


爬虫综合大作业——网易云音乐《Five Hours》爬虫&可视化分析
作业要求来自于https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/3075
爬虫综合大作业
- 选择一个热点或者你感兴趣的主题。
- 选择爬取的对象与范围。
- 了解爬取对象的限制与约束。
- 爬取相应内容。
- 做数据分析与文本分析。
- 形成一篇文章,有说明、技术要点、有数据、有数据分析图形化展示与说明、文本分析图形化展示与说明。
- 文章公开发布。
1. 数据爬取
我们本次爬取的对象是一首名为《five hours》的经典电音流行歌曲,Five Hours是Erick Orrosquieta于2014年4月发行的单曲,当年这首单曲就出现在奥地利,比利时,法国,荷兰,挪威,瑞典和瑞士的榜单中。
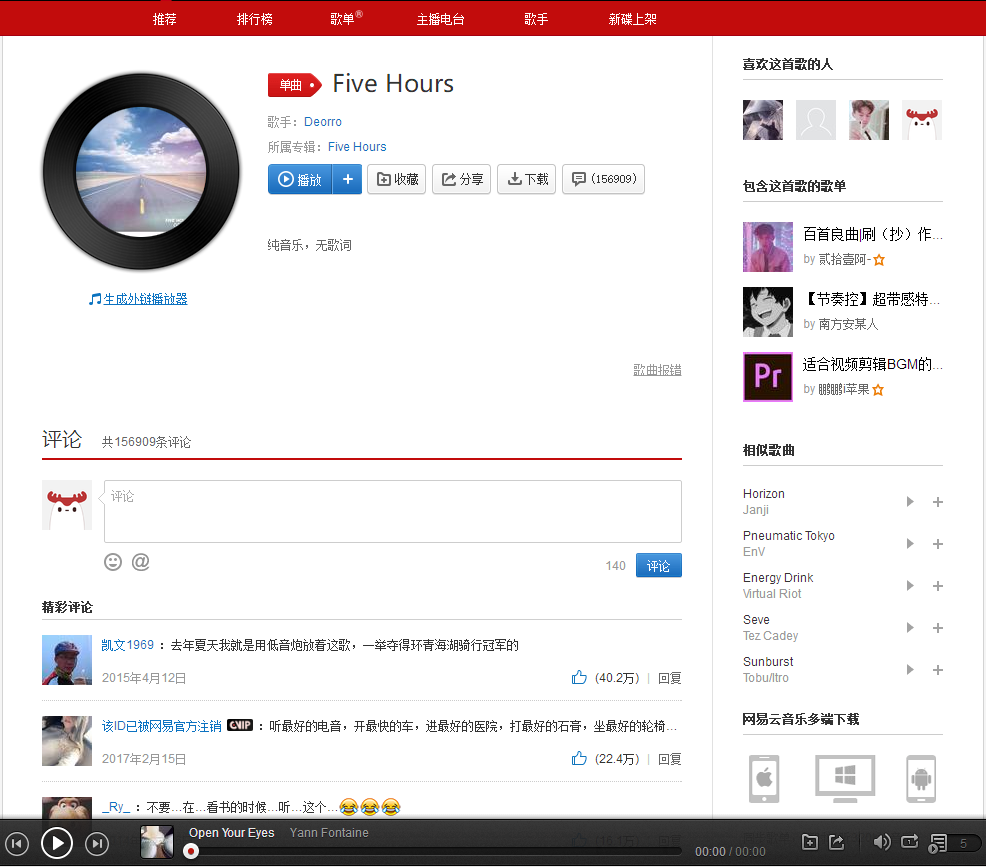
而在爬虫部分主要是调用官方API,本次用到的API主要有两个:
①获取评论:
http://music.163.com/api/v1/resource/comments/R_SO_4_{歌曲ID}?limit={每页限制数量}&offset={评论数总偏移}
②获取评论对应用户的信息:
https://music.163.com/api/v1/user/detail/{用户ID}
完成后的项目文件图如下:
1.1 评论爬取
具体代码如下:
1 from urllib import request 2 import json 3 import pymysql 4 from datetime import datetime 5 import re 6 7 ROOT_URL = 'http://music.163.com/api/v1/resource/comments/R_SO_4_%s?limit=%s&offset=%s' 8 LIMIT_NUMS = 50 # 每页限制爬取数 9 DATABASE = 'emp' # 数据库名 10 TABLE = 'temp1' # 数据库表名 11 # 数据表设计如下: 12 ''' 13 commentId(varchar) 14 content(text) likedCount(int) 15 userId(varchar) time(datetime) 16 ''' 17 PATTERN = re.compile(r'[\n\t\r\/]') # 替换掉评论中的特殊字符以防插入数据库时报错 18 19 def getData(url): 20 if not url: 21 return None, None 22 headers = { 23 "User-Agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.80 Safari/537.36', 24 "Host": "music.163.com", 25 } 26 print('Crawling>>> ' + url) 27 try: 28 req = request.Request(url, headers=headers) 29 content = request.urlopen(req).read().decode("utf-8") 30 js = json.loads(content) 31 total = int(js['total']) 32 datas = [] 33 for c in js['comments']: 34 data = dict() 35 data['commentId'] = c['commentId'] 36 data['content'] = PATTERN.sub('', c['content']) 37 data['time'] = datetime.fromtimestamp(c['time']//1000) 38 data['likedCount'] = c['likedCount'] 39 data['userId'] = c['user']['userId'] 40 