
起点中文网各榜单前20书籍爬虫系统
起点中文网各榜单前20书籍爬虫系统
一 选题背景
随着网络小说的兴起,越来越多人沉迷其中,好的小说让人增长见闻,读之快乐无比
然而小说之多,要找一本好的小说却是难上加难,基于此,我建立了本课题
爬取的9个榜单url
https://www.qidian.com/rank/yuepiao/','https://www.qidian.com/rank/hotsales/','https://www.qidian.com/rank/readindex/','https://www.qidian.com/rank/newfans/','https://www.qidian.com/rank/recom/','https://www.qidian.com/rank/collect/','https://www.qidian.com/rank/vipup/','https://www.qidian.com/rank/vipcollect/','https://www.qidian.com/rank/vipreward/'
二 设计方案
1.主题式网络爬虫名称
起点中文网主榜单前20书籍爬虫系统
2.主题式网络爬虫爬取内容与数据特征分析
对各榜单前20书籍的书名,名次,作者等进行爬取
并做分析
3·主题式爬虫设计方案概述(包括实现思路与技术难点)
1.通过开发者模式查看网页结构与所需爬取的东西所在的位置
2.通过简单的input函数做一个选择界面
3.存储数据:利用open(),WRITE()等等
三.实现步骤及代码
1.爬虫设计
(1)主题页面结构特征与特征分析
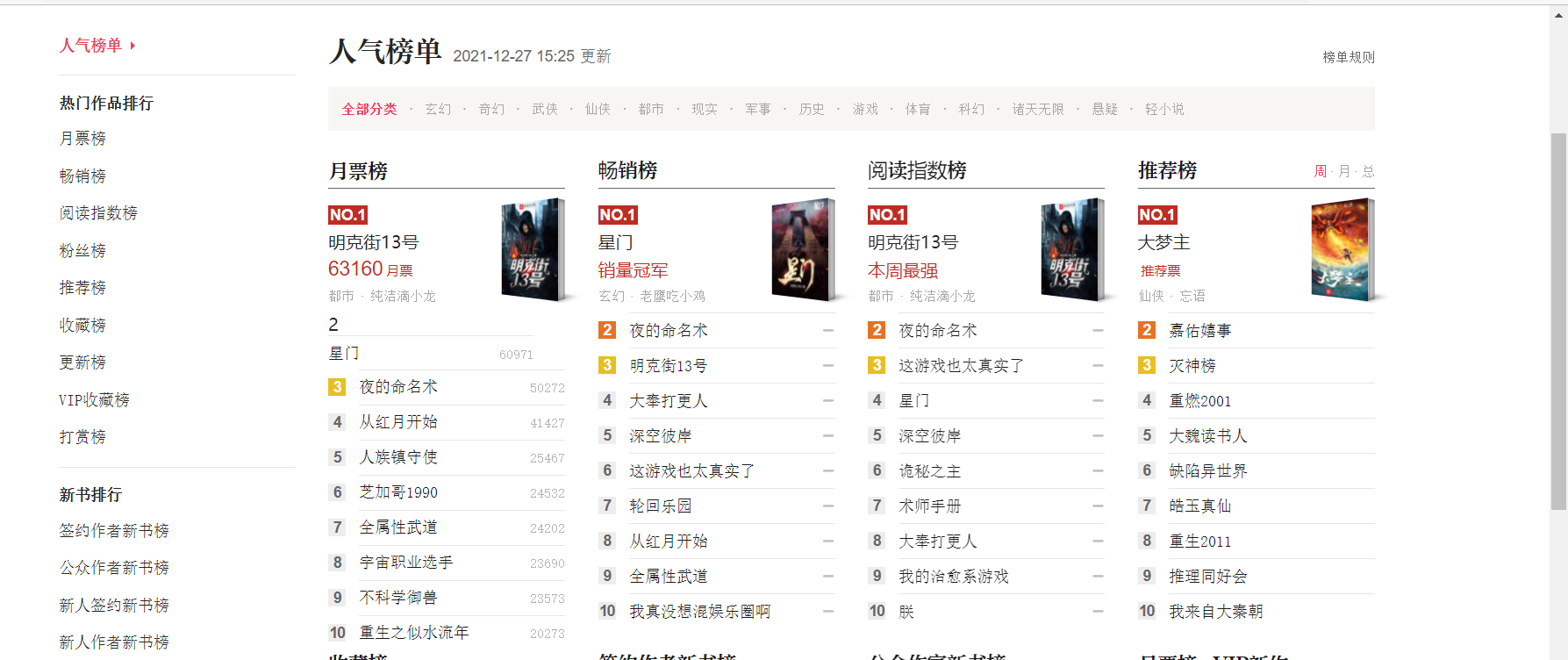
(2)html页面解析
书名:
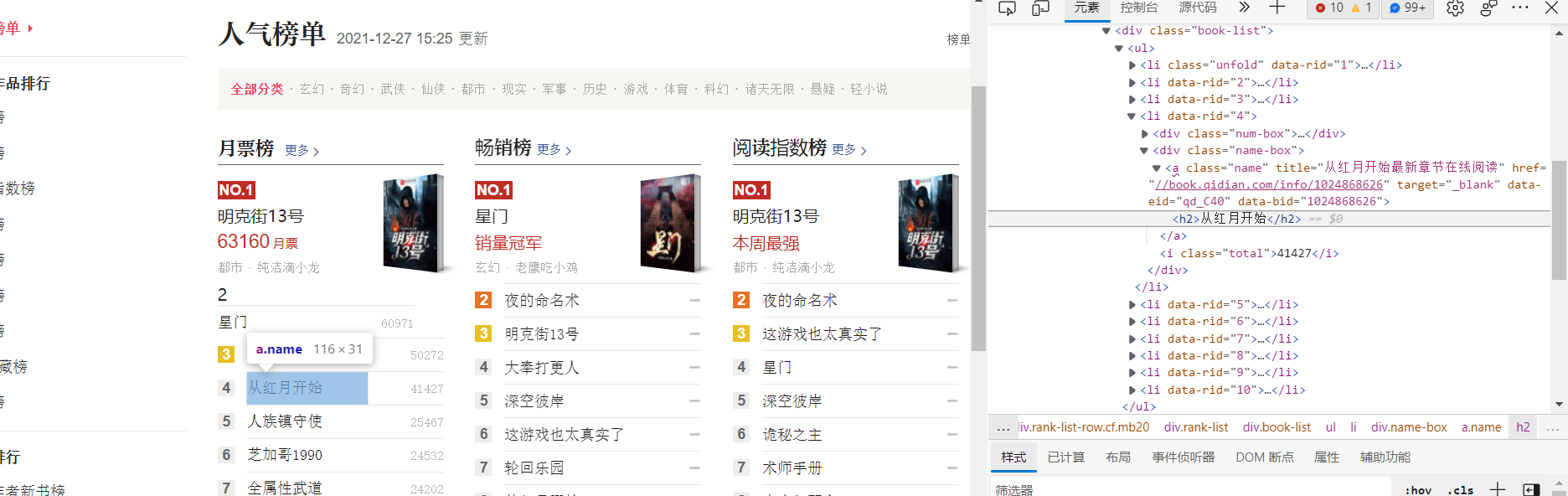
类型:
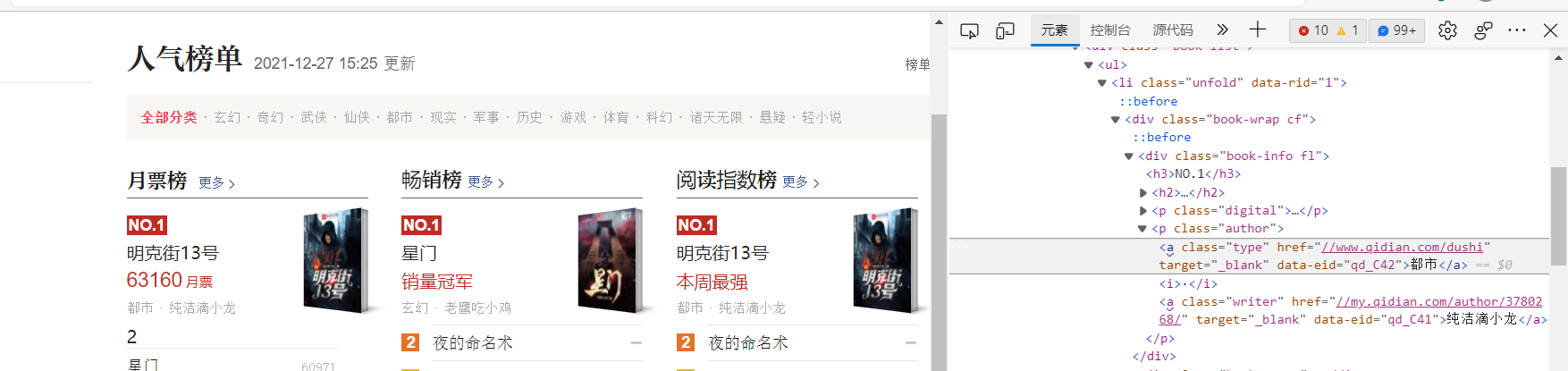
作者:
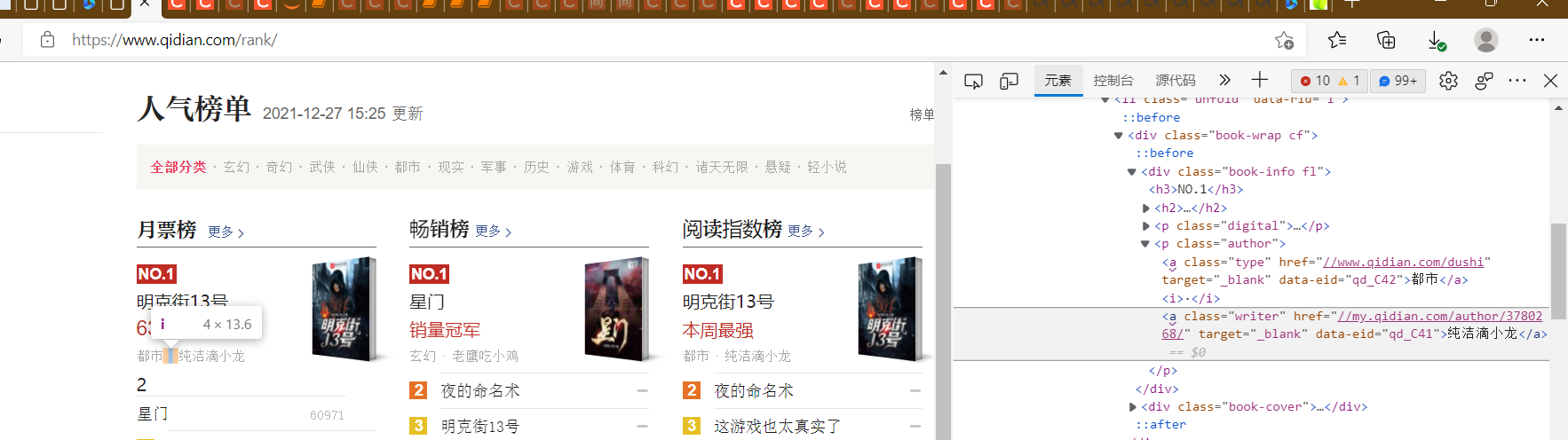
排名:

(3)节点查找方法与遍历
from bs4 import BeautifulSoup import pandas as pd import numpy import re import requests import xlwt import csv urllist=['https://www.qidian.com/rank/yuepiao/','https://www.qidian.com/rank/hotsales/','https://www.qidian.com/rank/readindex/','https://www.qidian.com/rank/newfans/','https://www.qidian.com/rank/recom/','https://www.qidian.com/rank/collect/','https://www.qidian.com/rank/vipup/','https://www.qidian.com/rank/vipcollect/','https://www.qidian.com/rank/vipreward/'] choice=int(input('请选择你想查看的榜单:1,月票榜 