Oracle--索引
索引:
提高查询效率, 增删改: 效率降低
表的数据量很大, 才会有查询效率优化
通俗的来讲,索引在表中的作用,相当于书的目录对书的作用。
索引的特点
1.与表独立存放,但不能独立存在,必须属于某个表 , 数据库开辟空间存储索引
2.由数据库自动维护,表被删除时,该表上的索引自动被删除, 删除表的数据的时候, 表对于的索引进行对于删除
数据库的索引策略:
1、表的主键列, 唯一约束列, 数据库会自动的添加唯一索引
2、查询中,经常使用某一列作为条件查询, 用户可以给这一列手动添加索引
索引分类:
按照索引列的个数,分为单列索引、复合索引;
按照索引列值的唯一性,分为唯一索引、非唯一索引。
此外还有函数索引、全局索引、分区索引等。
Oracle数据库提供以下类型的索引:
B-tree索引(Oracle默认建立B-tree索引) ***
B-tree聚集索引(B-tree cluster indexes)
Hash聚集索引(Hash cluster indexes)
反向索引(Reverse key indexes)
位图索引(Bitmap indexes) ***
位图连接索引(Bitmap join indexes)
创建索引的语法:
CREATE [UNIQUE] INDEX 索引名 ON 表名(列的列表) [TABLESPACE 表空间名]; unique: 表示索引是唯一索引, 索引值唯一的, 不推荐用户添加唯一索引, **表的主键列, 唯一约束列, 数据库会自动的添加唯一索引** ,没有unique关键字, 这个索引是一个不唯一索引
例:
-- 创建一个表 create table dex ( id number, sex char(2), name varchar2(10) ); -- 插入数据 (1千万条数据) Begin for i in 1..10000000 loop insert into dex values(i,'M','chongshi'); end loop; commit; end;
测试:
-- 没有使用索引 用时: 3.273秒 select * from dex where id = 8888888; --使用索引: 给id 添加一个索引 --使用B树索引 create index idx_dexId on dex(id); --用时: 0.144秒 -- Table access (By index ) 根据索引扫描 -- Index (Range Scann) 这一行中Object_name: 使用的索引的名字 select * from dex where id = 8888888; --加索引的列使用函数, B-tree索引失效, 使用函数索引, to_number(id) 作为索引值 --Table Access (Full) 表示全表扫描 select * from dex where to_number(id) = 8888888;
B-树索引
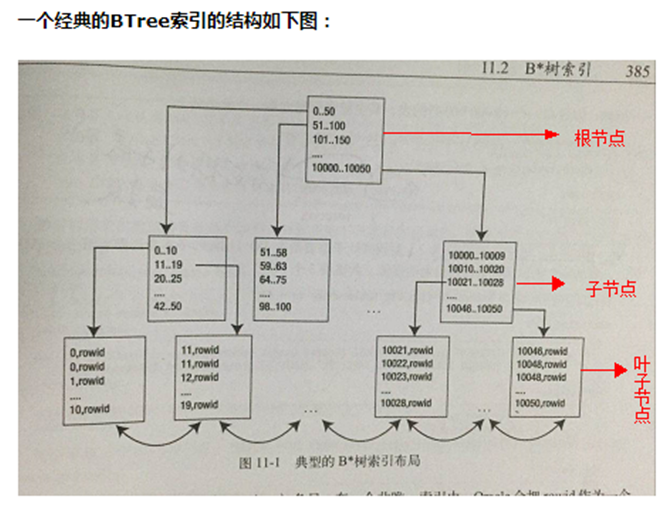
索引页的数据结构是使用B树的结构
分3层: 根节点, 分支节点, 叶子节点
查找: 当查询某一数据时先读根节点,再读分支节点,最后找到叶子节点
Root为B-Tree的根节点,branch为分支节点,leaf到最下面一层称为叶子节点,每个节点表示一层,当查询某一数据时先读根节点,再读支节点,最后找到叶子节点,叶子节点会存放index entry(索引入口),每个索引入口对应一条记录.
