小试牛刀
1 将你的 QQ 头像(或者微博头像)右上角加上红色的数字,类似于微信未读信息数量那种提示效果。 类似于图中效果

def add_num(img): draw = ImageDraw.Draw(img) x,y = img.size # 在window系统中字体,字体都在 C:\Windows\Fonts\文件中,这里选的是楷体 font = ImageFont.truetype(r'C:\Windows\Fonts\simkai.ttf',size=50) # 颜色是草青色 fillcolor='#1ce50d' draw.text((x-100,0),'学友',font=font,fill=fillcolor) img.save('zhang.jpg') return 0 if __name__ == '__main__': img=Image.open(r'C:\Users\zuo\Desktop\zhang.jpg') add_num(img)
2 做为 Apple Store App 独立开发者,你要搞限时促销,为你的应用生成激活码(或者优惠券),使用 Python 如何生成 200 个激活码(或者优惠券)。
总结:
注释掉的是自己写的, 列表生成器是参照别人。 明显简练了许多。
最后,用到了 join()。
import random def coupon(f): # coupon_str='' # for i in range(10): # num = random.randint(48,57) # b = chr(random.randint(65,90)) # s = chr(random.randint(97,122)) # res=random.choice([num,b,s]) # coupon_str += str(res) # coupon_str += '\n' # f.write(coupon_str) s = [random.choice([str(random.randint(48,57)),chr(random.randint(65,90)),chr(random.randint(97,122))]) for i in range(10)] f.write(''.join(s)+'\n') if __name__ == '__main__': n = 200 # n 代表想要随机多少个优惠券 f = open('coupon.txt','w') for i in range(n): coupon(f)
f.close()
3 将 0001 题生成的 200 个激活码(或者优惠券)保存到 MySQL 关系型数据库中。
import random import pymysql def gen_coupon(n): coupon_l=[] for i in range(n): s = [random.choice([str(random.randint(0,9)),chr(random.randint(65,90)),chr(random.randint(97,122))]) for j in range(10)] s = ''.join(s) coupon_l.append(s) return coupon_l def store(coupons): conn = pymysql.connect(host='localhost',user='zuo',password='123',port=3306) cur = conn.cursor() #Create a new cursor to execute queries with cur.execute('create database if not EXISTS coupon;') #Execute a query cur.execute('use coupon;') # 注意这个创建表格的sql语句,第一次写 报错调试了半个小时。 cur.execute('create table if not exists coupons(id INT NOT NULL auto_increment ,coupon VARCHAR (32) NOT NULL,PRIMARY KEY (id)); ') for coupon in coupons: cur.execute('insert into coupons (coupon) VALUES (%s);',(coupon)) conn.commit() #Commit changes to stable storage cur.close() conn.close() if __name__ == '__main__': coupons=gen_coupon(10) store(coupons)
4 任一个英文的纯文本文件,统计其中的单词出现的个数。
方法一:
总结:这是很简单就能想到的方法。但是说实话,很low。
if __name__ == '__main__': f = open('test.txt','r',encoding='utf8') dic={} for line in f: words=line.split(' ') # print(words) for word in words: if word.isalpha() or word.isdigit(): word = word.strip('\n') # print(word) if word not in dic: dic[word]=1 else: dic[word] += 1 print(dic)
方法二:
看到别人的方法,竟然是用正则表达式,我第一反应就是正则表达式还可以是这样用的喽!
利用到了一个 \b,精髓所在。
if __name__ == '__main__': dic={} import re # \b 匹配一个单词边界,也就是指单词和空格间的位置。 obj = re.compile('\b?[a-zA-Z]+\b?') # Compile a regular expression pattern, returning a pattern object.此pattern乃是精髓所在!! with open('test.txt','r',encoding='utf8') as f: for line in f: word_list=obj.findall(line) for word in word_list: if dic.get(word): dic[word] += 1 else: dic[word] = 1 with open('result','w',encoding='utf8') as f: for word,num in dic.items(): f.write('{}:{}{}'.format(word,num,'\n'))
结果:
indexmodules:2 next:2 previous:2 Python:8 Documentation:2 The:20 Standard:2 Library:2 File:2 and:77 Directory:4 ....
