

寒假作业2/2
| 这个作业属于哪个课程 | 2021春软件工程实践|W班(福州大学) |
| 这个作业要求在哪里 | 寒假作业2/2 |
| 这个作业的目标 | 阅读《构建之法》提出十个问题,学习使用github、git,编写WordCount |
| 参考文献 | 无 |
一、我的疑惑
1.来自第三章软件工程师
文章中有提到“有人试图用‘re-work’(返工)来表示软件的质量”,个人认为只凭返工数来衡量开发质量缺乏合理性。在查阅的资料中是这样描述的:被广泛认可的衡量标准同时在教材中也有提到的是千行代码Bug率 =Bug数量/ (代码行数/1000),千行代码Bug率数值越小质量越好。结合平时在开发中的经验,一个bug有可能引发其他bug,在调试的过程中有的bug不易修改有的就易如反掌,造成“返工”的时间差异,由此我想用平均返工时间+平均返工解决的bug数来衡量开发的质量会更合理点,开发质量=平均返工时间/平均返工解决的bug数,数值越小质量越高,这样做的缺点就是为了计算开发质量要做许多记录和大量计算,耗费了时间。
2.来自第三章软件工程师
在教材3.2中软件工程师误区里提到“软件的不可见性和易变性会导致软件的依赖关系很难定义清楚,导致软件不易得到及时的维护和修复。”,在个人的开发经验中,使用多方的没有体系的依赖来开发软件不是一个聪明的选择,即使使用过多依赖,在维护时只需先更新所用的依赖,在按需维护即可。所以我感觉文中所说的复杂的依赖关系不是导致软件不易得到及时维护的原因。也查不到有关资料来验证书中的说法,所以不太懂。
3.来自第四章两人合作
在4.6.2如何正确的给予反馈中提到:“评价别人有三种层次1.最外层:行为和后果 2.中间层:习惯和动机 3.最内层:本质和固有属性 同时也给出了妥当的处理方法——‘三明治’法”,我也赞同使用最外层来评价别人,减少攻击性语言,先认同,建议,最后鼓励。不过在实际的合作中,苦口婆心劝不动的人使用三明治法来评价效果不见得显著。在评价别人时情况可能会更复杂,是否需要要考虑人际关系,职位,情感,对方的个性问题等等,所以我表示疑惑。
4.来自第五章团队和流程
在5.2团队合作的模式中有“交响乐团模式”和“功能团队模式”,根据其描述个人认识这两种模式只是规模不同,前者更大一点,其他并没有什么不同却分出了两种模式。查阅自资料:功能团队模式优点:能够互相沟通,能够发挥自己的特长,缺点:团队人员的能力不一样,需要长时间 的磨合。交响乐团模式优点:各司其职,分工明确,需要强大的领导者,缺点:不能互相沟通,如果没有领导者,这个团队就不能运行。解释了交响乐团模式还需要领导者,但其核心还是各司其职,没有什么本质区别,所以存在困惑。
5. 来自第16章IT行业的创新
在16.1.6提到的“技术是创新的关键”,经过一番思考,我认为创新的关键不只是技术,更是一个想法与大众需求碰撞的火花。高新技术如果能迅速满足人们的需要,被人们迅速接受才能说明技术是创新的关键,但据我个人经验来看很难就此定义。查阅资料:创新的关键是人生观、价值观以及bai决定这些的社会环境与文化土壤。也能说明该问题,说以我认为技术是创新的基石,还不至于是关键。
6.有趣的故事——程序中bug的名称源自“虫子”
在程序中bug一词用于技术错误。这一术语最初由爱迪生在1878年提出的,但当时并没有流行起来。在这的几年之后,美国上将Grace Hopper在她的日志本中,写下了她在Mark II电脑上发现的一项bug。不过实际上,她说的真的是“虫子”问题,因为一只蛾子被困在电脑的继电器中,导致电脑的操作无法正常运行。如图片所见,她写道“这是我在电脑上发现的第一个bug”。有意思的名字诞生伴随着有趣的意外,不得不说这个bug用来描述程序技术错误真是妙啊~~~
二、WordCount
1.项目的GitHub地址
2.PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| • Estimate | • 估计这个任务需要多少时间 | 90 | 60 |
| Development | 开发 | ||
| • Analysis | • 需求分析 (包括学习新技术) | 240 | 约180 |
| • Design Spec | • 生成设计文档 | 30 | 约10 |
| • Design Review | • 设计复审 | 10 | 0 |
| • Coding Standard | • 代码规范 (为目前的开发制定合适的规范) | 40 | 约30 |
| • Design | • 具体设计 | 90 | 约60 |
| • Coding | • 具体编码 | 300 | 约480 |
| • Code Review | • 代码复审 | 30 | 30 |
| • Test | • 测试(自我测试,修改代码,提交修改) | 120 | 约240 |
| Reporting | 报告 | ||
| • Test Repor | • 测试报告 | 60 | 约120 |
| • Size Measurement | • 计算工作量 | 20 | 20 |
| • Postmortem & Process Improvement Plan | • 事后总结, 并提出过程改进计划 | 60 | 60 |
