Hadoop完整搭建过程(三):完全分布模式(虚拟机)
1 完全分布模式
完全分布模式是比本地模式与伪分布模式更加复杂的模式,真正利用多台Linux主机来进行部署Hadoop,对集群进行规划,使得Hadoop各个模块分别部署在不同的多台机器上,这篇文章介绍的是通过三台虚拟机进行集群配置的方式,主要步骤为:
- 准备虚拟机:准备虚拟机基本环境
ip+Host配置:手动设置虚拟机ip以及主机名,需要确保三台虚拟机能互相ping通ssh配置:生成密钥对后复制公钥到三台虚拟机中,使其能够实现无密码相互连接Hadoop配置:core-site.xml+hdfs-site.xml+workersYARN配置:yarn-site.xml
2 虚拟机安装
需要使用到三台虚拟机,其中一台为Master节点,两台Worker节点,首先安装虚拟机并配置环境,最后进行测试。
2.1 镜像下载
使用VirtualBox进行虚拟机的安装,先去CentOS官网下载最新版本的镜像:
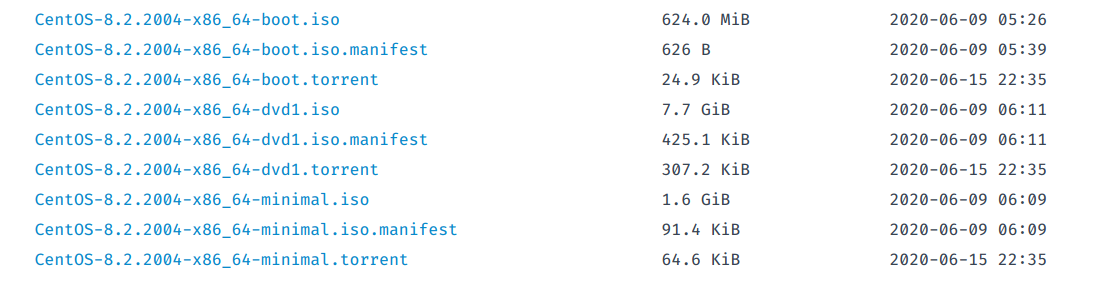
这里有三种不同的镜像:
boot:网络安装版dvd1:完整版minimal:最小化安装版
这里为了方便选择最小化安装版的,也就是不带GUI的。
2.2 安装
下载后,打开Virtual Box并点击New,选择专家模式:
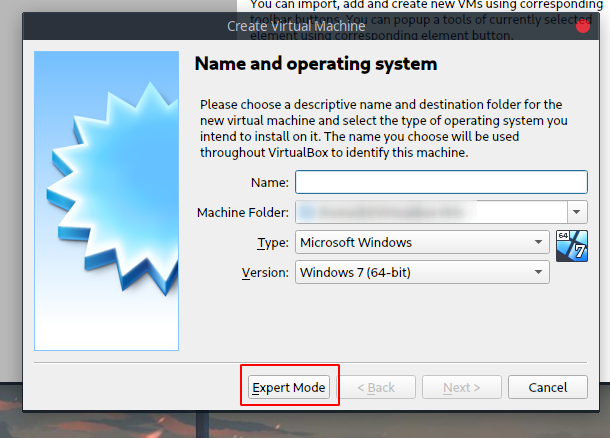
命名为CentOSMaster,作为Master节点,并且分配内存,这里是1G,如果觉得自己内存大的可以2G:
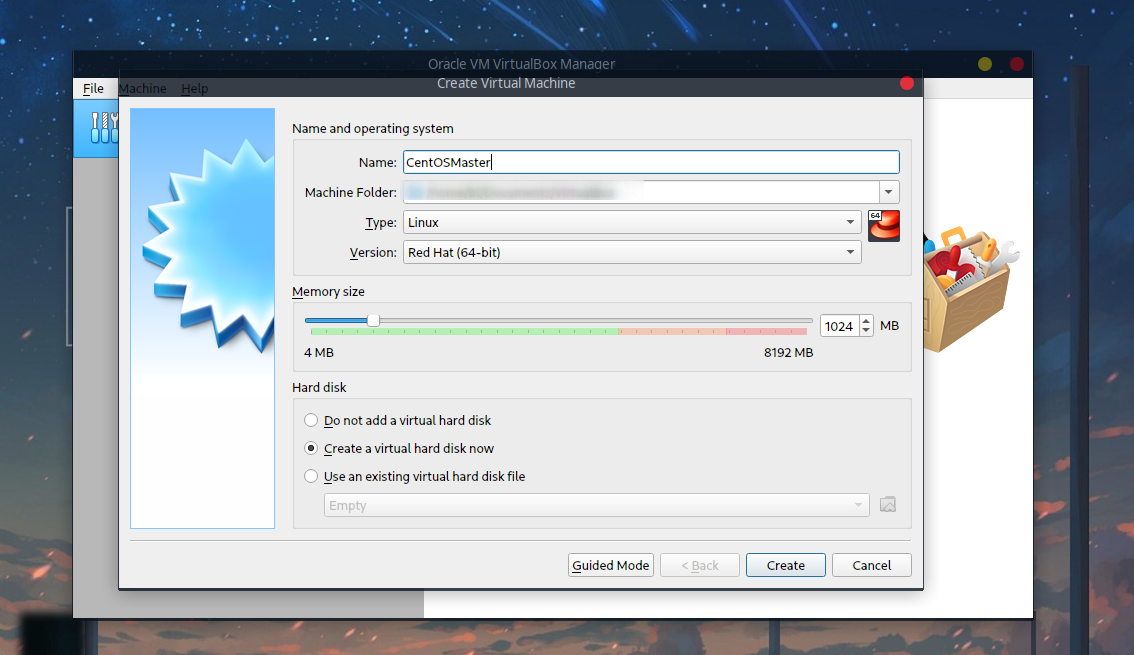
磁盘30G足够,其他可以保持默认:
创建好后从设置中的存储中,选择下载的镜像:
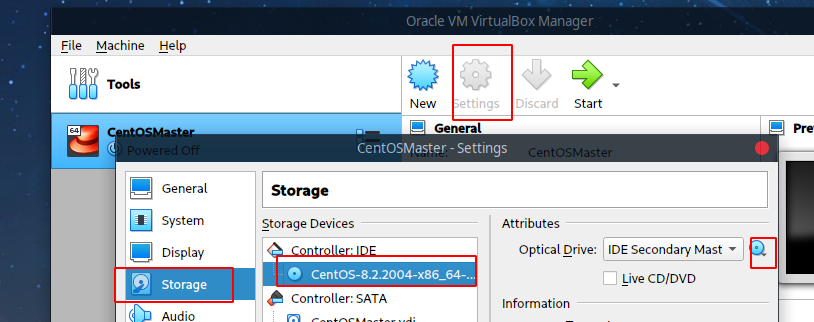
启动后会提示选择启动盘,确定即可:
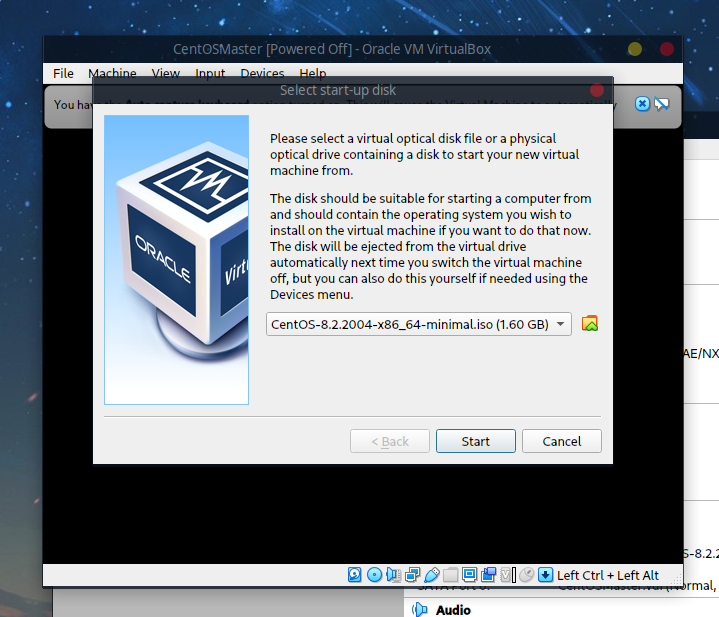
好了之后会出现如下提示画面,选择第一个安装:
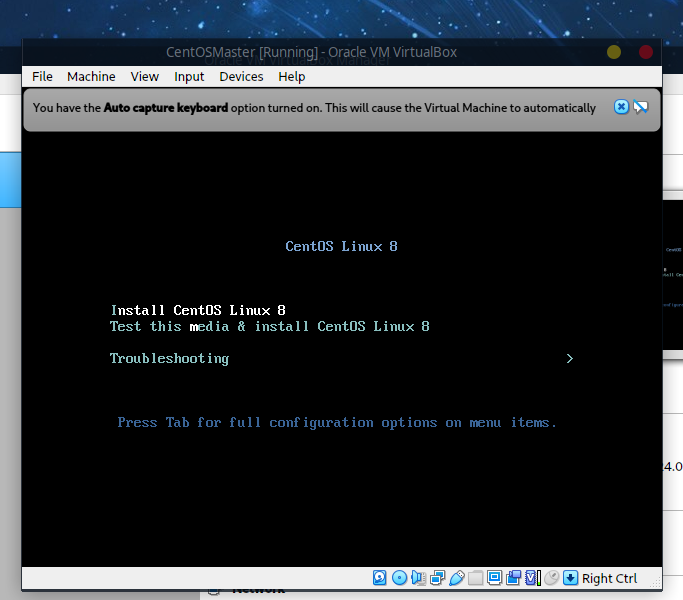
等待一会后进入安装界面:
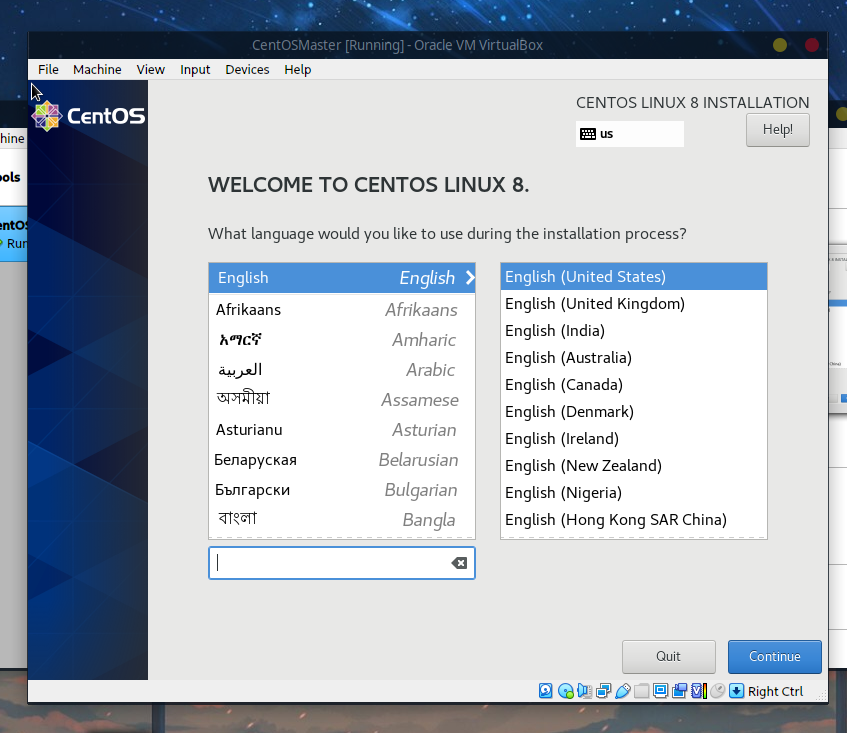