5 你有一个目录,装了很多照片,把它们的尺寸变成都不大于 iPhone5 分辨率的大小。
总结:
os.listdir()的用法,取到文件夹内的每一个文件名。
img.thumbnail() 用法,变缩略图。
img.save() 保存的时候,需要一个给定的文件名。
if __name__ == '__main__': import os from PIL import Image # 1136x640 iphone5的像素大小 dir = r'C:\Users\zuo\Desktop\pic' # os.listdir() Return a list containing the names of the files in the directory. file_paths = os.listdir(dir) for file in file_paths: img = Image.open(os.path.join(dir,file)) x,y = img.size if x > 1136 or y > 640: #Make this image into a thumbnail.This method modifies theimage to contain # a thumbnail version of itself, no larger than the given size. img.thumbnail((1136,640)) #Saves this image under the given filename. If no format is specified, # the format to use is determined from the filename extension, if possible. img.save(os.path.join(dir,file))
6 你有一个目录,放了你一个月的日记,都是 txt,为了避免分词的问题,假设内容都是英文,请统计出你认为每篇日记最重要的词。
这个题是在第四题的基础上延伸而来的。
发现了一个很厉害的模块。collections模块。可以大大减少代码量。
核心代码:
if __name__ == '__main__': dic = {} l = [] import re # \b 匹配一个单词边界,也就是指单词和空格间的位置。 obj = re.compile('\b?[a-zA-Z]+\b?') # Compile a regular expression pattern, returning a pattern object.此pattern乃是精髓所在!! with open('test.txt','r',encoding='utf8') as f: for line in f: word_list = obj.findall(line) for word in word_list: l.append(word) import collections # Counter:Dict subclass for counting hashable items.Sometimes called a bag or # multiset. Elements are stored as dictionary keys and their counts are stored # as dictionary values. counter_dic = collections.Counter(l) print(counter_dic) # sorted:Return a new list containing all items from the iterable in ascending order. # A custom key function can be supplied to customize the sort order, and the reverse # flag can be set to request the result in descending order. #!尽管以设定了某种自定义的排序,可能是以某种value值的大小进行排序,但是返回的排序 # 结果还是key值 keywords = sorted(counter_dic,key=lambda x:counter_dic[x],reverse=True) print(keywords)
输出:
Counter({'the': 222, 'is': 114, 'to': 78, 'and': 77, 'a': 70, 'of': 69, 'file': 59, 'be': 57, ....})
['the', 'is', 'to', 'and', 'a', 'of', 'file', 'be', 'copy', 'shutil',....]
总结:
sorted 内置函数。
与列表的sort函数有两点不同。
sort只是列表的方法。sorted可以对任何可迭代对象都可以使用。
sort是列表的方法,修改对原列表生效。sort 函数是生成一个新的可迭代对象,原来的不改动,所以需要新变量名来接收这个返回值。
更强大的是功能是,可以设定参数 key = lambada x:.. ,自定义其排序的依据。可以对字典进行排序,返回排好序的key值。是这样的。
collections模块
Counter类
接收一个可迭代对象,返回一个字典。key是列表中的元素,value值元素出现的个数。
8 一个HTML文件,找出里面的正文。
9 一个HTML文件,找出里面的链接。
if __name__ == '__main__': #Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库. from bs4 import BeautifulSoup f = open(r'C:\Users\zuo\Desktop\test.html',encoding='utf8') # BeautifulSoup的__init__ The Soup object is initialized as the 'root tag', # and the provided markup (which can be a string or a file-like object) is fed into the # underlying parser. text = BeautifulSoup(f,'lxml') # s = 'xxoo' text = BeautifulSoup(s) #findAll: Extracts a list of Tag objects that match the given criteria. # You can specify the name of the Tag and any attributes you want the Tag to have. urls = text.findAll('a') # get_text() Get all child strings, concatenated using the given separator. content = text.get_text() for url in urls: print(url) print(content)
总结:
用到了BeautifulSoup模块,在BS4里。BeautifulSoup有很多东西。参考文档。
用到了findAll()和get_text ()两个方法。
10 使用 Python 生成类似于下图中的字母验证码图片

