【Python高级应用课程设计 】数据分析--天猫美妆的销售数据分析
选题背景:
美妆销售数据反映了消费者的购买行为和偏好,通过分析这些数据,品牌可以更准确地把握市场需求和趋势,从而制定更符合市场需求的策略和产品。通过对历史销售数据的分析,企业可以预测未来的销售趋势,提前调整库存、生产和销售策略,以应对市场的变化。通过对不同产品的销售数据的分析,企业可以了解哪些产品更受欢迎,从而优化产品结构,提高整体销售业绩。销售数据还可以反映各个销售渠道的效率,企业可以根据数据分析结果优化渠道布局,提高销售效率。通过与竞争对手的销售数据的对比,企业可以更好地了解自身在市场中的定位以及与竞争对手的优劣势,从而制定更具针对性的竞争策略。销售数据可以帮助企业更准确地划分不同的客户群体,针对不同群体制定个性化的营销策略,提高客户满意度和忠诚度。
大数据设计分析方案
数据为天猫双十一女性美妆的数据集,围绕产品及其销量和评论撰写。数据具有7个特征,可以从多个维度解析文本。
数据包括27599行和7个特征变量。每一行对应一个产品的销售情况,包括以下变量:
update_time 统计时间
id 产品编号
title 产品名称
price 交易价格
sale_count 销量
comment_count 评论数量
店名 店铺名称
可参考的探索方向:
购买化妆品的客户的关注度(评论数)是多少?各产品销量分布情况? 哪些产品的卖得最好,哪些牌子最受欢迎,哪些化妆品是大家最需要的? 不同商家之间的差异,及促销打折力度? 模拟定价系统及推荐系统?
数据源
这是选自kesci中的数据集,链接:https://www.kesci.com/home/dataset/5ce889bed10470002b3394c2。
其中包含了2016年美妆系列化妆品等的销售信息。
读取数据
点击查看代码
import pandas as pd
import numpy as np
data = pd.read_csv('双十一淘宝美妆数据.csv')
data.head()

# 查看各字段信息
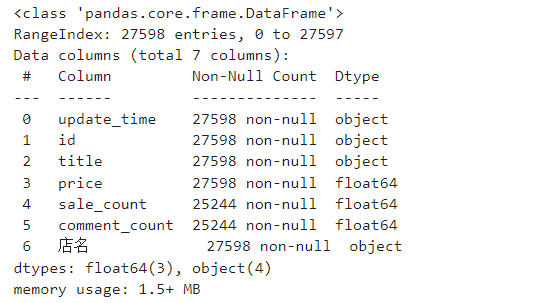
data.info()
# 分店铺统计
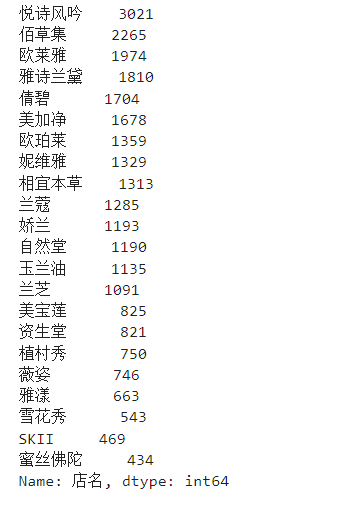
data['店名'].value_counts()
数据清洗
重复数据处理
# 对重复数据做删除处理
print(data.shape)
data = data.drop_duplicates(inplace=False)
print(data.shape)
(27598, 7)
(27512, 7)
print(data.index)
data = data.reset_index(drop=True)
print('新索引:',data.index)

缺失值处理
# 查看缺失值
data.isnull().any()

# 查看数据结构
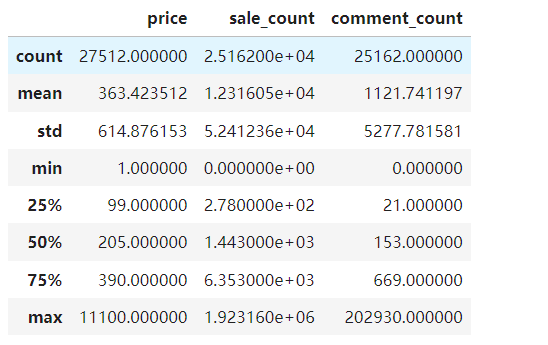
data.describe()
# 给商品添加分类
basic_config_data = """护肤品 套装 套装
护肤品 乳液类 乳液 美白乳 润肤乳 凝乳 柔肤液' 亮肤乳 菁华乳 修护乳
护肤品 眼部护理 眼霜 眼部精华 眼膜
护肤品 面膜类 面膜
护肤品 清洁类 洗面 洁面 清洁 卸妆 洁颜 洗颜 去角质 磨砂
护肤品 化妆水 化妆水 爽肤水 柔肤水 补水露 凝露 柔肤液 精粹水 亮肤水 润肤水 保湿水 菁华水 保湿喷雾 舒缓喷雾
护肤品 面霜类 面霜 日霜 晚霜 柔肤霜 滋润霜 保湿霜 凝霜 日间霜 晚间霜 乳霜 修护霜 亮肤霜 底霜 菁华霜
护肤品 精华类 精华液 精华水 精华露 精华素
护肤品 防晒类 防晒霜 防晒喷雾
化妆品 口红类 唇釉 口红 唇彩
化妆品 底妆类 散粉 蜜粉 粉底液 定妆粉 气垫 粉饼 BB CC 遮瑕 粉霜 粉底膏 粉底霜
化妆品 眼部彩妆 眉粉 染眉膏 眼线 眼影 睫毛膏
化妆品 修容类 鼻影 修容粉 高光 腮红
其他 其他 其他"""
# 将字符串basic_config_data 转为字典 category_config_map
category_config_map = {}
for config_line in basic_config_data.split('\n'):
basic_cateogry_list = config_line.strip().strip('\n').strip(' ').split(' ')
main_category = basic_cateogry_list[0]
sub_category = basic_cateogry_list[1]
unit_category_list = basic_cateogry_list[2:-1]
for unit_category in unit_category_list:
if unit_category and unit_category.strip().strip(' '):
category_config_map[unit_category] = (main_category,sub_category)
category_config_map
{'乳液': ('护肤品', '乳液类'),
'美白乳': ('护肤品', '乳液类'),
