解决火车头如何采集93高考网数据,附上代码
今天在群里看到一个哥们说起93高考网,他的网址是进行base64进行加密,无法通过火车头等工具进行采集,而且他的分页最大只支持10页。所以就写了以下接口:
使用方法:
在自己网站新建一个文件,例如:geturl.php
<?php
//获取参赛id
$id=$_GET['id'];
$cat=$_GET['cat'];
$id=base64_encode($id);
if($cat){
$url= "https://www.93gaokao.com/".$cat."/".$id.".html";
}else{
$url= "https://www.93gaokao.com/zixun/".$id.".html";
}
function curl_request ( $url , $post = '' , $cookie = '' , $returncookie = 0 ) {
$curl = curl_init ( ) ;
curl_setopt ( $curl , CURLOPT_URL , $url ) ;
curl_setopt ( $curl , CURLOPT_USERAGENT , 'Mozilla/5.0 (compatible; Baiduspider/2.0; +http://www.baidu.com/search/spider.html)');
curl_setopt ( $curl , CURLOPT_FOLLOWLOCATION , 1 ) ;
curl_setopt ( $curl , CURLOPT_AUTOREFERER , 1 ) ;
curl_setopt ( $curl , CURLOPT_REFERER , "https://www.baidu.com" ) ;
if ( $post ) {
curl_setopt ( $curl , CURLOPT_POST , 1 ) ;
curl_setopt ( $curl , CURLOPT_POSTFIELDS , http_build_query ( $post ) ) ;
}
if ( $cookie ) {
curl_setopt ( $curl , CURLOPT_cookie , $cookie ) ;
}
curl_setopt($curl, CURLOPT_SSL_VERIFYPEER, false);
curl_setopt($curl, CURLOPT_SSL_VERIFYHOST, false);
curl_setopt ( $curl , CURLOPT_HEADER , $returncookie ) ;
curl_setopt ( $curl , CURLOPT_TIMEOUT , 10 ) ;
curl_setopt ( $curl , CURLOPT_RETURNTRANSFER , 1 ) ;
$data = curl_exec ( $curl ) ;
if ( curl_errno ( $curl ) ) {
return curl_error ( $curl ) ;
}
curl_close ( $curl ) ;
if ( $returncookie ) {
list ( $header , $body ) = explode ( "\r\n\r\n" , $data , 2 ) ;
preg_match_all ( "/Set\-cookie:([^;]*);/" , $header , $matches ) ;
$info [ 'cookie' ] = substr ( $matches [ 1 ] [ 0 ] , 1 ) ;
$info [ 'content' ] = $body ;
return $info ;
} else {
//return $data ;
echo $data;
}
}
curl_request ( $url, $post = '' , $cookie = '' , $returncookie = 0 );
//header('HTTP/1.1 301 Moved Permanently');
//Header("Location:".$url);
?>
调取为:geturl.php?cat=[分类名称]&id=[id]
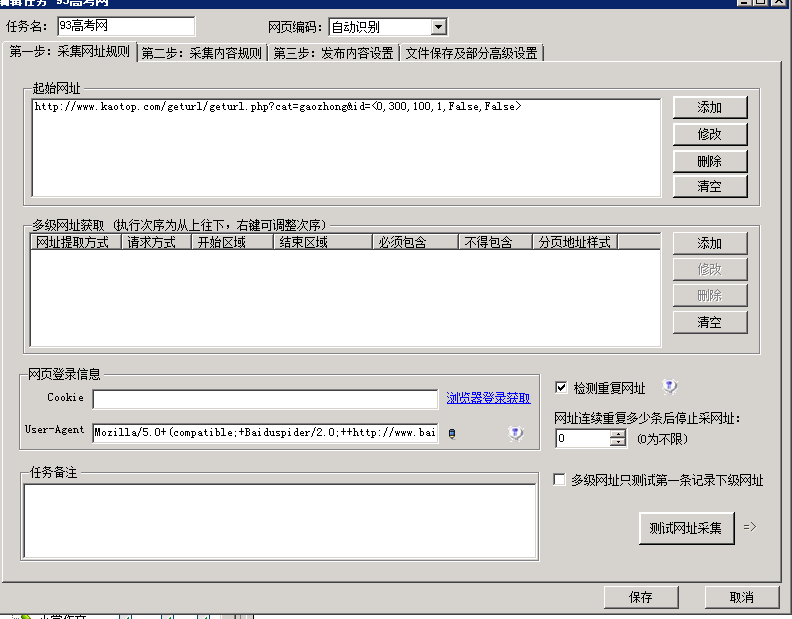
比如我要调取高中分类下id为1的文章,即可geturl.php?cat=gaozhong&id=id
文章转自:http://www.kaotop.com/it/415135.html

千行代码,Bug何处藏。 纵使上线又怎样,朝令改,夕断肠。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号