分布式id解决方案 - 雪花算法
分布式id解决方案 - 雪花算法
随着业务的增长,文章表可能要占用很大的物理存储空间,为了解决该问题,后期使用数据库分片技术。将一个数据库进行拆分,通过数据库中间件连接。如果数据库中该表选用ID自增策略,则可能产生重复的ID,此时应该使用分布式ID生成策略来生成ID。
雪花算法实现
snowflake是Twitter开源的分布式ID生成算法,结果是一个long型的ID。其核心思想是:使用41bit作为毫秒数,10bit作为机器的ID(5个bit是数据中心,5个bit的机器ID),12bit作为毫秒内的流水号(意味着每个节点在每毫秒可以产生 4096 个 ID),最后还有一个符号位,永远是0
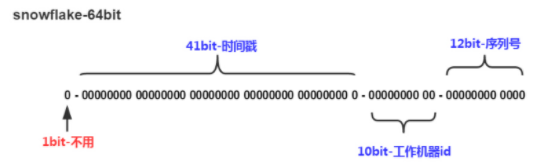
mybatis-plus已经集成了雪花算法,完成以下两步即可在项目中集成雪花算法
第一:在实体类中的id上加入如下配置,指定类型为id_worker
@TableId(value = "id",type = IdType.ID_WORKER)
private Long id;
第二:在application.yml文件中配置数据中心id和机器id
mybatis-plus:
mapper-locations: classpath*:mapper/*.xml
# 设置别名包扫描路径,通过该属性可以给包中的类注册别名
type-aliases-package: com.heima.model.article.pojos
global-config:
datacenter-id: 1
workerId: 1
datacenter-id:数据中心id(取值范围:0-31)
workerId:机器id(取值范围:0-31)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号