接下来对安装位置以及时区进行配置,首先选择安装位置:
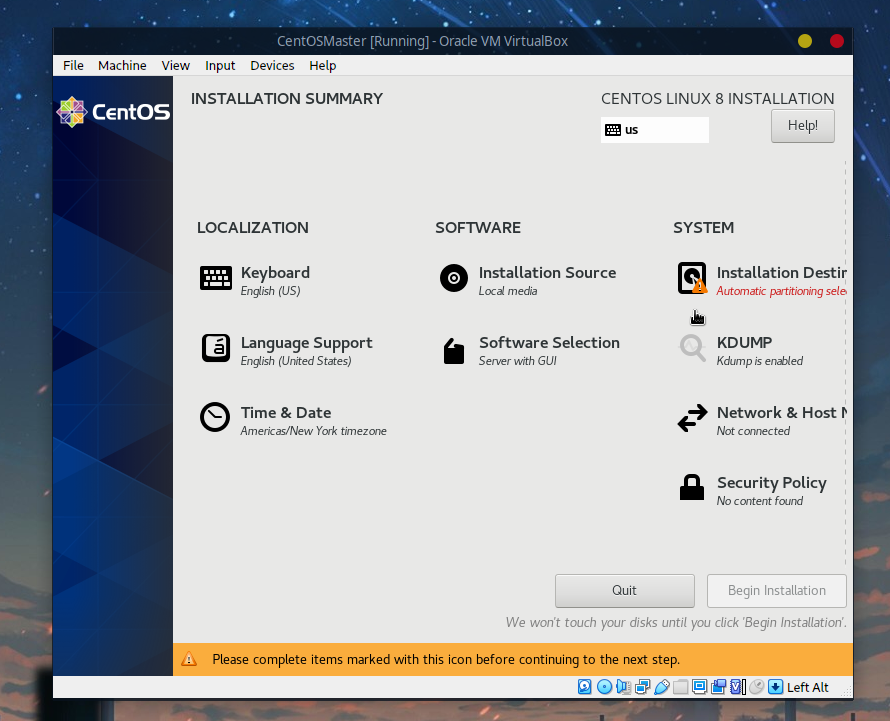
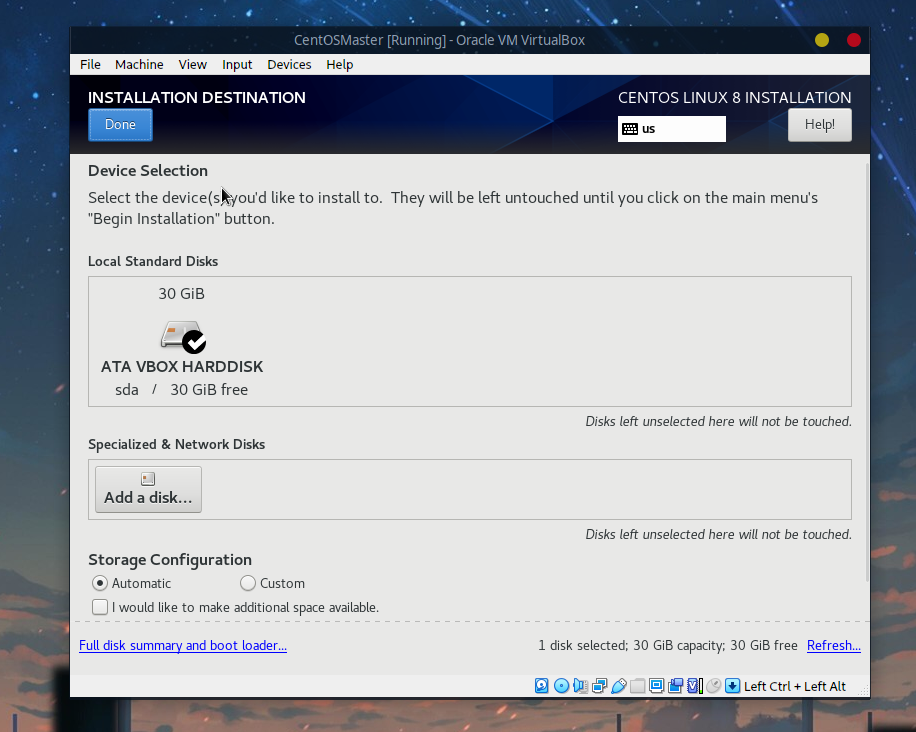
由于是虚拟的单个空磁盘,选择自动分区即可:
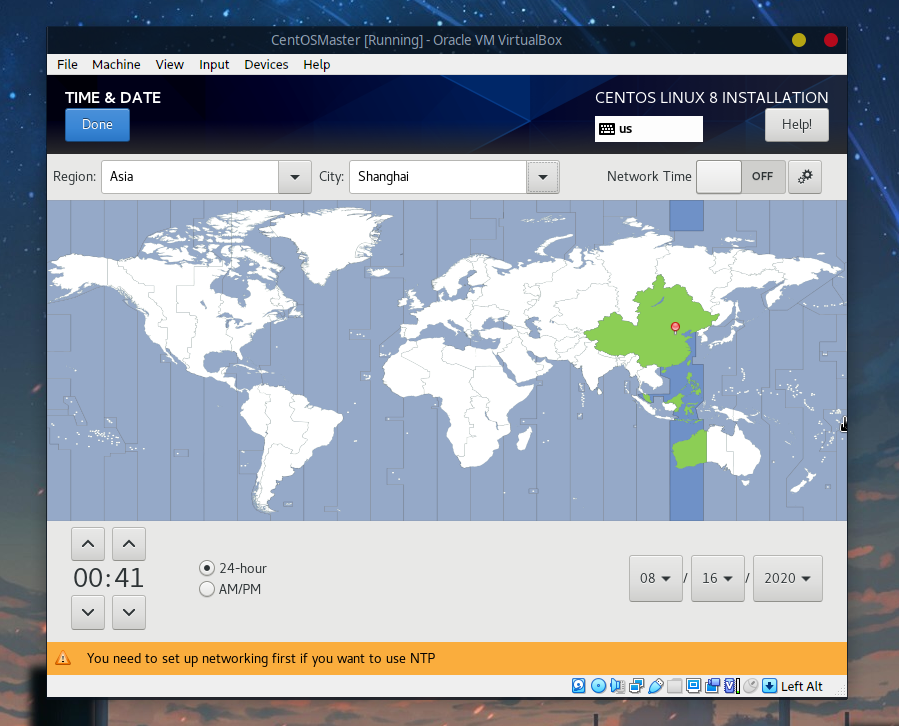
时区这里可以选择中国的上海:
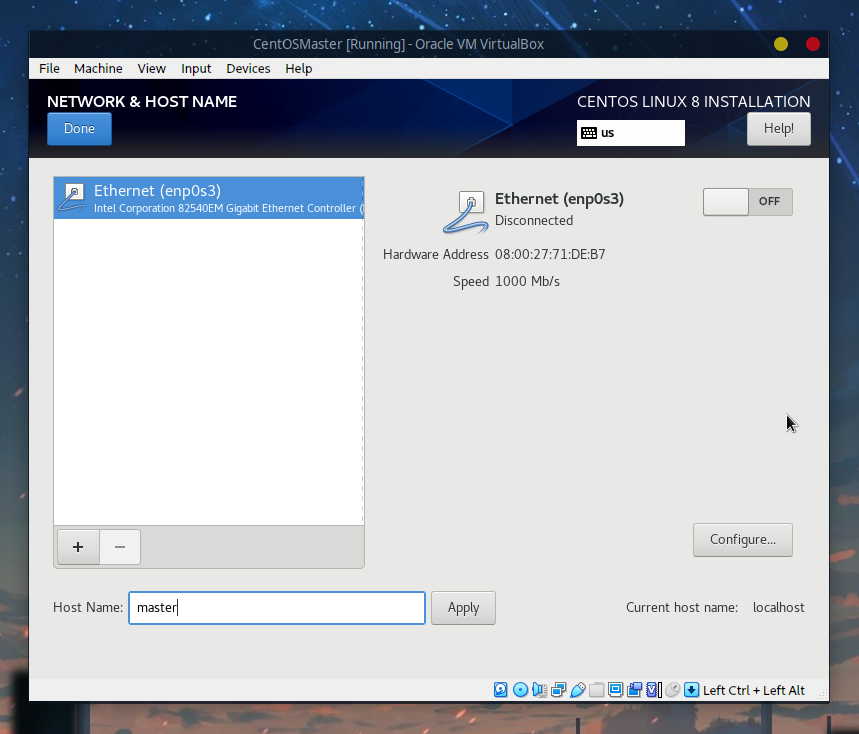
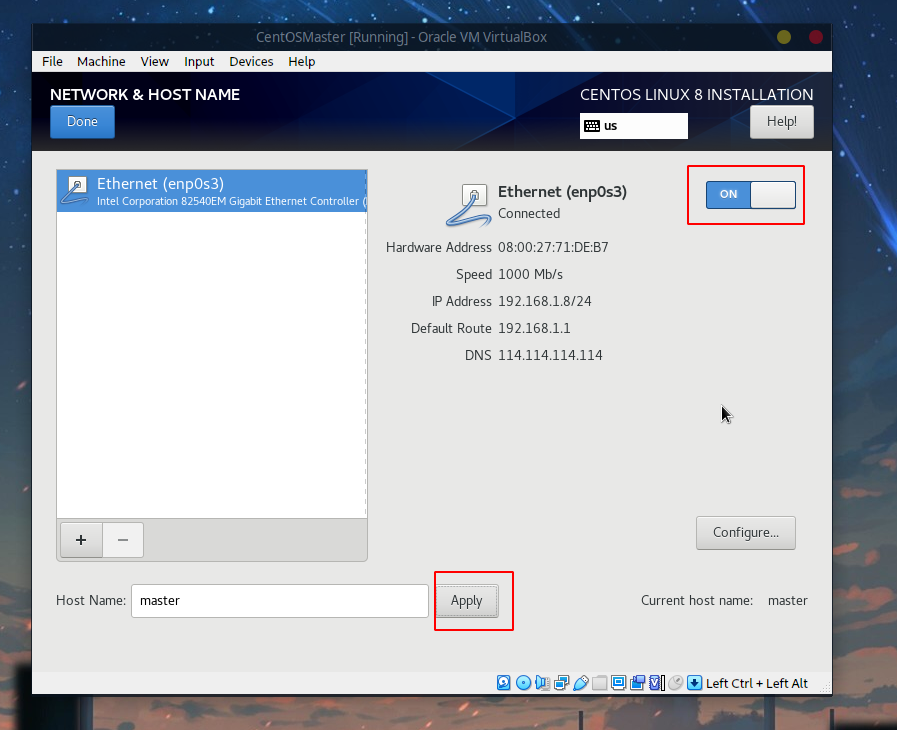
接着选择网络,首先修改主机名为master:
接着点击Configure:
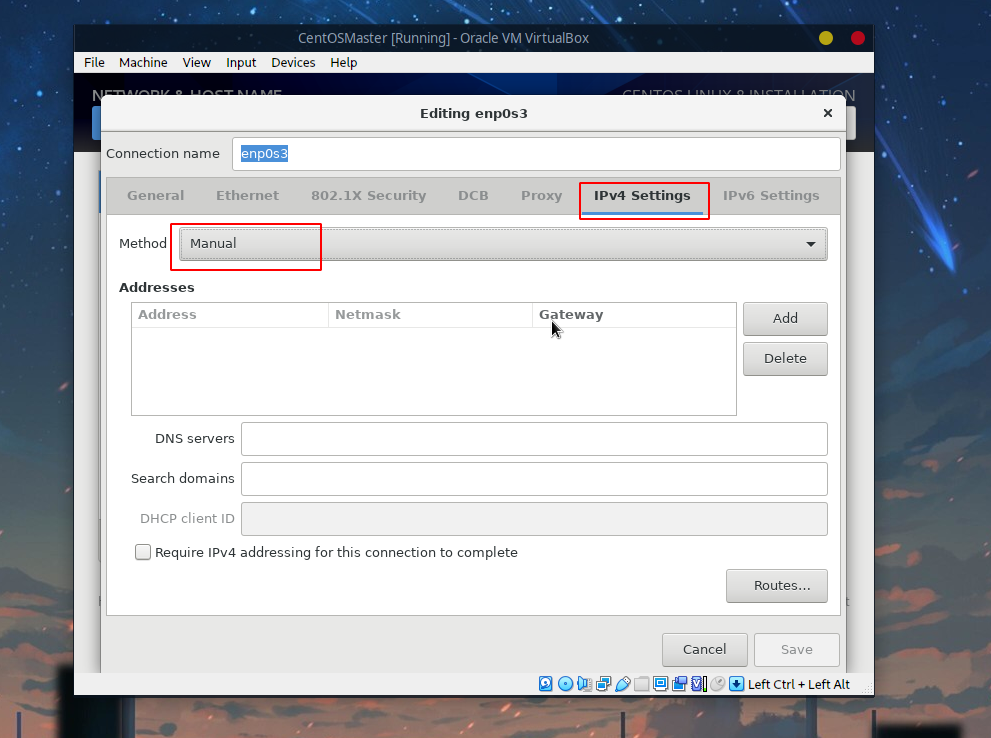
添加ip地址以及DNS服务器,ip地址可以参考本机,比如笔者的机器本地ip为192.168.1.7,则:
- 虚拟机的
ip可以填192.168.1.8 - 子网掩码一般为
255.255.255.0 - 默认网关为
192.168.1.1 DNS服务器为114.114.114.114(当然也可以换其他的公共DNS比如阿里的223.5.5.5、百度的180.76.76.76等)
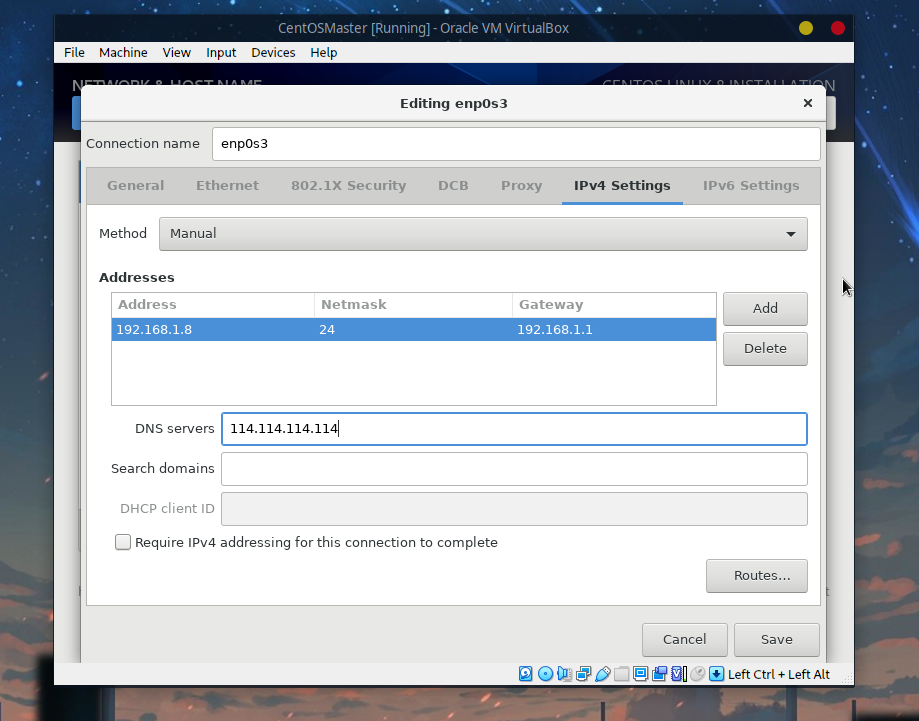
点击Save后应用主机名并开启:
没问题的话就可以安装了:
安装的时候设置root用户的密码以及创建用户:
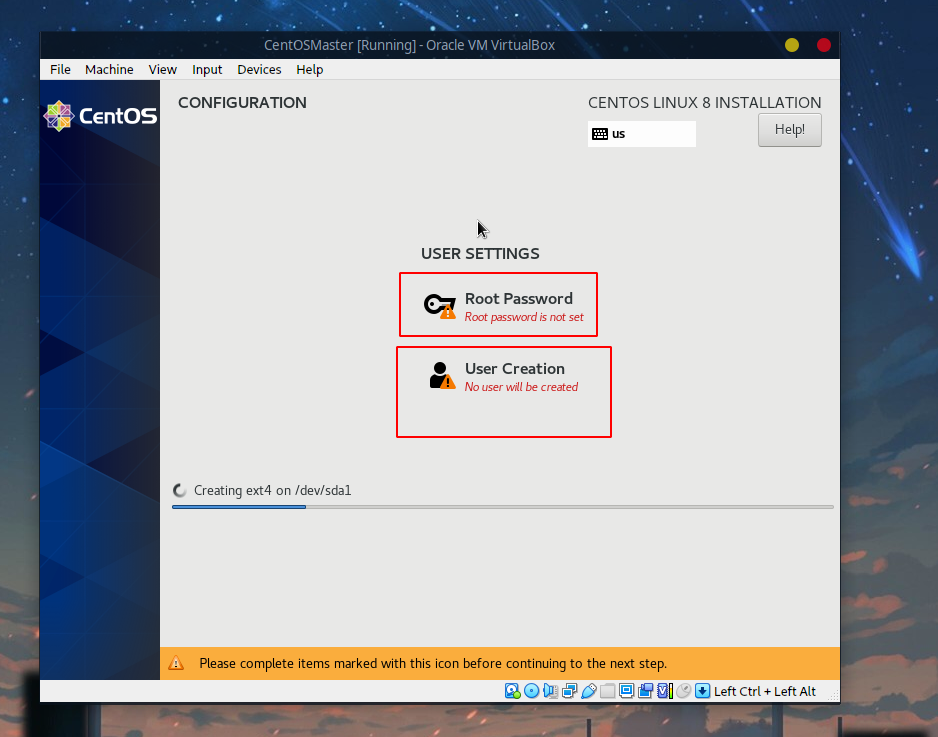
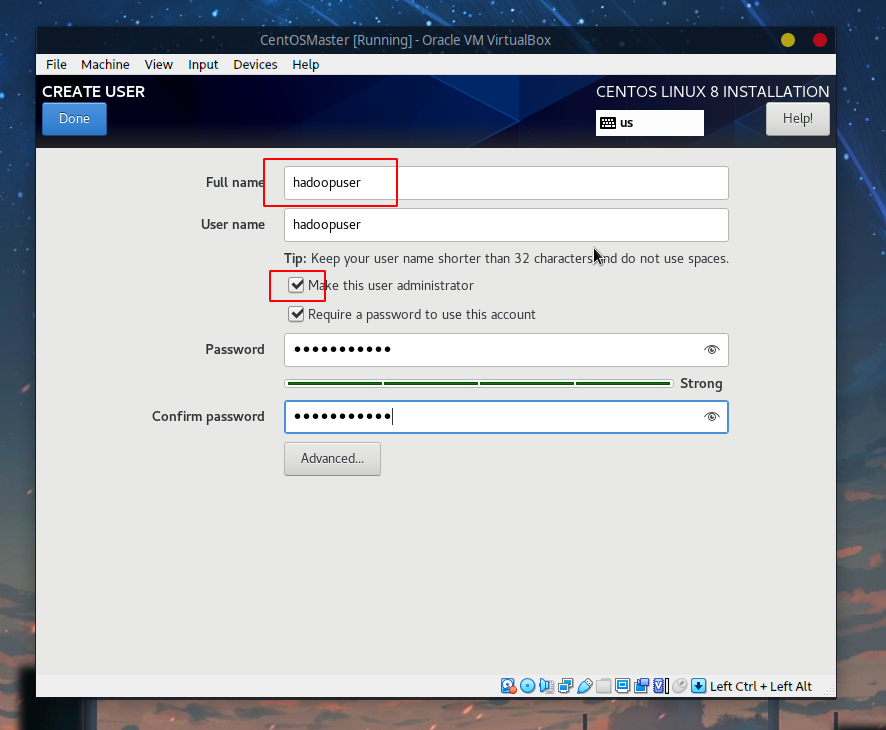
用户这里采用一个叫hadoopuser的用户,后面的操作都直接基于该用户:
等待一段时间后安装完成重启即可。
2.3 启动
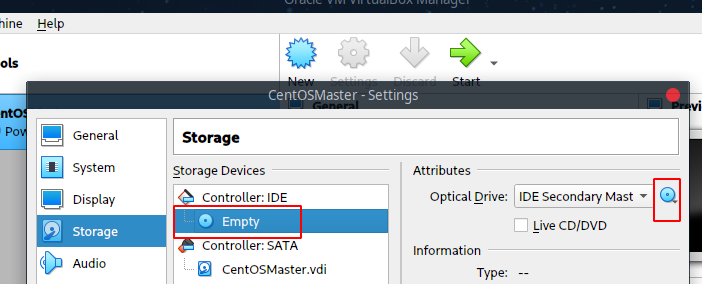
在启动之前首先把原来的镜像去掉:
启动后是黑框界面:
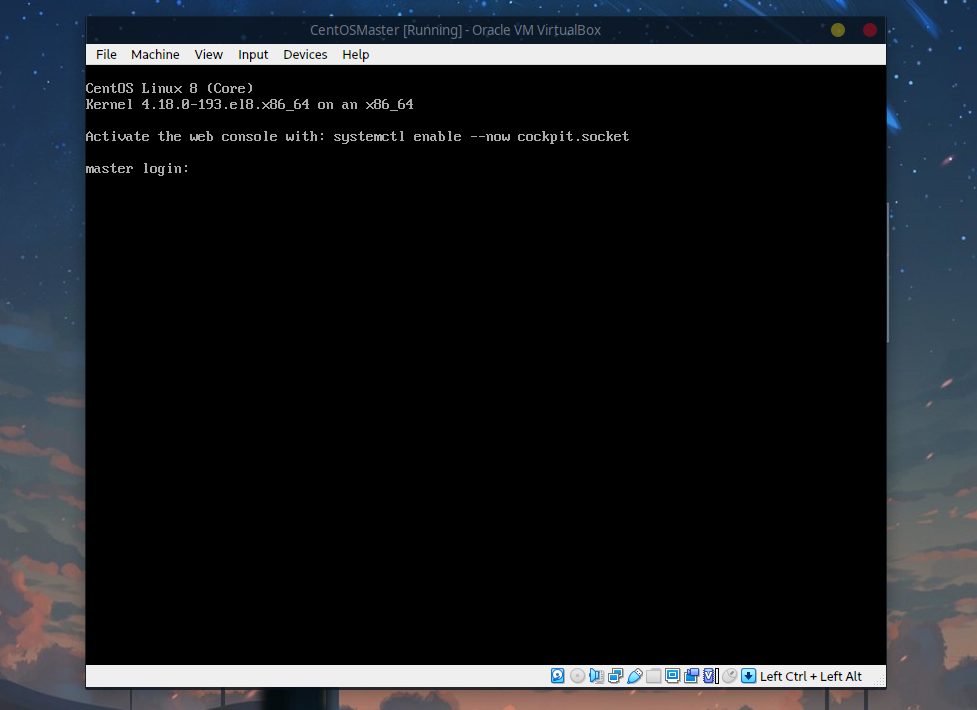
登录刚才创建的hadoopuser用户即可。
3 ssh连接虚拟机
