实验4
void input(int x[], int n); void output(int x[], int n); double average(int x[], int n); void bubble_sort(int x[], int n); int main() { int scores[N]; double ave; printf("录入%d个分数:\n", N); input(scores, N); printf("\n输出课程分数: \n"); output(scores, N); printf("\n课程分数处理: 计算均分、排序...\n"); ave = average(scores, N); bubble_sort(scores, N); printf("\n输出课程均分: %.2f\n", ave); printf("\n输出课程分数(高->低):\n"); output(scores, N); return 0; } // 函数定义 // 输入n个整数保存到整型数组x中 void input(int x[], int n) { int i; for(i = 0; i < n; ++i) scanf("%d", &x[i]); } // 输出整型数组x中n个元素 void output(int x[], int n) { int i; for(i = 0; i < n; ++i) printf("%d ", x[i]); printf("\n"); }
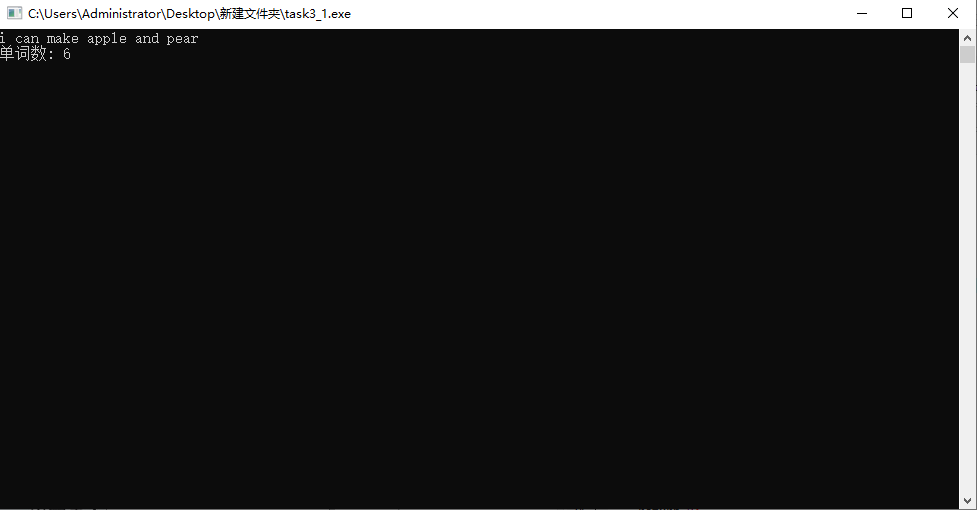
#include <stdio.h> #define N 80 int count(char x[]); int main() { char words[N+1]; int n; while(gets(words) != NULL) { n = count(words); printf("单词数: %d\n\n", n); } return 0; } int count(char x[]) { int i; int word_flag = 0; // 用作单词标志,一个新单词开始,值为1;单词结束,值为0 int number = 0; // 统计单词个数 for(i = 0; x[i] != '\0'; i++) { if(x[i] == ' ') word_flag = 0; else if(word_flag == 0) { word_flag = 1; number++; } } return number; }
#include <stdio.h> #define N 4 int main() { int a[N] = {2, 0, 2, 3}; char b[N] = {'2', '0', '2', '3'}; int i; printf("sizeof(int) = %d\n", sizeof(int)); printf("sizeof(char) = %d\n", sizeof(char)); printf("\n"); // 输出int型数组a中每个元素的地址、值 for (i = 0; i < N; ++i) printf("%p: %d\n", &a[i], a[i]); printf("\n"); // 输出char型数组b中每个元素的地址、值 for (i = 0; i < N; ++i) printf("%p: %c\n", &b[i], b[i]); printf("\n"); // 输出数组名a和b对应的值 printf("a = %p\n", a); printf("b = %p\n", b); return 0; }

int型数组在内存中是连续存放的每个占用四个字节
char型数组在内存是连续存放的每个占用一个字节
是一样的
#include <stdio.h> #define N 2 #define M 3 int main() { int a[N][M] = {{1, 2, 3}, {4, 5, 6}}; char b[N][M] = {{'1', '2', '3'}, {'4', '5', '6'}}; int i, j; // 输出int型二维数组a中每个元素的地址、值 for (i = 0; i < N; ++i) for (j = 0; j < M; ++j) printf("%p: %d\n", &a[i][j], a[i][j]); printf("\n"); // 输出int型二维数组名a, 以及,a[0], a[1]的值 printf("a = %p\n", a); printf("a[0] = %p\n", a[0]); printf("a[1] = %p\n", a[1]); printf("\n"); // 输出char型二维数组b中每个元素的地址、值 for (i = 0; i < N; ++i) for (j = 0; j < M; ++j) printf("%p: %c\n", &b[i][j], b[i][j]); printf("\n"); // 输出char型二维数组名b, 以及,b[0], b[1]的值 printf("b = %p\n", b); printf("b[0] = %p\n", b[0]); printf("b[1] = %p\n", b[1]); printf("\n"); return 0; }