2,畅销榜 3,阅读指数榜 4,粉丝榜 5,推荐榜 6,收藏榜,7,更新榜8,VIP收藏榜9,打赏榜:')) url=urllist[choice-1] r=requests.get(url,timeout=30,) r.raise_for_status() r.encoding='utf_8' html=r.text soup=BeautifulSoup(html,'html.parser') body=soup.body data=body.find('div',{'class':'rank-body'}) 书名=data.find_all('div')[1].find_all("h2") 简介=data.find_all('div')[1].find_all('p',{'class':'intro'}) 更新=data.find_all('div')[1].find_all('p',{'class':'update'}) i=0 for i in range(len(书名)): print(书名[i].text) print(简介[i].text) print(更新[i].text)
(4)运行展示

2.数据持久化及演示
from bs4 import BeautifulSoup import pandas as pd import numpy import re import requests import xlwt import csv f = open("总数据.csv",mode="w",encoding="utf-8",newline='') csvwriter = csv.writer(f)v
def savedata(url): r=requests.get(url,timeout=30,) r.raise_for_status() r.encoding='utf_8' html=r.text soup=BeautifulSoup(html,'html.parser') body=soup.body data=body.find('div',{'class':'rank-body'}) 书名=data.find_all('div')[1].find_all("h2") 简介=data.find_all('div')[1].find_all('p',{'class':'intro'}) 更新=data.find_all('div')[1].find_all('p',{'class':'update'}) 类型=data.find_all('div')[1].find_all('a',{'data-eid':'qd_C42'}) for i in range(len(书名)): 名次=i+1 csvwriter.writerow([书名[i].text,简介[i].text,更新[i].text,类型[i].text,名次])