默认的话是不能连接外网的,需要在菜单栏中的Devices中选择Network,设置为Bridged Adapter(桥接模式):
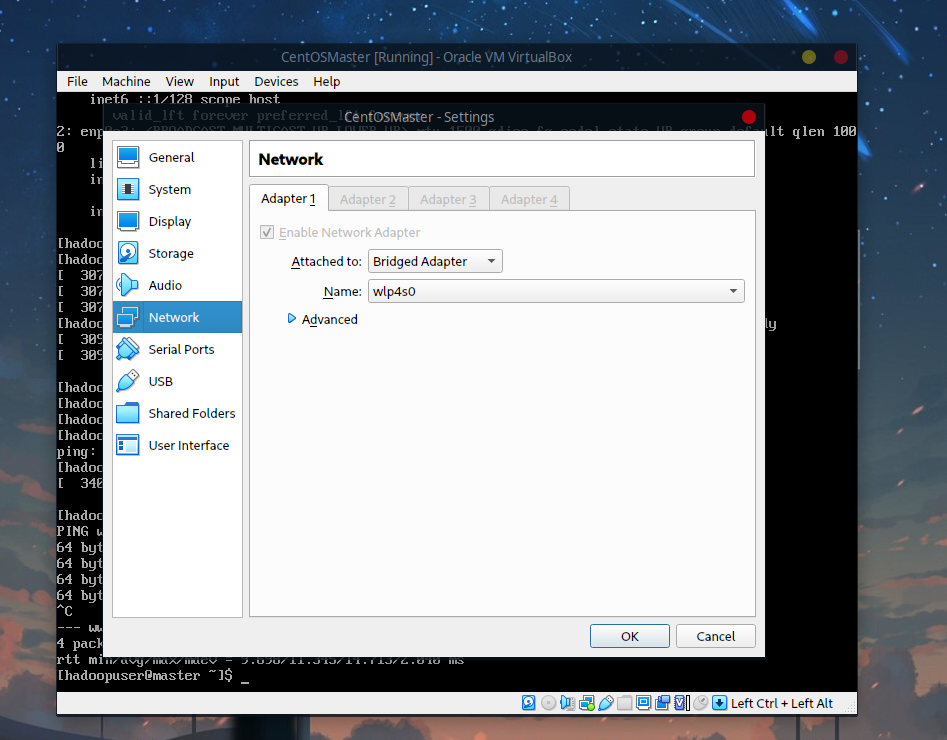
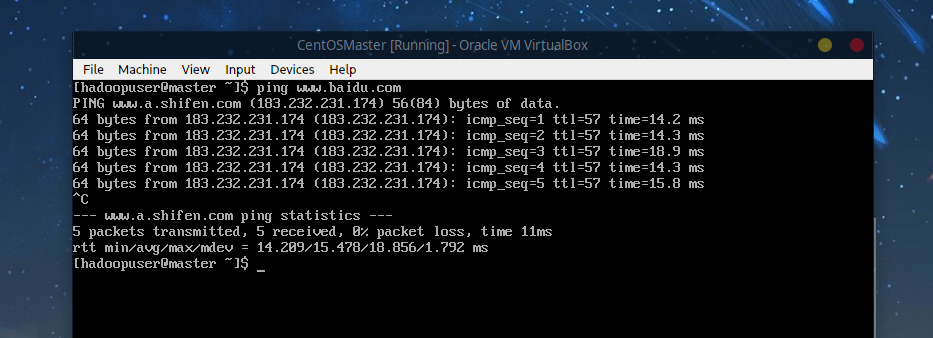
使用ping测试:
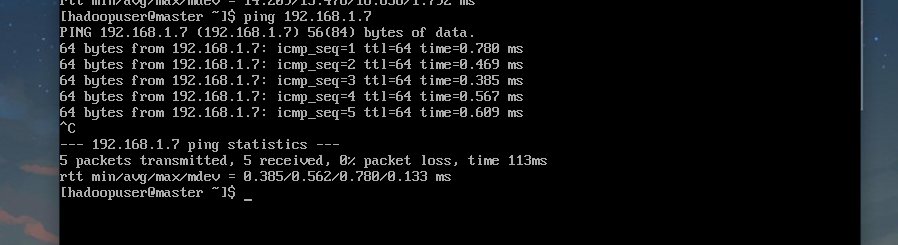
接着可以测试能否ping通本地机器:
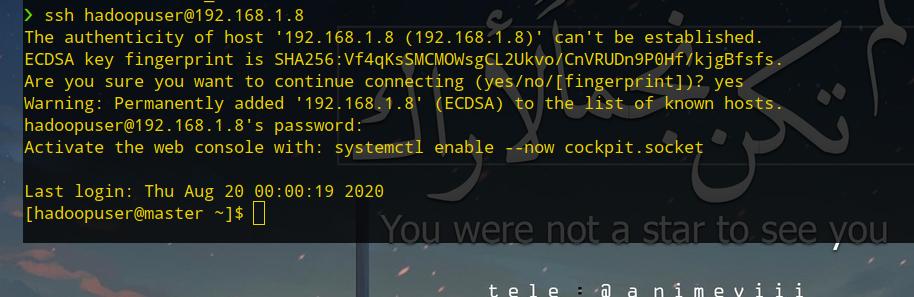
通了之后可以通过ssh连接虚拟机,像平时操作服务器一样,在本地终端中连接虚拟机,首先添加指纹:

接着输入密码连接即可:
如果想偷懒可以使用密钥连接的方式,在本地机器中:
ssh-keygen -t ed25519 -a 100
ssh-copy-id -i ~/.ssh/id_ed25519.pub hadoopuser@192.168.1.8
4 基本环境搭建
基本环境搭建就是安装JDK以及Hadoop,使用scp上传OpenJDK以及Hadoop。
4.1 JDK
首先去下载OpenJDK,然后在本地机器上使用scp上传:
scp openjdk-11+28_linux-x64_bin.tar.gz hadoopuser@192.168.1.8:/home/hadoopuser
接着在本地上切换到连接虚拟机的ssh中,
cd ~
tar -zxvf openjdk-11+28_linux-x64_bin.tar.gz
sudo mv jdk-11 /usr/local/java
下一步是编辑/etc/profile,添加bin到环境变量中,在末尾添加:
sudo vim /etc/profile
# 没有vim请使用vi
# 或安装:sudo yum install vim
# 添加
export PATH=$PATH:/usr/local/java/bin
然后:
. /etc/profile
测试:

4.2 Hadoop
Hadoop的压缩包scp上传到虚拟机后,解压并移动到/usr/local:
scp hadoop-3.3.0.tar.gz hadoopuser@192.168.1.8:/home/hadoopuser
