "今天是晴天", "荷兰豆喜欢北冰洋"]
#添加数据索引
embeddings.index([(i, text, None) for i, text in enumerate(data)])
question = "人工智能如何影响世界?"
result = embeddings.search(question, 2)
print(result)
这个代码主要使用了txtai的嵌入索引和相似性搜索功能。其中,嵌入索引是通过index()方法对文本计算嵌入并存储。语义搜索通过search()方法基于语义相似性查询相关内容。
[(0,0.9434640407562256),(3,0.512606680393219)]
这个结果表示语义检索的匹配情况,具体含义如下:
- 0和3是数据索引,即在data列表中对应的文本索引位置。
- 0.9434640407562256和0.512606680393219是相似度分数(越接近1,匹配度越高)。
2.2基于语义检索(RAG)的问答系统
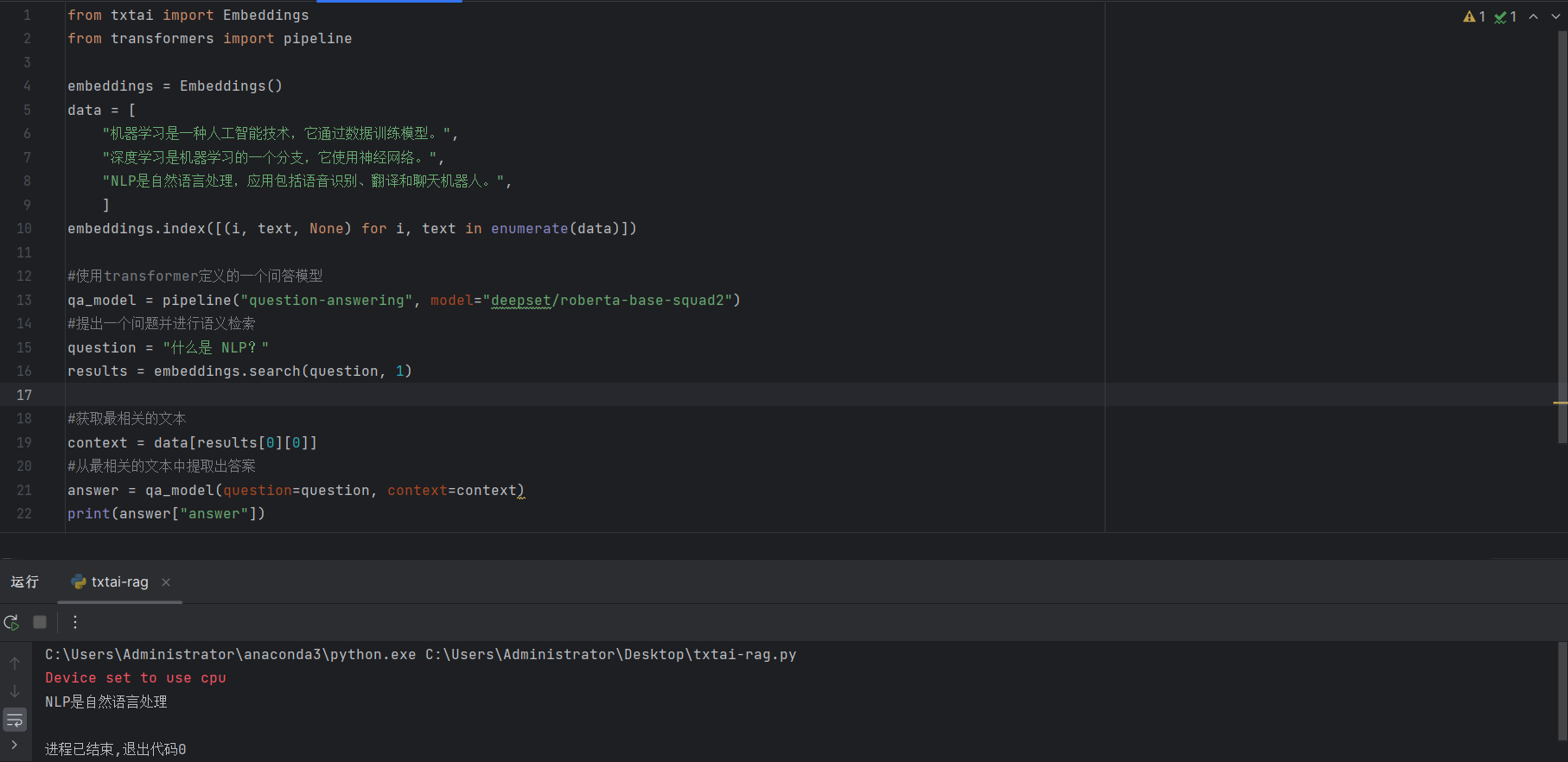
from txtai import Embeddings
from transformers import pipeline
embeddings = Embeddings()
data = [
"机器学习是一种人工智能技术,它通过数据训练模型。",
"深度学习是机器学习的一个分支,它使用神经网络。",
"NLP是自然语言处理,应用包括语音识别、翻译和聊天机器人。",
]
embeddings.index([(i, text, None) for i, text in enumerate(data)])
