Spring Boot demo系列(十一):ShardingSphereJDBC + MyBatisPlus 分库分表
1 概述
本文主要讲述了如何使用ShardingSphereJDBC和MyBatisPlus进行分库分表,具体步骤包括:
- 准备数据库环境
- 准备依赖
- 编写配置文件
- 测试
2 环境
MyBatis Plus 3.5.1MyBatis Plus Generator 3.5.2Druid 1.2.10ShardingSphereJDBC 5.1.1MySQL 8.0.29(Docker)yitter-idgenerator 1.0.6Freemarker 2.3.31
3 准备数据库环境
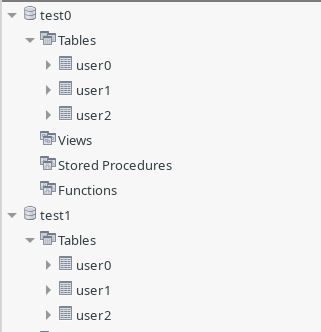
准备好两个库:
test0test1
在两个库中分别建立三个字段一样的表:
user0user1user2
字段如下:

这样就准备了两个库以及其中的六个表了。
4 新建项目
新建Spring Boot项目并引入如下依赖:
DruidMyBatis Plus starterMyBaits Plus GeneratorFreemarkerShardingSphereYitter(一个雪花id生成器)
Gradle如下:
implementation 'com.alibaba:druid:1.2.10'
implementation 'com.baomidou:mybatis-plus-boot-starter:3.5.1'
implementation 'org.freemarker:freemarker:2.3.31'
implementation 'com.baomidou:mybatis-plus-generator:3.5.2'
implementation 'org.apache.shardingsphere:shardingsphere-jdbc-core-spring-boot-starter:5.1.1'
implementation 'com.github.yitter:yitter-idgenerator:1.0.6'
Maven如下:
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.5.1</version>
</dependency>
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-generator</artifactId>
<version>3.5.2</version>
</dependency>
<dependency>
<groupId>org.freemarker</groupId>
<artifactId>freemarker</artifactId>
<version>2.3.31</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.2.10</version>
</dependency>
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>5.1.1</version>
</dependency>
<dependency>
<groupId>com.github.yitter</groupId>
<artifactId>yitter-idgenerator</artifactId>
<version>1.0.6</version>
</dependency>
5 配置文件
配置文件可以参考ShardingSphere文档,这里给出一个示例配置:
spring:
shardingsphere:
mode:
type: Memory # 内存模式,元数据保存在当前进程中
datasource:
names: test0,test1 # 数据源名称,这里有两个
test0: # 跟上面的数据源对应
type: com.alibaba.druid.pool.DruidDataSource # 连接池
url: jdbc:mysql://127.0.0.1:3306/test0 # 连接url
username: root
password: 123456
test1: # 跟上面的数据源对应
type: com.alibaba.druid.pool.DruidDataSource
url: jdbc:mysql://127.0.0.1:3306/test1
username: root
password: 123456
rules:
sharding:
tables:
user: # 这个可以随便取,问题不大
actual-data-nodes: test$->{0..1}.user$->{0..2} # 实际节点名称,格式为 库名$->{0..n1}.表名$->{0..n2}