'润肤乳': ('护肤品', '乳液类'),
'凝乳': ('护肤品', '乳液类'),
"柔肤液'": ('护肤品', '乳液类'),
'亮肤乳': ('护肤品', '乳液类'),
'菁华乳': ('护肤品', '乳液类'),
'眼霜': ('护肤品', '眼部护理'),
'眼部精华': ('护肤品', '眼部护理'),
'洗面': ('护肤品', '清洁类'),
'洁面': ('护肤品', '清洁类'),
'清洁': ('护肤品', '清洁类'),
'卸妆': ('护肤品', '清洁类'),
'洁颜': ('护肤品', '清洁类'),
'洗颜': ('护肤品', '清洁类'),
'去角质': ('护肤品', '清洁类'),
'化妆水': ('护肤品', '化妆水'),
'爽肤水': ('护肤品', '化妆水'),
'柔肤水': ('护肤品', '化妆水'),
'补水露': ('护肤品', '化妆水'),
'凝露': ('护肤品', '化妆水'),
'柔肤液': ('护肤品', '化妆水'),
'精粹水': ('护肤品', '化妆水'),
'亮肤水': ('护肤品', '化妆水'),
'润肤水': ('护肤品', '化妆水'),
'保湿水': ('护肤品', '化妆水'),
'菁华水': ('护肤品', '化妆水'),
'保湿喷雾': ('护肤品', '化妆水'),
'面霜': ('护肤品', '面霜类'),
'日霜': ('护肤品', '面霜类'),
'晚霜': ('护肤品', '面霜类'),
'柔肤霜': ('护肤品', '面霜类'),
'滋润霜': ('护肤品', '面霜类'),
'保湿霜': ('护肤品', '面霜类'),
'凝霜': ('护肤品', '面霜类'),
'日间霜': ('护肤品', '面霜类'),
'晚间霜': ('护肤品', '面霜类'),
'乳霜': ('护肤品', '面霜类'),
'修护霜': ('护肤品', '面霜类'),
'亮肤霜': ('护肤品', '面霜类'),
'底霜': ('护肤品', '面霜类'),
'精华液': ('护肤品', '精华类'),
'精华水': ('护肤品', '精华类'),
'精华露': ('护肤品', '精华类'),
'防晒霜': ('护肤品', '防晒类'),
'唇釉': ('化妆品', '口红类'),
'口红': ('化妆品', '口红类'),
'散粉': ('化妆品', '底妆类'),
'蜜粉': ('化妆品', '底妆类'),
'粉底液': ('化妆品', '底妆类'),
'定妆粉': ('化妆品', '底妆类'),
' 气垫': ('化妆品', '底妆类'),
'粉饼': ('化妆品', '底妆类'),
'BB': ('化妆品', '底妆类'),
'CC': ('化妆品', '底妆类'),
'遮瑕': ('化妆品', '底妆类'),
'粉霜': ('化妆品', '底妆类'),
'粉底膏': ('化妆品', '底妆类'),
'眉粉': ('化妆品', '眼部彩妆'),
'染眉膏': ('化妆品', '眼部彩妆'),
'眼线': ('化妆品', '眼部彩妆'),
'眼影': ('化妆品', '眼部彩妆'),
'鼻影': ('化妆品', '修容类'),
'修容粉': ('化妆品', '修容类'),
'高光': ('化妆品', '修容类')}
def func1(row):
sub_type = '' #子类别
main_type = '' #主类别
exist = False
# 遍历item_name_cut 里每个词语
for temp in row:
# 如果词语包含在category_config_map里面,打上子类和主类标签
if temp in category_config_map:
sub_type = category_config_map.get(temp)[1]
main_type = category_config_map.get(temp)[0]
exist = True
break
if not exist:
sub_type= '其他'
main_type = '其他'
return [sub_type, main_type]
# 将子类别sub_type新增为一列
data['sub_type'] = data['item_name_cut'].map(lambda r:func1(r)[0])
# 将主类别main-type新增为一列
data['main_type'] = data['item_name_cut'].map(lambda r:func1(r)[1])
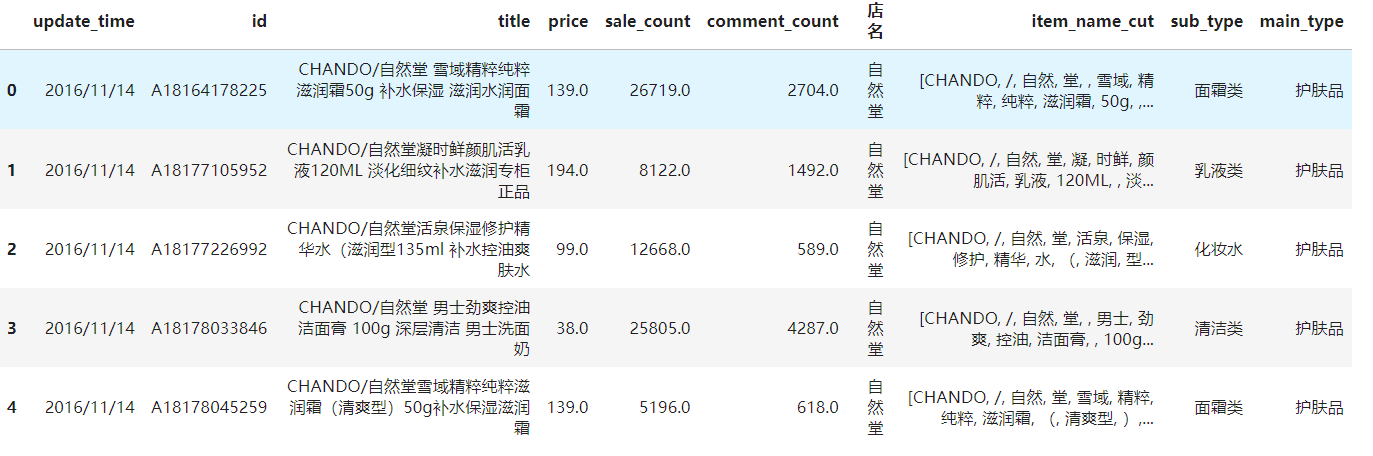
data.head()
# 将“是否男士专用”新增为一列
gender = []
for i in range(len(data)):
if '男' in data.item_name_cut[i]:
gender.append('是')
elif '男士' in data.item_name_cut[i]:
gender.append('是')
elif '男生' in data.item_name_cut[i]:
gender.append('是')
else:
gender.append('否')
# 将“是否男士专用”新增为一列
data['是否男士专用'] = gender