datas.append(data) 41 return total, datas 42 except Exception as e: 43 print('Down err>>> ', e) 44 pass 45 46 def saveData(data): 47 if not data: 48 return None 49 conn = pymysql.connect(host='localhost', user='root', passwd='123456', db='emp', charset='utf8mb4') # 注意字符集要设为utf8mb4,以支持存储评论中的emoji表情 50 cursor = conn.cursor() 51 sql = 'insert into ' + TABLE + ' (commentId,content,likedCount,time,userId) VALUES (%s,%s,%s,%s,%s)' 52 53 for d in data: 54 55 try: 56 #cursor.execute('SELECT max(c) FROM '+TABLE) 57 #id_ = cursor.fetchone()[0] 58 59 cursor.execute(sql, (d['commentId'], d['content'], d['likedCount'], d['time'], d['userId'])) 60 conn.commit() 61 except Exception as e: 62 print('mysql err>>> ',d['commentId'],e) 63 pass 64 65 cursor.close() 66 conn.close() 67 68 if __name__ == '__main__': 69 songId = input('歌曲ID:').strip() 70 total,data = getData(ROOT_URL%(songId, LIMIT_NUMS, 0)) 71 saveData(data) 72 if total: 73 for i in range(1, total//50+1): 74 _, data = getData(ROOT_URL%(songId, LIMIT_NUMS, i*(LIMIT_NUMS))) 75 saveData(data)
实际操作过程中,网易云官方对于API的请求是有限制的,有条件的可以采用更换代理IP来防反爬,而这一次作业在爬取数据的时候由于前期操作过度,导致被BAN IP,数据无法获取,之后是通过挂载虚拟IP才实现数据爬取的。

本次采用的是单线程爬取,所以IP封的并不太频繁,后面会对代码进行重构,实现多线程+更换IP来加快爬取速度。
根据获取评论的API,请求URL有3个可变部分:每页限制数limit和评论总偏移量offset,通过API分析得知:当offeset=0时,返回json数据中包含有评论总数量total。
本次共爬取5394条数据(避免盲目多爬被封ID)

1.2 用户信息爬取
具体代码如下:
1 from urllib import request 2 import json 3 import pymysql 4 import re 5 6 ROOT_URL = 'https://music.163.com/api/v1/user/detail/' 7 DATABASE = 'emp' 8 TABLE_USERS = 'temp2' 9 TABLE_COMMENTS = 'temp1' 10 # 数据表设计如下: 11 ''' 12 id(int) userId(varchar) 13 gender(char) userName(varchar) 14 age(int) level(int) 15 city(varchar) sign(text) 16 eventCount(int) followedCount(int) 17 followsCount(int) recordCount(int) 18 avatar(varchar) 19 ''' 20 