#使用transformer定义的一个问答模型
qa_model = pipeline("question-answering", model="deepset/roberta-base-squad2")
#提出一个问题并进行语义检索
question = "什么是 NLP?"
results = embeddings.search(question, 1)
#获取最相关的文本
context = data[results[0][0]]
#从最相关的文本中提取出答案
answer = qa_model(question=question, context=context)
print(answer["answer"])
这个代码使用了txtai的嵌入索引和相似性搜索并结合transformers库的问答模型来实现基于语义检索的问答系统,可以从检索到的最相关文本中提取出精准的答案。
NLP是自然语言处理
这是代码运行结果,得到最符合问题的答案。
2.3文本分类和索引功能
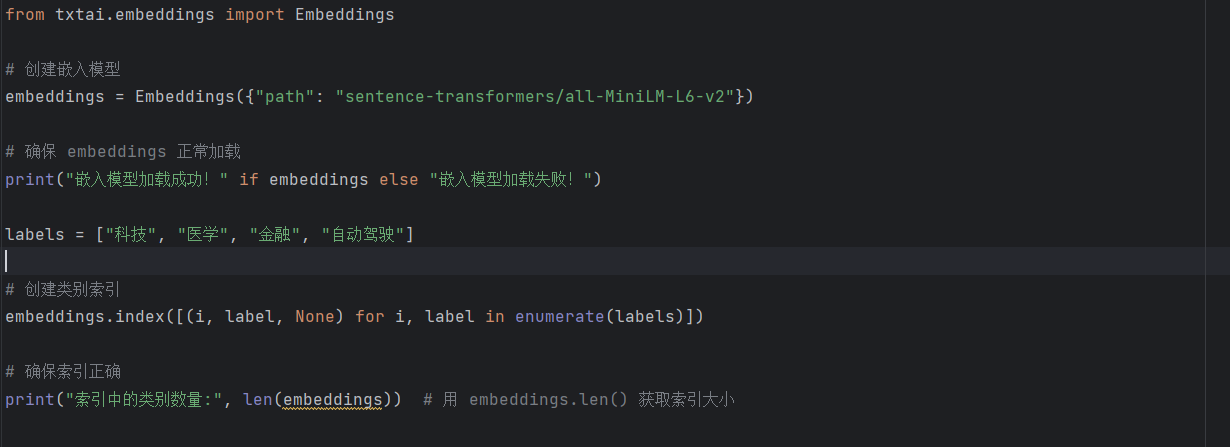
from txtai.embeddings import Embeddings
# 创建嵌入模型
embeddings = Embeddings({"path": "sentence-transformers/all-MiniLM-L6-v2"})
# 确保 embeddings 正常加载
print("嵌入模型加载成功!" if embeddings else "嵌入模型加载失败!")