data.head()
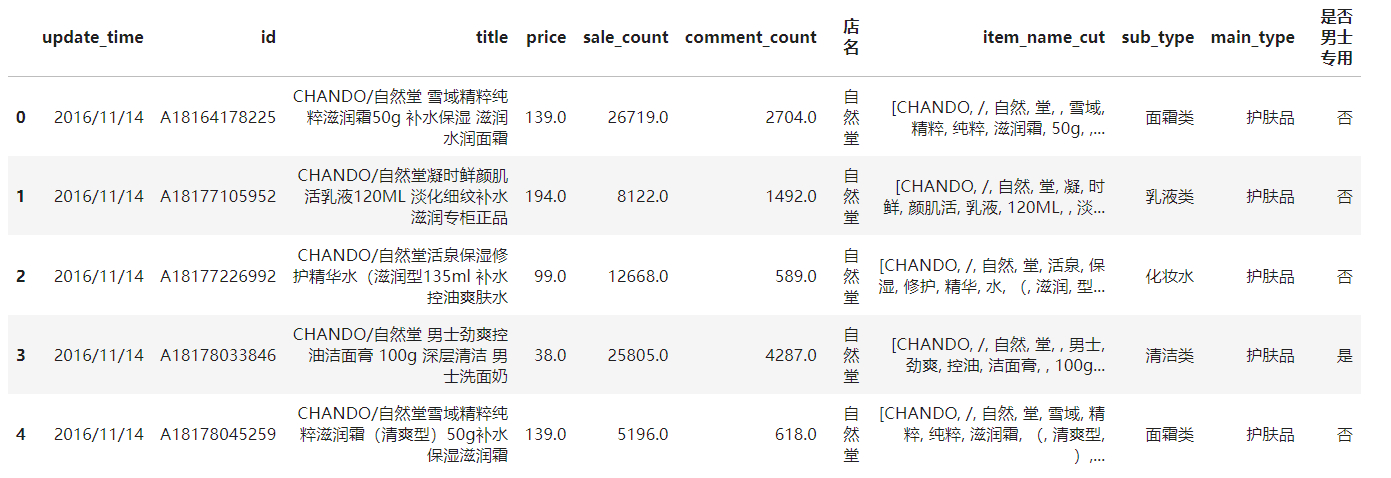
数据可视化
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
plt.figure(figsize=(12,7))
data['店名'].value_counts().sort_values(ascending=False).plot.bar(width=0.8,alpha=0.6,color='b')
plt.title('各品牌SKU数',fontsize=18)
plt.ylabel('商品数量',fontsize=14)
plt.show()
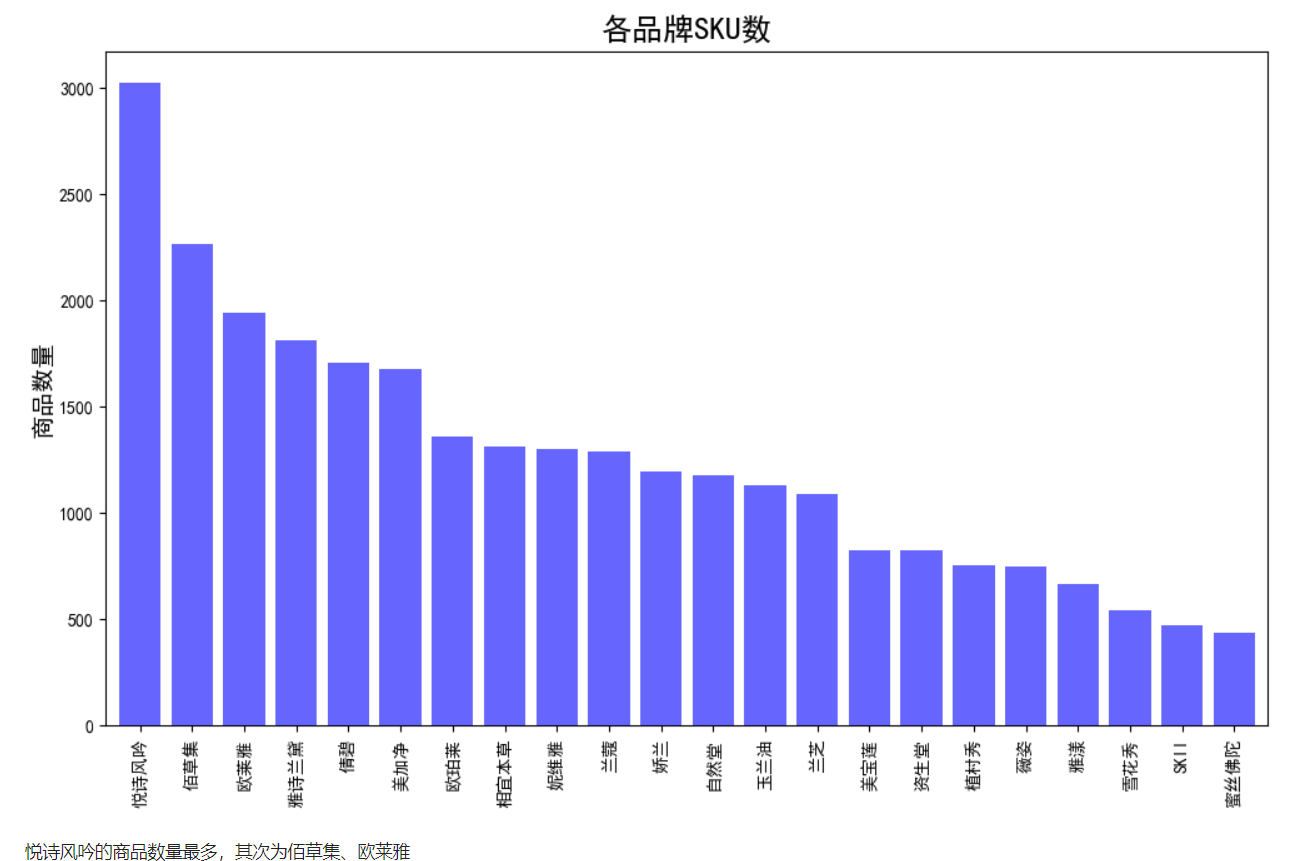
销售量和销售总额
fig,axes = plt.subplots(1,2,figsize=(12,10))
ax1 = data.groupby('店名').sale_count.sum().sort_values(ascending=True).plot(kind='barh',ax=axes[0],width=0.6)
ax1.set_title('品牌总销售量',fontsize=12)
ax1.set_xlabel('总销售量')
ax2 = data.groupby('店名')['销售额'].sum().sort_values(ascending=True).plot(kind='barh',ax=axes[1],width=0.6)
ax2.set_title('品牌总销售额',fontsize=12)
ax2.set_xlabel('总销售额')
plt.subplots_adjust(wspace=0.4)
plt.show()
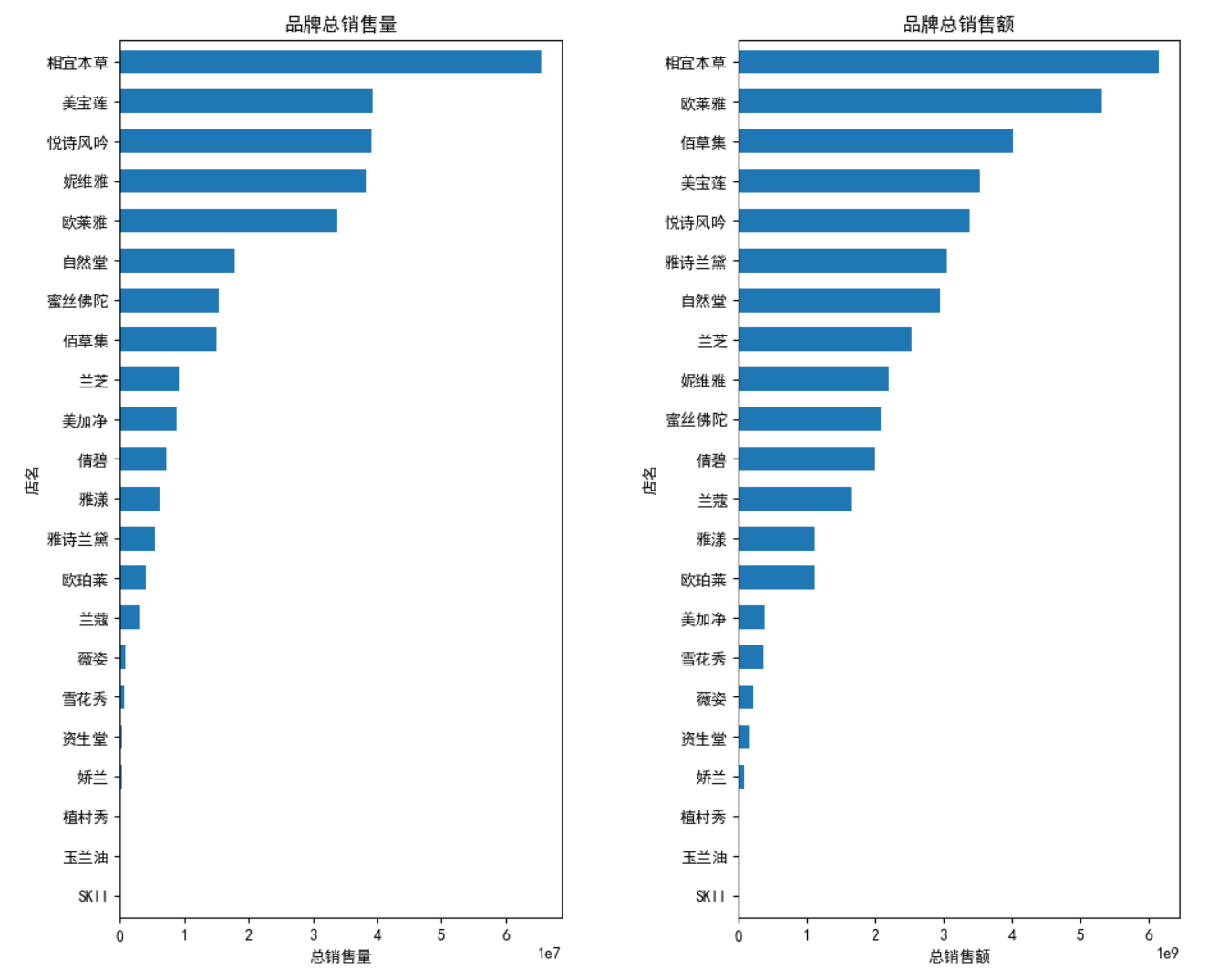
各类别的销售量、销售额情况
fig,axes = plt.subplots(1,2,figsize=(18,12))
data1 = data.groupby('main_type')['sale_count'].sum()
ax1 = data1.plot(kind='pie',ax=axes[0],autopct='%.1f%%',
pctdistance=0.8,
labels= data1.index,
labeldistance = 1.05,
startangle = 60,
radius = 1.2,
counterclock = False,
wedgeprops = {'linewidth': 1.2, },
textprops = {'fontsize':16, 'color':'k','rotation':80},
)
ax1.set_title('主类别销售量占比',fontsize=20)
data2 = data.groupby('sub_type')['sale_count'].sum()
ax2 = data2.plot(kind='pie',ax=axes[1],autopct='%.1f%%',
pctdistance=0.8,
labels= data2.index,
labeldistance = 1.05,
startangle = 230,
radius = 1.2,
counterclock = False,
wedgeprops = {'linewidth': 1.2, },
textprops = {'fontsize':16, 'color':'k','rotation':80},
)
ax2.set_title('子类别销售量占比',fontsize=20)
ax1.set_xlabel(..., fontsize=16,labelpad=38.5)
ax1.set_ylabel(..., fontsize=16,labelpad=38.5)
ax2.set_xlabel(..., fontsize=16,labelpad=38.5)
ax2.set_ylabel(..., fontsize=16,labelpad=38.5)
plt.subplots_adjust(wspace=0.4)
plt.show()
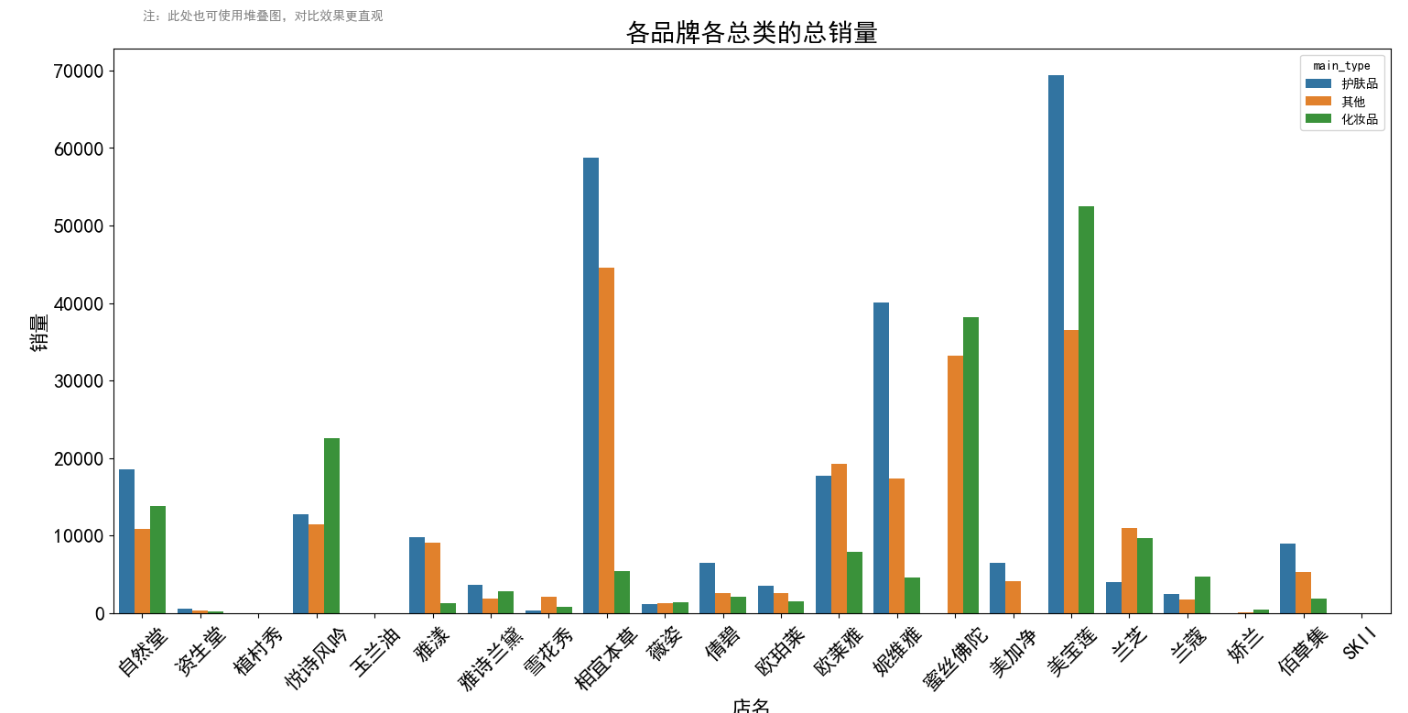
plt.figure(figsize=(18,8))
sns.barplot(x='店名',y='sale_count',hue='main_type',data=data,saturation=0.75,ci=0)
plt.title('各品牌各总类的总销量', fontsize=20)
plt.ylabel('销量',fontsize=16)
plt.xlabel('店名',fontsize=16)
plt.text(0,78000,
verticalalignment='top', horizontalalignment='left',color='gray', fontsize=10)
plt.xticks(fontsize=16,rotation=45)
plt.yticks(fontsize=16)
plt.show()
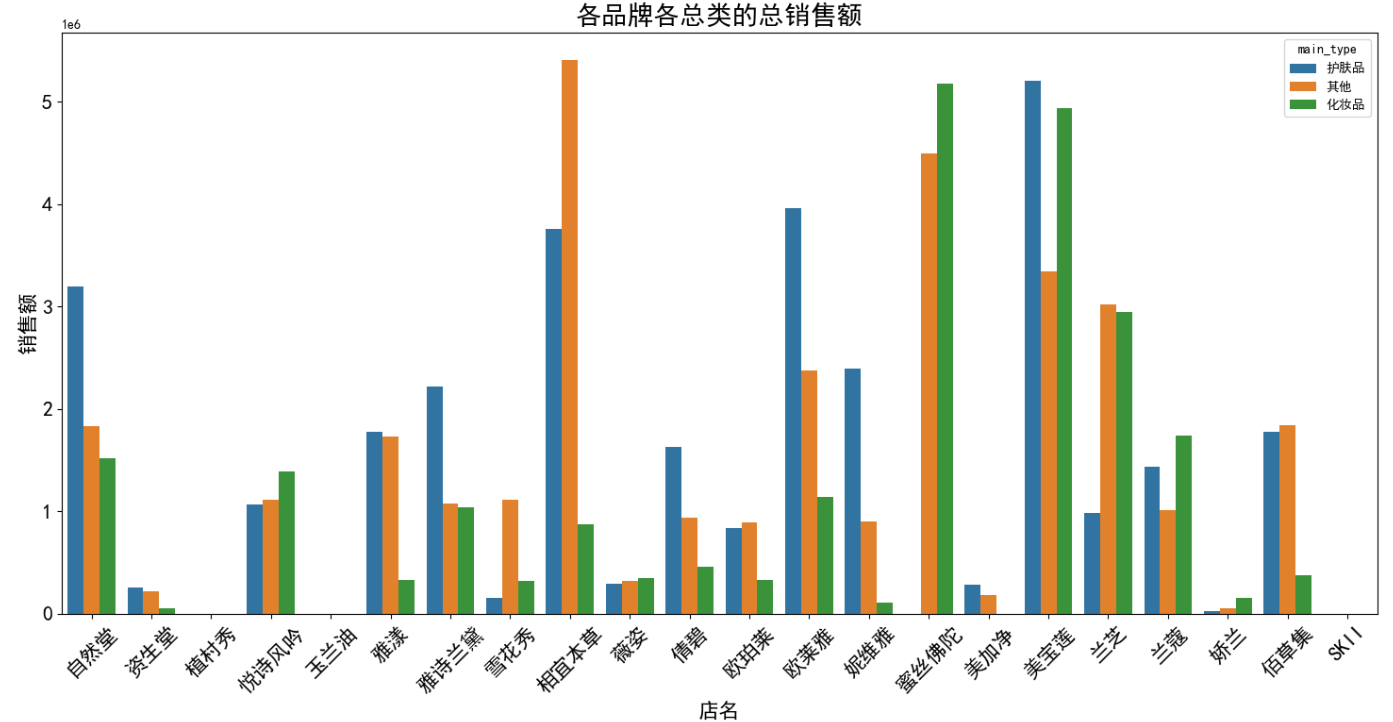
plt.figure(figsize=(18,8))
