
Oracle转换字符集操作到底发生了什么?
数据库当前字符集为AL32UTF8,若打算将字符集更换为ZHS16GBK,执行如下命令:
"ALTER DATABASE NATIONAL CHARACTER SET INTERNAL_USE ZHS16GBK"
可以达到预期目标吗?
我们通过一个实验来看一看,执行上述命令,在数据库层面到底发生了什么。
在字符集为AL32UTF8的数据库中,创建一张表,分两个字段分别插入一些汉字和一些可打印的字符。
1、创建表
create table TEST
(
id NUMBER, --记录编号
name VARCHAR2(10 CHAR),--插入随机生成的汉字串。生成方法见附件一。
key VARCHAR2(60) –插入随机生成的可打印字符串
)
2、插入50000条记录
declare
leng number;
begin
for x in 1..5
loop
for y in 1..10000
loop
leng:=ceil(dbms_random.value(0,10));
insert into test values (y,gen_hanzi(leng),dbms_random.string('P',leng));
end loop;
commit;
end loop;
end;
3、随机查看一些记录值,以及在该字符集下的编码
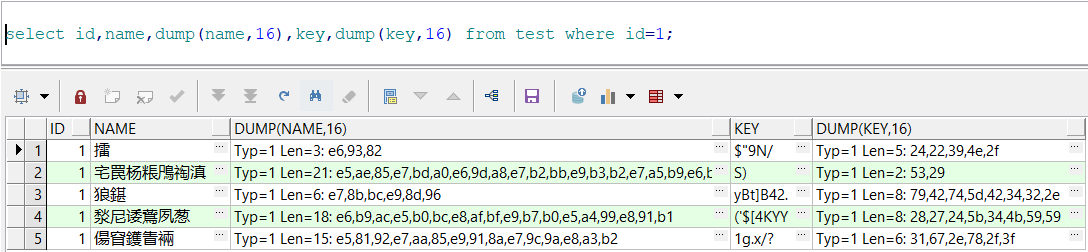
查询汉字"擂"的UTF8编码,

可知,数据库当前对汉字确实是使用UTF8进行编码。
4、数据库执行转换字符集命令
转换之后,查询当前数据库的字符集:
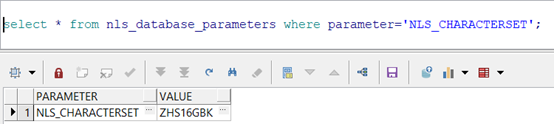
可知,在数据字典层面,数据库的字符集已合AL32UTF8转为了ZHS16GBK。
数据字典层面进行了调整,那么字符的编码有没有根据新的字符集进行调整呢?
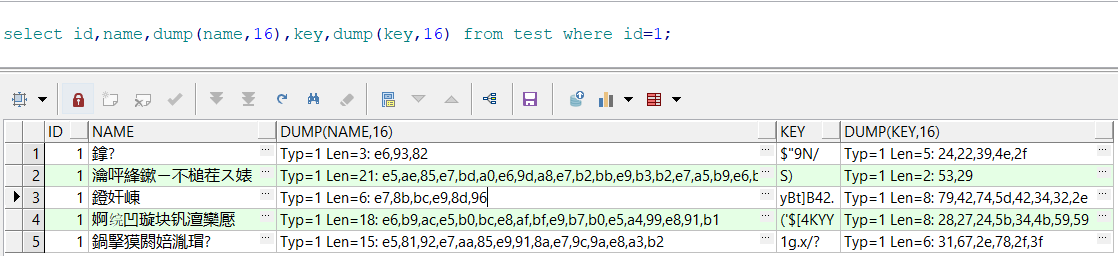
可以看到,所有的DUMP值均没有发生变化——即在磁盘存储层面,信息未发生任何变化。因为存储上仍然在使用UTF8编码,但解码上使用GBK解码,所以,汉字全部解码错误(即没有得到正确的汉字符号)。而对于可打印的字符,由于字符在两种不同的字符集中,其编码值一致,因此,未发生解码错误。
从上述可知,如果目标字符集不是原字符集的超集,因为原编码并未发生变化,则极有可能出现解码错误而导致乱码的现象。在上面,看到了相关汉字字符在UTF8字符集下的编码值,那么这些字符在GBK字符集下是如何编码的呢?
