Numpy的补充(重要!!)
轴的概念
英文解释 https://www.sharpsightlabs.com/blog/numpy-axes-explained/
汉化解释 https://www.jianshu.com/p/f4e9407f9f9d
多维数组的索引及切片
https://blog.csdn.net/brucewong0516/article/details/79186126
核心 每个维度一个索引值,逗号分割
每个维度取切片用冒号
隔行取 需嵌套索引,arr[ [ 1,3,4,5] , : ]
np.newaxis
给原数组增加一个维度,newaxis放在第几个位置,就会在shape里 相应的位置增加了一个维数
https://www.jb51.net/article/144967.htm

广播机制
涉及到不同shape的数组运算的时候的概念
https://www.runoob.com/numpy/numpy-broadcast.html
https://zhuanlan.zhihu.com/p/60365398
np.where( condition, [x, y] )
condition:array_like,bool
x,y:array_like
实际上 感觉涉及到的东西很多,比如涉及到了广播。这个应该是个很强大的方法。某种程度上像布尔值索引。
https://zhuanlan.zhihu.com/p/83208224

arr.reshape(1,-1) / np.reshape(-1,1)
实际就是自动计算的方法。-1代表自动计算,666
https://blog.csdn.net/W_weiying/article/details/82112337

数组的添加 有两个方法 np.insert 和 np.append
np.insert(arr, obj, values, axis=None)
https://blog.csdn.net/lcxxcl_1234/article/details/80869152
1 values 可能是个m*1维数组

np.append()

数组的行列相互交换
不值一提了

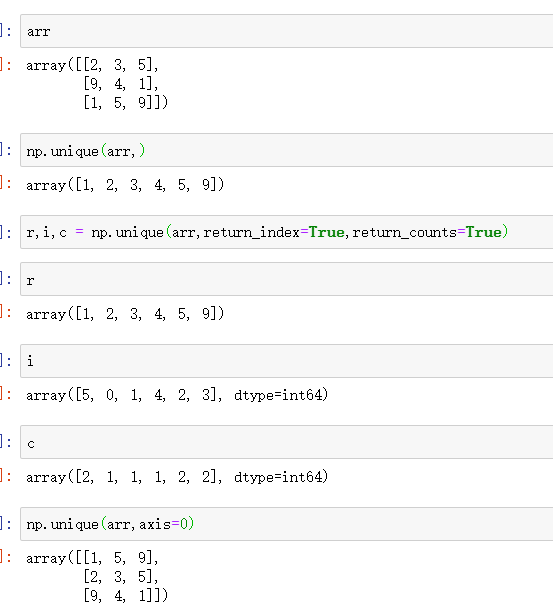
np.unique(ar,return_index=False,return_inverse=False,return_counts=False,axis=None)
最常用的功能是 去重。
有这几个参数,return_index,return_counts 可能用到的频率比较高。知道有这几参数就行。
当指定axis后,对多维数组可以使用,不会返回惟一值,而是对指定轴进行排序。
np.maximum()
返回较大值,参数可以广播。完全可以用np.where 实现。可能 广播机制 会用的比较广。

np.concatenate()
与np.stack的区别是 concatenate不改变维度

DateFram的切片,索引
牢记,一定优先用 df.loc[ ]
df.loc['a':'c','xx':'xxx'] 只有这一种方法,可以取多行多列
df.loc[['a','d'],['xx','xxxx']]
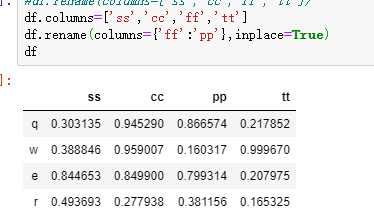
df.rename()
用处就是对index,column进行重命名。
也可以df.index = df.columns = 直接改。这个方法的好处就是可以对想单独改一个名称比较方便,参数可以是字典。
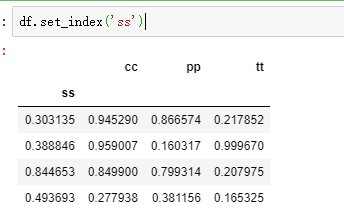
df.set_index()
Set the DataFrame index using existing columns
可能会有一定的应用场景。原来一列的数值,变为index,对从数据库中读到的数据,把id变为index,这种场景下就能用到了
DateFrame 两个df的合并
df.append(df1)

pd.concat( [df1,df2] )

