
爬取今日头条中的图片
代码:https://github.com/factsbenchmarks/jinritoutiao
今日头条搜索 :cos.
网址:https://www.toutiao.com/search/?keyword=cos
分析1 在network的doc中的Preview,看到只有一句话,并没有页面的信息,所以判定存在异步加载。

分析2 在XHR中,果然找到相关的json数据。注意,只有key值是 media_creator_id 才会是页面中显示的。

推荐一个chrome上的插件。JSON-handler,可以将json数据显示的更美观。
这便是其效果。
分析3 在data下拿到每个item 的url,访问这个url。这里面有点玄机。
比如,我们访问这个url:https://www.toutiao.com/a6543541911368499725/
如果你用BeautifulSoup的select或者find方法,都找不到图片的 a 标签。尽管前端的html页面中会显示这个 a 标签。
那么,图片的地址放在那里了呢?
实际上可以通过Network-->doc-->Response查到
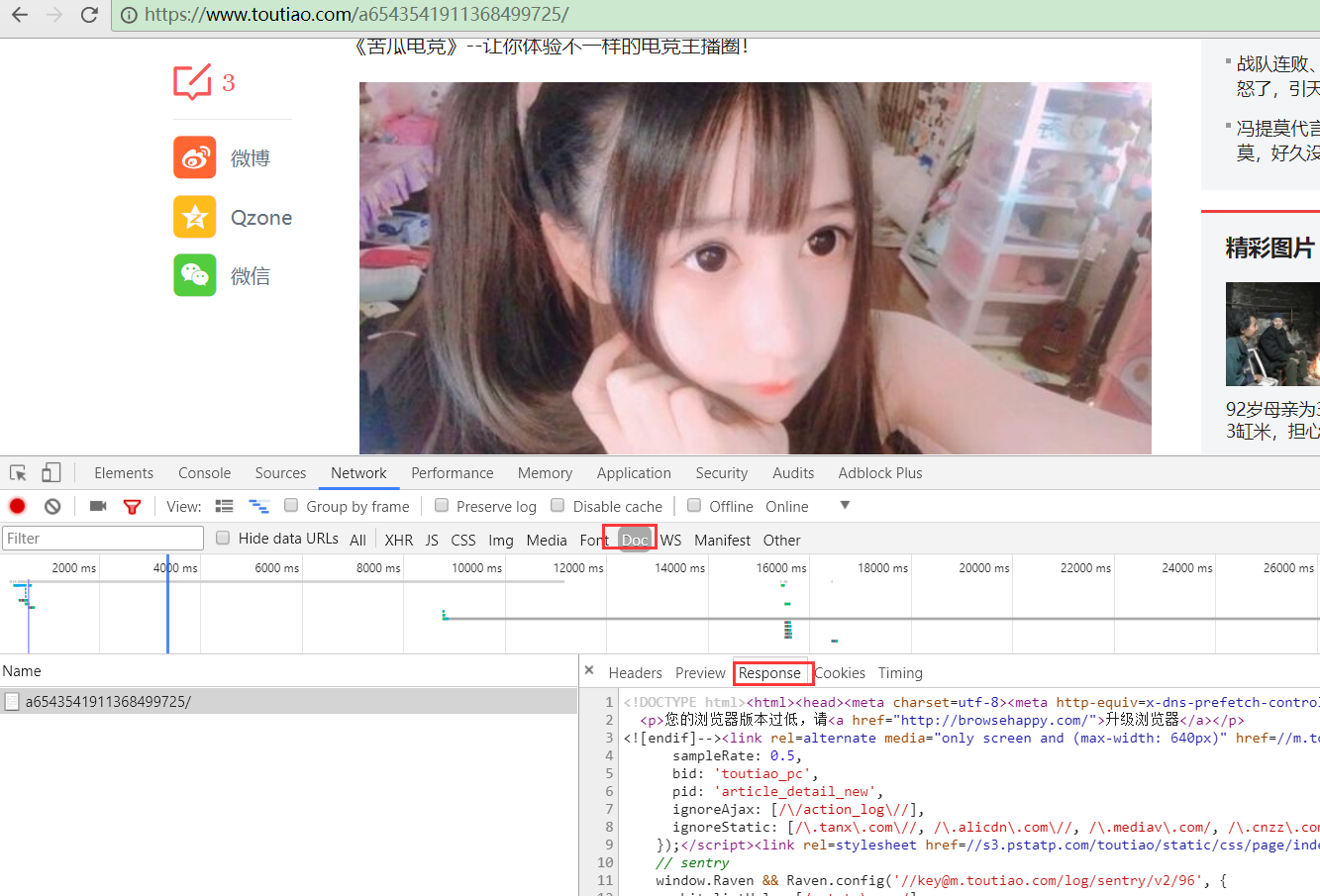
分析 4 ,查看图片的绝对地址,然后,在doc-->Resoponse 中查找。可以发现是在articleInfo字典,content字段中。
这个页面的所有数据都在这里。
如何找到这个url呢? 通过正则匹配。


分析5 拿到绝对地址,可以报图片下载下来,并将url保存到数据库中。