虚拟机ssh终端:
cd ~
tar -xvf hadoop-3.3.0.tar.gz
sudo mv hadoop-3.3.0 /usr/local/hadoop
同时修改etc/hadoop/hadoop-env.sh配置文件,填入Java路径:
sudo vim /usr/local/hadoop/etc/hadoop/hadoop-env.sh
# 填入
export JAVA_HOME=/usr/local/java # 修改为您的Java目录
5 克隆
因为需要一个Master节点以及两个Worker节点,将Master节点关机,并选择配置好的CentOSMaster,右键进行克隆:
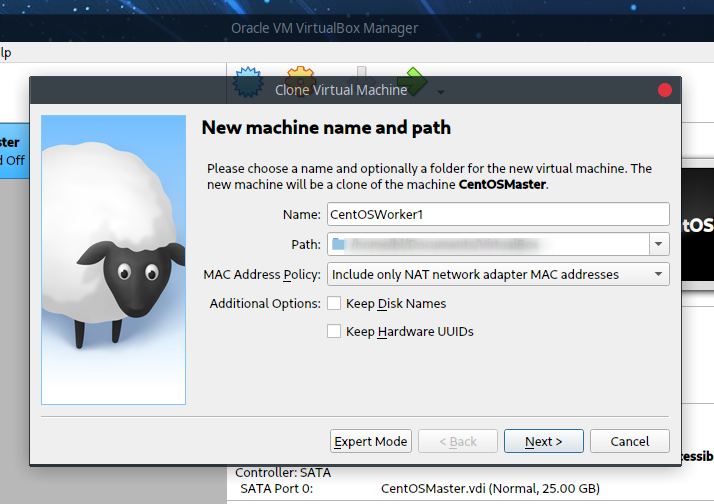
并选择完全克隆:
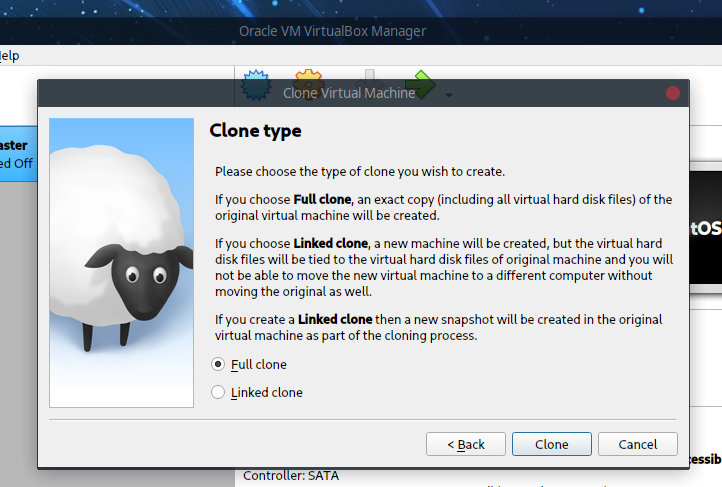
克隆出CentOSWorker1以及CentOSWorker2。
6 主机名+ip设置
这里的两个Worker节点以Worker1以及Worker2命名,首先操作Worker1,修改主机名:
sudo vim /etc/hostname
# 输入
# worker1
对于ip,由于Master节点的ip为192.168.1.8,因此这里修改两个Worker的节点分别为:
192.168.1.9192.168.1.10
sudo vim /etc/sysconfig/network-scripts/ifcfg-xxxx # 该文件因人而异
# 修改IPADDR
IPADDR=192.168.1.9
修改完成后重启Worker1,对Worker2进行同样的修改主机名以及ip操作。
7 Host设置
需要在Master以及Worker节点进行Host设置:
7.1 Master节点
sudo vim /etc/hosts
# 添加
192.168.1.9 worker1 # 与上面的ip对应一致
192.168.1.10 worker2
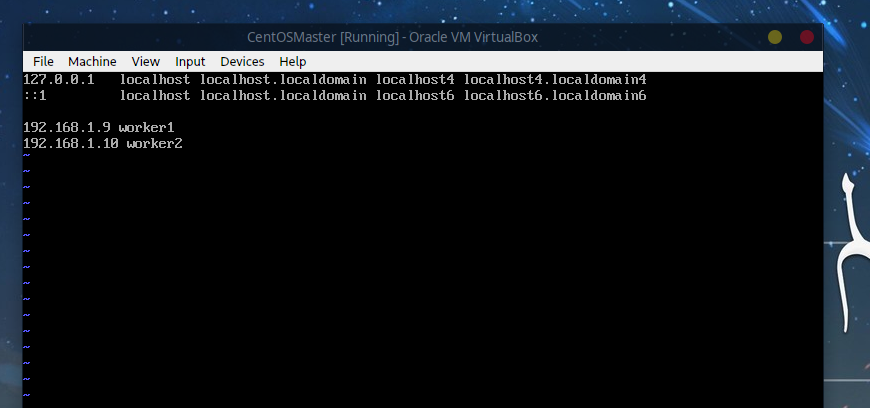
7.2 Worker1节点
sudo vim /etc/hosts
# 添加
192.168.1.8 master
