
PG数据库CPU和内存满负荷运转优化案
1、问题描述
某客户系统采用三层架构:数据库—应用服务—前端应用。其中数据库使用PostgreSQL 10.0作为数据库软件。自周四起,服务器的CPU与内存使用率持续处于过饱合状态,并因此导致了数次宕机(期间有几次宕机是应用服务器宕机)。
2、问题观察
通过观察,发现如下几个疑似问题:
1)在无任何作业的情况下,存在数十个处于空闲状态的服务器进程(即postgres进程),这些进程虽然不消耗CPU,但始终持有内存资源;
2)开启慢查询之后发现,有三类SQL查询效率非常低。
1、根据输入的WKT(矩形范围)作空间相交分析。如下图(耗时30s以上)

2、DCTB表与DDXX表的JOIN查询,如下图耗时5-14s:

3、执行COMMIT提交事务后的等待,如下图耗时10-30s
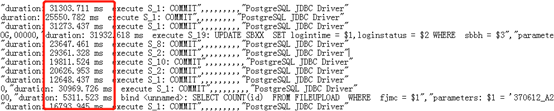
3、问题分析
1)针对空闲进程的处理:一方面,应用程序(Tomcat)要使用连接池,且要设计有效的回收连接的机制;二方面,在数据库层面设置TCP探针,每隔10s探测一下client process是否仍然处于active状态,如果客户端进程已经异常关闭,数据库会回收连接。
2)针对空间相交分析的SQL,经分析是由于public.dctb的geom字段上未创建空间索引,导致每次的相交分析(即&&操作符)都需要判断所有要素与WKT矩形的空间关系。空间运算属于CPU密集型操作,操作系统的CPU使用率长期过饱合可能与此有关。
创建空间索引:create index idx_dctb_geom on public.dctb using gist (geom),持续运行一段时间后观察到CPU的使用率有明显缓解。
3)针对JOIN查询慢的问题,原本认为可能是因为SQL写法的原因,导致查询优化器选择了错误的执行计划。但经过分析执行计划,发现该SQL的确是先通过索引过滤了部分记录,然后再执行JOIN连接,因此对该问题的优化需要考虑其它的办法。但这并不代表该SQL不需要优化,从SQL的易读性和避免查询优化器选择了错误的执行计划这两个方面考虑,建议把SQL改写成类似如下的写法:
with t3 as (select r_rybh from rwdd.sbxx where mac = '74:d2:1d:b3:a2:bc' limit 1),
t2 as (select bsm,coalesce(sfjz,'Y') sfjz,sjly from dctb where xzqdm='370322')
select t1.bsm,coalesce(t1.tbzt3,'00') tbzt3,t2.sfjz,t2.sjly,t1.shjg1 shjg1,
t1.shyj1 shyj1,
t1.shjg2 shjg2,
t1.shyj2 shyj2,
t1.shjg3 shjg3,
t1.shyj3 shyj3,
t1.wyhczt wyhczt,case when COALESCE(t3.r_rybh,'0') = '0' then '0' else '1' end as sfzpbj from ddxx t1 left join t3 on t1.rybh=t3.r_rybh join t2 on t1.bsm=t2.bsm
4)针对COMMIT延迟的问题,考虑从如下两方面解决:
1、对虚拟磁盘作基准测试,因为怀疑磁盘的IOPS本身就不高。
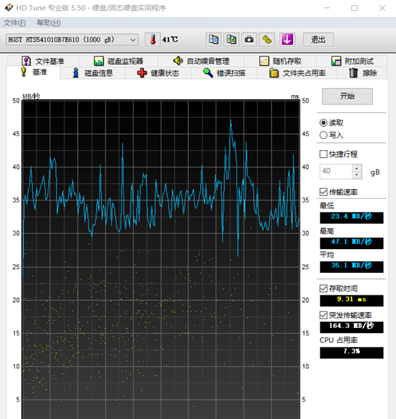
A.连续读的性能:

以7200转SATA盘连续读性能作为参考,如下:
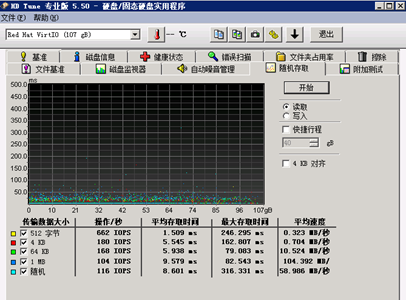
B.随机读性能
以7200转SATA盘连续读性能作为参考,如下:
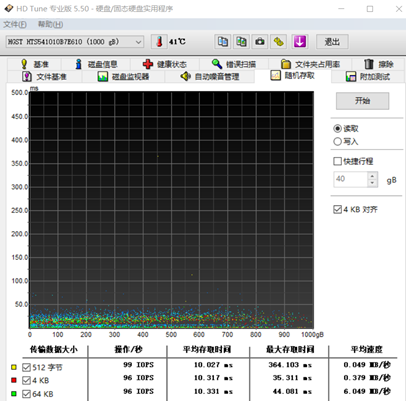
通过基础测试可知,虚拟磁盘的性能超过7200转的SATA盘,与10000-15000转SAS盘性能相当。
2、通过修改数据库参数文件,优化WAL日志写的效率
修改的参数包括:
synchronous_commit 由 on 改为了 off
wal_buffers 由100MB 改为了 400MB
commit_delay 由0 改为了 100
wal_compression 由 off 改为了 on
3、其它调整
A.调整了部分内存池的设置。
包括work_mem = 20MB和 maintenance_work_mem = 20MB
B.关闭了autovacuum
4、目前情况
收集了3月18日13:30到21点的部分性能数据,分析如下:
1)Processor Time

Processor Time基本上处于50%左右。
2)磁盘读写MB/s

磁盘读写普遍处于10M/s以下。
3)可用内存(GB)
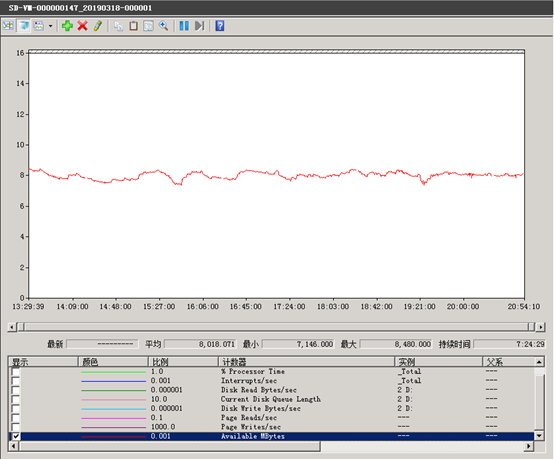
可用内存长期保持8G左右。