labels = ["科技", "医学", "金融", "自动驾驶"]
# 创建类别索引
embeddings.index([(i, label, None) for i, label in enumerate(labels)])
# 确保索引正确
print("索引中的类别数量:", len(embeddings)) # 用 embeddings.len() 获取索引大小
这段代码通过index()方法将labels中的所有数据转换为向量,并存入索引中,以支持后续的义搜索、文本分类或推荐系统。
3.软件分析
3.1基本使用流程:
- 安装
txtai并导入相关模块 - 构建索引,添加文本数据
- 进行相似度搜索、问答或者文本分类等
- 解析搜索到的结果,提取出相关性最高的文本
3.2是否解决用户的需求
txtai是一款轻量级AI驱动的文本搜索和NLP处理库,主要是用于自然语言处理任务,如文本搜索、问答系统、分类等相关场景。对于需要高效文本检索和嵌入搜索的用户,txtai可以很好地满足需求。
3.3优缺点分析
| 分析角度 | 优点 | 缺点 |
|---|---|---|
| 数据量 | 可以支持大规模文本索引 | 需要手动优化索引参数 |
| 界面 | 提供API供用户调用使用 | 没有GUI界面,在一定程度上不够便捷 |
| 功能 | 语义搜索、向量检索、问答、分类摘要等 | 部分功能的依赖可能会冲突,使用过程问题较多 |
| 准确度 | 利用了transformers提高了文本匹配的精确度 | 受调用模型质量影响大,需要手动调整参数 |
| 用户体验 | 轻量级,部署简单 | 许多功能学习使用起来较为困难 |
4.改进意见
针对上述的优缺点分析,我认为可以有一下的改进意见:
- 可以提供Web UI,方便用户管理索引
- 对于用户文档,可以增加更多简单使用示例,便于初学者快速上手
- 在部署环境的过程中较为繁琐复杂,可以提供Docker预构建环境,让初学者可以更快完成环境配置
5.用户调研
在本次用户调研中,我选择采访了同样使用过txtai的zjc同学。

- Q:采访对象的背景,为什么选择这个人采访?TA 的需求是什么?
A:zjc同学是王德庆老师班级的学生,他曾经在某个项目的NLP应用开发上有相应的需求,需要使用文本搜索工具,便因此使用了txtai来解决他自己的需求。 - Q:采访对象实际使用的产品栏目
A:zjc同学只要是使用了txtai的文本搜索和问答系统的功能 - Q:采访对象使用软件的过程中会遇到的问题和亮点
A:zjc同学在使用的过程中,遇到的问题包括:需要手动调整索引参数以及使用txtai缺乏细粒度的权限控制。这和我的体验有着相似之处。同时他也反馈到,在体验过程中的亮点包括:轻量级,易于嵌入现有系统以及处理速度快,适用于大规模数据集。这些都符合txtai的优点。 - Q:采访对象觉得从用户体验的角度来说需要改进的地方有哪些?
