
Oracle Spatial分区应用研究之六:全局空间索引下按县分区与按省分区效率差异原因分析
1、实验结论
- 全局空间索引下,不同分区粒度之所有效率会有不同,差异并不在于SDO_FILTER操作本身,而在于对于数据字典表的访问次数上;
- 分区越多、表上的lob column越多,对数据字典表的访问次数越多;
- 对数据字典表访问次数的大概值(暂不考虑对其它数据字典表的访问)是可量算的。
2、实验目的
在04-不同分区粒度+全局空间索引查询效率对比一文中,我们看到了某种趋势:在四千万条要素量级下,分区粒度越细,全局空间索引查询效率越低。虽然看到了这种现象,但当时尚不能解释深层次的原因。本文的目的,既是探索研究出现这一现象的原因。
3、实验方法
分别以按县分区、按省分区两种方式来组织2531个区县、共46982394条要素。在两个分区表上均创建全局空间索引。按县分区表共有2531个分区,按省分区表共有43个分区。
开启10046事件,跟踪SDO_FILTER操作。10046事件将trace数据库所有的SQL请求,包括递归与与非递归的SQL请求,得到trc文件。然后按如下3步来分析:
- 逐行对比两个trc文件;
- 使用tkprof工具分析trc文件,按prsela,exeela,fchela(解析时间、执行时间、获取时间)排序SQL;
- 根据绑定变量的值分析递归查询查询了数据字典的哪些内容。
4、实验结果
4.1 逐行对比trc文件
两个trc文件内容基本一致。差别在于对于相同的SQL,其执行次数、elapsed、返回记录数、等待事件等存在差异。
4.2 使用tkprof分析trc文件
因为本文主要分析的是不同分区粒度下,空间查询性能的差异,因此在使用tkprof分析trc文件时,将从elapsed入手分析。而elapsed又包括parse、execute、fetch三种数据库调用类型,所以将指定sort = prsela,exeela,fchela。使用tkprof生成格式化文本的命令如下:
Tkprof db12c...trc country.txt sys=yes aggregate=yes sort=prsela,exeela,fchela
下文将以在按县分区空间查询中耗时较多的一系列SQL为参照,比较相同SQL在按省分区空间查询中的耗时。
-
Seg$
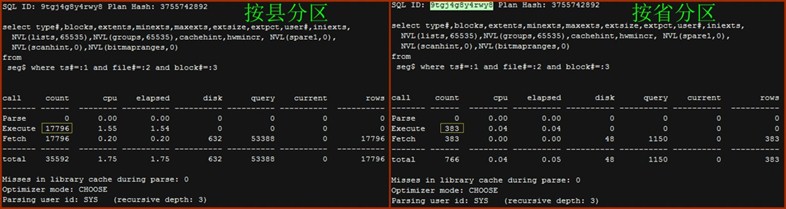
按县分区对SQL ID为9tgj4g8y4rwy8的SQL执行了17796次,总耗时1.75s;而按省分区对相同SQL的执行次数仅为383次,总耗时为0.05s。SQL查询的对象是seg$,seg$是数据字典表,每条记录表示一个ORACLE Segment。为什么会有差异呢?在3.3会说明。
- Lobfrag$
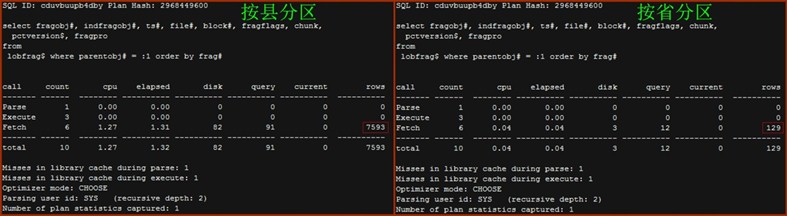
按县分区对SQL ID为cduvbuupb4dby的SQL返回了7593条记录,总耗时1.32s;而按省分区对相同SQL的仅返回129条记录,总耗时为0.04s。SQL查询的对象是lobfrag$,lobfrag$是数据字典表,每条记录表示一个lob fragment。如果仔细观察,会发现7593是2531(分区个数)的3倍,而129是43的3倍。是巧合还是有必须的联系?在3.3会说明。
- Obj$
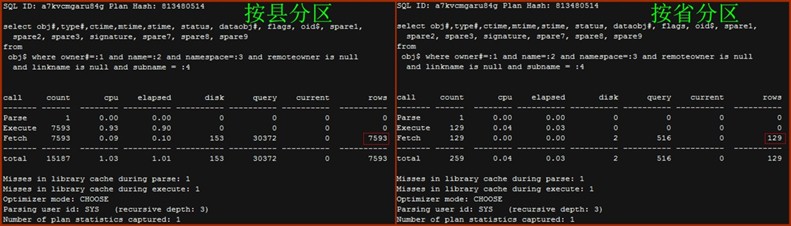
按县分区对SQL ID为a7kvcmgaru84g的SQL返回了7593条记录,总耗时1.01s;而按省分区对相同SQL的仅返回129条记录,总耗时为0.03s。SQL查询的对象是obj$,obj$是数据字典表,每条记录表示一个object。
- Indpart$
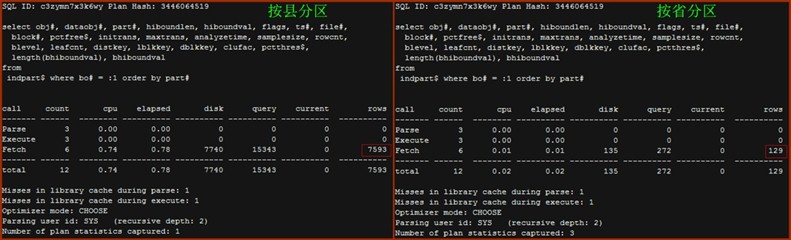
按县分区对SQL ID为a7kvcmgaru84g的SQL返回了7593条记录,总耗时0.78s;而按省分区对相同SQL的仅返回129条记录,总耗时为0.02s。SQL查询的对象是indpart$,indpart$是数据字典表,每条记录表示一个index parttition。
- Obj$(2)