PATTERN = re.compile(r'[\n\t\r\/]') # 替换掉签名中的特殊字符以防插入数据库时报错 21 headers = { 22 "User-Agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.80 Safari/537.36', 23 "Host": "music.163.com", 24 } 25 def getData(url): 26 if not url: 27 return None 28 print('Crawling>>> ' + url) 29 try: 30 req = request.Request(url, headers=headers) 31 content = request.urlopen(req).read().decode("utf-8") 32 js = json.loads(content) 33 data = {} 34 if js['code'] == 200: 35 data['userId'] = js['profile']['userId'] 36 data['userName'] = js['profile']['nickname'] 37 data['avatar'] = js['profile']['avatarUrl'] 38 data['gender'] = js['profile']['gender'] 39 if int(js['profile']['birthday'])<0: 40 data['age'] = 0 41 else: 42 data['age'] =(2018-1970)-(int(js['profile']['birthday'])//(1000*365*24*3600)) 43 if int(data['age'])<0: 44 data['age'] = 0 45 data['level'] = js['level'] 46 data['sign'] = PATTERN.sub(' ', js['profile']['signature']) 47 data['eventCount'] = js['profile']['eventCount'] 48 data['followsCount'] = js['profile']['follows'] 49 data['followedCount'] = js['profile']['followeds'] 50 data['city'] = js['profile']['city'] 51 data['recordCount'] = js['listenSongs'] 52 53 saveData(data) 54 except Exception as e: 55 print('Down err>>> ', e) 56 pass 57 return None 58 59 def saveData(data): 60 if not data: 61 return None 62 conn = pymysql.connect(host='localhost', user='root', passwd='123456', db='emp', charset='utf8mb4') # 注意字符集要设为utf8mb4,以支持存储签名中的emoji表情 63 cursor = conn.cursor() 64 sql = 'insert into ' + TABLE_USERS + ' (userName,gender,age,level,city,sign,eventCount,followsCount,followedCount,recordCount,avatar,userId) VALUES (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)' 65 try: 66 67 68 