
Oracle Spatial分区应用研究之五:不同分区粒度+本地空间索引效率对比
1、实验目的
若使用本地空间索引,不同分区粒度将产生不同索引组织,其索引分区个数、大小、R-TREE树结构均不相同。那么,在什么分区粒度下的本地空间索引效率较高呢?
2实验数据
实验数据为全国2531个区县,要素总数为46982394。分别以按县、市、省、区域分区,以及不分区来进行组织。在分区表上创建本地空间索引,在不分区表上创建全局空间索引。
3实验方法
在1:500、1:2000、1:10000、1:25000、1:50000、1:100000比例尺下,随机从全国范围内选择3个样本范围,作为空间查询时的查询范围。将6*3个样本范围分别与3个实验主体进行空间查询运算,记录每次查询的耗时。
分区表采用最适合本地空间索引的算法——part_query,未分区表采用最适合全局索引的算法——part_query3。
4实验结果
实验结果如下表:
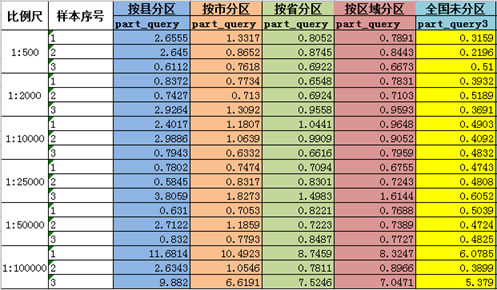
求每种比例尺3个样本的平均值:
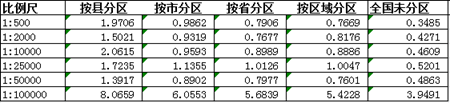
绘制不同分区粒度在不同比例尺下响应时间的折线图。

5实验结论
- 过于分散的分区策略(按县分区),其性能损失较为严重。
- 随着分区粒度越来越"粗",性能趋于平缓。按市、按省、按区域分区性能相差不大。
- 表现最好的分区+本地索引,其效率仍然不如未分区表+全局索引。
- 在大比例尺下,虽然分区效率不如未分区,但差异相差微小。是否产用分区,产用何种分区,应结合业务场景选择合适的组织方式。
欢迎转载,但本着尊重原创的精神,请标明出处