192.168.1.10 worker2
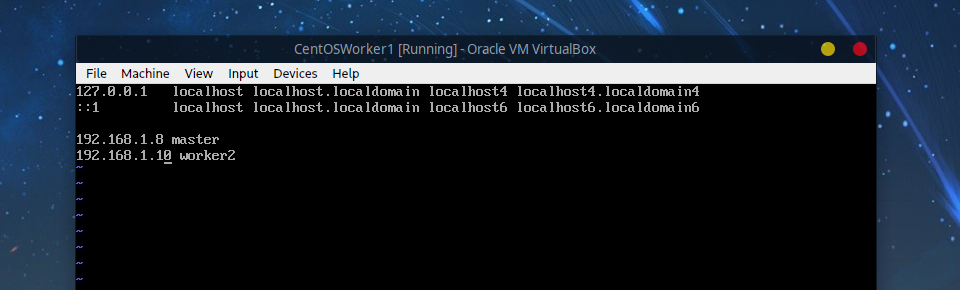
7.3 Worker2节点
sudo vim /etc/hosts
# 添加
192.168.1.8 master
192.168.1.9 worker1
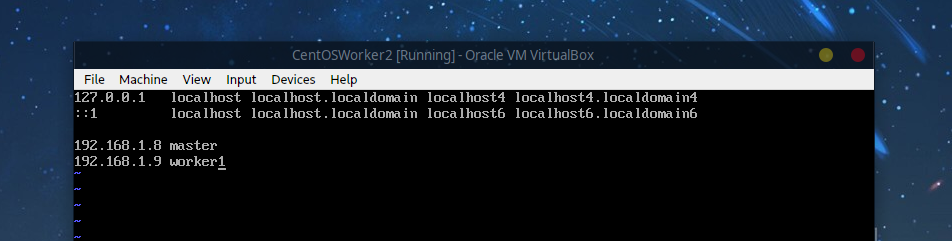
7.4 互ping测试
在三台虚拟机中的其中一台ping另外两台的ip或者主机名,测试通过后就可以进行下一步了,这里使用Worker1节点测试:
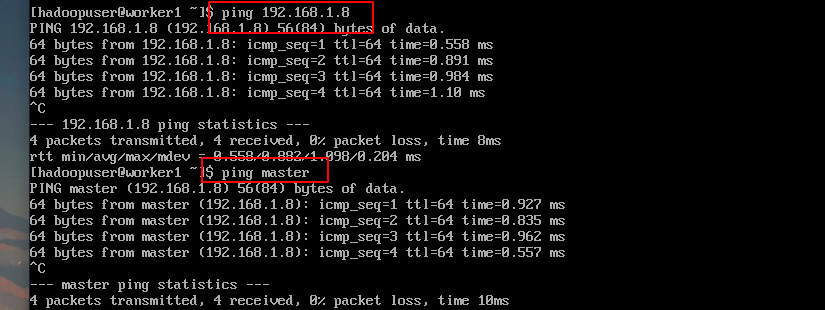
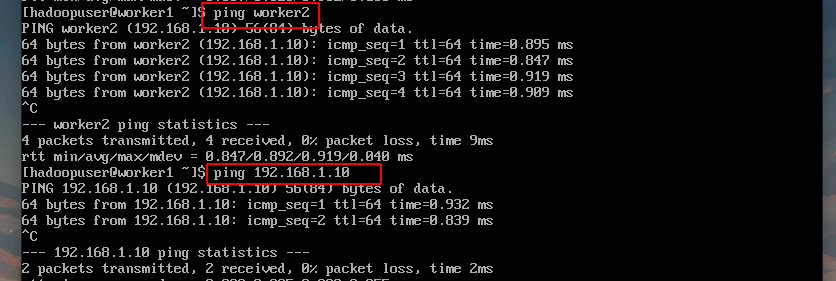
8 配置ssh
8.1 sshd服务
需要在三个节点(包括自身)之间配置ssh无密码(密钥)连接,首先使用
systemctl status sshd
检查sshd服务是否开启,没开启的使用
systemctl start sshd
开启。
8.2 复制公钥
三个节点都进行如下操作:
ssh-keygen -t ed25519 -a 100
ssh-copy-id master
ssh-copy-id worker1
ssh-copy-id worker2
8.3 测试
在其中一个节点中直接ssh连接其他节点,无需密码即可登录,比如在Master节点中:
ssh master # 都是hadoopuser用户,所以省略了用户
ssh worker1
ssh worker2
9 Master节点Hadoop配置
在Master节点中,修改以下三个配置文件:
HADOOP/etc/hadoop/core-site.xmlHADOOP/etc/hadoop/hdfs-site.xmlHADOOP/etc/hadoop/workers
9.1 core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/data/tmp</value>
</property>
</configuration>
fs.defaultFS:NameNode地址hadoop.tmp.dir:Hadoop临时目录