def main(): urllist=['https://www.qidian.com/rank/yuepiao/','https://www.qidian.com/rank/hotsales/','https://www.qidian.com/rank/readindex/','https://www.qidian.com/rank/newfans/','https://www.qidian.com/rank/recom/','https://www.qidian.com/rank/collect/','https://www.qidian.com/rank/vipup/','https://www.qidian.com/rank/vipcollect/','https://www.qidian.com/rank/vipreward/'] for i in range(0,9): url=urllist[i] savedata(url)
if __name__ == '__main__': main() f.close()
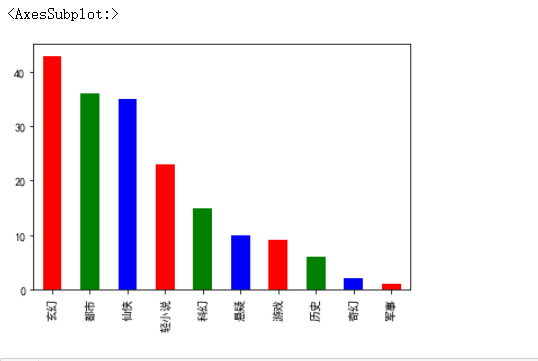
3.数据可视化
import matplotlib.pyplot as plt plt.rcParams['font.sans-serif'] = ['SimHei'] plt.rcParams['axes.unicode_minus'] = False df=pd.read_csv('D:/总数据表格一.csv',header=None,names=['书名','简介','更新','类型','名次']) t=df['类型'].value_counts() #输出一个柱状图 t.plot(kind='bar',color=['r','g','b'])
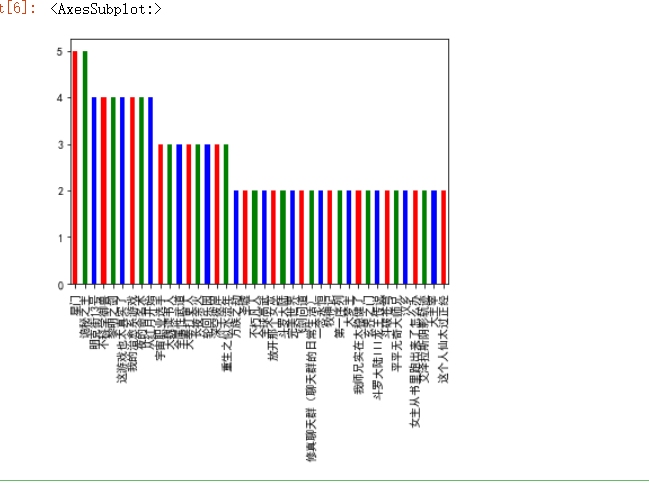
#做出一个该书在9个榜单出现的次数的柱状图 import matplotlib.pyplot as plt plt.rcParams['font.sans-serif'] = ['SimHei'] plt.rcParams['axes.unicode_minus'] = False h=df['书名'].value_counts() h.plot(kind='bar',color=['r','g','b'])
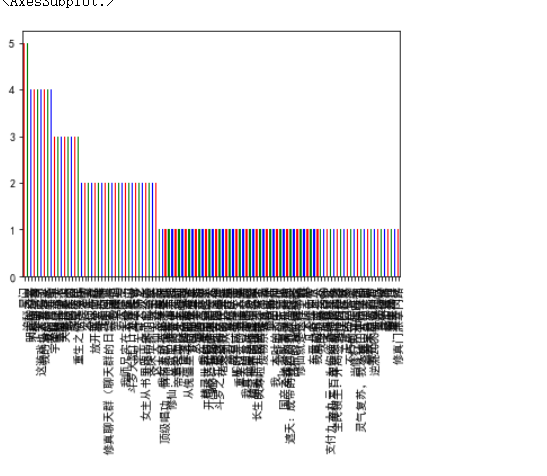
#因为书籍太多,看不清楚,这边用前40再做一图 h1=h.head(40) h1.plot(kind='bar',color=['r','g','b'])
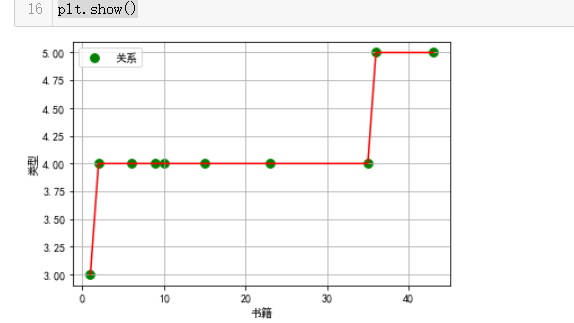
#输出书籍出现次数与其类型出现次数的更新 import pandas as pd import matplotlib.pyplot as plt import matplotlib import numpy as np x=t.head(10) y=h.head(10) plt.figure size=60 plt.ylabel('类型') plt.xlabel('书籍') plt.scatter(x,y,size,color='g',label='关系') plt.legend(loc=2) plt.plot(x,y,color='r') plt.grid() plt.show()