A:zjc同学认为改进建议可以有:改进建议:增强索引管理功能,支持动态调整索引参数和提供Web UI,方便非开发者使用。
6.评测结论
评测结果:d) 好,不错
理由:txtai是一个轻量级的NLP解决方案,适用于需要高效文本搜索的开发者,但对于初学者而言,学习曲线较陡,需要改进文档和UI体验。
Bug 量化标准
- 五星:致命性系统故障、严重安全漏洞、用户体验极度受损,导致系统无法使用或大规模数据泄露。
- 四星:严重系统故障、服务器鉴权漏洞或重要数据泄露、用户体验较差,但仍可部分运行。
- 三星:影响功能正常使用,但有可行的绕过方案,不影响安全性。
- 二星:轻微影响系统功能,可能导致意外行为,但影响有限。
- 一星:无关紧要的小问题,不影响核心功能,仅影响美观或日志输出。
BUG分析1
测试环境
操作系统:Windows11
Python 版本:Python 3.10
bug现象
在txtai的词向量模块中,当前代码在处理字符串列表进行矢量化时,每一行都会被解析为一个标记token列表。然而,它没有正确处理“没有解析出任何标记”的情况,导致:如果输入字符串没有返回任何标记,原始字符串会被错误地作为标记列表传递。
原因分析
这个bug产生的概率为有可能触发。在文本向量化过程中,系统预期字符串能被拆分成一系列token进行处理。然而,在某些情况下,解析器可能会返回空列表,而现有代码未考虑这一情况,导致原始字符串直接作为token列表传递。
如下代码可能触发此bug:
from txtai.embeddings import Embeddings
import nltk
nltk.download("punkt")
from nltk.tokenize import word_tokenize
# 创建词向量实例
embeddings = Embeddings({"path": "sentence-transformers/all-MiniLM-L6-v2"})
# 修正方法
def tokenize(text):
tokens = word_tokenize(text)
return tokens if tokens else ["[UNK]"] # 处理空 token 情况
# 词向量化方法
def vectorize_texts(texts):
vectors = []
for text in texts:
tokens = tokenize(text)
vector = embeddings.embed(" ".join(tokens))
vectors.append(vector)
return vectors
texts = [
"Hello, world!",
"!!!", # 只包含标点
"", # 空字符串
" " # 只有空格
]
vectors = vectorize_texts(texts)
print(vectors)
bug严重性
此Bug并不会导致系统完全崩溃,但会影响模型的稳定性和一致性,尤其是对于依赖文本向量化的任务(如文本搜索、推荐系统等)。用户可能会发现某些文本的向量化结果与预期不符,影响实际使用效果。总体来说三星级别的bug。
为什么软件团队在发布前未能修复此Bug
我认为是因为开发者对用户需求掌握不够精确,默认所有文本输入都能被正确解析成 token,但忽略了空token情况。
bug改进建议
当解析出的token为空时,应给出合理的默认行为,而不是直接将原始字符串作为token处理。例如:抛出异常,提示用户输入无效或者设定一个合理的默认 token。
bug分析2
测试环境
操作系统:Windows11
Python 版本:Python 3.10
bug现象
当将ID作为目标传入时,该NetworkX.hasedge方法会出现问题。当将None或0作为边的目标ID时,程序会报错或返回意外的结果
原因分析
我认为是因为hasedge()可能期望输入的是有效的节点ID(如整数、字符串),但None或0可能未被正确处理。
import networkx as nx
from txtai.embeddings import Embeddings
# 创建向量数据库
embeddings = Embeddings()
embeddings.index([
(1, "This is a test sentence."),
(2, "Another test sentence."),
])
G = nx.Graph()
G.add_edge(1, 2) # 添加正常边
# 正常查询
print(G.has_edge(1, 2))
# **错误案例:传入None作为目标ID**
print(G.has_edge(1, None))
print(G.has_edge(None, 2))
print(G.has_edge(0, 2))
bug严重性