sns.barplot( x = '店名',
y = '销售额',hue = 'main_type',data =data,saturation = 0.75,ci=0,)
plt.ylabel('销售额',fontsize=16)
plt.xlabel('店名',fontsize=16)
plt.title('各品牌各总类的总销售额',fontsize=20)
plt.xticks(fontsize=16,rotation=45)
plt.yticks(fontsize=16)
plt.show()
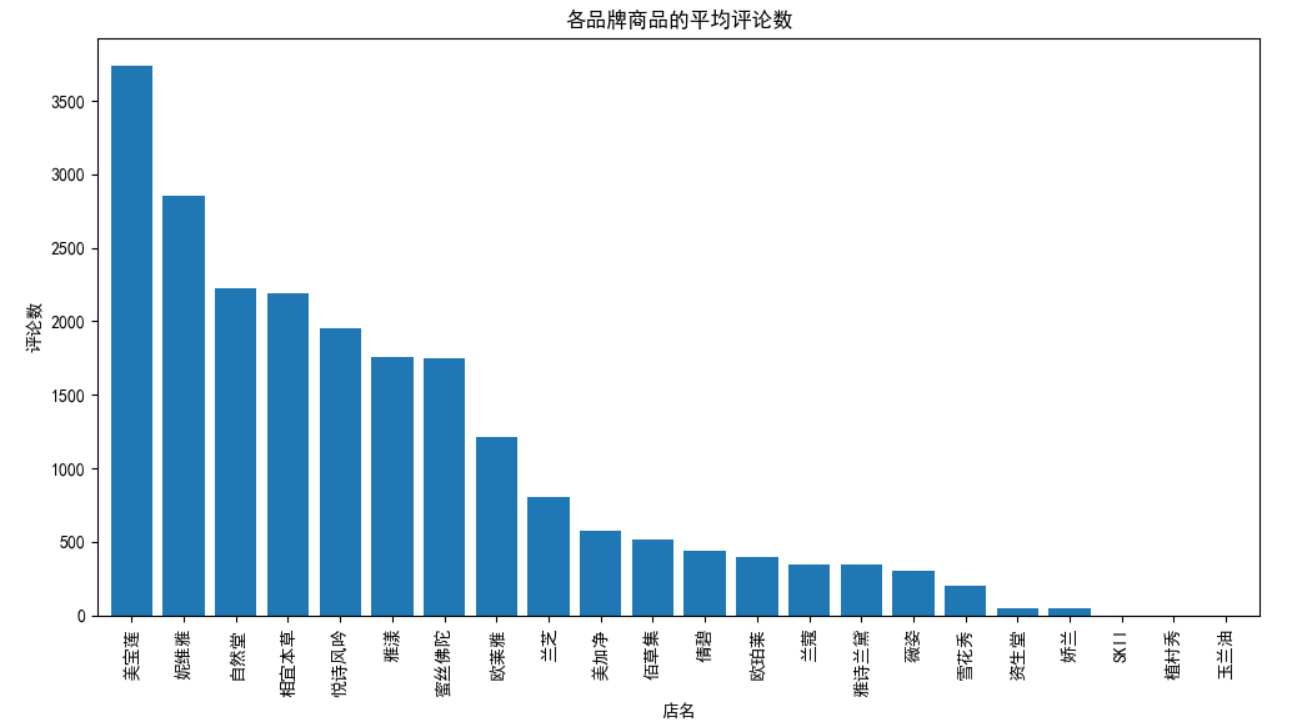
各品牌热度
plt.figure(figsize = (12,6))
data.groupby('店名').comment_count.mean().sort_values(ascending=False).plot(kind='bar',width=0.8)
plt.title('各品牌商品的平均评论数')
plt.ylabel('评论数')
plt.show()
plt.figure(figsize=(18,12))
x = data.groupby('店名')['sale_count'].mean()
y = data.groupby('店名')['comment_count'].mean()
s = data.groupby('店名')['price'].mean()
txt = data.groupby('店名').id.count().index
sns.scatterplot(x=x,y=y,size=s,hue=s,sizes=(100,1500),data=data)
for i in range(len(txt)):
plt.annotate(txt[i],xy=(x[i],y[i]))
plt.ylabel('热度')
plt.xlabel('销量')
plt.legend(loc='upper left')
plt.show()
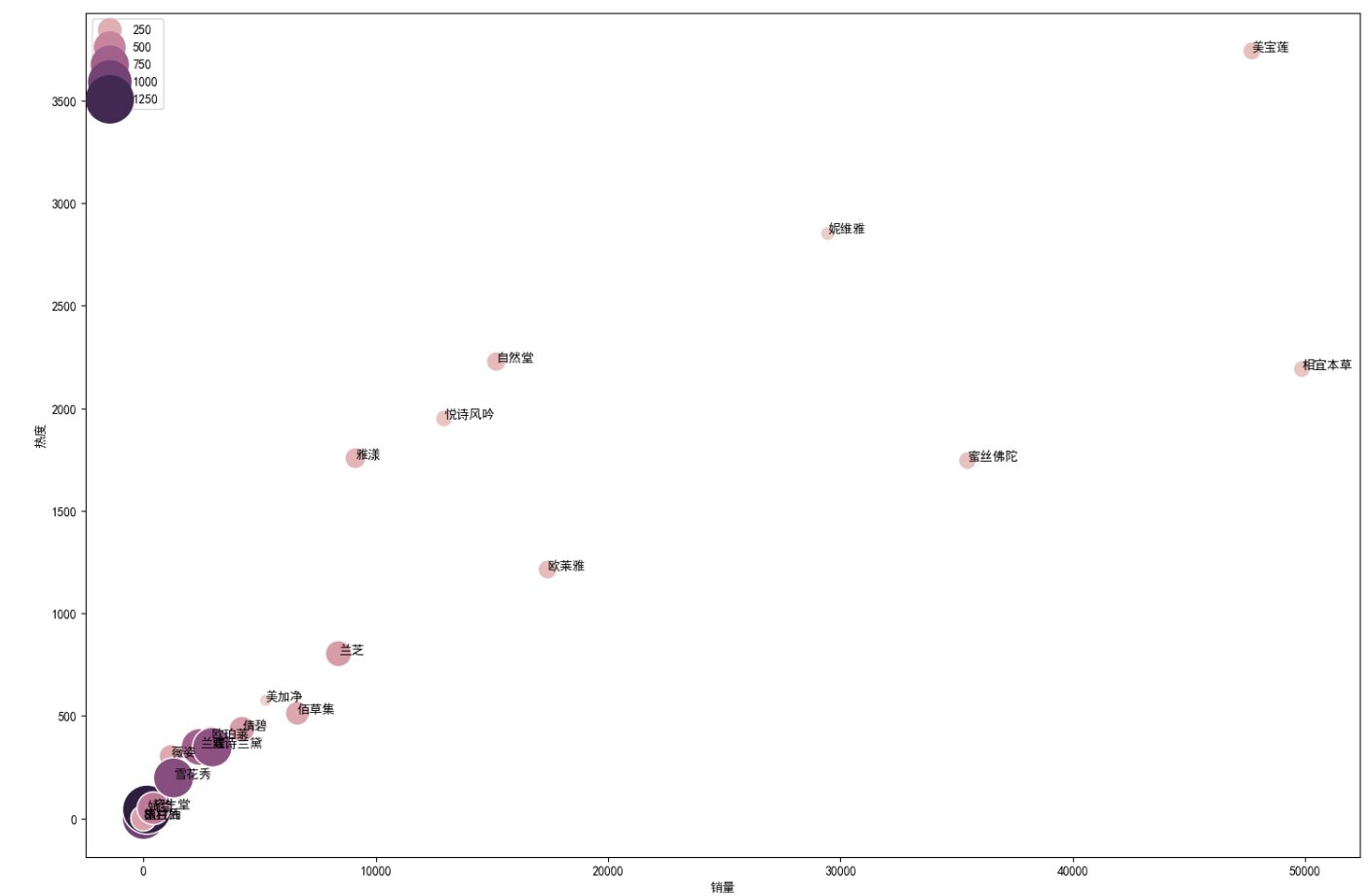
由上图所示:
越靠上的品牌热度越高,越靠右的品牌销量越高,颜色越深圈越大价格越高
热度与销量呈现一定的正相关; 美宝莲热度第一,销量第二,妮维雅热度第二,销量第四,两者价格均相对较低; 价格低的品牌热度和销量相对较高,价格高的品牌热度和销量相对较低,说明价格在热度和销量中有一定影响;
各品牌价格
plt.figure(figsize=(18,10))
sns.boxplot(x='店名',y='price',data=data)
plt.ylim(0,3000)#如果不限制,就不容易看清箱型,所以把Y轴刻度缩小为0-3000
plt.show()
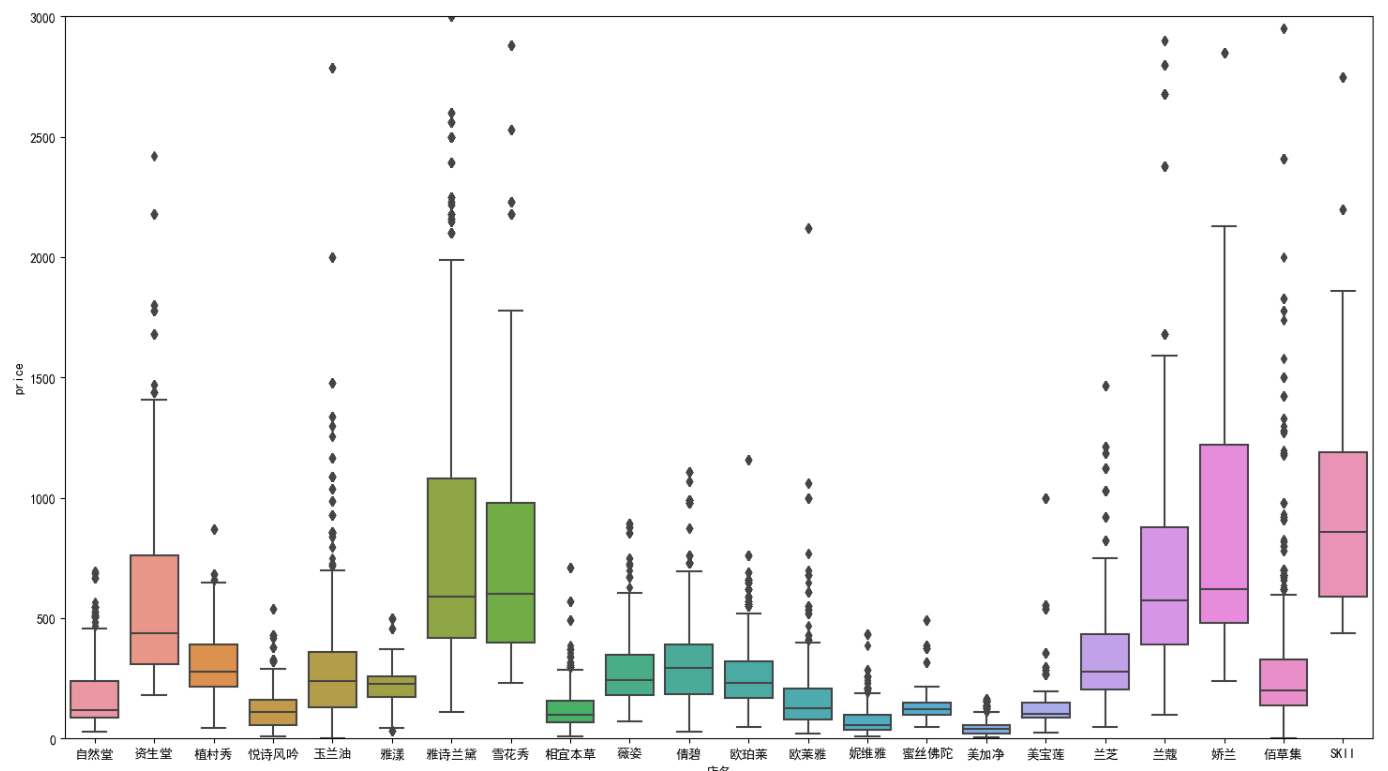
data.groupby('店名').price.sum()
avg_price=data.groupby('店名').price.sum()/data.groupby('店名').price.count()
avg_price
店名
SKII 1011.727079
佰草集 289.823171
倩碧 346.092190
兰芝 356.615809
兰蔻 756.400778
妮维雅 73.789053
娇兰 1361.043588
悦诗风吟 121.245945
植村秀 311.786667
欧珀莱 276.218543
欧莱雅 167.282698
玉兰油 329.657294
相宜本草 122.958446
美加净 44.694619
美宝莲 148.757576
自然堂 180.130213
薇姿 281.085791
蜜丝佛陀 142.118894
资生堂 577.438490
雅漾 212.618401
雅诗兰黛 872.470718
雪花秀 901.082873
Name: price, dtype: float64
fig = plt.figure(figsize=(12,6))
avg_price.sort_values(ascending=False).plot(kind='bar',width=0.8,alpha=0.6,color='b',label='各品牌平均价格')
y = data['price'].mean()
plt.axhline(y,0,5,color='r',label='全品牌平均价格')
plt.ylabel('各品牌平均价格')
plt.title('各品牌产品的平均价格',fontsize=24)
plt.legend(loc='best')
plt.show()
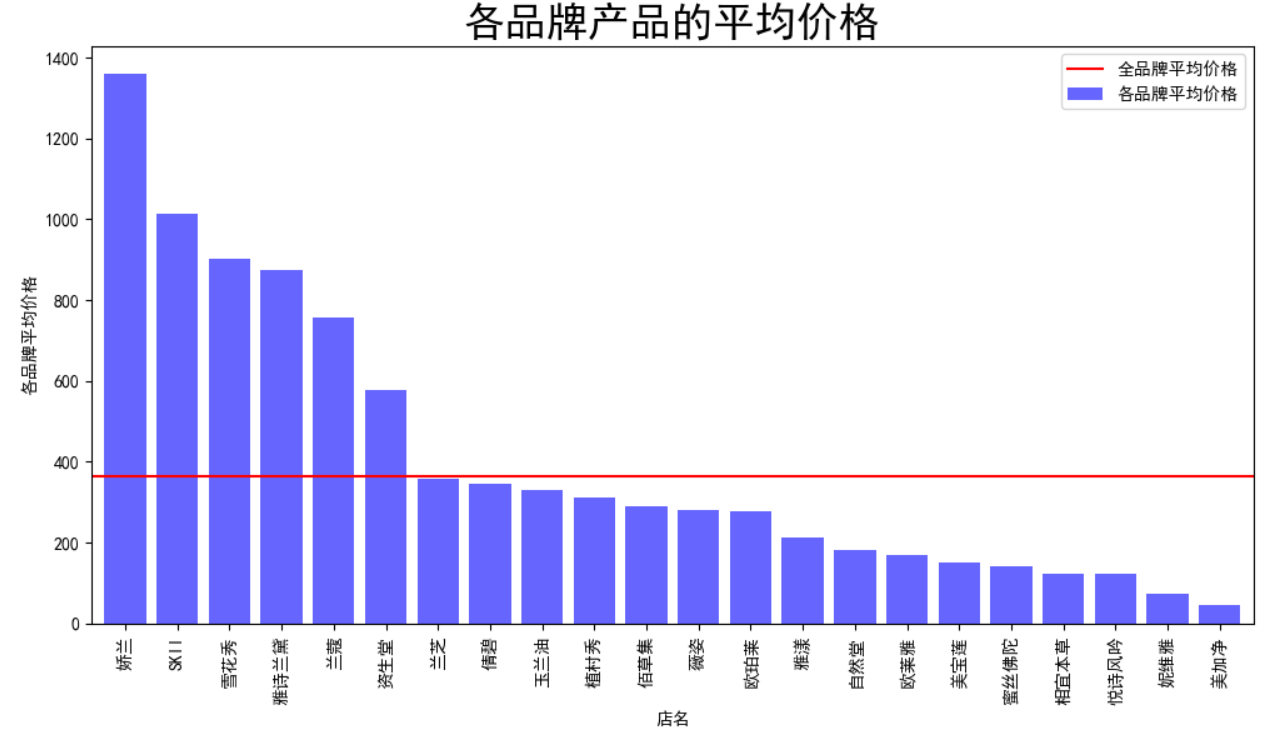
娇兰、SKII、雪花秀、雅诗兰黛、兰蔻、资生堂这几个国际大牌的产品价格很高,产品平均价格都在500以上,都是一线大牌;
兰芝、倩碧、玉兰油、植村秀、佰草集、薇姿、雅漾的平均价格在300-400元左右,其中佰草集是最贵的国货品牌;
美加净作为国货品牌,性价比高,平均价格最低,妮维雅的平均价格第二低,在100元左右;
全品牌平均价格低于400元,除了前五个国际大牌其余品牌的平均价格都低于全品牌平均价格;
plt.figure(figsize=(18,10))
