
Pandas中常用的函数使用
1、离散值的onehot编码
pd.get_dummies()
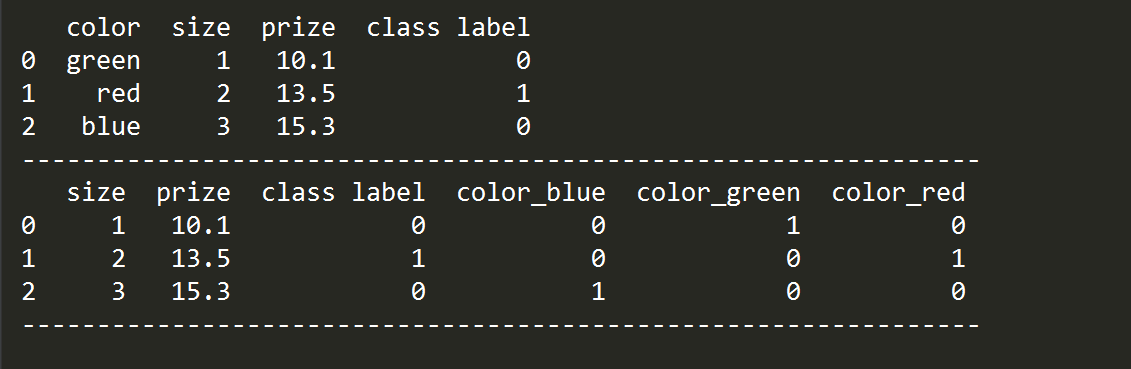
import pandas as pd #对于离散值不能进行编码的利用onehot编码 df = pd.DataFrame([ ['green', 'M', 10.1, 'class1'], ['red', 'L', 13.5, 'class2'], ['blue', 'XL', 15.3, 'class1']]) df.columns = ['color', 'size', 'prize', 'class label'] size_mapping = { 'XL': 3, 'L': 2, 'M': 1} df['size'] = df['size'].map(size_mapping) class_mapping = {label: idx for idx, label in enumerate(set(df['class label']))} df['class label'] = df['class label'].map(class_mapping) print('----------------------------------------------------------------') print(df) print('----------------------------------------------------------------') df = pd.get_dummies(df) print(df) print('----------------------------------------------------------------')
2、DROP——删除pandas DataFrame的某一/几列
1. DF= DF.drop('column_name', 1);
2. DF.drop('column_name',axis=1, inplace=True)
3. DF.drop([DF.columns[[0,1, 3]]], axis=1,inplace=True) # Note: zero indexed
凡是会对原数组作出修改并返回一个新数组的,往往都有一个 inplace可选参数。如果手动设定为True(默认为False),那么原数组直接就被替换。也就是说,采用inplace=True之后,原数组名(如2和3情况所示)对应的内存值直接改变;而采用inplace=False之后,原数组名对应的内存值并不改变,需要将新的结果赋给一个新的数组或者覆盖原数组的内存位置。