pct_change()
计算变化率 (后一个值-前一个值)/前一个值
df.dropna()
这几个参数注意下
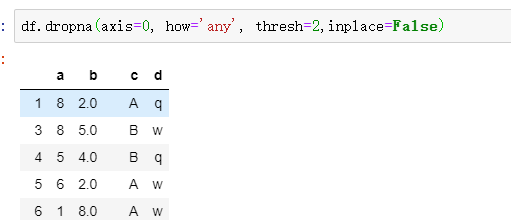
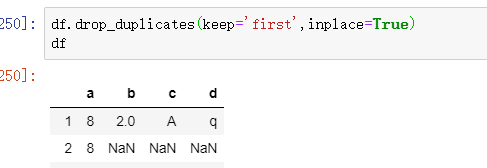
df.drop_duplicates
去重,这几个参数眼熟下
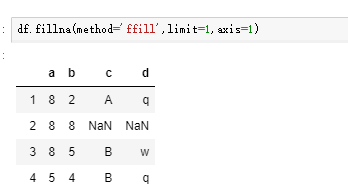
df.fillna()
添补na数据。熟悉下这几个参数
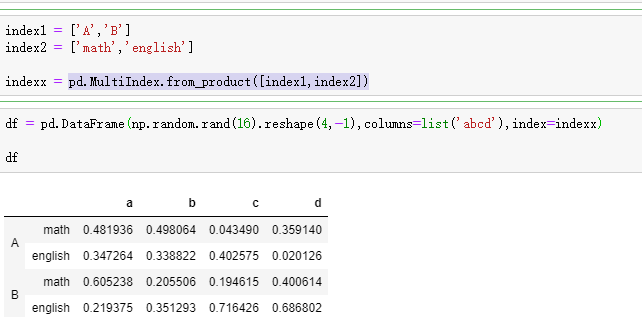
多重索引
了解下这个方法就够了,切片,索引都差不多
pd.MultiIndex.from_product([index1,index2])
聚合运算
什么叫聚合函数,聚合函数就是对一组值执行计算,并返回单个值。返回单个值,这是重点!
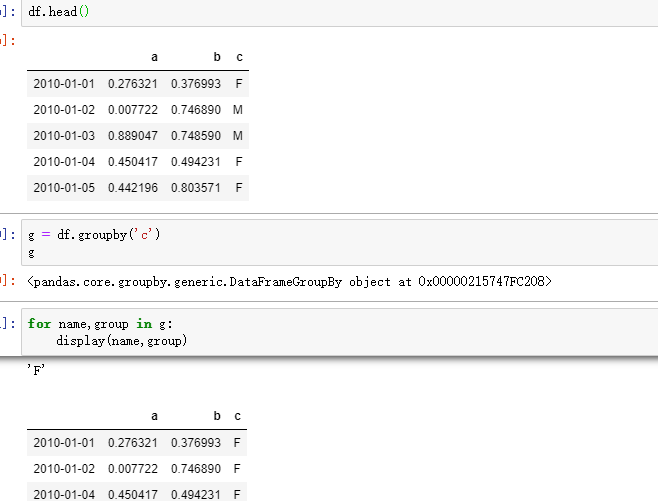
g = df.groupby(' ')
1)这个 g 可以拿来直接聚合 ,g.agg( ) , g.apply( ) ,这里想说的不是这个,而是 g 本身有很多方法。
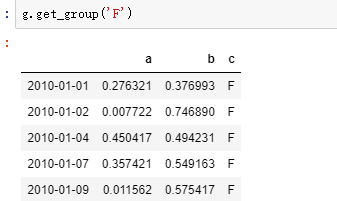
通过 for 循环 取 ,或者 g.get_group() 取分组后的结果。
2) groupby( by =)
by = mapping, function, label, or list of labels,可以接很多参数,最常见的就是dataframe的columns,一个 或多个列表都可以。
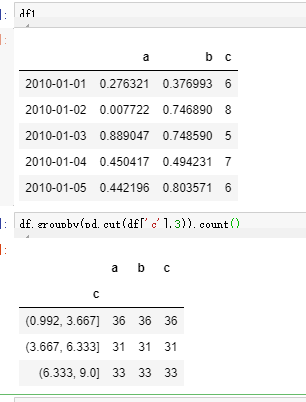
函数也是可以的,只不是是函数的返回值的value值 作为分组的依据,可以是个范围(之前我们看到的都是确定值,比如男,女,省份等)。最好的例子就是 df.groupby(pd.cut(df,[])).count()
(即groupby可以按照具体的值分类,也可以按照范围分类,具体的值不必多说,说道范围,就想到了pd.cut )
g.agg() 聚合运算,参数比较灵活,可以接列表,字典,懂含义就行。 优点,速度快,缺点,局限性大,只能聚合。聚合接收的参数是每一个列,即series。
g.apply( func ,* args ) 。 优点,自定义,灵活,缺点,速度慢。接收的参数是dateframe。 这个方法应用的场景很广。
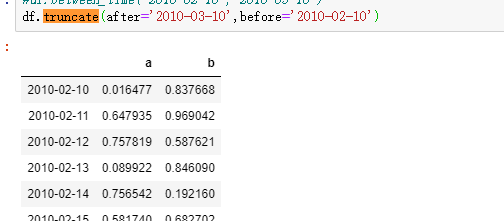
时间序列索引
ts = pd.date_range( )
这里介绍的是由时间序列作为索引而引申出的两个方法,一个是truncate,一个是between_time,这两个方法的调用者 都是 series或者dataframe,而不是 timeindex。