cursor.execute(sql, (data['userName'],data['gender'],data['age'],data['level'],data['city'],data['sign'],data['eventCount'],data['followsCount'],data['followedCount'],data['recordCount'],data['avatar'],data['userId'])) 69 conn.commit() 70 except Exception as e: 71 print('mysql err>>> ',data['userId'],e) 72 pass 73 finally: 74 cursor.close() 75 conn.close() 76 77 def getID(): 78 conn = pymysql.connect(host='localhost', user='root', passwd='123456', db='emp', charset='utf8mb4') 79 cursor = conn.cursor() 80 sql = 'SELECT userId FROM '+TABLE_COMMENTS 81 try: 82 cursor.execute(sql) 83 res = cursor.fetchall() 84 return res 85 except Exception as e: 86 print('get err>>> ', e) 87 pass 88 finally: 89 cursor.close() 90 conn.close() 91 return None 92 93 if __name__ == '__main__': 94 usersID = getID() 95 for i in usersID: 96 getData(ROOT_URL+i[0].strip()) 97
根据获取用户信息的API,请求URL有1个可变部分:用户ID,前一部分已经将每条评论对应的用户ID也存储下来,这里只需要从数据库取用户ID并抓取信息即可(对应以上的5394条数据)。
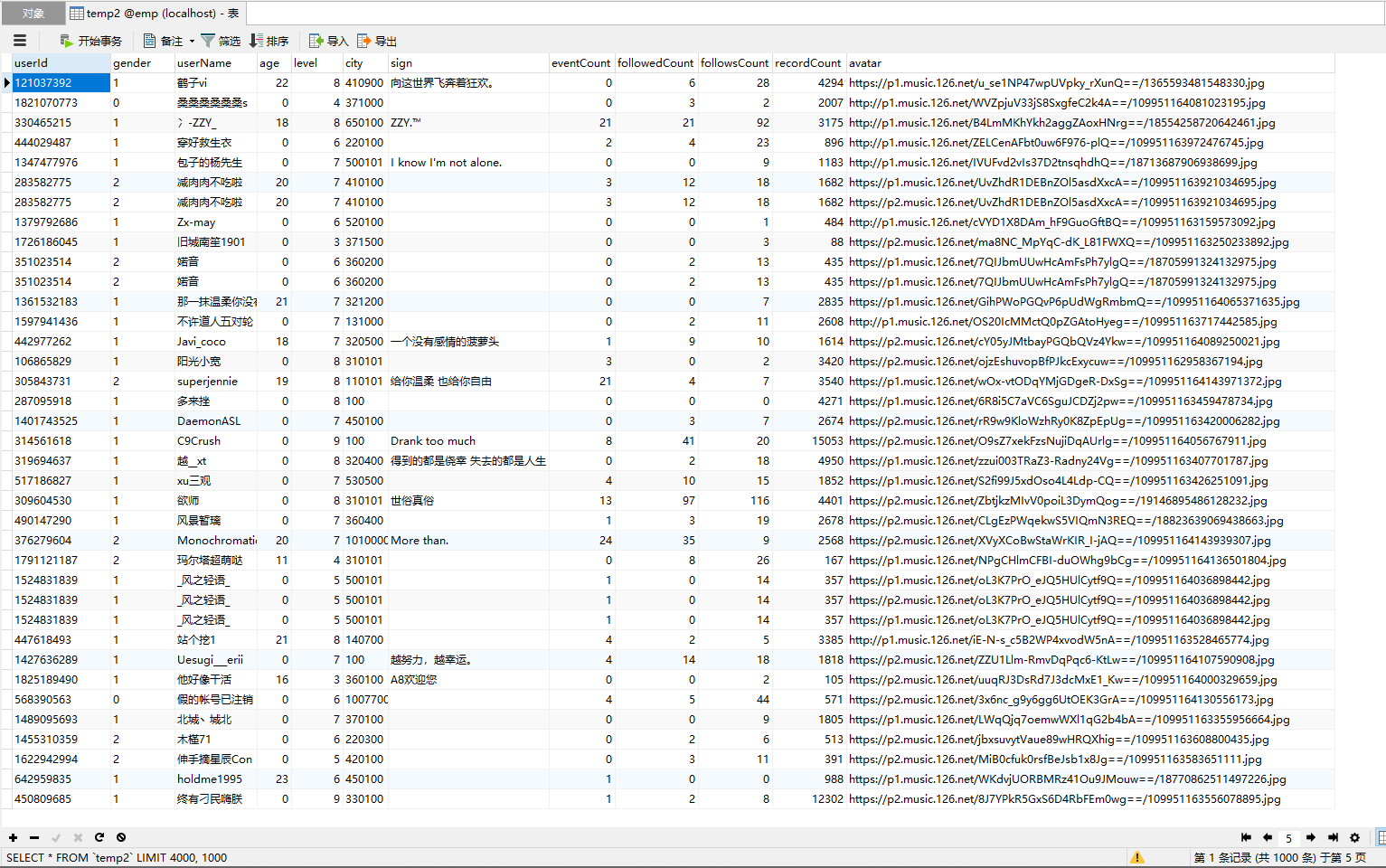
至此,已经完成了歌曲评论和对应用户信息的抓取。接下来,对抓取到的数据进行清洗及可视化分析。
2 数据清洗 & 可视化
处理代码如下:
1 import pandas as pd 2 import pymysql 3 from pyecharts import Bar,Pie,Line,Scatter,Map 4 5 TABLE_COMMENTS = 'temp1' 6 TABLE_USERS = 'temp2' 7 DATABASE = 'emp' 8 9 conn = pymysql.connect(host='localhost', user='root', passwd='123456', db='emp', charset='utf8mb4') 10 sql_users = 'SELECT id,gender,age,city FROM '+TABLE_USERS 11 sql_comments = 'SELECT id,time FROM '+TABLE_COMMENTS 12 comments = pd.read_sql(sql_comments, con=conn) 13 users = pd.read_sql(sql_users, con=conn) 14 15 # 评论时间(按天)分布分析 16 comments_day = comments['time'].dt.date 17 data = comments_day.id.groupby(comments_day['time']).count() 18 line = Line('评论时间(按天)分布') 19 line.use_theme('dark') 20 line.add( 21 '', 22 data.index.values, 23 data.values, 24 is_fill=True, 25 ) 26 line.render(r'./评论时间(按天)分布.html') 27 # 评论时间(按小时)分布分析 28 