torch.arange()和torch.arange().reshape()和torch.transpose()可视化理解
torch.arange(24) # tensor([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23])
其可视化为:
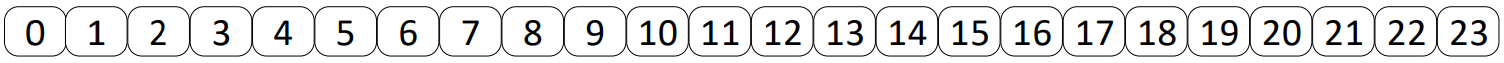
torch.arange().reshape()
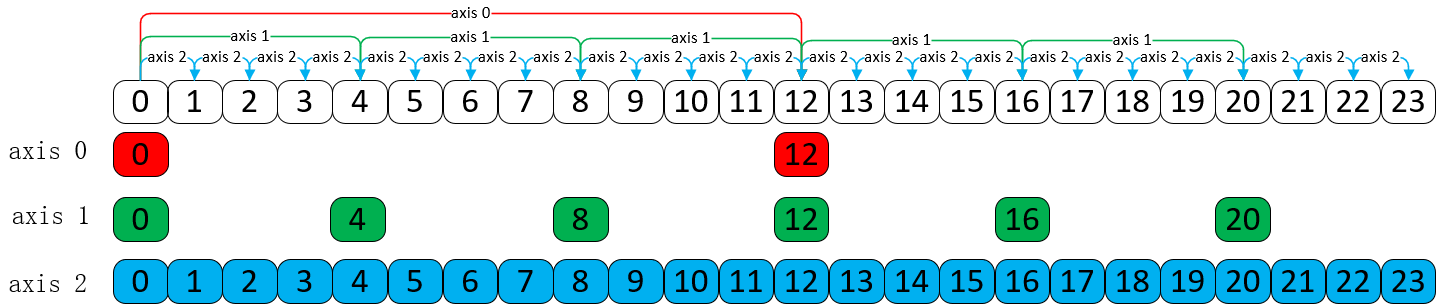
对上述的一维Tensor 通过 reshape 产生三维Tensor,其 shape = [2, 3, 4]。
torch.arange(24).reshape((2,3,4)) # tensor([[[ 0, 1, 2, 3], # [ 4, 5, 6, 7], # [ 8, 9, 10, 11]], # # [[12, 13, 14, 15], # [16, 17, 18, 19], # [20, 21, 22, 23]]])
其实 Tensor 是以 一维Tensor 进行存储,只不过组合的时候每个维度通过不同的步长(Stride)进行组合,以呈现给我们。
torch.arange(24).reshape((2,3,4)).stride() # (12, 4, 1)
如上可以看到,第0个维度的步长是12,第1个维度的步长是4,第2个维度的步长是1,因此通过选取和组合后,其可视化如下所示。
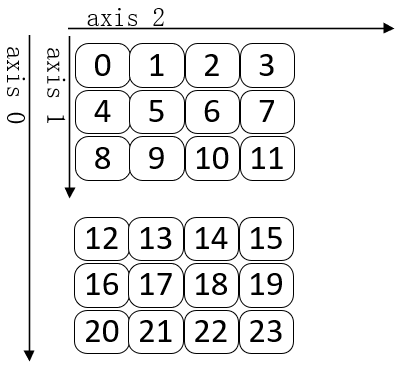
torch.arange().reshape().transpose()
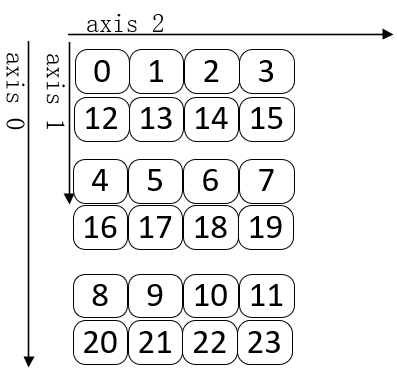
torch.transpose()正如前面所说的,它是转置,即交换维度,以及步长(Stride)。
torch.arange(24).reshape((2,3,4)).transpose(0,1) # tensor([[[ 0, 1, 2, 3], # [12, 13, 14, 15]], # # [[ 4, 5, 6, 7], # [16, 17, 18, 19]], # # [[ 8, 9, 10, 11], # [20, 21, 22, 23]]]) torch.arange(24).reshape((2,3,4)).transpose(0,1).shape # torch.Size([3, 2, 4]) torch.arange(24).reshape((2,3,4)).transpose(0,1).stride() # (4, 12, 1)
可以看到它的 shape 从 [2, 3, 4] -> [3, 2, 4],stride 从 (12, 4, 1) -> (4, 12, 1)。其可视化如下所示。
三、扩展知识
对于上面这三个维度,可以从词嵌入理解:第0维度是句子的个数(batch_size),第1个维度是单词的数量(vocab),第2个维度是每个单词的最大维度(d_model)。那么对于 shape = [2, 3, 4] 来说,有2个句子(batch_size),每个句子有3个单词(vocab),每个单词的维度是4(d_model)。
在 Transformer 中,对于 Input Embedding + Position Embedding ,相加的只是最后一个维度(即第2个维度,也就是词向量的维度d_model), 它是将 x.shape = [batch_size, src_len, d_model] 通过torch.transpose()函数将其变成 x.shape = [src_len, batch_size, d_model],然后与Position Embedding 在 d_model 上进行相加,加完之后,再通过torch.transpose()函数将其变成 [batch_size, src_len, d_model],进行后续的处理。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号