
ElasticSearch - 2 分词器
ElasticSearch - 2 分词器
5.1 分词器介绍
- IKAnalyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包
- 是一个基于Maven构建的项目
- 具有60万字/秒的高速处理能力
- 支持用户词典扩展定义
- 下载地址:https://github.com/medcl/elasticsearch-analysis-ik/archive/v7.4.0.zip
安装包在资料文件夹中提供
5.2 ik分词器安装
参见 ik分词器安装.md
执行如下命令时如果出现 打包失败(501码)将maven镜像换成阿里云的
mvn package
/opt/apache-maven-3.1.1/conf/setting.xml
<mirror>
<id>alimaven</id>
<name>aliyun maven</name>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
<mirrorOf>central</mirrorOf>
</mirror>
5.3 ik分词器使用(熟练)
IK分词器有两种分词模式:ik_max_word和ik_smart模式。
ik_max_word
会将文本做最细粒度的拆分,比如会将“乒乓球明年总冠军”拆分为“乒乓球、乒乓、球、明年、总冠军、冠军。
#方式一ik_max_word
GET /_analyze
{
"analyzer": "ik_max_word",
"text": "乒乓球明年总冠军"
}
执行结果如下
{
"tokens" : [
{
"token" : "乒乓球",
"start_offset" : 0,
"end_offset" : 3,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "乒乓",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "球",
"start_offset" : 2,
"end_offset" : 3,
"type" : "CN_CHAR",
"position" : 2
},
{
"token" : "明年",
"start_offset" : 3,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 3
},
{
"token" : "总冠军",
"start_offset" : 5,
"end_offset" : 8,
"type" : "CN_WORD",
"position" : 4
},
{
"token" : "冠军",
"start_offset" : 6,
"end_offset" : 8,
"type" : "CN_WORD",
"position" : 5
}
]
}
ik_smart
会做最粗粒度的拆分,比如会将“乒乓球明年总冠军”拆分为乒乓球、明年、总冠军。
#方式二ik_smart
GET /_analyze
{
"analyzer": "ik_smart",
"text": "乒乓球明年总冠军"
}
执行结果如下
{
"tokens" : [
{
"token" : "乒乓球",
"start_offset" : 0,
"end_offset" : 3,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "明年",
"start_offset" : 3,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "总冠军",
"start_offset" : 5,
"end_offset" : 8,
"type" : "CN_WORD",
"position" : 2
}
]
}
5.4 使用IK分词器-查询文档(重点)
-
词条查询:term
-
- 词条查询不会分析查询条件,只有当词条和查询字符串完全匹配时才匹配搜索,不对查询条件分词
-
全文查询:match
-
- 全文查询会分析查询条件,先将查询条件进行分词,然后查询,求并集
5.4.1 创建索引,添加映射,并指定分词器为ik分词器
PUT person2
{
"mappings": {
"properties": {
"name": {
"type": "keyword"
},
"address": {
"type": "text",
"analyzer": "ik_max_word"
}
}
}
}
5.4.2 添加文档
POST /person2/_doc/1
{
"name":"张三",
"age":18,
"address":"北京海淀区"
}
POST /person2/_doc/2
{
"name":"李四",
"age":18,
"address":"北京朝阳区"
}
POST /person2/_doc/3
{
"name":"王五",
"age":18,
"address":"北京昌平区"
}
5.4.3 查询映射
**GET person2**
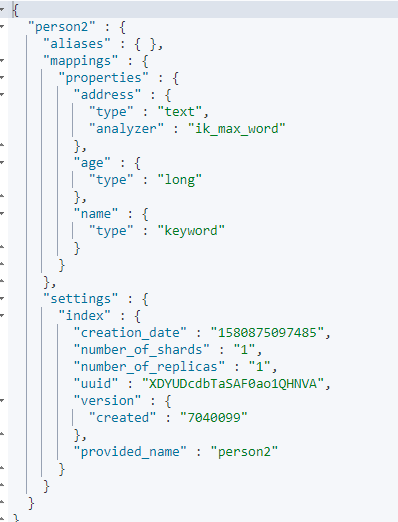
5.4.4 查看分词效果
GET _analyze
{
"analyzer": "ik_max_word",
"text": "北京海淀"
}
5.4.5 词条查询:term
查询person2中匹配到"北京"两字的词条
GET /person2/_search
{
"query": {
"term": {
"address": {
"value": "北京"
}
}
}
}
5.4.6 全文查询:match
全文查询会分析查询条件,先将查询条件进行分词,然后查询,求并集
GET /person2/_search
{
"query": {
"match": {
"address":"北京昌平"
}
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号