# 绘制词云,查看出现最多的词语 import jieba from pylab import * from wordcloud import WordCloud text = '' for line in df['书名']: text += line # 使用jieba模块将字符串分割为单词列表 cut_text = ' '.join(jieba.cut(text)) color_mask = imread('D:/书本.jpg') #设置背景图 cloud = WordCloud( background_color = 'white', # 对中文操作必须指明字体 font_path='C:\Windows\Fonts\simkai.ttf', mask = color_mask, max_words = 50, max_font_size = 200 ).generate(cut_text) # 保存词云图片 cloud.to_file('qzword1cloud.jpg') plt.imshow(cloud) plt.axis('off') plt.show()

四。总代码
from bs4 import BeautifulSoup import pandas as pd import numpy import re import requests import xlwt import csv f = open("总数据.csv",mode="w",encoding="utf-8",newline='') csvwriter = csv.writer(f) def savedata(url): r=requests.get(url,timeout=30,) r.raise_for_status() r.encoding='utf_8' html=r.text soup=BeautifulSoup(html,'html.parser') body=soup.body data=body.find('div',{'class':'rank-body'}) 书名=data.find_all('div')[1].find_all("h2") 简介=data.find_all('div')[1].find_all('p',{'class':'intro'}) 更新=data.find_all('div')[1].find_all('p',{'class':'update'}) 类型=data.find_all('div')[1].find_all('a',{'data-eid':'qd_C42'}) for i in range(len(书名)): 名次=i+1 csvwriter.writerow([书名[i].text,简介[i].text,更新[i].text,类型[i].text,名次]) def main(): urllist=['https://www.qidian.com/rank/yuepiao/','https://www.qidian.com/rank/hotsales/','https://www.qidian.com/rank/readindex/','https://www.qidian.com/rank/newfans/','https://www.qidian.com/rank/recom/','https://www.qidian.com/rank/collect/','https://www.qidian.com/rank/vipup/','https://www.qidian.com/rank/vipcollect/','https://www.qidian.com/rank/vipreward/'] for