按县分区对SQL ID为87gaftwrm2h68的SQL返回了7697条记录,总耗时0.45s;而按省分区对相同SQL的返回记录仅为210条,总耗时为0.02s。SQL查询的对象也是obj$。
- Tabpart$
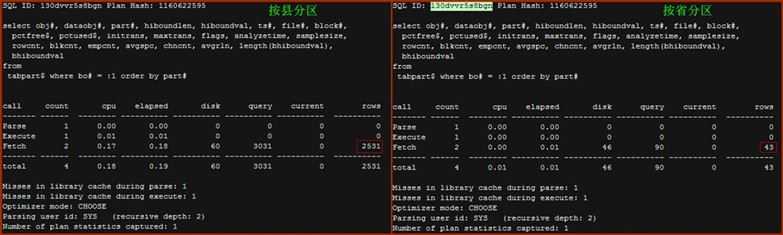
按县分区对SQL ID为87gaftwrm2h68的SQL返回了2531条记录,总耗时0.19s;而按省分区对相同SQL的返回记录仅为43条,总耗时为0.01s。SQL查询的对象是tabpart$, tabpart$是数据字典表,每条记录表示一个table parttition。
- SDO_FILTER
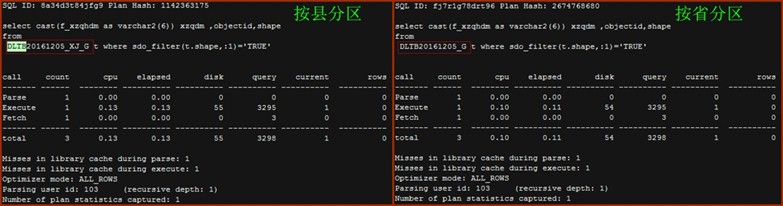
在本例中,按县分区和按省分区,在全局空间索引下,SDO_FILTER的效率相当。注意,该例查询范围内没有返回要素。
- 其它
其它还有一些递归SQL,其查询对象包括hist_head$、histgrm$等数据字典表。因为对这些对象的查询与分区个数相关度不大,因此不着重分析。
4.3 分析数据字典的访问内容
对seg$ 、lobfrag$ 、obj$ 、indpart$、obj$(2) 、tabpart$字典表的访问次数似乎都表现出了与分区个数的正相关性。那到底存不存在正相关性呢?
通过编写Shell脚本,将3.2(1)-(8)SQL语句中的绑定变量值提取出来,然后与相应的数据字典表进行JOIN操作,发现:
- Seg$
查询内容包括所有的lob partition 、index partition、table partition 以及sys和mdsys用户下的字典表、元数据表、少量其它表。本例中的两个图层都包含3个lob column,分别是sdo_geometry.sdo_elem_info、sdo_geometry.sdo_ordinate、se_anno_cad_data,而每个lob column上会存在一个lobindex。以按县分区图层为例,table partition有2531个,lob partition有2531*3个,index partition 有2531*3。
- Lobfrag$
查询内容包括所有的lob partition。以按县分区图层为例,lob partition有2531*3个。
- Obj$
查询内容包括所有的lob partition。以按县分区图层为例,lob partition有2531*3个。
- Indpart$
查询内容包括所有index partiton。以按县分区图层为例,lob partition有2531*3个。
- Obj$(2)
查询内容包括所有的lob partition、以及sys和mdsys用户下的字典表、少量其它表。在本例中,访问sys用户下61张表,mdsys用户下23张表。
- Tabpart$
查询内容包括所有table partiton。以按县分区图层为例,table partiton有2531个。
5、实验结论
- 全局空间索引下,不同分区粒度之所有效率会有不同,差异并不在于SDO_FILTER操作本身,而在于对于数据字典表的访问次数上;
- 分区越多、表上的lob column越多,对数据字典表的访问次数越多;
- 对数据字典表访问次数的大概值(暂不考虑对其它数据字典表的访问)是可量算的。假设分区数以X表示,lob column个数以Y表示,不同字典表的访问次数见下表:
|
数据字典表 |
访问次数 |
|
Seg$ |
(1+2Y)*X |
|
Lobfrag$ |
XY |
|
Obj$ |
XY |
|
Indpart$ |
XY |
|
Obj$(2) |
XY |
|
Tabpart$ |
X |
若已经获知对各数据字典表的平均访问时间,甚至可以估算查询耗时。在每例中seg$ 、lobfrag$ 、obj$ 、indpart$、obj$(2) 、tabpart$,各数据字典表的平均访问时间约为100us、240us、50us、150us、180us、120us。因此可估算时间为:
Elapsed all= 100*(1+2Y)*X + 240*Y*X + 50*X*Y + 150*Y*X + 180*Y*X + 120*X =X(820Y+220)