if __name__ == '__main__': from PIL import Image,ImageDraw,ImageFont,ImageFilter import random length = 300 heigth = 75 def random_color(): return (random.randint(0,255),random.randint(0,255),random.randint(0,255)) def random_num(): return random.randint(0,9) def random_alpha(): return random.choice([chr(random.randint(65,90)),chr(random.randint(97,122))]) # Creates a new image with the given mode and size. #(255,255,255) 是全白 img = Image.new('RGB',(length,heigth),(255,255,255)) draw = ImageDraw.Draw(img) # This function loads a font object from the given file or file-like # object, and creates a font object for a font of the given size. # 字体大小是在这里确定。 font = ImageFont.truetype(r'C:\Windows\Fonts\consolaz.ttf',50) for i in range(length): for j in range(heigth): # point: Draw one or more individual pixels draw.point((i,j),fill=random_color()) for x in range(4): draw.text((30+65*x,10),random.choice([str(random_num()),random_alpha()]),fill=random_color(),font=font) #filter: Filters this image using the given filter img = img.filter(ImageFilter.BLUR) img.save('a.jpg') #show Displays this image. This method is mainly intended for debugging purposes img.show('a.jpg')
总结:
1 创建新的对象 —— Image.new()
2 在图像上画像素点 —— draw.point()
3 在图像上写数字,字母 —— draw.text()
4 模糊化处理 —— img.filter(ImageFilter.BLUR)
13 用 Python 写一个爬图片的程序,爬 这个链接里的日本妹子图片 :-)
if __name__ == '__main__': import requests import re import os from bs4 import BeautifulSoup r = requests.get(r'http://tieba.baidu.com/p/2166231880?see_lz=1') #findAll: Extracts a list of Tag objects that match the given criteria. # You can specify the name of the Tag and any attributes you want the Tag to have. # The value of a key-value pair in the 'attrs' map can be a string, a list of strings, # a regular expression object, or a callable that takes a string and returns whether or # not the string matches for some custom definition of 'matches'. # The same is true of the tag name. b = BeautifulSoup(r.text, 'lxml') imgs = b.findAll('img',bdwater=re.compile(r'杉本有美吧')) # imgs = b.findAll('img',bdwater='杉本有美吧,1280,860') for img in imgs: #os.path.split: Return tuple (head, tail) where tail is everything after the final slash. # Either part may be empty. # img['src'] tag的属性的操作方法与字典相同 with open(os.path.split(img['src'])[1],'wb') as f: f.write(requests.get(img['src']).content)
总结:
1 os.path.split(path)[1] ,可以拿到文件的文件名
print(os.path.split(r'C://aa//bb//cc'))
输出:
('C://aa//bb', 'cc')
2 soup.findAll()的参数问题。
soup.find('a',href=re.compile('^xx')),表示查找 是以xx开的 href属性的a标签
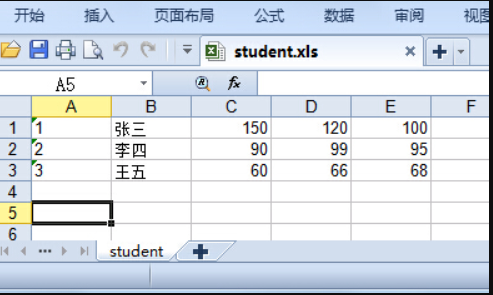
14 纯文本文件 student.txt为学生信息, 里面的内容(包括花括号)如下所示:
{ "1":["张三",150,120,100], "2":["李四",90,99,95], "3":["王五",60,66,68] }
请将上述内容写到 student.xls 文件中,如下图所示:
先补充一下OrderDict的一些知识。
import json from collections import OrderedDict dic = dict() dic['a'] = 'a' dic['b'] = 'b' print(dic) dic = OrderedDict() dic['a'] = 'a' dic['b'] = 'b' print(dic) with open('test.txt')as f: data = json.load(f) print(data) with open('test.txt') as f: data = json.load(f,object_pairs_hook=OrderedDict) print(data)
输出: 注意样式区别。
{'a': 'a', 'b': 'b'}
OrderedDict([('a', 'a'), ('b', 'b')])
{'1': ['tom', 150, 120, 100], '2': ['loda', 90, 99, 95], '3': ['kroky', 60, 66, 68]}
OrderedDict([('1', ['tom', 150, 120, 100]), ('2', ['loda', 90, 99, 95]), ('3', ['kroky', 60, 66, 68])])
正式代码
if __name__ == '__main__': import xlwt,json from collections import OrderedDict with open('test.txt') as f: data = json.load(f,object_pairs_hook=OrderedDict) #Workbook: This is a class representing a workbook and all its contents. # When creating Excel files with xlwt, you will normally start by # instantiating an object of this class. workbook = xlwt.Workbook() #add_sheet:This method is used to create Worksheets in a Workbook. #cell_overwrite_ok: If ``True``, cells in the added worksheet will not raise an exception if written to more than once. #sheet1: <class 'xlwt.Worksheet.Worksheet'> sheet1 = workbook.add_sheet('student',cell_overwrite_ok=True) # data:OrderedDict([('1', ['tom', 150, 120, 100]), ('2', ['loda', 90, 99, 95]), ('3', ['kroky', 60, 66, 68])]) # data.items():odict_items([('1', ['tom', 150, 120, 100]), ('2', ['loda', 90, 99, 95]), ('3', ['kroky', 60, 66, 68])]) # data.keys():odict_keys(['1', '2', '3']) # data.values(): odict_values([['tom', 150, 120, 100], ['loda', 90, 99, 95], ['kroky', 60, 66, 68]]) for index,(key,values) in enumerate(data.items()): #write:This method is used to write a cell to a :class:`Worksheet`. sheet1.write(index,0,key) for i,value in enumerate(values): sheet1.write(index,i+1,value) workbook.save('student.xls')
