flume通过avro对接(汇总数据)
使用场景:
把多台服务器(flume generator)上面的日志汇总到一台或者几台服务器上面(flume collector),然后对接到kafka或者HDFS上

Flume Collector服务端
vim flume-server.properties
# agent1 name a1.channels = c1 a1.sources = r1 a1.sinks = k1 #set channel a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # other node, slave to master a1.sources.r1.type = avro a1.sources.r1.bind = master a1.sources.r1.port = 52020 # set sink to logger a1.sinks.k1.type = logger a1.sources.r1.channels = c1 a1.sinks.k1.channel=c1
启动:
## Master
/usr/local/flume/bin/flume-ng agent –f flume-server.properties –name a1
Flume Generator客户端
vim flume-client.properties
# a1 name a1.channels = c1 a1.sources = r1 a1.sinks = k1 #set channel a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 a1.sources.r1.channels = c1 a1.sources.r1.type = exec a1.sources.r1.command = tail -f /root/test.log # set sink1 #a1.sinks.k1.type = logger a1.sinks.k1.channel = c1 a1.sinks.k1.type = avro a1.sinks.k1.hostname = master a1.sinks.k1.port = 52020 a1.sources.r1.channels = c1 a1.sinks.k1.channel=c1
启动:
分别在slave1和slave2服务器上面启动
/usr/local/flume/bin/flume-ng agent –f flume-client.properties –name a1
启动之后,在slave1和slave2服务器上面分别执行以下操作:
#slave1 echo "wangzai slave1" > /root/test.log #slave2 echo "wangzai slave2" > /root/test.log
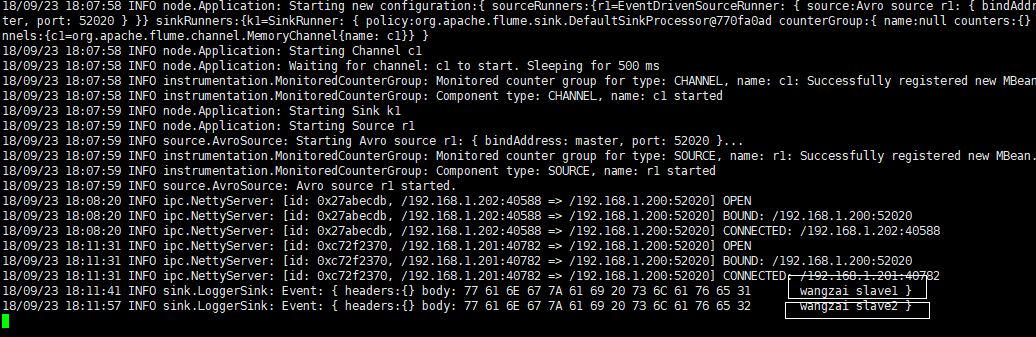
结果:
Master:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号