Index entry的组成部分: Indexentry entry header 存放一些控制信息。 Key column length 某一key的长度 Key column value 某一个key 的值 ROWID 指针,具体指向于某一个数据
B树索引的重建
B树索引经过大量的插入删除操作以后一个是容易使树不平衡,再一个是删除后空间不回收,形成了索引碎片, --所以定期重建索引(删除再创建)非常有必要. --所有的索引的维护: --第一种: rebuild -- alter index 索引名 rebuild ; 对索引进行重建 alter index idx_dexId rebuild; --第二种方式: 先删,再建 drop index idx_dexId; create index idx_dexId on dex(id);
B-Tree索引适用的场景:
- 适合高基数的列(唯一值多,重复值小)
- 适合大量的增删改
- 不能用包含OR操作符的查询
B-Tree索引不适合的场景:
- 只有几个不同的值供选择。例如,一个“类型”列中,只有四个不同的值(A,B,C,和D)。该索引是一个低效的选择。如果你有一个Oracle数据库,那么为这些选择范围小的的列建立位图索引是更好的选择。
- 当在where 条件中使用了除了MIN和MAX以外的函数。
rowid: 行地址
一旦这条数据插入到表中, Oracle分配一个行地址, 行地址一般情况不会改变 select e.*,rowid from emp e;
B树索引: 注意: 要求这一列的数据 高基数(重复值小), 默认的索引
查看sql的执行计划:
(查看这条sql 使用那些索引, 优化SQL语句之前, 使用执行计划, 查看SQL 执行情况)
1、可执行完具有索引的sql语句后,在执行工具上的‘解释计划’
2、通过语句 --1) explain plan for + SQL explain plan for select * from dex where id = 8888888; --2) select * from table(dbms_xplan.display); select * from table(dbms_xplan.display); ...等其他方式
位图索引
要求这一列的值大量重复, 例如: 性别, 岗位
创建位图索引:
create bitmap index 索引名 on 表名(列); create bitmap index bm_sex on dex(sex);
位图索引主要针对大量相同值的列而创建。拿全国居民登录表来说,假设有四个字段:姓名、性别、年龄、和身份证号,年龄和性别两个字段会产生许多相同的值,性别只有男女两种值,年龄,1到120(假设最大年龄120岁)个值。那么不管一张表有几亿条记录,但根据性别字段来区分的话,只有两种取值(男、女)。那么位图索引就是根据字段的这个特性所建立的一种索引。
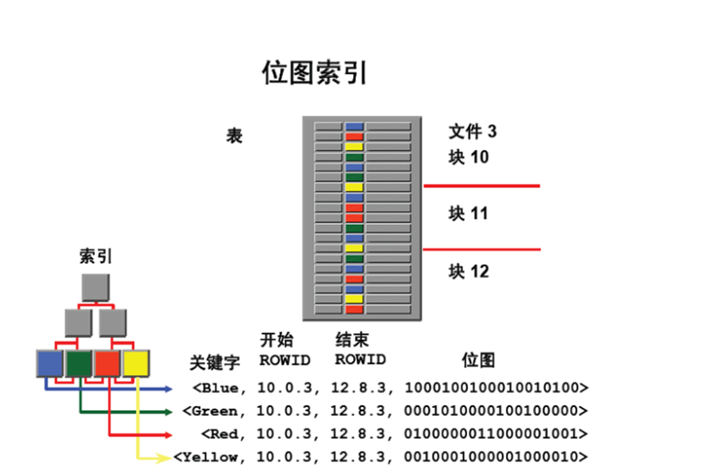
从上图,我们可以看出,一个叶子节点(用不同颜色标识)代表一个key , start rowid 和 end rowid规定这种类型的检索范围,一个叶子节点标记一个唯一的bitmap值。因为一个数值类型对应一个节点,当时行查询时,位图索引通过不同位图取值直接的位运算(与或),来获取到结果集合向量(计算出的结果)。

位图索引的特点:
- Bitmap索引的存储空间节省
- Bitmap索引创建的速度快
- Bitmap索引允许键值为空
- Bitmap索引对表记录的高效访问
总结:
- 如果用户查询的列的基数非常的小, 即只有的几个固定值,如性别、婚姻状况、行政区等等。要为这些基数值比较小的列建索引,就需要建立位图索引。
- 位图索引适合静态数据,而不适合索引频繁更新的列。这个原因是因为在更新该列时,需要同时更新系统中的该列该值对应位图向量,此时,系统会将所有该列为该值的行锁定。
- 位图索引创建时,不需要进行排序,因此速度较快;而B-tree索引创建时,需要排序等操作,因此慢很多。
- 当使用count(XX),可以直接访问索引就快速得出统计数据.
- 当根据位图索引的列进行and,or或 in(x,y,..)查询时,直接用索引的位图进行或运算,在访问数据之前可事先过滤数据.
- 位图索引允许键值为NULL,因此进行NULL条件查询时,可以使用索引。而B-tree索引不记录NULL,当使用NULL条件的查询时,会使用全表扫描
索引的维护
- 建立索引后,查询的时候需要在where条件中带索引的字段才会使用索引
- 在进程查询的字段上建立索引,不要在所有的字段建立索引
- 因为索引是用来加快查询速度的,如果一张表经常在insert.update,delete而很少select,不建议建立索引,因为Oracle需要对索引进行额外的维护
- 索引是由Oracle自动维护的,索引使用久了会产生索引碎片(磁盘碎片),影响查询速度,所以使用久了需要手动进行维护(删除再重建).

 浙公网安备 33010602011771号
浙公网安备 33010602011771号