可能导致txtai相关功能异常,影响文本检索,影响使用体验。总体来说三星级别的bug。
为什么软件团队在发布前未能修复此Bug
可能未在has_edge()传入None或0的情况下进行充分测试,只在正常ID传递的情况下进行了测试。
bug改进建议
输入检查在txtai代码中,确保has_edge()传入的参数始终是有效ID。
第二部分 分析
1.工作量分析
假设开发团队6人,团队每周工作40h-45h,估算txtai的开发时间:
- NLP模型集成:3个月
- API设计与优化:2个月
- 文档编写与示例:1个月
- 测试与优化:1个月
2.软件质量分析
与类似软件相比
| 维度 | txtai | Elasticsearch | FAISS |
|---|---|---|---|
| 轻量级 | yes | no | yes |
| 部署难度 | 中 | 高 | 中 |
| 适用场景 | NLP搜索 | 通用搜索 | 向量搜索 |
软件质量排名(同类产品中)
若仅考虑NLP搜索,txtai处于中上水平。但与Elasticsearch相比,txtai适用于小型项目,不适合大规模分布式环境。总体来说,我认为txtai在同类产品中可以排名到第三名左右。
提高方面
改进点:用户体验优化
- 增加Web UI以降低使用门槛。
- 提供更详细的官方教程,涵盖不同的使用场景。
- 提供自动化性能评估工具,便于开发者选择合适的参数。
结论
txtai是一个优秀的NLP轻量级文本搜索工具,但仍有改进空间,特别是在UI和索引管理方面。
第三部分 建议和规划
1.市场现状
1.1市场概况:
在github的官网上,txtai源码的star数已经超过10k。它主要面向需要文本搜索、问答和分类的开发者市场。由于其开源性质,txtai 的直接用户主要是全球范围内的开发者和企业。然而,具体的用户数量并未公开,因此无法提供准确的直接用户数量。直接用户包括NLP开发者和数据科学家,潜在用户包括企业IT团队和学术研究人员。
1.2竞争产品:
目前的竞争产品包括STORM、Elasticsearch和FAISS。STORM适用于更大规模的数据处理,Elasticsearch在企业级搜索方面更成熟,而FAISS主要用于高效向量搜索。
1.3产品定位:
txtai 作为轻量级NLP搜索工具,适合小型应用,但缺乏企业级功能,例如权限控制和GUI。
2.市场与产品生态
2.1核心用户群
核心或者典型用户是25-40岁的具有计算机、数据科学相关背景的NLP开发者、数据科学家、企业IT团队或者学术研究人员。他们的潜在需求都是需要使用txtai处理NLP任务,实现检索分类。
2.2联系
首先是NLP开发者,他们会在github等开源社区中共享开源代码,以供其他数据科学家、学术研究人员研究学习。反过来,他们也会为NLP开发者提供一些新的建议和方法,相辅相成。
其次,企业IT团队通常会依赖于NLP开发者和数据科学家提供技术支持和定制化开发。
2.3构建生态
txtai可通过构建开放API和插件生态,支持开发者创建NLP解决方案,拓展应用场景。同时,建立社区支持体系,包括论坛、线上分享会等,提升开发者参与度并增强开源及企业市场影响力。此外,为企业用户提供更完善的UI、权限管理和大规模数据索引支持,以优化使用体验,推动产品在商业化场景中的应用。
3.产品规划
新功能设计
在我使用过程中得到的缺点之一是没有UI界面,所以我想新增的新功能是:增加Web UI界面,降低开发者或者初学者的使用门槛。
NABCD分析
- N(Need,需求)
当前txtai通过API进行操作,对于初学者来说门槛较高。同时在管理大规模索引的时候需要手动操作,增加了使用的成本。因此,提供一个Web UI的界面,可以降低门槛,提高工作效率。 - A(Approach,做法)
前端:构建Web UI,支持索引管理、查询等功能
后端:封装API,提供UI交互 - B(Benefit,好处)
对于初学者来说,极大地降低了使用门槛,提高管理索引的效率。同时,直观的UI操作,减少代码编写的时间。最后,改进了上手难度大的缺陷,增加了产品的竞争力。 - C(Competitors,竞争)
txtai + Web UI = 轻量级 + 可视化,适用于个人开发或者中小型项目或者企业开发。 - D(Delivery,落地)
1-2 周:需求分析与界面设计。
3-6 周:API开发与UI框架搭建。
7-10 周:功能开发:索引管理、查询测试等。
11-12 周:权限管理、性能优化。
13-14 周:内部测试与迭代。
15-16 周:正式发布与推广。
团队分工
2名后端开发工程师负责后端API开发,提供UI交互
2名前端工程师:构建Web UI
1名测试工程师:负责测试部分
1名项目经理:负责推动管理整个项目有序进行

 浙公网安备 33010602011771号
浙公网安备 33010602011771号