# 其中n1、n2分别为库数量-1和表数量-1
# 也可以使用${0..n1}的形式,但是会与Spring属性文件占位符冲突
# 所以使用$->{0..n1}的形式
database-strategy: # 分库策略
standard: # 标准分库策略
sharding-column: age # 分库列名
sharding-algorithm-name: age-mod # 分库算法名字
table-strategy: # 分表策略
standard: # 标准分表策略
sharding-column: id # 分表列名
sharding-algorithm-name: id-mod # 分表算法名字
sharding-algorithms: # 配置分库和分表的算法
age-mod: # 分库算法名字
type: MOD # 算法类型为取模
props: # 算法配置的键名,所有算法配置都需要在props下
sharding-count: 2 # 分片数量
id-mod: # 分表算法名字
type: MOD # 算法类型为取模
props: # 算法配置的键名,所有算法配置都需要在props下
sharding-count: 3 # 分片数量
props:
sql-show: true # 打印SQL
大部分的配置说明在读写分离这篇文章有提到,此处说明一些不同的配置。
5.1 数据节点配置
spring.shardingsphere.rules.sharding.tables.<table-name>.actual-data-nodes,其中<table-name>可以任意取值,能明确意义即可,比如这里取值user。
actual-data-nodes后面是具体的节点名字,节点名字采用库名.表名的形式,多个表用,分隔,支持行内表达式,也就是例子中test$->{0..1}.user$->{0..2}的形式。
test$->{0..1}.user$->{0..2}表示数据库包含test0、test1,而表包含user0、user1、user2。文档还提到可以使用${}而不是$->{},但是前者与Spring配置文件占位符冲突,因此使用$->{}。
5.2 分库分表策略配置
分别为:
spring.shardingsphere.rules.sharding.tables.<table-name>.database-strategyspring.shardingsphere.rules.sharding.tables.<table-name>.table-strategy
两者的配置是类似的,以database-strategy为例,文档提到需要配置如下属性:
sharding-columns:分片列的名称,对于分库,表示的是按照哪一列进行分库,对于分表,表示的是按照哪一列进行分表sharding-algorithm-name:分片算法的名称,具体的分片算法配置在sharding-algorithms中。
5.3 分片算法配置
spring.shardingsphere.rules.sharding.sharding-algorithms.<sharding-algorithm-name>,其中<sharding-algorithm-name>是spring.shardingsphere.rules.sharding.tables.<table-name>.database-strategy.sharding-algorithm-name/spring.shardingsphere.rules.sharding.tables.<table-name>.table-strategy.sharding-algorithm-name配置的名字,这里的例子是age-mod以及id-mod。
对于分片算法,需要配置两个属性:
type:分片算法的类型,此处的是MOD,取模算法props:根据类型的不同,配置算法的不同属性,比如MOD类型可以配置的属性为sharding-count,sharding-count表示分片数量
内置的分片算法包括:
- 自动分片算法:包括取模分片、哈希取模分片、基于分片容量的范围分片、基于分片边界的范围分片、自动时间段分片
- 标准分片算法:包括行表达式分片、时间范围分片
- 复合分片算法:包括复合行表达式分片
Hint分片算法:包括Hint行表达式分片
还有一种是自定义的分片算法,支持标准、复合、Hint类型。由于算法过多且属性比较复杂,具体的分片算法请参考官方文档。
6 测试代码生成
使用MyBaits Plus Generator生成相应代码,具体使用可以参考笔者之前的文章,这里直接放上生成类的代码:
public class CodeGenerator {
public static void main(String[] args) {