comments_hour = comments['time'].dt.hour 29 data = comments_hour.id.groupby(comments_hour['time']).count() 30 line = Line('评论时间(按小时)分布') 31 line.use_theme('dark') 32 line.add( 33 '', 34 data.index.values, 35 data.values, 36 is_fill=True, 37 ) 38 line.render(r'./评论时间(按小时)分布.html') 39 # 评论时间(按周)分布分析 40 comments_week = comments['time'].dt.dayofweek 41 data = comments_week.id.groupby(comments_week['time']).count() 42 line = Line('评论时间(按周)分布') 43 line.use_theme('dark') 44 line.add( 45 '', 46 data.index.values, 47 data.values, 48 is_fill=True, 49 ) 50 line.render(r'./评论时间(按周)分布.html') 51 52 # 用户年龄分布分析 53 age = users[users['age']>0] # 清洗掉年龄小于1的数据 54 age = age.id.groupby(age['age']).count() # 以年龄值对数据分组 55 Bar = Bar('用户年龄分布') 56 Bar.use_theme('dark') 57 Bar.add( 58 '', 59 age.index.values, 60 age.values, 61 is_fill=True, 62 ) 63 Bar.render(r'./用户年龄分布图.html') # 生成渲染的html文件 64 65 # 用户地区分布分析 66 # 城市code编码转换 67 def city_group(cityCode): 68 city_map = { 69 '11': '北京', 70 '12': '天津', 71 '31': '上海', 72 '50': '重庆', 73 '5e': '重庆', 74 '81': '香港', 75 '82': '澳门', 76 '13': '河北', 77 '14': '山西', 78 '15': '内蒙古', 79 '21': '辽宁', 80 '22': '吉林', 81 '23': '黑龙江', 82 '32': '江苏', 83 '33': '浙江', 84 '34': '安徽', 85 '35': '福建', 86 '36': '江西', 87 '37': '山东', 88 '41': '河南', 89 '42': '湖北', 90 '43': '湖南', 91 '44': '广东', 92 '45': '广西', 93 '46': '海南', 94 '51': '四川', 95 '52': '贵州', 96 '53': '云南', 97 '54': '西藏', 98 '61': '陕西', 99 '62': '甘肃', 100 '63': '青海', 101 '64': '宁夏', 102 '65': '新疆', 103 '71': '台湾', 104 '10': '其他', 105 } 106 return city_map[cityCode[:2]] 107 108 city = users['city'].apply(city_group) 109 city = city.id.groupby(city['city']).count() 110 map_ = Map('用户地区分布图') 111 map_.add( 112 '', 113 city.index.values, 114 city.values, 115 maptype='china', 116 is_visualmap=True, 117 visual_text_color='#000', 118 is_label_show=True, 119 ) 120 map_.render(r'./用户地区分布图.html')