x = data.groupby('店名')['sale_count'].mean()
y = data.groupby('店名')['销售额'].mean()
s = avg_price
txt = data.groupby('店名').id.count().index
sns.scatterplot(x=x,y=x,size=s,sizes=(100,1500),marker='v',alpha=0.5,color='b',data=data)
for i in range(len(txt)):
plt.annotate(txt[i],xy=(x[i],y[i]),xytext = (x[i]+0.2, y[i]+0.2)) #在散点后面增加品牌信息的标签
plt.ylabel('销售额')
plt.xlabel('销量')
plt.legend(loc='upper left')
plt.show()
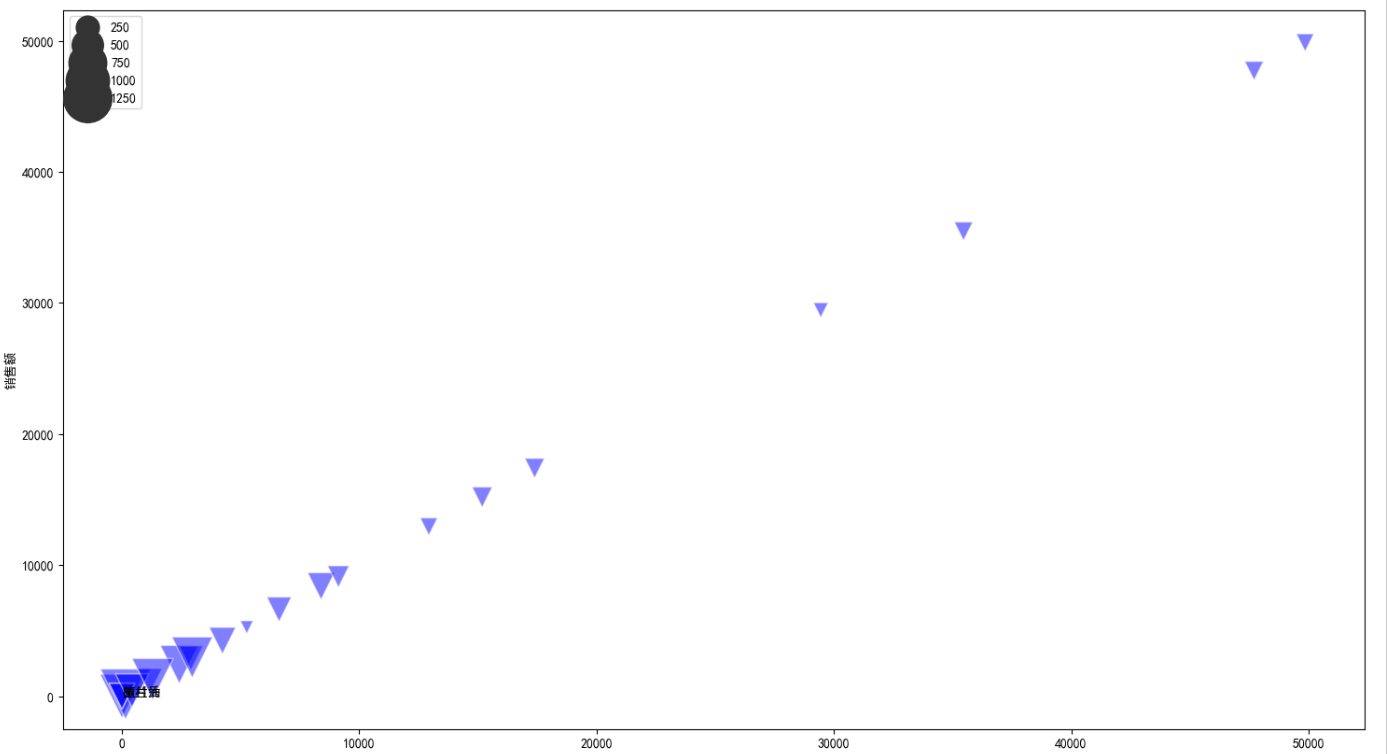
由上图所示,越靠上代表销售额越高,越靠左代表销量越高,图形越大代表平均价格越高
销售量和销售额呈现正相关;
相宜本草、美宝莲、蜜丝佛陀销量和销售额位居前三,且平均价格居中;
说明销量销售额与价格有很重要的联系;
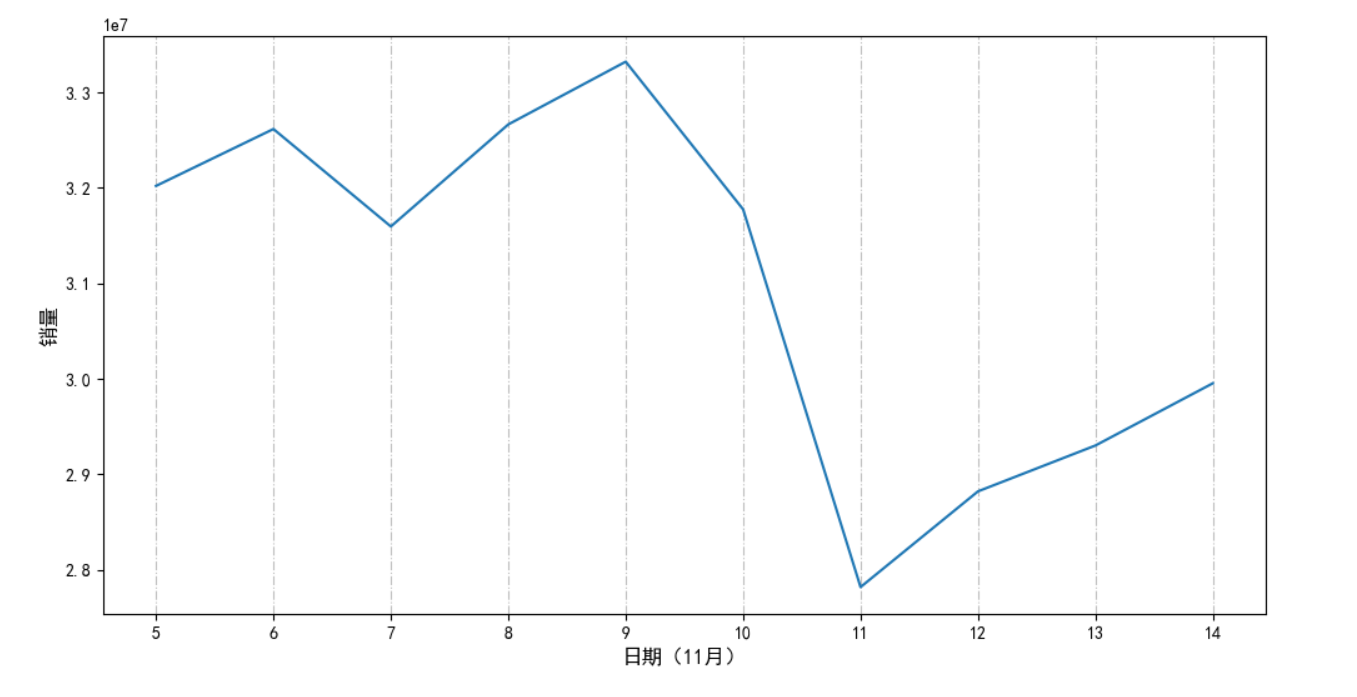
分析时间与销量的关系,体现购买高峰期
from matplotlib.pyplot import MultipleLocator
plt.figure(figsize = (12,6))
day_sale=data.groupby('day')['sale_count'].sum()
day_sale.plot()
plt.grid(linestyle="-.",color="gray",axis="x",alpha=0.5)
x_major_locator=MultipleLocator(1) #把x轴的刻度间隔设置为1,并存在变量里
ax=plt.gca() #ax为两条坐标轴的实例
ax.xaxis.set_major_locator(x_major_locator)
#把x轴的主刻度设置为1的倍数
plt.xlabel('日期(11月)',fontsize=12)
plt.ylabel('销量',fontsize=12)
plt.show()
总结
这次进行的python作业,我对此乐此不彼。一直在研究在查询看怎么进行这个数据分析。最后虽然完成了这个项目,但是我觉得并不好。我会继续研究继续完善。这次也让我有了很多收获 比如:掌握了如何清洗、整理和处理数据的技能,这些技能在数据分析中非常重要。对统计分析、聚类分析和线性回归等分析方法有了更深入的理解等等。
完整程序代码如下:
点击查看代码
import pandas as pd
import numpy as np
data = pd.read_csv('双十一淘宝美妆数据.csv')
data.head()
# 查看各字段信息
data.info()
# 分店铺统计
data['店名'].value_counts()
# ## 二、数据清洗
# ### 2.1 重复数据处理
# 对重复数据做删除处理
print(data.shape)
data = data.drop_duplicates(inplace=False)
print(data.shape)
print(data.index)
data = data.reset_index(drop=True)
print('新索引:',data.index)
# ### 2.2 缺失值处理
# 查看缺失值
data.isnull().any()
# 有两列数据存在缺失值:sale_count, comment_count
data.describe()
mode_01 = data.sale_count.mode()
print(mode_01)
mode_02 = data.comment_count.mode()
print(mode_02)
data = data.fillna(0)
data.isnull().sum()
import jieba
# jieba.load_userdict('addwords.txt')
title_cut = []
for i in data.title:
j = jieba.lcut(i)
title_cut.append(j)
data['item_name_cut'] = title_cut
data[['title','item_name_cut']].head()
# 给商品添加分类
basic_config_data = """护肤品 套装 套装
护肤品 乳液类 乳液 美白乳 润肤乳 凝乳 柔肤液' 亮肤乳 菁华乳 修护乳
护肤品 眼部护理 眼霜 眼部精华 眼膜
护肤品 面膜类 面膜
护肤品 清洁类 洗面 洁面 清洁 卸妆 洁颜 洗颜 去角质 磨砂
护肤品 化妆水 化妆水 爽肤水 柔肤水 补水露 凝露 柔肤液 精粹水 亮肤水 润肤水 保湿水 菁华水 保湿喷雾 舒缓喷雾
护肤品 面霜类 面霜 日霜 晚霜 柔肤霜 滋润霜 保湿霜 凝霜 日间霜 晚间霜 乳霜 修护霜 亮肤霜 底霜 菁华霜
护肤品 精华类 精华液 精华水 精华露 精华素
护肤品 防晒类 防晒霜 防晒喷雾
化妆品 口红类 唇釉 口红 唇彩