final String USER_TABLE_NAME = "User";
FastAutoGenerator.create("jdbc:mysql://localhost:3306/test0", "root", "123456")
.globalConfig(builder ->
builder.author("author").outputDir(System.getProperty("user.dir") + "/src/main/java").build())
.packageConfig(builder ->
builder.parent("com.example.demo").moduleName("user").build())
.strategyConfig(builder ->
builder.addInclude("user0")
.entityBuilder().enableLombok().disableSerialVersionUID().convertFileName((entityName -> USER_TABLE_NAME))
.mapperBuilder().convertMapperFileName((entityName -> USER_TABLE_NAME + "Mapper")).convertXmlFileName((entityName -> USER_TABLE_NAME + "Mapper"))
.serviceBuilder().convertServiceFileName((entityName -> "I" + USER_TABLE_NAME + "Service")).convertServiceImplFileName((entityName -> USER_TABLE_NAME + "Service"))
.controllerBuilder().enableRestStyle().convertFileName(entityName -> USER_TABLE_NAME + "Controller"))
.templateEngine(new FreemarkerTemplateEngine())
.execute();
}
}
把UserController类修改如下:
@RestController
@RequestMapping("/user")
@RequiredArgsConstructor(onConstructor = @__(@Autowired))
public class UserController {
private final IUserService userService;
@GetMapping("/insert")
public boolean insert() {
return userService.save(User.builder().name("name").age(new Random().nextInt(100) + 1).build());
}
@GetMapping("/select")
public List<User> select() {
return userService.list();
}
}
7 增加雪花id生成器
首先修改User类,增加一个@Builder注解,同时修改id的生成策略,使用IdType.ASSIGN_ID:
@Getter
@Setter
@Builder
public class User {
@TableId(type = IdType.ASSIGN_ID)
private Long id;
private String name;
private Integer age;
}
新建id生成器类:
public class IdGenerator {
@Bean
public IdentifierGenerator identifierGenerator() {
return entity -> YitIdHelper.nextId();
}
}
这样生成id的时候,就会自动调用nextId()方法,其中的id生成器可以根据需要进行替换,换成其他雪花id生成器或分布式id生成器。
配置的时候可以参考MyBaits Plus 自定义ID生成器文档。
8 测试
先随机插入三条数据,刷新三次如下页面:
localhost:8080/user/insert
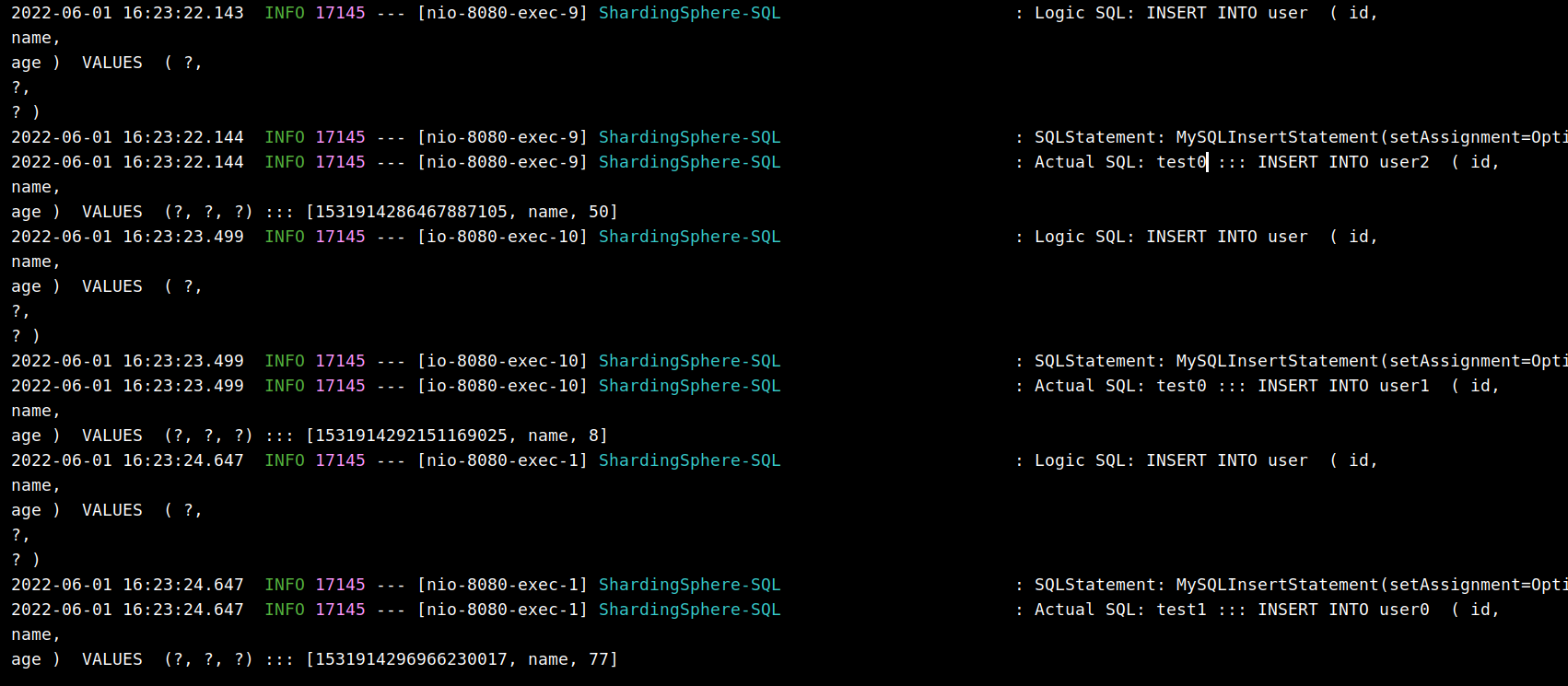
可以看到执行了三次插入操作,插入的三个表分别是:
test0.user2test0.user1test1.user0
查看数据:
http://localhost:8080/user/select

日志输出如下:

9 参考源码
Java版:
Kotlin版:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号