| 合计 | 940 | 1110 |
3.解题思路
1.行数统计:
要求:任何包含非空白字符的行,都需要统计。
思路:读取有效行数(空行数量不计入),使用热readline读取,判断读取的行是否长度为零,即空行。使用总行数-空行=有效行数
2.字符数统计
要求:
- 只需要统计Ascii码,汉字不需考虑
- 空格,水平制表符,换行符,均算字符
思路:将文本按字符数组读取,记录换行符数量(不计入总词数),最后逐个读取后得到总字符数-换行数得到需要统计的字符数量。
3.单词数统计
要求:
- 英文字母: A-Z,a-z
- 字母数字符号:A-Z, a-z,0-9
- 分割符:空格,非字母数字符号
- 例:file123是一个单词, 123file不是一个单词。file,File和FILE是同一个单词
思路:将字符转为小写,从第一个字符开始读取,当a-z、0-9的字符大于等于4时,记录,再利用正则表达式过滤不合法的单词
4.统计单词出现次数
要求:
- 频率相同的单词,优先输出字典序靠前的单词。
- 例如,windows95,windows98和windows2000同时出现时,则先输出windows2000
- 输出的单词统一为小写格式
思路:将之前统计完的单词集合按数量从多到少排序,取前十个
4.代码规范
5.设计与实现过程
(ps:由于我是在编码时也考虑了性能改进,所以将这两个部分合起来)
1.设计与改进过程
初始设计的程序整体流程 改进后的程序整体流程

分析 :改进前的设计整体采用的是顺序结构,先统计字符和行数,最后统计单词数量,在初始程序做完后简单测试了一下(还未测试正确性)发现效率实在太低了,500万+行的数据用了快一分钟,后来思考在统计行数,单词,字符时没有相关性,即可以用多线程解决问题。在一波测试下发现读取耗时与统计耗时差不多,另外在数据量不算太大的情况下统计行数和字符 数的耗时之和与统计单词的耗时是差不多的,所以可以将行数字符串行再和单词并行统计。单词统计的采用HashMap保存数据,读取、判断、计算、合并的一系列操作会增加耗时,所以把单词统计分为多个子线程并行计算。最后整理结果输出。
2.实现过程
(ps:初版的代码被我删了 0.o ,所以目前没办法做前后比较 )
1.字符、行数统计核心函数:
@Override
public void run() {
try { //输入
InputStreamReader read = new InputStreamReader(new FileInputStream(filePath), "utf-8");
BufferedReader in = new BufferedReader(read);
String temp = null;
startTime = System.currentTimeMillis(); //开始计时
char[] chars = new char[1000];
int whileCount = 0;
int remain = 0;
while ((in.read(chars)) != -1) { //统计换行符与字符数
remain = 0;
for (int i = 0;i < chars.length;i++){
if (chars[i] == '\n') lineNum++;
if((int)chars[i] == 0) {
remain = i;
break;
}
}
whileCount++;
}
int flag = 0;
if(lineNum == 0 && whileCount != 0){
lineNum += 1;
flag = 1;
}
if(whileCount == 0) whileCount++; //将统计结果分类,计算实际结果
if(flag == 1) charNum = (whileCount - 1 ) * 1000 + remain;
else charNum = (whileCount -1) * 1000 + remain - lineNum;
in.close();
useTime = System.currentTimeMillis() - startTime;
}catch (Exception e){
e.printStackTrace();
}
}
算法描述:由于readline读不到'\r',采用read读取进char[]内,一次读取1k个字符,再循环统计换行符;有几种情况:无换行符但有数据则输出行数为1; 无换行符无数据则输出行数为0;有换行符有数据则输出行数为换行符数量加一(此办法无法判断空行,后面有进行改进),最后字符数为统计得字符数-换行符数(换行符不计入总字符)。
2.单词统计核心函数:
①线程分配与合并统计
private void count(String filePath,int lineToThread){
try { //输入
InputStreamReader read = new InputStreamReader(new FileInputStream(filePath), "utf-8");
BufferedReader in = new BufferedReader(read);
String temp = null;
StringBuffer toStatisticsStr=new StringBuffer();