化妆品 底妆类 散粉 蜜粉 粉底液 定妆粉 气垫 粉饼 BB CC 遮瑕 粉霜 粉底膏 粉底霜
化妆品 眼部彩妆 眉粉 染眉膏 眼线 眼影 睫毛膏
化妆品 修容类 鼻影 修容粉 高光 腮红
其他 其他 其他"""
category_config_map = {}
for config_line in basic_config_data.split('\n'):
basic_cateogry_list = config_line.strip().strip('\n').strip(' ').split(' ')
main_category = basic_cateogry_list[0]
sub_category = basic_cateogry_list[1]
unit_category_list = basic_cateogry_list[2:-1]
for unit_category in unit_category_list:
if unit_category and unit_category.strip().strip(' '):
category_config_map[unit_category] = (main_category,sub_category)
category_config_map
def func1(row):
sub_type = ''
main_type = ''
exist = False
# 遍历item_name_cut 里每个词语
for temp in row:
if temp in category_config_map:
sub_type = category_config_map.get(temp)[1]
main_type = category_config_map.get(temp)[0]
exist = True
break
if not exist:
sub_type= '其他'
main_type = '其他'
return [sub_type, main_type]
data['sub_type'] = data['item_name_cut'].map(lambda r:func1(r)[0])
data['main_type'] = data['item_name_cut'].map(lambda r:func1(r)[1])
data.head()
gender = []
for i in range(len(data)):
if '男' in data.item_name_cut[i]:
gender.append('是')
elif '男士' in data.item_name_cut[i]:
gender.append('是')
elif '男生' in data.item_name_cut[i]:
gender.append('是')
else:
gender.append('否')
data['是否男士专用'] = gender
data.head()
data['销售额'] = data.sale_count*data.price
data['update_time'] = pd.to_datetime(data['update_time'])
data[['update_time']].head()
data = data.set_index('update_time')
data['day'] = data.index.day
del data['item_name_cut']
ata.head()
data.to_excel('./clean_beautymakeup.xlsx',sheet_name='clean_data')
# ## 三、数据可视化
import matplotlib.pyplot as plt
import seaborn as sns
get_ipython().run_line_magic('matplotlib', 'inline')
data.columns
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
plt.figure(figsize=(12,7))
data['店名'].value_counts().sort_values(ascending=False).plot.bar(width=0.8,alpha=0.6,color='b')
plt.title('各品牌SKU数',fontsize=18)
plt.ylabel('商品数量',fontsize=14)
plt.show()
fig,axes = plt.subplots(1,2,figsize=(12,10))
ax1 = data.groupby('店名').sale_count.sum().sort_values(ascending=True).plot(kind='barh',ax=axes[0],width=0.6)
ax1.set_title('品牌总销售量',fontsize=12)
ax1.set_xlabel('总销售量')
ax2 = data.groupby('店名')['销售额'].sum().sort_values(ascending=True).plot(kind='barh',ax=axes[1],width=0.6)