i in range(0,9): url=urllist[i] savedata(url) if __name__ == '__main__': main() f.close() #一个简单的交互 from bs4 import BeautifulSoup import pandas as pd import numpy import re import requests import xlwt import csv urllist=['https://www.qidian.com/rank/yuepiao/','https://www.qidian.com/rank/hotsales/','https://www.qidian.com/rank/readindex/','https://www.qidian.com/rank/newfans/','https://www.qidian.com/rank/recom/','https://www.qidian.com/rank/collect/','https://www.qidian.com/rank/vipup/','https://www.qidian.com/rank/vipcollect/','https://www.qidian.com/rank/vipreward/'] choice=int(input('请选择你想查看的榜单:1,月票榜 2,畅销榜 3,阅读指数榜 4,粉丝榜 5,推荐榜 6,收藏榜,7,更新榜8,VIP收藏榜9,打赏榜:')) url=urllist[choice-1] r=requests.get(url,timeout=30,) r.raise_for_status() r.encoding='utf_8' html=r.text soup=BeautifulSoup(html,'html.parser') body=soup.body data=body.find('div',{'class':'rank-body'}) 书名=data.find_all('div')[1].find_all("h2") 简介=data.find_all('div')[1].find_all('p',{'class':'intro'}) 更新=data.find_all('div')[1].find_all('p',{'class':'update'}) i=0 for i in range(len(书名)): print(书名[i].text) print(简介[i].text) print(更新[i].text) #可视化部分 import matplotlib.pyplot as plt plt.rcParams['font.sans-serif'] = ['SimHei'] plt.rcParams['axes.unicode_minus'] = False