int nowlineNum=0;
List multiCounterList=new ArrayList<>();
while (true) { //读取行,分配给多个线程
boolean flag= (temp = in.readLine()) == null;
if(!flag){
toStatisticsStr.append(temp + "-");
if((temp + "-").length() == 1){
emptyLineNum++;
}
}
nowlineNum++;
if(nowlineNum >= lineToThread || flag){
multiCounterList.add(new MultiCounter(toStatisticsStr)); //创建心线程并启动
multiCounterList.get(multiCounterList.size() - 1).start();
nowlineNum=0;
if(toStatisticsStr.length()!=0) toStatisticsStr.delete(0,toStatisticsStr.length()-1);
}
if (flag) {
in.close();
break;
}
}
in.close();
for(int i = 0;i < multiCounterList.size();i++){
multiCounterList.get(i).join(); //所有线程结束后合并Map
mergeMap(multiCounterList.get(i).getPartWordHashMap());
}
sortByValue(); //按value排序
}catch (Exception e){
e.printStackTrace();
}
}
算法描述:每读取N行就将读取的数据交给新线程统计单词,待所有线程统计完成后将统计结果合并至父线程的Map里,同时计算子线程统计的单词总数,按数量排序得数量前十的单词
①子线程的统计
@Override
public void run(){
str.toLowerCase();
int wordLength=0;
String tempWord=null;
for (int i = 0;i < str.length();i++){
int asciiNum=(int)str.charAt(i);
if((asciiNum >=48 && asciiNum <= 57)||(asciiNum >= 97 && asciiNum <= 122)){
wordLength++; //读取可以成为单词的字符
}else{
tempWord=str.substring(i - wordLength,i);
if(wordLength>3 && isWord(tempWord)){ //获取两个分隔符的间的单词是否为合法单词
if(partWordHashMap.containsKey(tempWord)){
partWordHashMap.put(tempWord,partWordHashMap.get(tempWord)+1); //保存进线程自己的Map
}else{
partWordHashMap.put(tempWord,1);
}
}else{
tempWord=null;
}
wordLength=0;
}
}
}
算法描述:子线程将自己获得的字符串筛选出单词,原理是先获取分隔符间的字符串,判断长度是否大于等于4,使用正则表达式判断其是否为合法单词
3.输入输出
public Output(int characterNum, int lineNum, int wordNum,int emptyLine,
List<Map.Entry<String,Integer>> mapList, String outPutFilePath) {
this.characterNum = characterNum;
this.lineNum = lineNum-emptyLine;
this.wordNum = wordNum;
this.outPutFilePath = outPutFilePath;
this.emptyNum=emptyLine;
topTen=new ArrayList<>();
int count=0;
for (Map.Entry<String,Integer> me:mapList) {
topTen.add(me.getKey()+": "+me.getValue());
}
}
public void writeToOutPut(){
try {
BufferedWriter out = new BufferedWriter(new FileWriter(outPutFilePath));
out.write("character: "+characterNum+"\t\n");
out.write("word: "+wordNum+"\t\n");
out.write("line: "+lineNum+"\t\n");
for (int i=0;i<(topTen.size()>=10?10:topTen.size());i++){