ax2.set_title('品牌总销售额',fontsize=12)
ax2.set_xlabel('总销售额')
plt.subplots_adjust(wspace=0.4)
plt.show()
fig,axes = plt.subplots(1,2,figsize=(18,12))
data1 = data.groupby('main_type')['sale_count'].sum()
ax1 = data1.plot(kind='pie',ax=axes[0],autopct='%.1f%%',
pctdistance=0.8,
labels= data1.index,
labeldistance = 1.05,
startangle = 60,
radius = 1.2,
counterclock = False,
wedgeprops = {'linewidth': 1.2, },
textprops = {'fontsize':16, 'color':'k','rotation':80},
)
ax1.set_title('主类别销售量占比',fontsize=20)
data2 = data.groupby('sub_type')['sale_count'].sum()
ax2 = data2.plot(kind='pie',ax=axes[1],autopct='%.1f%%',
pctdistance=0.8,
labels= data2.index,
labeldistance = 1.05,
startangle = 230,
radius = 1.2,
counterclock = False,
wedgeprops = {'linewidth': 1.2, },
textprops = {'fontsize':16, 'color':'k','rotation':80},
)
ax2.set_title('子类别销售量占比',fontsize=20)
ax1.set_xlabel(..., fontsize=16,labelpad=38.5)
ax1.set_ylabel(..., fontsize=16,labelpad=38.5)
ax2.set_xlabel(..., fontsize=16,labelpad=38.5)
ax2.set_ylabel(..., fontsize=16,labelpad=38.5)
plt.subplots_adjust(wspace=0.4)
plt.show()
plt.figure(figsize=(18,8))
sns.barplot(x='店名',y='sale_count',hue='main_type',data=data,saturation=0.75,ci=0)
plt.title('各品牌各总类的总销量', fontsize=20)
plt.ylabel('销量',fontsize=16)
plt.xlabel('店名',fontsize=16)
plt.text(0,78000,
verticalalignment='top', horizontalalignment='left',color='gray', fontsize=10)
plt.xticks(fontsize=16,rotation=45)
plt.yticks(fontsize=16)
plt.show()
plt.figure(figsize=(18,8))
sns.barplot( x = '店名',
y = '销售额',hue = 'main_type',data =data,saturation = 0.75,ci=0,)
plt.ylabel('销售额',fontsize=16)
plt.xlabel('店名',fontsize=16)
plt.title('各品牌各总类的总销售额',fontsize=20)
plt.xticks(fontsize=16,rotation=45)
plt.yticks(fontsize=16)
plt.show()
plt.figure(figsize = (16,6))
sns.barplot( x = '店名',
y = 'sale_count',hue = 'sub_type',data =data,saturation = 0.75,ci=0)
plt.title('各品牌各子类的总销量')
plt.ylabel('销量')
plt.show()
plt.figure(figsize = (14,6))
sns.barplot( x = '店名',
y = '销售额',hue = 'sub_type',data =data,saturation = 0.75,ci=0)
plt.title('各品牌各子类的总销售额')
plt.ylabel('销售额')
plt.show()
plt.figure(figsize = (12,6))
data.groupby('店名').comment_count.mean().sort_values(ascending=False).plot(kind='bar',width=0.8)
plt.title('各品牌商品的平均评论数')
plt.ylabel('评论数')
plt.show()
plt.figure(figsize=(18,12))