9.2 hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/local/hadoop/data/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/local/hadoop/data/datanode</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
</configuration>
dfs.namenode.name.dir:保存FSImage的目录,存放NameNode的metadatadfs.datanode.data.dir:保存HDFS数据的目录,存放DataNode的多个数据块dfs.replication:HDFS存储的临时备份数量,有两个Worker节点,因此数值为2
9.3 workers
最后修改workers,输入(与上面设置的主机名一致):
worker1
worker2
9.4 复制配置文件
把Master节点的配置复制到Worker节点:
scp /usr/local/hadoop/etc/hadoop/* worker1:/usr/local/hadoop/etc/hadoop/
scp /usr/local/hadoop/etc/hadoop/* worker2:/usr/local/hadoop/etc/hadoop/
10 HDFS格式化并启动
10.1 启动
在Master节点中:
cd /usr/local/hadoop
bin/hdfs namenode -format
sbin/start-dfs.sh
运行后可以通过jps命令查看:

在Worker节点中:


10.2 测试
浏览器输入:
master:9870
# 如果没有修改本机Host可以输入
# 192.168.1.8:9870
但是。。。
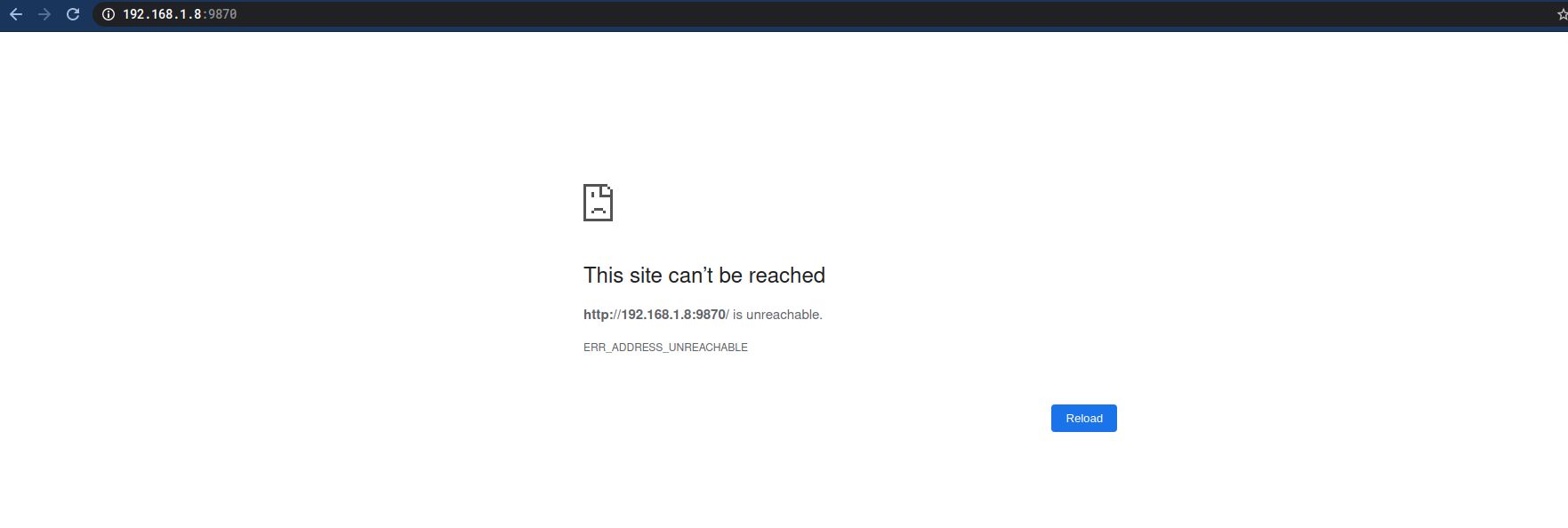
本以为做了这么多能看到成果了。
然后检查过了一遍本机+虚拟机Host,还有Hadoop的配置文件,都没有问题。
最后,
才定位到问题是
防火墙。
10.3 防火墙
CentOS8默认开启了防火墙,可以使用:
systemctl status firewalld
查看防火墙状态。
由于是通过9870端口访问,首先查询9870是否开放,Master节点中输入:
sudo firewall-cmd --query-port=9870/tcp
# 或
sudo firewall-cmd --list-ports
如果输出为no:

则表示没有开放,手动开放即可:
sudo firewall-cmd --add-port=9870/tcp --permanent
sudo firewall-cmd --reload # 使其生效

再次在浏览器输入:
master:9870
# 如果没有修改本地Host
# 192.168.1.8:9870
可以看到一个友好的页面了:
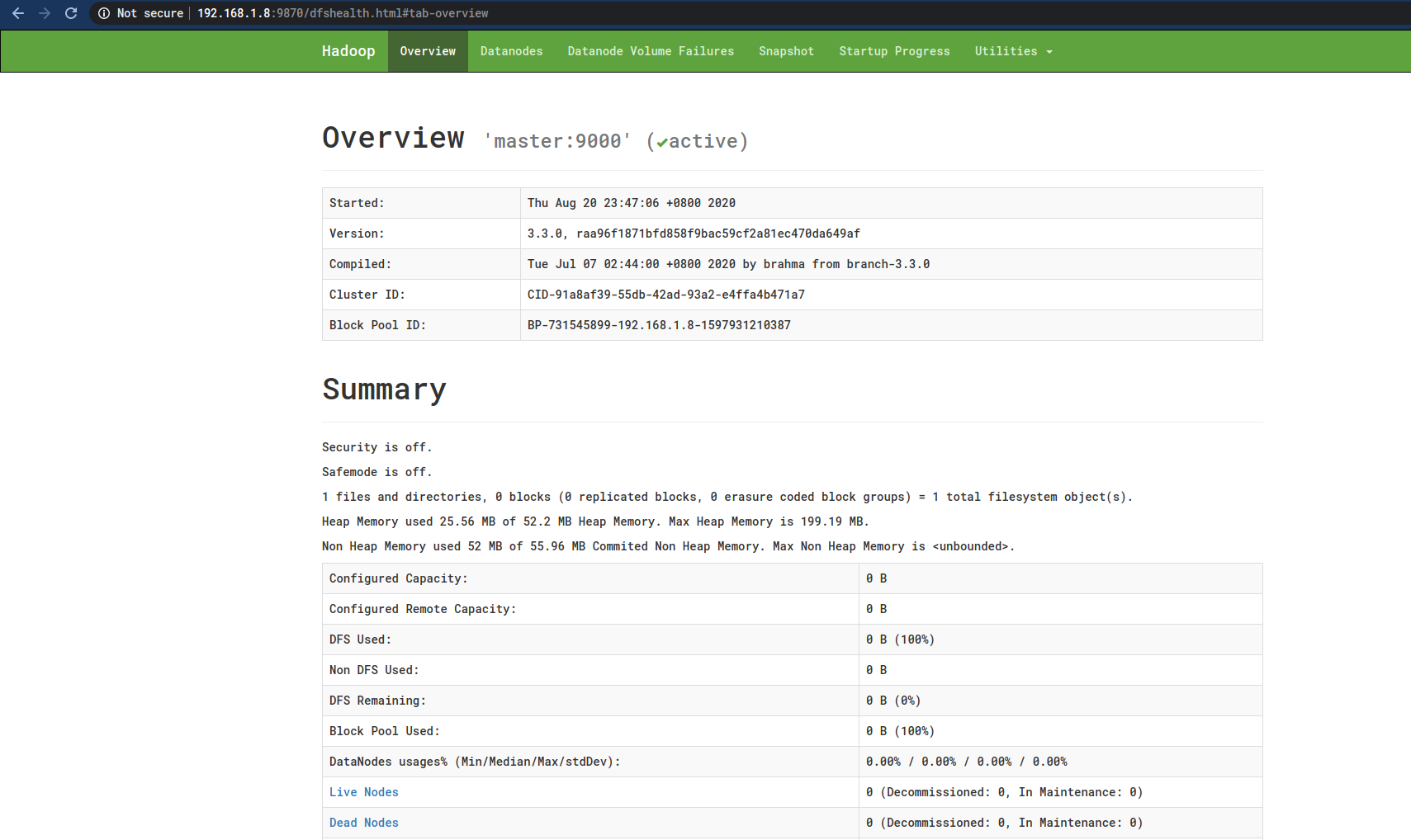
但是,有一个问题就是这里没有显示Worker节点,上图中的Live Nodes数目为0 ,而Datanodes这里什么也没有显示:
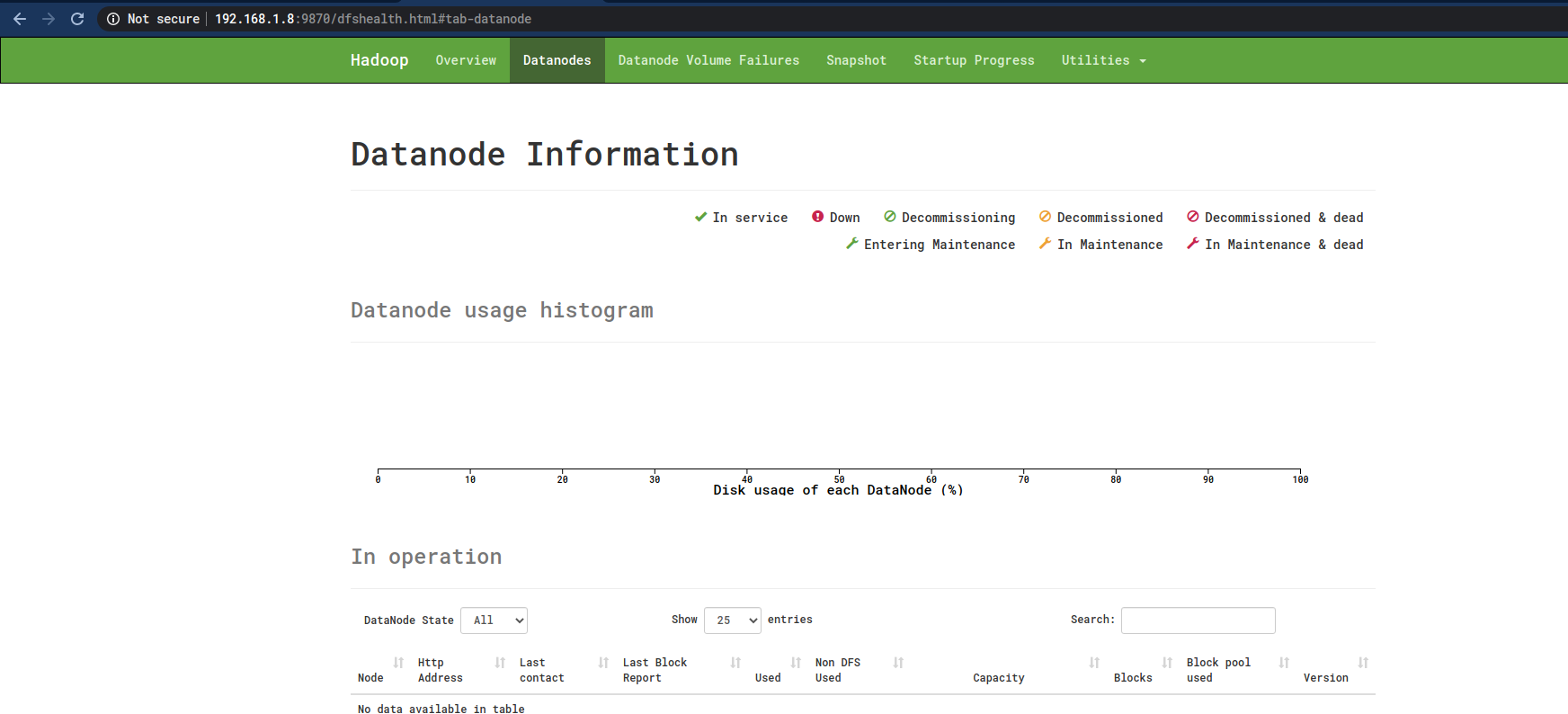
但是在Worker节点中的确可以看到有Datanode的进程了:


查看Worker节点的日志(/usr/local/hadoop/logs/hadoop-hadoopuser-datanode-worker1.log)可以看到应该是Master节点9000端口的没有开启的问题:
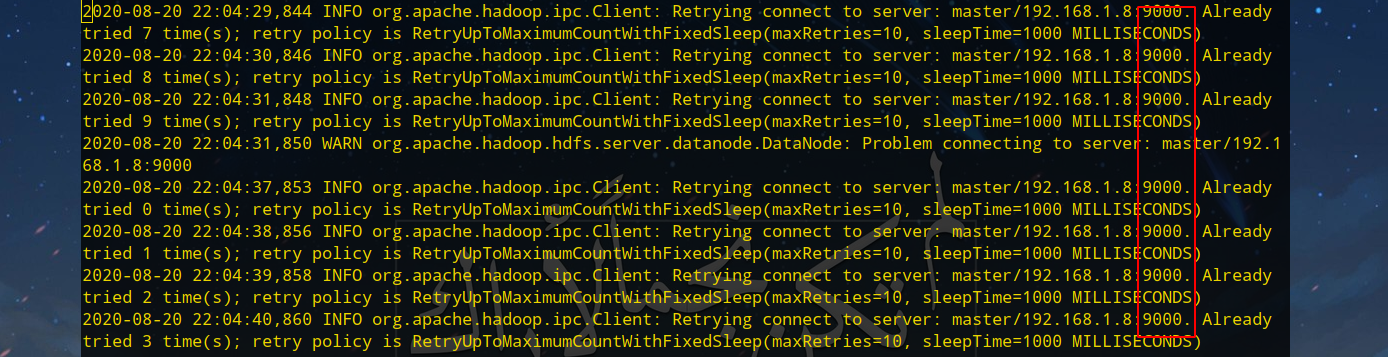
回到Master节点,先执行stop-dfs.sh关闭,并开放9000端口后执行start-dfs.sh开启:
/usr/local/hadoop/sbin/stop-dfs.sh
sudo firewall-cmd --add-port=9000/tcp --permanent
sudo firewall-cmd --reload
/usr/local/hadoop/sbin/start-dfs.sh
再次在浏览器访问:
master:9000
# 或
# 192.168.1.8:9000
这时候就可以看见Worker节点了:
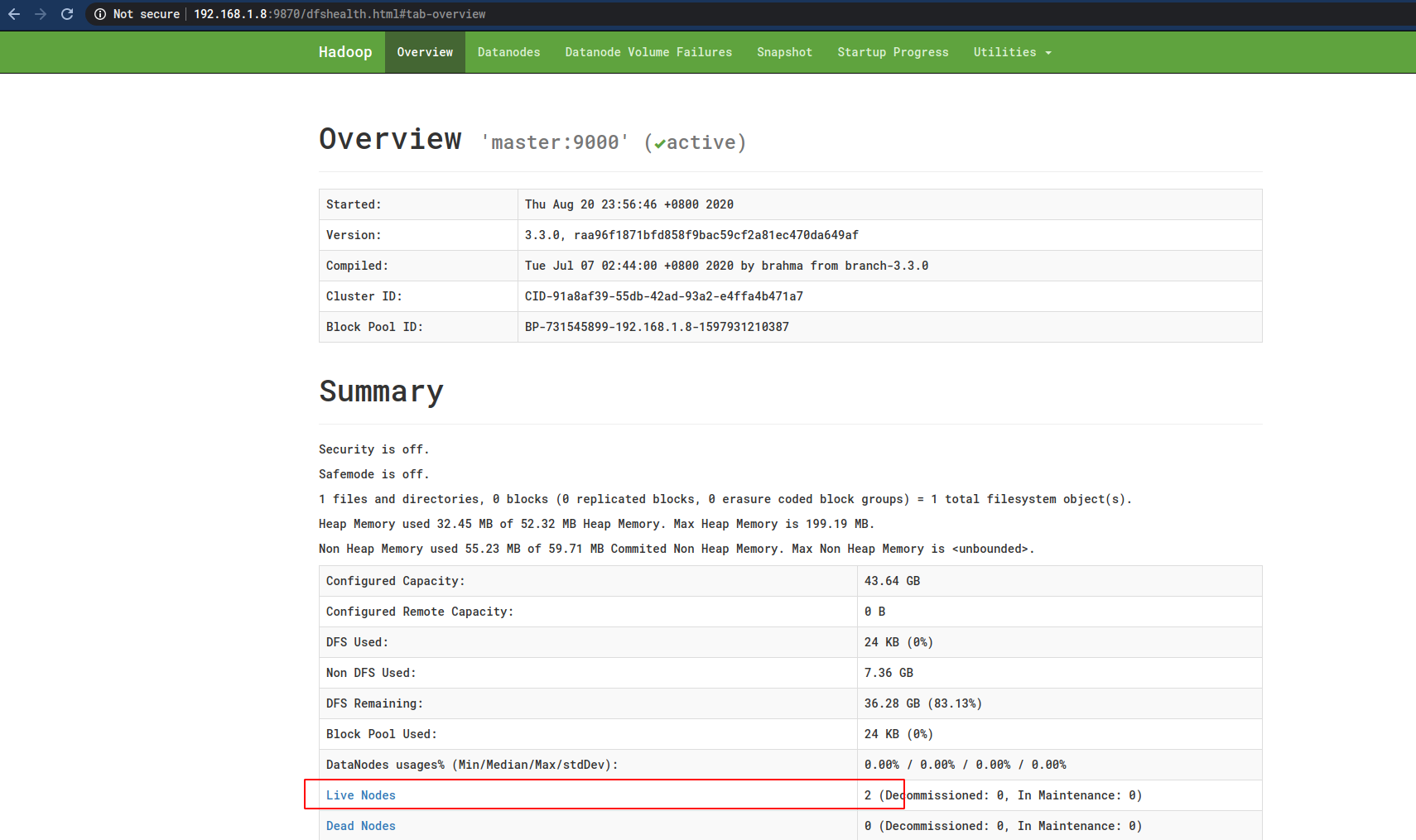
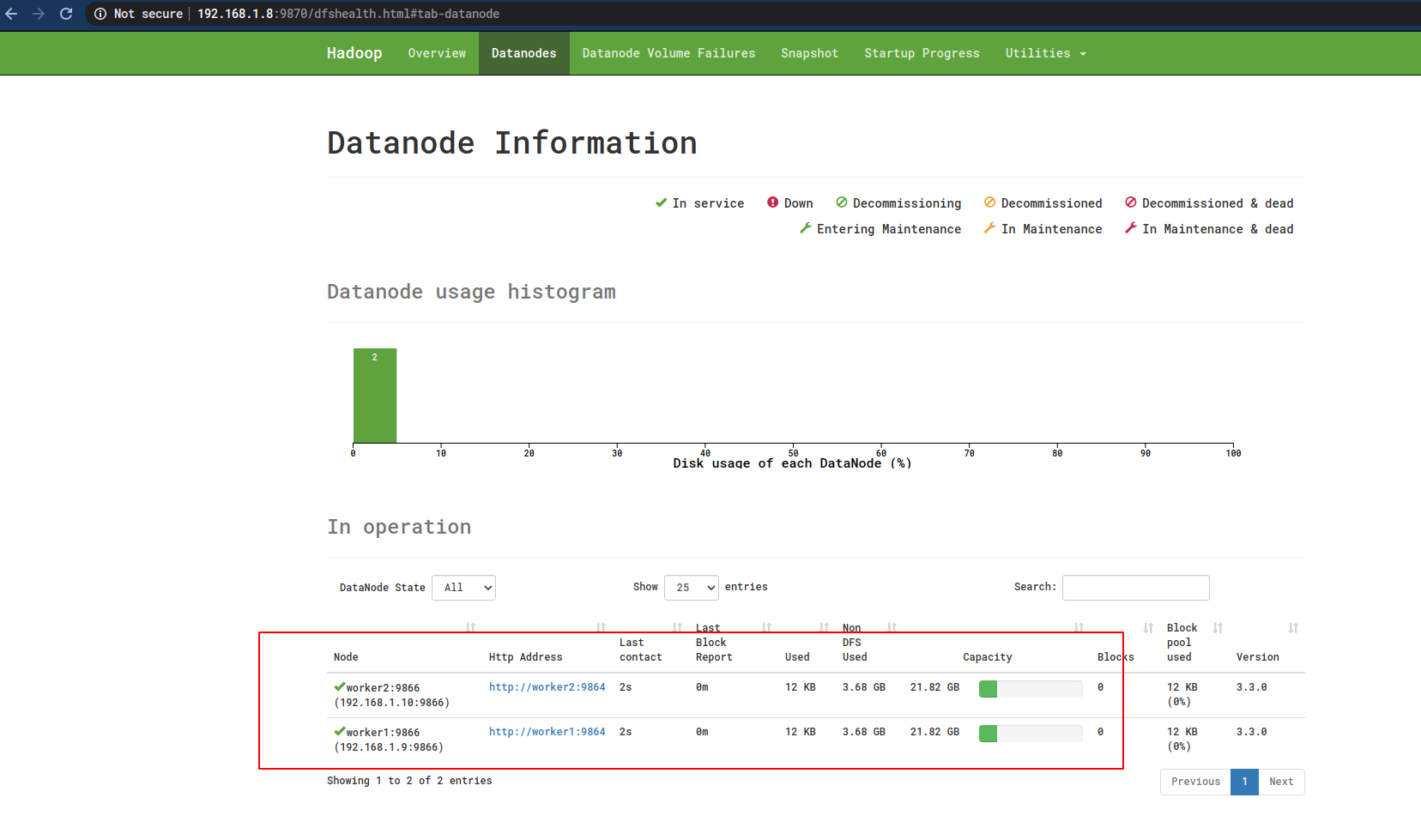
11 配置YARN
11.1 YARN配置
在两个Worker节点中修改/usr/local/hadoop/etc/hadoop/yarn-site.xml:
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
11.2 开启YARN
Master节点中开启YARN:
cd /usr/local/hadoop
sbin/start-yarn.sh
同时开放8088端口为下面的测试做准备:
sudo firewall-cmd --add-port=8088/tcp --permanent
sudo firewall-cmd --reload
11.3 测试
浏览器输入:
master:8088
# 或
# 192.168.1.8:8088
应该就可以访问如下页面了:
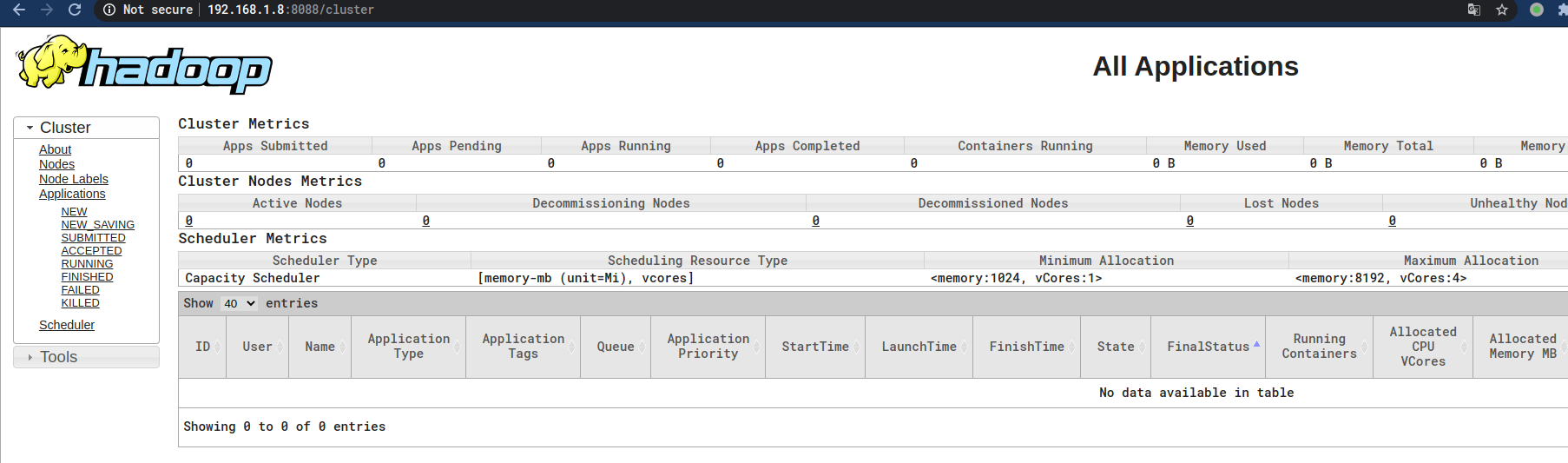
同样道理没有看到Worker节点,查看Worker节点的日志,发现也是端口的问题:
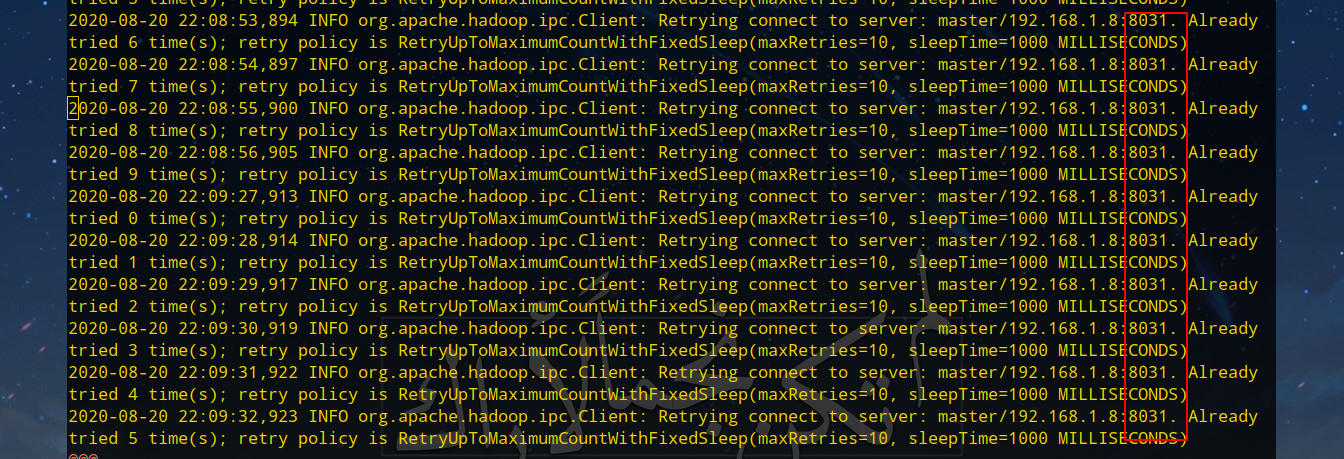
Master节点先关闭YARN,开放8031端口,并重启YARN:
/usr/local/hadoop/sbin/stop-yarn.sh
sudo firewall-cmd --add-port=8031/tcp --permanent
sudo firewall-cmd --reload
/usr/local/hadoop/sbin/start-yarn.sh
再次访问:
master:8088
# 或
# 192.168.1.8:8088
就可以看到Worker节点了:
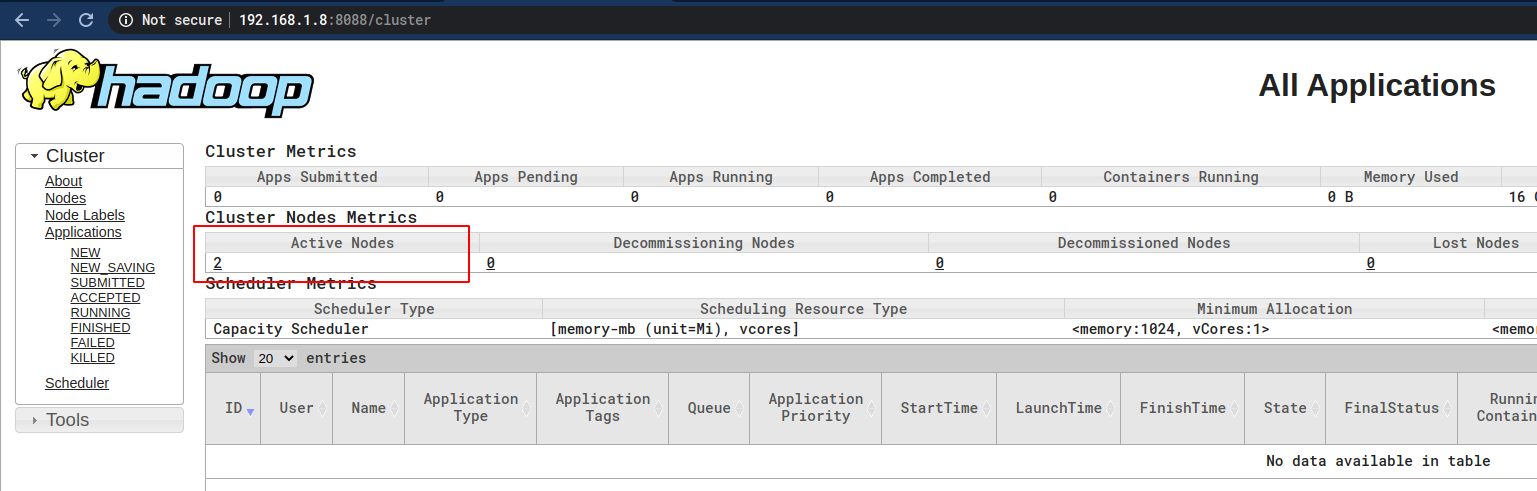
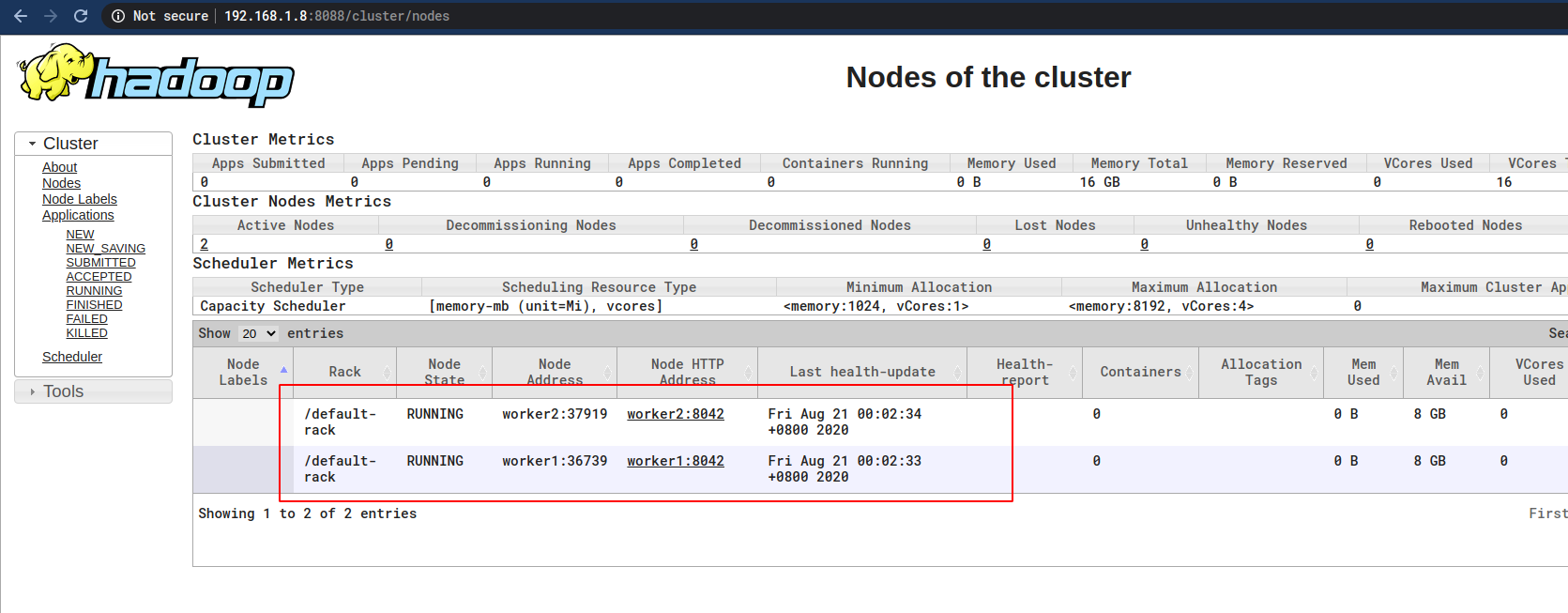
至此,虚拟机组成Hadoop集群正式搭建完成。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号