C++的常用输入及其优化以及注意事项

$\mathcal{P.S:}$ 对于输入方式及其优化有了解的大佬可直接阅读$\mathcal{Part}$ $\mathcal{2}$
特别鸣谢:@归斋
目录:
$\mathcal{Part}$ $\mathcal{1}$
读入方式们的万年争斗
$\mathcal{Part}$ $\mathcal{2}$
读入不谨慎,爆$\mathcal{0}$两行泪
$\mathcal{Part}$ $\mathcal{1}$ 读入方式们的万年争斗
有一些$\mathcal{OIer}$很喜欢用$\mathcal{cin}$,多方便啊,多好打啊,不像$\mathcal{scanf}$和$\mathcal{printf}$,打那么多%、$\mathcal{""}$、$\mathcal{()}$
这是事实,我在调试程序时用$\mathcal{cin}$和$\mathcal{cout}$也比较多
但是$\mathcal{cin}$和$\mathcal{cout}$也有缺点:
$\mathcal{1}$.格式
比如当你想输出格式$\mathcal{f[a][b]=f[c]+f[d]}$时,用$\mathcal{cout}$就是:
cout<<"f["<<a<<"]["<<b<<"]=f["<<c<<"]+f["<<d<<"]"<<endl;
而用$\mathcal{printf}$的话:
printf("f[%d][%d]=f[%d]+f[%d]",a,b,c,d);
多简洁啊,而且也不易混淆
所以:在输出较为复杂的格式时建议用$\mathcal{printf}$
$\mathcal{2}$.速度
速度可是一个大问题,因为$\mathcal{cin}$和$\mathcal{cout}$的速度可是比$\mathcal{scanf}$和$\mathcal{printf}$慢的
接下来我们测试一下它们的速度:
$\mathcal{1.}$ 输入$\mathcal{10}$万个数字:
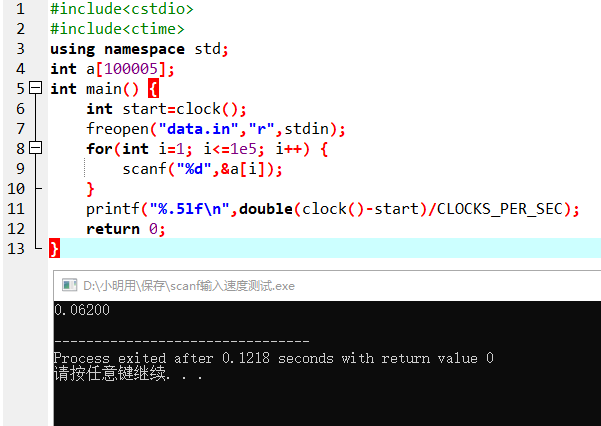
两者的差异为$\mathcal{0.031s}$,即$\mathcal{31ms}$.这时$\mathcal{cin}$离$\mathcal{scanf}$就有点远了,那么如果数据更大呢?
$\mathcal{2.}$输入$\mathcal{1000}$万个数字:

$\mathcal{scanf}$的输入速度
$\mathcal{cin}$的输入速度
可以看出两者的差距从$\mathcal{0.031s}$暴涨成$\mathcal{2.58s}$,即$\mathcal{2580ms}$。这个距离就很大啦。
所以说平时做题时,我们一般都用$\mathcal{scanf}$输入而不用$\mathcal{cin}$,因为$\mathcal{cin}$实在太慢啦。
那么$\mathcal{cin}$党是不是就此解散了呢?不不不。首先我们要知道$\mathcal{cin}$为什么这么慢呢?
那是因为$\mathcal{cin}$与$\mathcal{stdin}$有兼容性,也就是说$\mathcal{cin}$与$\mathcal{cin}$总是保持同步,可以放心地混用。
但是这样$\mathcal{cin}$就要背一个$\mathcal{stdin}$啊,当然就比$\mathcal{scanf}$慢咯。所以这是不公平竞争。
为了让$\mathcal{cin}$与$\mathcal{scanf}$公平竞赛,我们当然就应该让$\mathcal{cin}$放下身上的包裹与$\mathcal{scanf}$赛跑。
于是就用到了这句:
ios::sync_with_stdio(false);
这一句的作用是关闭$\mathcal{cin}$与$\mathcal{stdin}$的同步。加上这一句之后$\mathcal{cin}$的速度就可以接近$\mathcal{scanf}$啦
但是,在上面的测试中,$\mathcal{scanf}$竟然不如加了优化的$\mathcal{cin}$!!
这是因为$\mathcal{scanf}$和$\mathcal{cin}$不是那么稳定,毕竟在大多数题中$\mathcal{scanf}$还是比优化后的$\mathcal{cin}$快的
所以这个时候就要手写输入输出啦!
赠送快读快写代码一份~(感谢$\mathcal{}$大佬提供的代码)
inline int read (){//快读
int X = 0,w = 0; char ch = 0;
while(!isdigit(ch)) {w |= ch == '-', ch = getchar();}
while(isdigit(ch)) X = (X << 3) + (X << 1) + (ch ^ 48), ch = getchar();
return w?-X:X;
}
inline void write (int x){//快写
if (x < 0) putchar('-'), x = -x;
if (x > 9) write(x / 10);
putchar(x % 10 + '0');
}
快读的另一个优点就是它可以自动过滤掉多余的字符,这也导致它的缺点就是不能读那种需要读入字符的题...