x = data.groupby('店名')['sale_count'].mean()
y = data.groupby('店名')['comment_count'].mean()
s = data.groupby('店名')['price'].mean()
txt = data.groupby('店名').id.count().index
sns.scatterplot(x,y,size=s,hue=s,sizes=(100,1500),data=data)
for i in range(len(txt)):
plt.annotate(txt[i],xy=(x[i],y[i]))
plt.ylabel('热度')
plt.xlabel('销量')
plt.legend(loc='upper left')
plt.show()
plt.figure(figsize=(18,10))
sns.boxplot(x='店名',y='price',data=data)
plt.ylim(0,3000)
plt.show()
data.groupby('店名').price.sum()
avg_price=data.groupby('店名').price.sum()/data.groupby('店名').price.count()
avg_price
fig = plt.figure(figsize=(12,6))
avg_price.sort_values(ascending=False).plot(kind='bar',width=0.8,alpha=0.6,color='b',label='各品牌平均价格')
y = data['price'].mean()
plt.axhline(y,0,5,color='r',label='全品牌平均价格')
plt.ylabel('各品牌平均价格')
plt.title('各品牌产品的平均价格',fontsize=24)
plt.legend(loc='best')
plt.show()
plt.figure(figsize=(18,10))
x = data.groupby('店名')['sale_count'].mean()
y = data.groupby('店名')['销售额'].mean()
s = avg_price
txt = data.groupby('店名').id.count().index
sns.scatterplot(x,y,size=s,sizes=(100,1500),marker='v',alpha=0.5,color='b',data=data)
for i in range(len(txt)):
plt.annotate(txt[i],xy=(x[i],y[i]),xytext = (x[i]+0.2, y[i]+0.2))
plt.ylabel('销售额')
plt.xlabel('销量')
plt.legend(loc='upper left')
plt.show()
gender_data=data[data['是否男士专用']=='是']
gender_data_1=gender_data[(gender_data.main_type =='护肤品')| (gender_data.main_type=='化妆品')]
plt.figure(figsize = (12,6))
sns.barplot(x='店名',y='sale_count',hue='main_type',data =gender_data_1,saturation=0.75,ci=0,)
plt.show()
f,[ax1,ax2]=plt.subplots(1,2,figsize=(12,6))
gender_data.groupby('店名').sale_count.sum().sort_values(ascending=True).plot(kind='barh',width=0.8,ax=ax1)
ax1.set_title('男士护肤品销量排名')
gender_data.groupby('店名').销售额.sum().sort_values(ascending=True).plot(kind='barh',width=0.8,ax=ax2)
ax2.set_title('男士护肤品销售额排名')
plt.subplots_adjust(wspace=0.4)
plt.show()
from matplotlib.pyplot import MultipleLocator
plt.figure(figsize = (12,6))
day_sale=data.groupby('day')['sale_count'].sum()
day_sale.plot()
plt.grid(linestyle="-.",color="gray",axis="x",alpha=0.5)
x_major_locator=MultipleLocator(1)
ax=plt.gca()
ax.xaxis.set_major_locator(x_major_locator)
plt.xlabel('日期(11月)',fontsize=12)
plt.ylabel('销量',fontsize=12)
plt.show()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号