out.write(topTen.get(i)+"\t\n");
}
out.close();
System.out.println("文件输出成功!");
} catch (IOException e) {
e.printStackTrace();
}
}
public void show(){
System.out.println("character: "+characterNum);
System.out.println("word: "+wordNum);
System.out.println("line: "+lineNum);
for (int i=0;i<(topTen.size()>=10?10:topTen.size());i++){
System.out.println(topTen.get(i));
}
}
6.性能改进
(1)采用BufferReader:将字符批量读取缓冲区,与Reader相比之下效率更高。
(2)采用多线程与线程分配量的优化:
性能测试数据采用538W行,每行约12~15个字符,基本思想是每个线程分配N行,运行计算耗时,测试结果如下:

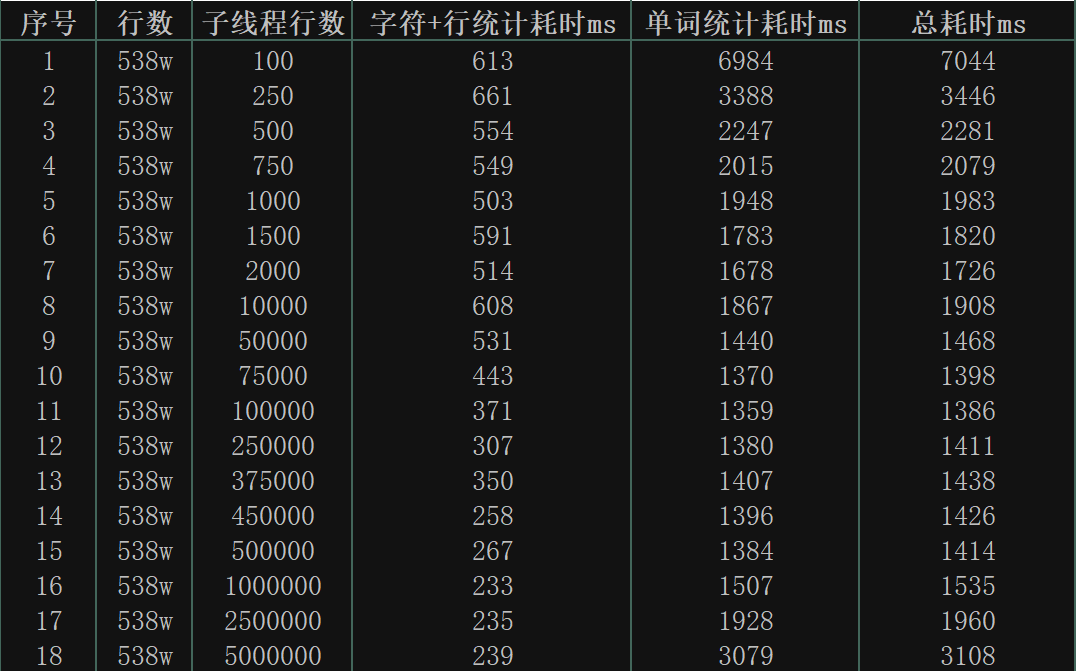
测试输出结果如下:

结论:小型数据测试下无法体现性能差异,或者说性能差异不大,在中型数据538W行测试下接近最优的行数为10W行,约为总量的2%,此时效率最佳,大概比初始版本提高了60%的效率,在子线程较多的情况下初始化线程计算完再合并做了太多无用功,得不偿失;在较少线程如500w行,大概退化为单线程情况下,效率也不高。测试过5000W行数据,内存爆炸所以就不整辣么多了。
(3)采用正则表达式匹配:采用正则表达式过滤合法单词,比自己写一个判断函数逐字符判断来的有效率。原理见:Java中的正则表达式性能概述
7.代码覆盖率与单元测试
1.代码覆盖率截图
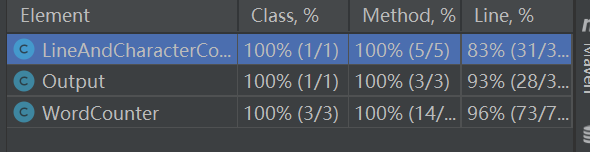
个人在编码优化代码覆盖率的方法:减少分支合并多种情况;减少不必要的判断;简化逻辑。
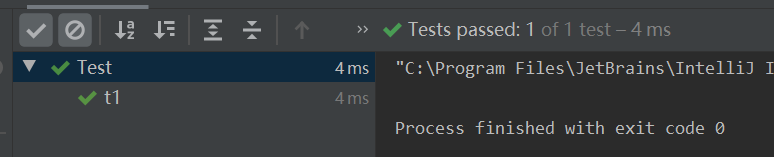
2.字符行数统计单元测试使用
/*字符行数统计单元测试*/
@org.junit.Test
public void t1(){
int lineNum=0;
int charNum=0;
String path="C:\\Users\\cmy\\Desktop\\input.txt";
try { //输入
InputStreamReader read = new InputStreamReader(new FileInputStream(path), "utf-8");
BufferedReader in = new BufferedReader(read);
String temp = null;
char[] chars = new char[1000];
int whileCount = 0;
int remain = 0;
while ((in.read(chars)) != -1) {
remain = 0;
for (int i = 0;i < chars.length;i++){
if (chars[i] == '\n') lineNum++;
if((int)chars[i] == 0) {
remain = i;
break;
}
}
whileCount++;
}
int flag = 0;
if(lineNum == 0 && whileCount != 0){
lineNum += 1;
flag = 1;
}
if(whileCount == 0) whileCount++;
if(flag == 1) charNum = (whileCount - 1 ) * 1000 + remain;
else charNum = (whileCount -1) * 1000 + remain - lineNum;
if(lineNum != 0 ){
lineNum += 1;
}
in.close();
}catch (Exception e){
e.printStackTrace();
}
Assert.assertEquals(charNum,99);
Assert.assertEquals(lineNum,10);
}
测试通过
8.异常处理
1.IO异常:在读取前判断文件是否存在
2.内存溢出:控制台报告错误
3.计算时数组越界:控制台报告错误,提示检查输入
9.心得体会
在看到题目前就感觉这不是一个简单的字符统计,在实际的编码实现时就印证的当时的想法。我们要做的其实不单只是这个程序还有学习一个项目从确定需求,设计,编码,调试,最后检测性能这一套开发流程。写到这回想起来感觉自己学到了不少:深入理解正则表达式的原理;巩固java多线程的使用;学会使用guthub desktop等等。然而做到这里回想起来起来确实还有不足之处:都是自己蛮干缺少与同学沟通交流经验,不太习惯用单元测试,还是常用土办法把变量System.out输出调试程序。。。
总之感觉还行


 浙公网安备 33010602011771号
浙公网安备 33010602011771号