将该表的记录插入到使用ZHS16GBK字符集的数据库中,查看记录值及编码值:
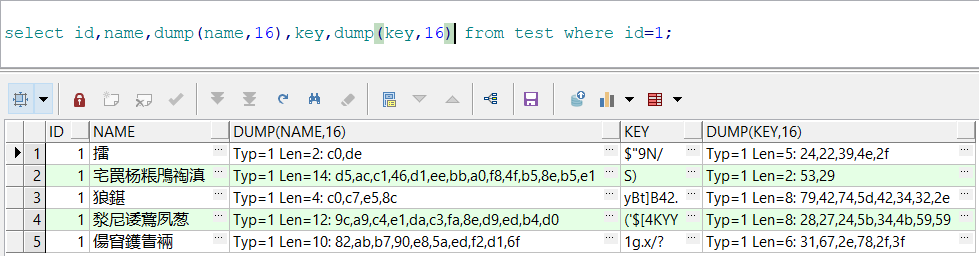
可以看到,GBK字符集对汉字是2字节编码,而UTF8对汉字是3字节编码。
我们还有另外一个问题——修改字符集之后,对于修改之前存储的字符编码无变化,那对于之后存储的字符呢?
6、向修改字符集之后的数据库中插入汉字与可打印的字符
插入100条记录,为与之前记录区别,其ID>10000。
declare
leng number;
begin
for y in 10000..10100
loop
leng:=ceil(dbms_random.value(0,10));
insert into test values (y,gen_hanzi(leng),dbms_random.string('P',leng));
end loop;
commit;
end;
查看插入的值,以及其编码:
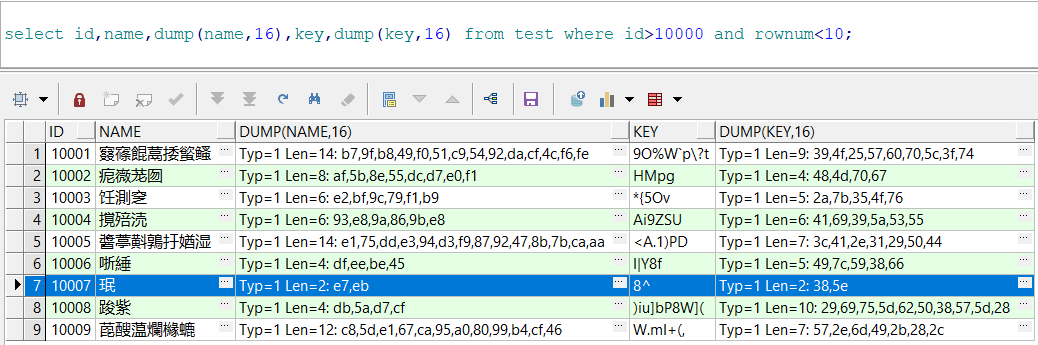
从第7条记录的编码长度,即可初步判断其使用了GBK的编码值。我们来验证一下:

结论:
1、执行字符集转换的命令会修改数据字典
2、执行字符集转换的命令不为使用新的字符集为之前存储的字符进行重新编码。因为如果目标字符集不是原字符集的超集,转换后可能(尤其是汉字)出现乱码。
3、执行字符集转换的命令后,将为之后输入的字符使用新的字符集进行编码。
附件——"生成随机长度汉字串的存储过程"
生成随机长度汉字串的存储过程:
create or replace function gen_hanzi(max_length number) return varchar2 as
leng number;
hanzi varchar2(1 char);
hanzis varchar2(4000):='';
begin
leng:=ceil(dbms_random.value(0,max_length));
for x in 1..leng
loop hanzi:=unistr('\'||trim(to_char(ceil(dbms_random.value(19968,40869)),'XXXX')));
hanzis:=hanzis||hanzi;
end loop;
return hanzis;
end;

