解决火车头7.6版本无法采集部分https网站处理方法
因为现在大多数网站都采取https,导致很多网站无法采集。那哪行,肯定得有解决办法,今日就说说关于火车头采集器7.6版本无法采集部分https网站处理方法。
火车头7.6版本由于发布时间久远,虽然采集器大部分功能都还可以正常使用,但是现在很多网站都从之前的http协议切换到了https协议。

现在怎么解决呢?办法就是通过php进行抓取数据,把文章标签都获取
只要网站目录新建一个接口,例如geturl/index.php
代码附下载,你们下载,放在网站根目录建个文件夹,例如:geturl,调用如下:
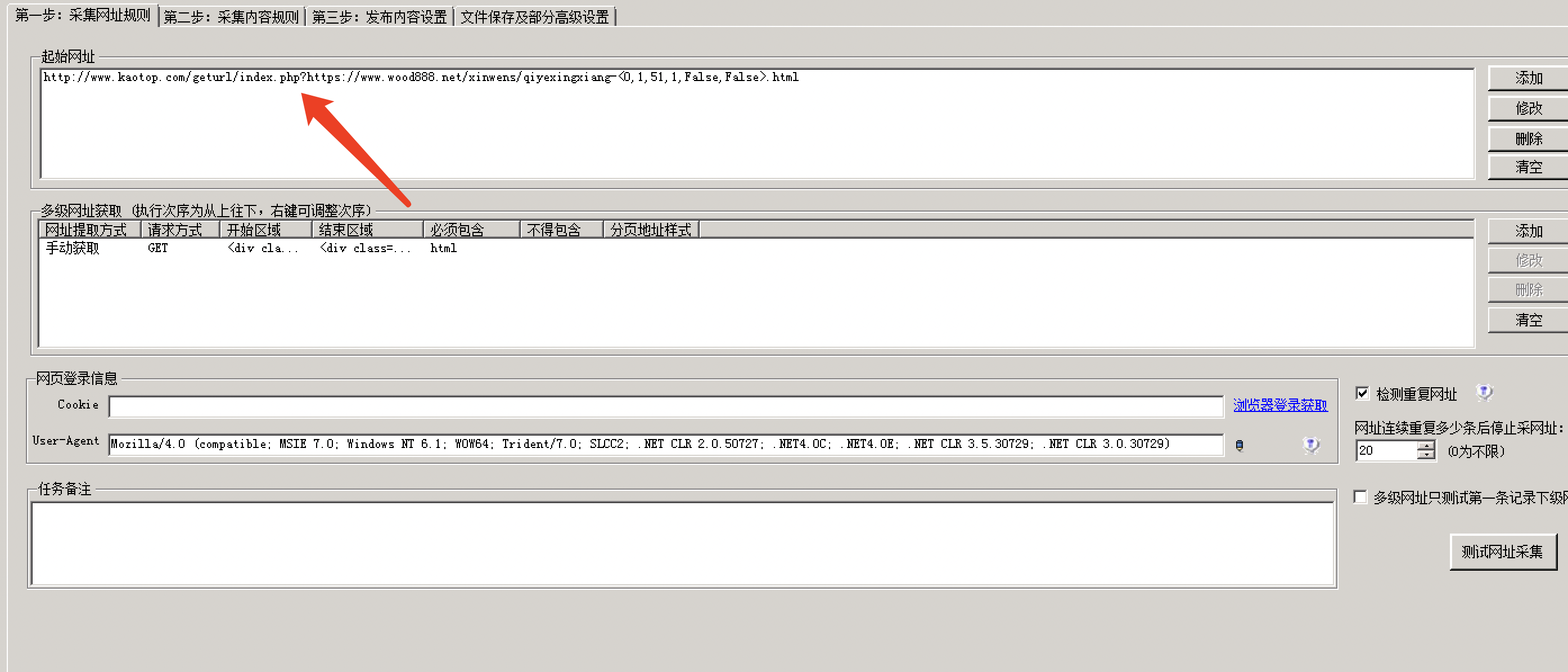
在接口后面/geturl/index.php?https://www.wood888.net/xinwens/qiyexingxiang-2.html
例如获取数据:/geturl/index.php?https://www.wood888.net/xinwens/qiyexingxiang-2.html