是按行连续存放的,每个元素占用四个字节
是一样的
是按行连续存放的,每个占用一个字节
是一样的
a[0]是表示第一行元素的值a[1]是表示第二行元素的值
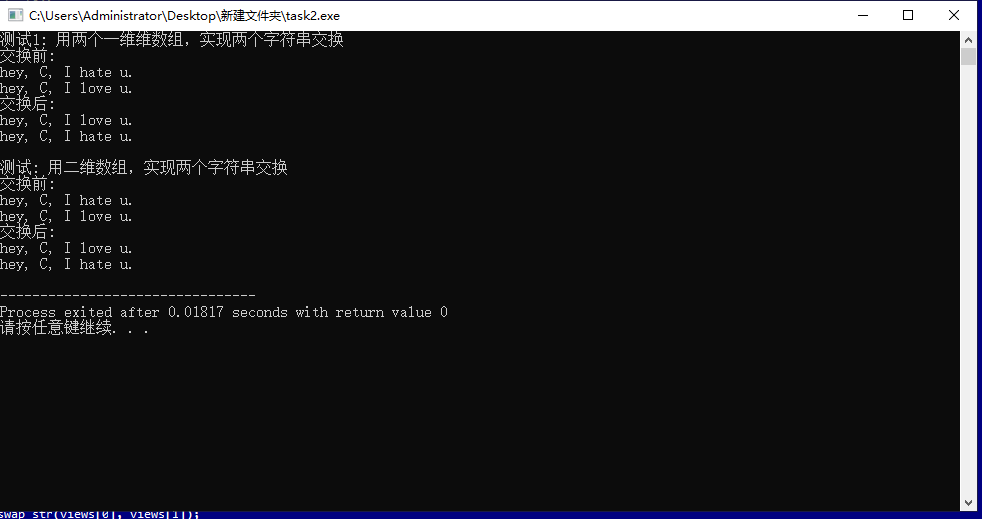
#include <stdio.h> #include <string.h> #define N 80 void swap_str(char s1[N], char s2[N]); void test1(); void test2(); int main() { printf("测试1: 用两个一维维数组,实现两个字符串交换\n"); test1(); printf("\n测试: 用二维数组,实现两个字符串交换\n"); test2(); return 0; } void test1() { char views1[N] = "hey, C, I hate u."; char views2[N] = "hey, C, I love u."; printf("交换前: \n"); puts(views1); puts(views2); swap_str(views1, views2); printf("交换后: \n"); puts(views1); puts(views2); } void test2() { char views[2][N] = {"hey, C, I hate u.", "hey, C, I love u."}; printf("交换前: \n"); puts(views[0]); puts(views[1]); swap_str(views[0], views[1]); printf("交换后: \n"); puts(views[0]); puts(views[1]); } void swap_str(char s1[N], char s2[N]) { char tmp[N]; strcpy(tmp, s1); strcpy(s1, s2); strcpy(s2, tmp); }
#include <stdio.h> #define N 80 int count(char x[]); int main() { char words[N+1]; int n; while(gets(words) != NULL) { n = count(words); printf("单词数: %d\n\n", n); } return 0; } int count(char x[]) { int i; int word_flag = 0; // 用作单词标志,一个新单词开始,值为1;单词结束,值为0 int number = 0; // 统计单词个数 for(i = 0; x[i] != '\0'; i++) { if(x[i] == ' ') word_flag = 0; else if(word_flag == 0) { word_flag = 1; number++; } } return number; }
#include <stdio.h> #define N 1000 int main() { char line[N]; int word_len; // 记录当前单词长度 int max_len; // 记录最长单词长度 int end; // 记录最长单词结束位置 int i; while(gets(line) != NULL) { word_len = 0; max_len = 0; end = 0; i = 0; while(1) { // 跳过连续空格 while(line[i] == ' ') { word_len = 0; // 单词长度置0,为新单词统计做准备 i++; } // 在一个单词中,统计当前单词长度 while(line[i] != '\0' && line[i] != ' ') { word_len++; i++; } // 更新更长单词长度,并,记录最长单词结束位置 if(max_len < word_len) { max_len = word_len; end = i; // end保存的是单词结束的下一个坐标位置 } // 遍历到文本结束时,终止循环 if(line[i] == '\0') break; } // 输出最长单词 printf("最长单词: "); for(i = end - max_len; i < end; ++i) printf("%c", line[i]); printf("\n\n"); } return 0; }
#include <stdio.h> #define N 1000 int main() { char line[N]; int word_len; // 记录当前单词长度 int max_len; // 记录最长单词长度 int end; // 记录最长单词结束位置 int i; while(gets(line) != NULL) { word_len = 0; max_len = 0; end = 0; i = 0; while(1) { // 跳过连续空格 while(line[i] == ' ') { word_len = 0; // 单词长度置0,为新单词统计做准备 i++; } // 在一个单词中,统计当前单词长度 while(line[i] != '\0' && line[i] != ' ') { word_len++; i++; } // 更新更长单词长度,并,记录最长单词结束位置 if(max_len < word_len) { max_len = word_len; end = i; // end保存的是单词结束的下一个坐标位置 } // 遍历到文本结束时,终止循环 if(line[i] == '\0') break; } // 输出最长单词 printf("最长单词: "); for(i = end - max_len; i < end; ++i) printf("%c", line[i]); printf("\n\n"); } return 0; }


 浙公网安备 33010602011771号
浙公网安备 33010602011771号