比如$\mathcal{UVA1292}$一题就可以用快读过滤掉括号,而不用再用$\mathcal{scanf}$过滤了
所以,以后在写读入时,千万不可只写一个$\mathcal{cin}$咯~(至少也得加个优化吧)
$\mathcal{Part}$ $\mathcal{2}$ 读入不谨慎,爆$\mathcal{0}$两行泪
你以为掌握了$\mathcal{Part}$ $\mathcal{1}$你加天下无敌了?$\mathcal{No}$,读入这一块还是有很多坑的~(对于某些大佬来说,的确是天下无敌(比如说@小竹生 @$\mathcal{qingsan}$)...)
$\mathcal{1.}$ 字符读入$\mathcal{--}$讨论$\mathcal{cin}$与$\mathcal{scanf}$
字符的读入对于经验少的$\mathcal{OIer}$来说自古以来都是一个毒瘤之地。
如果你不注意字符读入中的一些坑,那么即使你的算法如何正确,
读入照常把你卡到$\mathcal{0}$分$\mathcal{...}$所以我们首先就来讨论如何处理字符读入的空格吧。
处理方法$\mathcal{1:getchar()+scanf("}$%$\mathcal{c",}$&$\mathcal{x);}$
$\mathcal{getchar}$就是用来吃那该死的空格的和换行的,具体情况具体使用
比如下面这个输入:
5 a a a a a b b b b b c c c c c d d d d d e e e e e
那么可以用:
for(int i=1; i<=n; i++) {
for(int j=1; j<=n; j++) {
scanf("%c",&a[i][j]);
getchar();
}
}
这里的$\mathcal{getchar}$就是用来吃掉每一个每一个字符后面的空格的。
但是一旦数据搞事$\mathcal{...}$比如说在每一行后面再加一个空格,那么恭喜你,你的程序把换行给吃进去了
然后就是一调试就是各种神奇的答案...
$\mathcal{getchar}$的缺点就是只吃一个,肚子太小,极易出错。那么怎么办呢?
$\mathcal{2. cin>>...}$ 或 $\mathcal{scanf}$
相信$\mathcal{cin}$是大多数$\mathcal{OIer}$的选择了。
因为用$\mathcal{cin}$读入空格时,遇到空格就会自动停止输入,这样一定程度上就保证了读入时不会读入什么空格换行之类的了。
至于$\mathcal{cin}$的速度,加上那个优化就对了呗。
至于再用$\mathcal{scanf}$?或许你看到这里会觉得很奇怪,刚刚不是才说了$\mathcal{scanf}$会被空格卡吗?
是的,但是对$\mathcal{scanf}$加一点东西它也可以和$\mathcal{cin}$一样对空格免疫:
改进版$\mathcal{scanf}$输入:$\mathcal{scanf("}$ %$\mathcal{c",}$&$\mathcal{x);}$
没错,就是在%$\mathcal{c}$之前加一个空格。这样的$\mathcal{scanf}$和$\mathcal{cin}$一样,对于无论多长的空格和换行都免疫。
2.一种坑有点大的读入 [$\mathcal{SDOI2006}$]保安站岗
读题。嗯,先读入节点编号,再读入当前节点经费,再读入子节点数,再读入对应的子节点。
于是写了这个:
scanf("%d%d%d", &x, &money[x], &m);
for (int i = 1; i <= m; i++) {
scanf("%d", &y);
son[x].push_back(y);
}
然后跑一下样例,发现答案不对,然后又在算法部分查错,死活查不出来,最后生无可恋,砸掉电脑(程序员日常生活$\mathcal{ing}$)。
这种情况最好要检查一下输入啊~输入是基础啊~(╯‵□′)╯︵┻━┻
在每一次读入时都输出$\mathcal{money[x]}$,发现输出都是$\mathcal{money[x]}$那么说明问题就出在$\mathcal{money}$数组的输入。
让我们来想象一个过程:程序把你的这几个输入同时存入,你的第一个数据正在存入$\mathcal{money}$的过程中,你的第二个数据也正在存入$\mathcal{money[x]}$的过程中。第二个数据要存入$\mathcal{money[x]}$,就必须找到对应的$\mathcal{x}$。
按理来说,第一个数据才是第二个数据所对应的$\mathcal{x}$,但是第一个数据还没有存完,第二个数据又必须找到对应的$\mathcal{x}$
于是它只有找上一次的$\mathcal{x}$作为指针,于是就存到上一次的$\mathcal{x}$所对应的值里去了。
不信的话在这个输入后加一个$\mathcal{printf("}$%$\mathcal{d", money[x-1])}$,那么输出肯定就对上输入数据了。
对于这个题来说,实际上可以用
scanf("%d%d%d", &x, &money[i], &m);
但是如果有的题强制你先输入$\mathcal{x}$,再输入$\mathcal{..[x]}$之类的,就没办法啦╮(╯▽╰)╭
$\mathcal{3.}$其他注意事项
有的大佬在有字符读入的题中,喜欢用$\mathcal{scanf}$读入数字,然后用$\mathcal{cin}$读入字符
这样也的确可以,但是有风险!!因为$\mathcal{scanf}$和$\mathcal{cin}$可就没有流同步啦~所以如果混用会有一定的风险。
比如本人在做骑士精神那道题时,就因为混用而出现了玄学$\mathcal{bug}$,成功地爆$\mathcal{0}$了~
-----------------------------------------------------------------------------------------------
总结:输入方面是许多人很少注意的地方,当你检查程序时,个人建议先检查输入输出。(虽然我从来没有这么做过)
如果本文有任何错误或者可以补充的地方,欢迎在下方评论区提出~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号