总结:
1 xlwt模块
workbook=xlwt.WokrBook()
sheet1=workbook.add_sheet('name',cell_overwrite_ok=True)
sheet1.write()
workbook.save()
2 from collections import OrderDict
记住OrderDict的样式
3 json模块
json.load(f,object_paires_hook=OrederDict)
15 纯文本文件 city.txt为城市信息, 里面的内容(包括花括号)如下所示:
{ "1" : "上海", "2" : "北京", "3" : "成都" }
请将上述内容写到 city.xls 文件中
if __name__ == '__main__': import json from collections import OrderedDict import xlwt data = json.load(open('test.txt',encoding='utf8'),object_pairs_hook=OrderedDict) workbook = xlwt.Workbook() sheet1 = workbook.add_sheet('city',cell_overwrite_ok=True) for index,(key,value) in enumerate(data.items()): sheet1.write(index,0,key), sheet1.write(index,1,value) workbook.save('city.xls')
总结:
1 不用要记事本打开文本文件,记事本会乱加BOM,python解释器会报错。BOM(Byte Order Mark),字节顺序标记,出现在文本文件头部。
2 for index,(key,value) in enumerate(data.items()) 这是正确的写法
for index,(key,value) in enumerate(data) 这是我第一次写,想当然的认为,这样写实错误的。
验证如下:
dic = {'x':1,'y':2}
print(dic)
print(dic.items(),type(dic.items()))
print(dic.keys(),type(dic.keys()))
print(dic.values(),type(dic.values()))
输出:
{'x': 1, 'y': 2}
dict_items([('x', 1), ('y', 2)]) <class 'dict_items'>
dict_keys(['x', 'y']) <class 'dict_keys'>
dict_values([1, 2]) <class 'dict_values'>
20 对从中国联通导出的通话详单,对通话时间进行统计。通话详单是xls格式。

if __name__ == '__main__': import xlrd import re reobj = re.compile('(\d+)\D') def foo(filename): excel = xlrd.open_workbook(filename) sheet = excel.sheet_by_index(0) row_nums = sheet.nrows col_nums = sheet.ncols total_time = 0 min = 0 sec = 0 for i in range(1,row_nums): time = sheet.cell_value(i,3) res = reobj.findall(time) if len(res) == 2: min += int(res[0]) sec += int(res[1]) else: sec += int(res[0]) min1 = int(sec) // 60 sec = int(sec) % 60 min = int(min) + min1 h = min // 60 min = min % 60 return '通话时间 {}小时{}分钟{}秒'.format(str(h),str(min),str(sec)) print(foo(r'C:\Users\zuo\Desktop\2017年09月语音通信.xls'))
总结:
1 xlrd 模块 是python中操作excel文件的模块。
常用方法
excel = xlrd.open_workbook(filename)
sheet = excel. sheet_by_index(0)
row_nums = sheet.nrows
col_nums = sheet.ncols
从表格中取值
sheet.cell_value( i , j )
# value of the cell in the given row and column
2 利用正则表达式从表格数据中取值,数据格式是'1分50秒','38秒',这种夹杂着汉字的样式。
\D 匹配一个非数字字符,等价于[^0-9]
\d 匹配一个数字字符,等价于[0-9]
re.compile('\d+\D')。反正这样写,我是没想出来!
21 通常,登陆某个网站或者 APP,需要使用用户名和密码。密码是如何加密后存储起来的呢?请使用 Python 对密码加密。
import hashlib import os from hmac import HMAC def encrypt_password(password,salt=None): ''' Hash password on the fly :param password: :param salt: :return: ''' if salt == None: # urandom:Return a bytes object containing random bytes suitable for cryptographic use salt = os.urandom(8) password = password.encode('utf-8') # 这里先随机生成 64 bits 的 salt,再选择 SHA-256 算法使用 HMAC 对密码和 salt # 进行 10 次叠代混淆,最后将 salt 和 hash 结果一起返回。 for i in range(10): #digest: Return the hash value of this hashing object.This returns a # string containing 8-bit data. The object is not altered in any way # by this function; you can continue updating the object after calling # this function. password = HMAC(password,salt,hashlib.sha256).digest() return (salt + password) def valid_password(input_password,hashed): return hashed == encrypt_password(input_password,hashed[:8]) hashed = encrypt_password('xxxxxx') valid_password('xxxxx',hashed[:8])
总结:
1 os.urandom(x) 随机生成 x 位16进制字符串
2 hmac模块内的HMAC类的参数
HMAC(密码,加盐,加密的方法)
digest()
3 方法是很值得推荐的,很巧妙!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号