df=pd.read_csv('D:/总数据表格一.csv',header=None,names=['书名','简介','更新','类型','名次']) t=df['类型'].value_counts() #输出一个柱状图 t.plot(kind='bar',color=['r','g','b']) #做出一个该书在9个榜单出现的次数的柱状图 import matplotlib.pyplot as plt plt.rcParams['font.sans-serif'] = ['SimHei'] plt.rcParams['axes.unicode_minus'] = False h=df['书名'].value_counts() h.plot(kind='bar',color=['r','g','b']) #因为书籍太多,看不清楚,这边用前40再做一图 h1=h.head(40) h1.plot(kind='bar',color=['r','g','b']) #输出书籍出现次数与其类型出现次数的更新 x=t.head(10) y=h.head(10) plt.figure size=60 plt.ylabel('类型') plt.xlabel('书籍') plt.scatter(x,y,size,color='g',label='关系') plt.legend(loc=2) plt.plot(x,y,color='r') plt.grid() plt.show() # 绘制词云,查看出现最多的词语 import jieba from pylab import * from wordcloud import WordCloud text = '' for line in df['书名']: text += line # 使用jieba模块将字符串分割为单词列表 cut_text = ' '.join(jieba.cut(text)) color_mask = imread('D:/书本.jpg') #设置背景图 cloud = WordCloud( background_color = 'white', # 对中文操作必须指明字体 font_path='C:\Windows\Fonts\simkai.ttf', mask = color_mask, max_words = 50, max_font_size = 200 ).generate(cut_text) # 保存词云图片 cloud.to_file('qzword1cloud.jpg') plt.imshow(cloud) plt.axis('off') plt.show()
(五)、总结
1.经过对主题数据的分析与可视化,可以得到哪些结论?是否达到预期的目标?
根据数据分析与可视化可以看出书籍受欢迎程度与他们的种类有一定的关系
,其中玄幻最受欢迎,能独立完成这个作业,我十分满意
2.在完成此设计过程中,得到哪些收获?以及要改进的建议?
没有成功的爬取到排名,但是通过别的方法自定了排名,因为存取是从上到下的
所以利用遍历的方式正确的写入了排名。
改进:做出更多的可视化图并理解其中的意思

 浙公网安备 33010602011771号
浙公网安备 33010602011771号