获取内容页面就是通过火车头手动提取设置,把链接加入接口提取出来
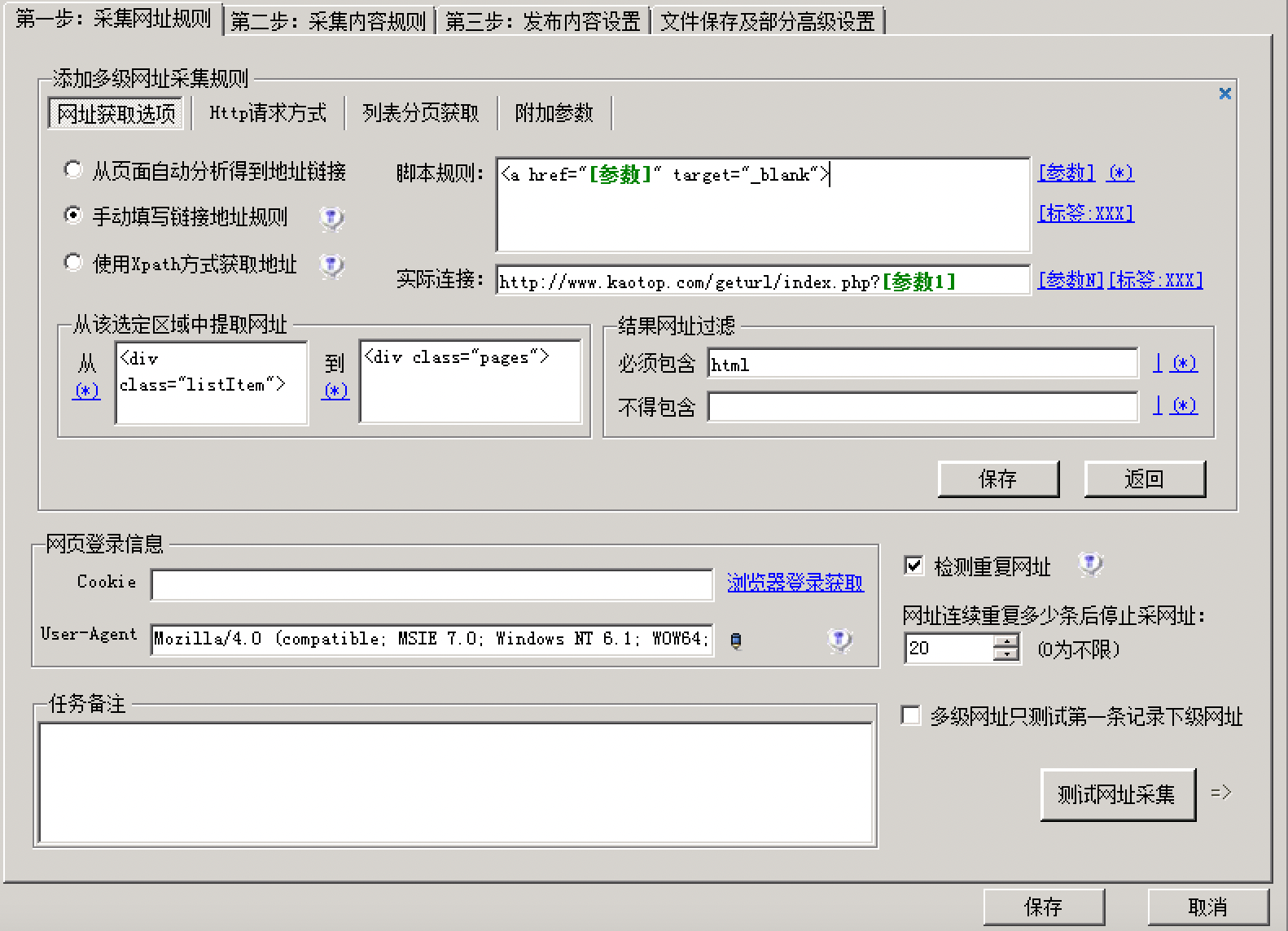
这样就能获取文章了
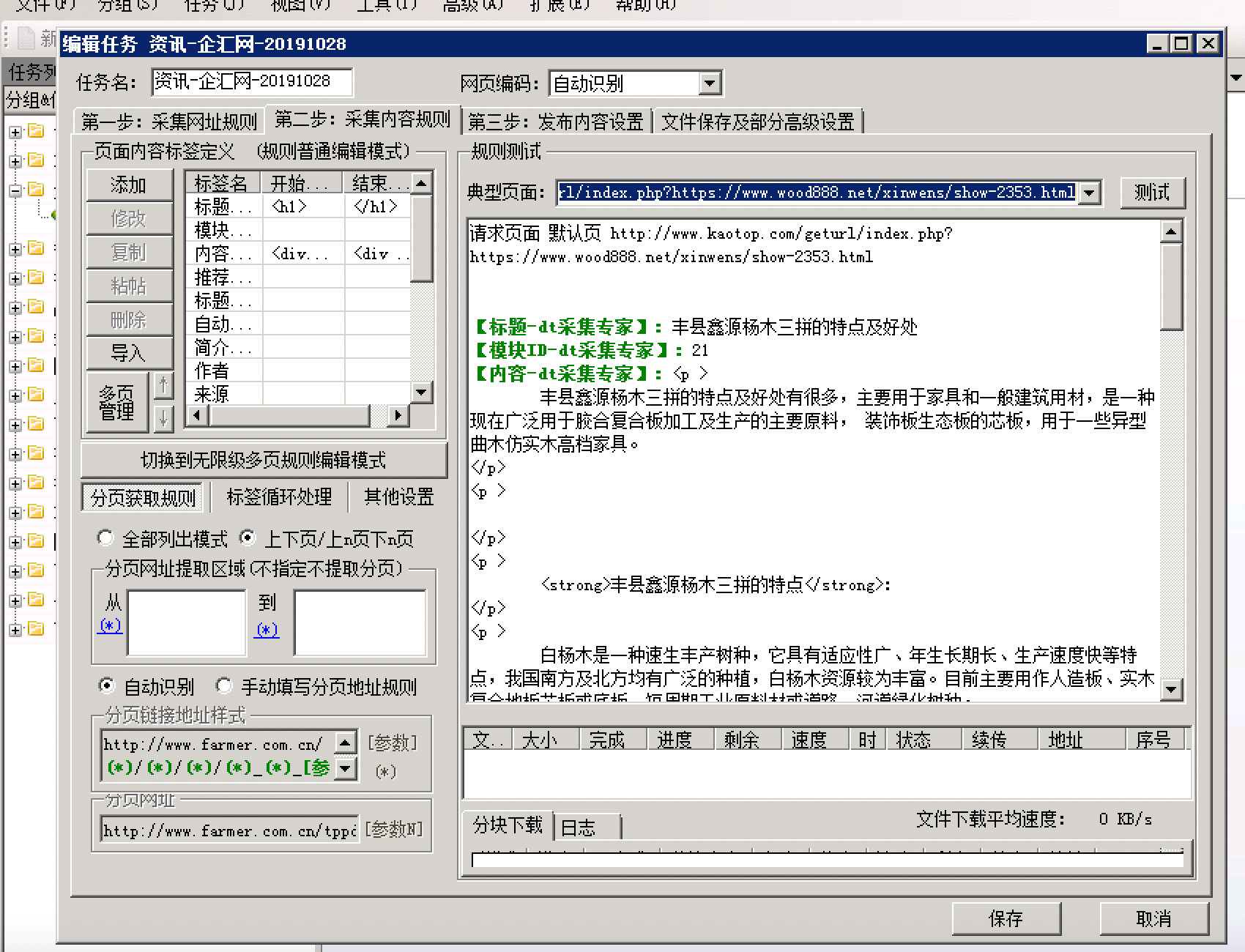
好了,这样就完美解决了
插件下载地址:http://www.68xi.com/591.html
千行代码,Bug何处藏。 纵使上线又怎样,朝令改,夕断肠。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号