关于数据的清洗,实际上在上一部分抓取数据的过程中已经做了一部分,包括:后台返回的空用户信息、重复数据的去重等。除此之外,还要进行一些清洗:用户年龄错误、用户城市编码转换等。
关于数据的去重,评论部分可以以sommentId为数据库索引,利用数据库来自动去重;用户信息部分以用户ID为数据库索引实现自动去重。
①API返回的用户年龄一般是时间戳的形式(以毫秒计)、有时候也会返回一个负值或者一个大于当前时间的值,暂时没有找到这两种值代表的含义,故而一律按0来处理。
②API返回的用户信息中,城市分为province和city两个字段,本此分析中只保存了city字段。实际上字段值是一个城市code码
③在这部分,利用Python的数据处理库pandas进行数据处理,利用可视化库pyecharts进行数据可视化。
以上,是对抓取到的数据采用可视化库pyecharts进行可视化分析,得到的结果如下:
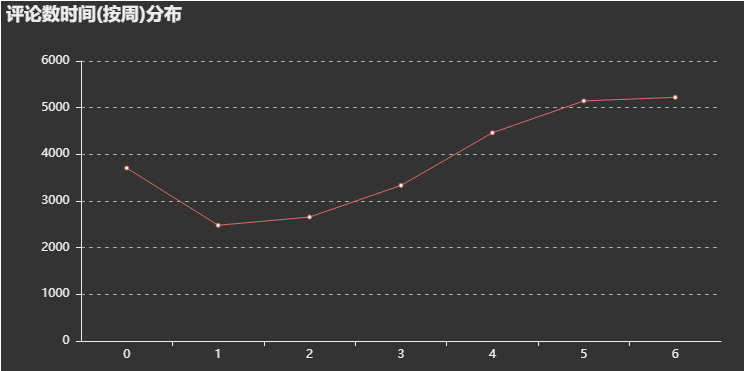
结论一:评论时间按周分布图可以看出,评论数在一周当中前面较少,后面逐渐增多,这可以解释为往后接近周末,大家有更多时间来听听歌、刷刷歌评,而一旦周末过完,评论量马上下降(周日到周一的下降过渡),大家又回归到工作当中。
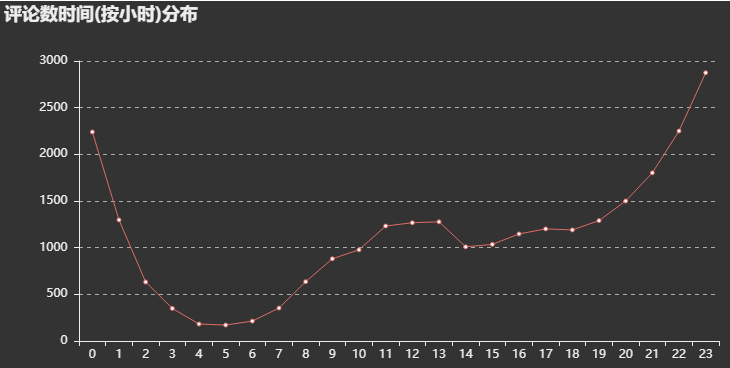
结论二:评论时间按小时分布图可以看出,评论数在一天当中有两个小高峰:11点-13点和22点-0点。这可以解释为用户在中午午饭时间和晚上下班(课)在家时间有更多的时间来听歌刷评论,符合用户的日常。至于为什么早上没有出现一个小高峰,大概是早上大家都在抢时间上班(学),没有多少时间去刷评论。

结论三:用户年龄分布图可以看出,用户大多集中在14-30岁之间,以20岁左右居多,除去虚假年龄之外,这个年龄分布也符合网易云用户的年龄段。图中可以看出28岁有个高峰,猜测可能是包含了一些异常数据,有兴趣的化可以做进一步分析。

结论四:用户地区分布图可以看出,用户涵盖了全国各大省份,因为中间数据(坑)的缺失,并没有展现出哪个省份特别突出的情况。对别的歌评(完全数据)的可视化分析,可以看出明显的地区分布差异。用户地区分布图可以看出,用户涵盖了全国各大省份,因为中间数据的缺失,并没有展现出哪个省份特别突出的情况。对别的歌评(完全数据)的可视化分析,可以看出明显的地区分布差异。
细心观察评论数(按天)分布那张图,发现2017年到2018年间有很大一部分数据缺失,这实际上是因为在数据抓取过程中出现的问题。研究了一下发现,根据获取歌曲评论的API,实际上每首歌最多只能获得2w条左右(去重后)的评论,对于评论数超过2w的歌曲,只能获得前后(日期)各1w条评论,而且这个限制对于网易云官网也是存在的,具体表现为:对一首评论数超过2w的歌,如果一直往后浏览评论,会发现从第500页(网页端网易云每页20条评论)往后,后台返回的内容和第500页完全一样,从后往前同理。这应该是官方后台做了限制,连自家也不放过。。。
此次分析只是对某一首歌曲评论时间、用户年龄/地区分布进行的,实际上抓取到的信息不仅仅在于此,可以做进一步分析(比如利用评论内容进行文本内容分析等),这部分,未来会进一步分析。当然也可以根据自己情况对不同歌曲进行分析。
3.歌评文本分析
评论的文本分析做了两部分:情感分析和词云生成。
情感分析采用Python的文本分析库snownlp。具体代码如下:
1 import numpy as np 2 import pymysql 3 from snownlp import SnowNLP 4 from pyecharts import Bar 5 6 TABLE_COMMENTS = 'temp1' 7 DATABASE = 'emp' 8 SONGNAME = 'five hours' 9 10 def getText(): 11 conn = pymysql.connect(host='localhost', user='root', passwd='123456', db=DATABASE, charset='utf8') 12 sql = 'SELECT id,content FROM '+TABLE_COMMENTS 13 text = pd.read_sql(sql%(SONGNAME), con=conn) 14 return text 15 16 def getSemi(text): 17 text['content'] = text['content'].apply(lambda x:round(SnowNLP(x).sentiments, 2)) 18 semiscore = text.id.groupby(text['content']).count() 19 bar = Bar('评论情感得分') 20 bar.use_theme('dark') 21 bar.add( 22 '', 23 y_axis = semiscore.values, 24 x_axis = semiscore.index.values, 25 is_fill=True, 26 ) 27 bar.render(r'情感得分分析.html') 28 29 text['content'] = text['content'].apply(lambda x:1 if x>0.5 else -1) 30 semilabel = text.id.groupby(text['content']).count() 31 bar = Bar('评论情感标签') 32 bar.use_theme('dark') 33 bar.add( 34 '', 35 y_axis = semilabel.values, 36 x_axis = semilabel.index.values, 37 is_fill=True, 38 ) 39 bar.render(r'情感标签分析.html')
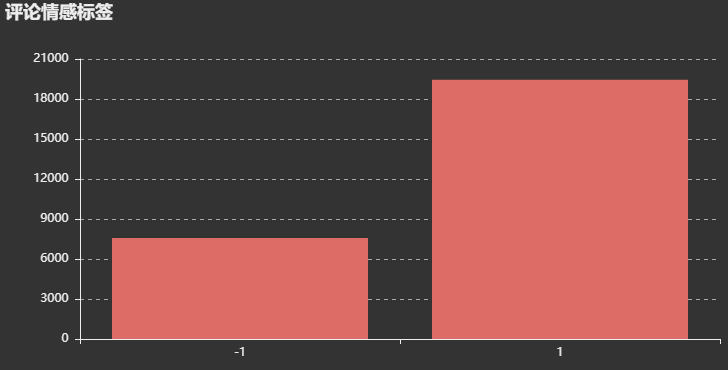
结果:

词云生成采用jieba分词库分词,wordcloud生成词云,具体代码如下:
1 from wordcloud import WordCloud 2 import matplotlib.pyplot as plt 3 plt.style.use('ggplot') 4 plt.rcParams['axes.unicode_minus'] = False 5 6 def getWordcloud(text): 7 text = ''.join(str(s) for s in text['content'] if s) 8 word_list = jieba.cut(text, cut_all=False) 9 stopwords = [line.strip() for line in open(r'./StopWords.txt', 'r').readlines()] # 导入停用词 10 clean_list = [seg for seg in word_list if seg not in stopwords] #去除停用词 11 clean_text = ''.join(clean_list) 12 # 生成词云 13 cloud = WordCloud( 14 font_path = r'C:/Windows/Fonts/msyh.ttc', 15 background_color = 'white', 16 max_words = 800, 17 max_font_size = 64 18 ) 19 word_cloud = cloud.generate(clean_text) 20 # 绘制词云 21 plt.figure(figsize=(12, 12)) 22 plt.imshow(word_cloud) 23 plt.axis('off') 24 plt.show() 25 26 if __name__ == '__main__': 27 text = getText() 28 getSemi(text) 29 getWordcloud(text)
词云:


