Hadoop完整搭建过程(二):伪分布模式
1 伪分布模式
伪分布模式是运行在单个节点以及多个Java进程上的模式。相比起本地模式,需要进行更多配置文件的设置以及ssh、YARN相关设置。
2 Hadoop配置文件
修改Hadoop安装目录下的三个配置文件:
etc/hadoop/core-site.xmletc/hadoop/hdfs-site.xmletc/hadoop/hadoop-env.sh
2.1 core-site.xml
首先修改core-site.xml:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/hadoop/tmp</value>
</property>
</configuration>
fs.defaultFS设置的是HDFS的地址,设置运行在本地的9000端口上hadoop.tmp.dir设置的是临时目录,如果没有设置的话默认在/tmp/hadoop-${user.name}中,系统重启后会导致数据丢失,因此修改这个临时目录的路径
接着创建该临时目录:
mkdir -p /usr/local/hadoop/tmp
2.2 hdfs-site.xml
接着修改hdfs-site.xml:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
dfs.replication设置的是HDFS存储的临时备份数量,因为伪分布模式中只有一个节点,所以设置为1。
2.3 hadoop-env.sh
修改该文件添加JAVA_HOME环境变量,就算JAVA_HOME在
~/.bashrc~/.bash_profile/etc/profile
等中设置了,运行时也是会提示找不到JAVA_HOME,因此需要手动在hadoop-env.sh中设置JAVA_HOME:
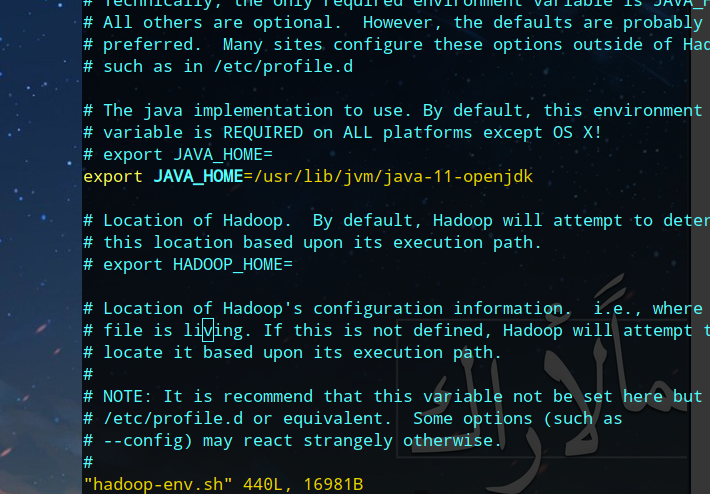
3 本地无密码ssh连接
下一步需要设置本地无密码ssh连接,首先先检查确保开启sshd服务:
systemctl status sshd
开启后可以直接localhost连接:
ssh localhost
输入自己的用户密码后就可以访问了,但是这里需要的是无密码连接,因此配置密钥认证连接的方式:
ssh-keygen -t ed25519 -a 100
cat ~/.ssh/id_25519.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keys
这里生成公私钥后把公钥添加到authorized_keys中,并且修改权限,需要注意600权限,只能本用户有写权限。
然后直接ssh localhost就可以连接本地主机了。
4 运行
4.1 格式化HDFS
这里以单一节点的模式运行,首先格式化HDFS:
# HADOOP为Hadoop安装目录
HADOOP/bin/hdfs namenode -format
格式化是对HDFS中的DataNode进行分块,统计所有分块后的初始元数据,存储在NameNode中。
格式化成功后会在上面配置文件中设置的临时目录中生成dfs目录,如下所示:

里面只有一个目录:dfs/name/current,其中tmp/dfs/name/current的文件如下:

文件说明如下:
fsimage:NameNode元数据在内存满后,持久化保存到的文件fsimage*.md5:校验文件,用于校验fsimage的完整性seen_txid:存放transactionID文件,format之后为0,表示NameNode里面的edits_*文件的尾数VERSION:保存创建时间,namespaceID、blockpoolID、storageType、cTime、clusterID、layoutVersion
关于VERSION的说明:
namespaceID:HDFS唯一标识符,在HDFS首次格式化后生成blockpoolID:标识一个block pool,跨集群全局唯一storageType:存储什么进程的数据结构信息cTime:创建时间clusterID:系统生成或指定的集群ID,可以使用-clusterid指定layoutVersion:表示HDFS永久性数据结构版本的信息
4.2 启动NameNode
HADOOP/sbin/start-dfs.sh
然后可以通过
localhost:9870
访问NameNode:
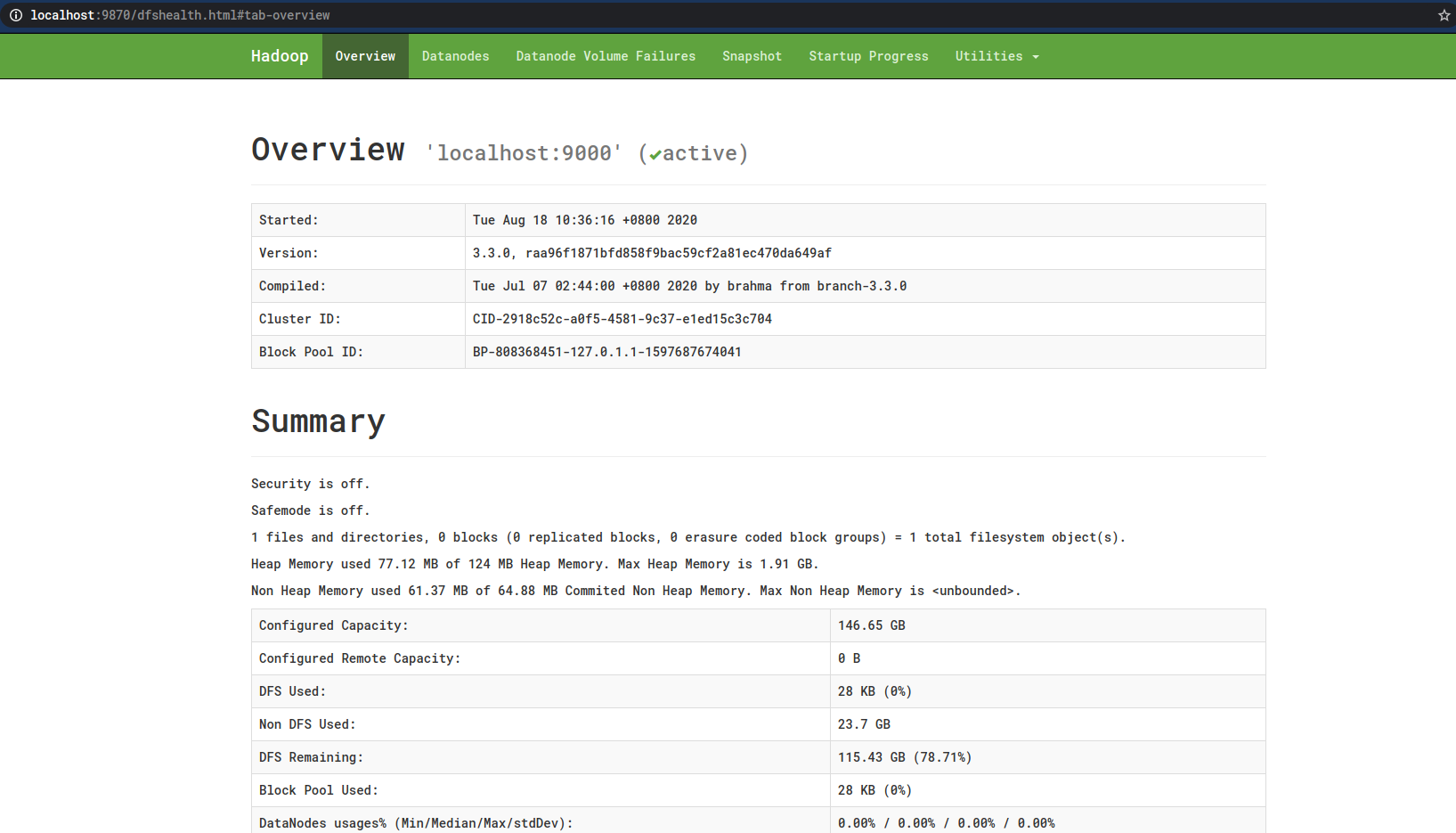
4.3 测试
生成输入目录,并使用配置文件作为输入:
bin/hdfs dfs -mkdir /user
bin/hdfs dfs -mkdir /user/USER_NAME # USER_NAME为您的用户名
bin/hdfs dfs -mkdir input
bin/hdfs dfs -put etc/hadoop/*.xml input
测试:
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.0.jar grep input output 'dfs[a-z.]+'
获取输出:
bin/hdfs dfs -get output output # 复制输出到output目录
cat output/*
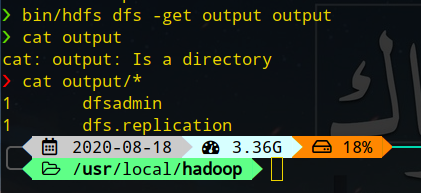
停止:
sbin/stop-hdfs.sh
5 使用YARN配置
除了可以将单个节点以伪分布模式启动,还可以通过YARN统一调度,只需要适当修改配置文件。
5.1 配置文件
修改以下文件:
HADOOP/etc/hadoop/mapred-site.xmlHADOOP/etc/hadoop/yarn-site.xml
5.1.1 mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*</value>
</property>
</configuration>
mapreduce.framework.name指定了MapReduce运行在YARN上mapreduce.application.classpath指定了类路径
5.1.2 yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>
yarn.nodemanager.aux-services:运行在NodeManager上运行的附属服务yarn.nodemanager.env-whitelist:环境变量通过从NodeManagers的容器继承的环境属性
5.2 运行
sbin/start-yarn.sh
运行后就可以通过
localhost:8088
访问:
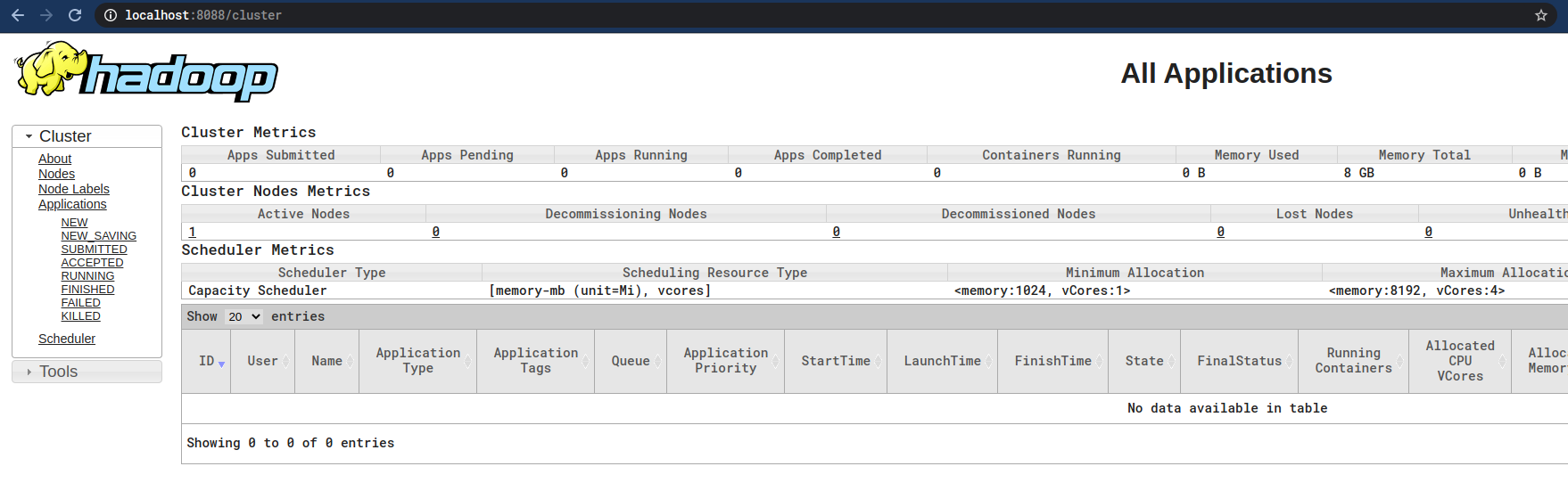
停止:
sbin/stop-yarn.sh

 浙公网安备 33010602011771号
浙公网安备 33010602011771号