


基于GPU的cuda和opencl学习
线程、进程、内核
线程通常被定义为一个进程中代码的不同执行路线,一个进程可包含多个线程。从实现方式上划分,线程有两种类型:"用户级线程"和"内核级线程
Guda的逻辑结构和内存结构
host(在cpu上执行)
device(在gpu上执行的部分,又称为kernel)
cuda的执行过程:
1、 host程序将需要并行计算的数据复制到gpu显存
2、gpu执行device程序,
3、完成后,由host程序将结果从gpu显存中取回
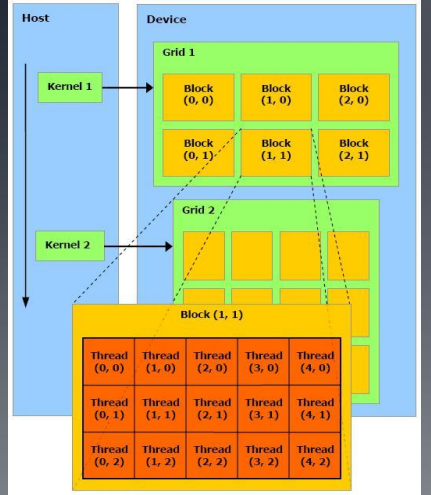
grid中的block数量由系统中处理器个数或待处理的数据量决定,block有built-in变量blockDim(block dimension)和blockIdx(block index)。


网格的划分(block个数,线程数/block),根据实际中的任务来划分:总启动的线程=总共的任务。
例如:((n+255)/256,256)
二、opencl
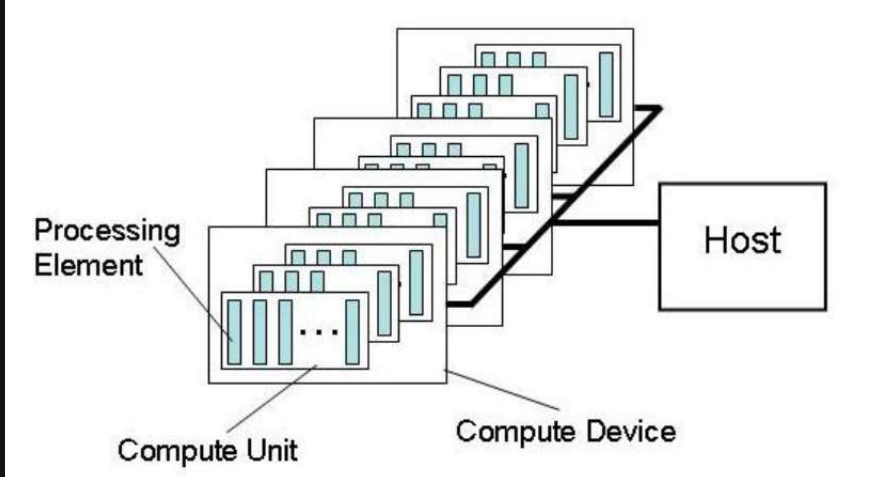
硬件结构
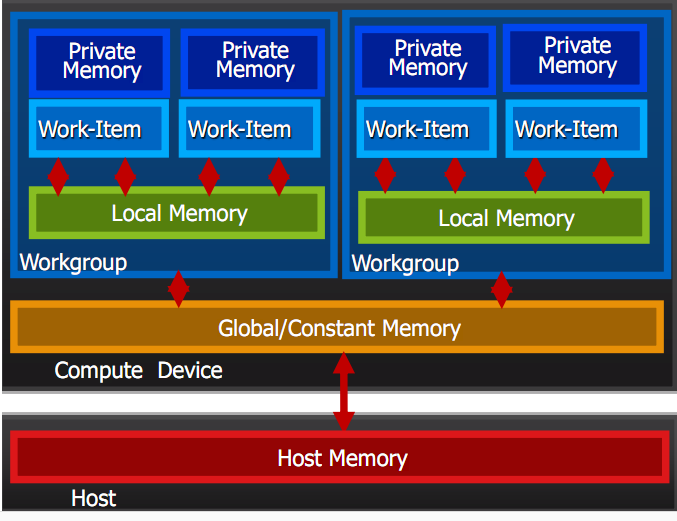
2内存架构
网格(全局线程个数,线程/group)注意:线程/group由硬件决定,英美达为32倍数,AMD为64的倍数
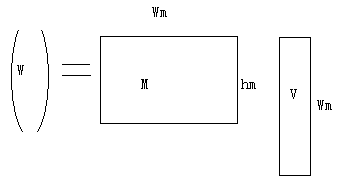
eg:矩阵与矢量相乘
串行
for(i=0;i<hm;i++)
{dot=0;
for(j=0;j<Wm;j++)
dot+=M [ i * Wm + j ] * V[j];
W[ i ]=dot;
}
a、完全可以按每个线程分配一个任务完成。
例如2565个,256个线程/group;需要11个workgroup,网格(256*11,256)
参数获得:
核编号的获得-----idx=get_global_id(0)
全局线程个数-----get_global_size(0)

每个核对应每一行,get_global_id(0)获得的核编号,对应矩阵的每行编号。( 其中M为矩阵指针首地址。)
b、不能按每个线程分配一个任务一次完成。
例如2565个,256个线程/group; 网格(640,256)需要每次执行四个线程,
c、按照workgroup划分
网格(设置的全局线程,线程/group,workgroup)=(640,64,10)(2565)

