---------------
| PSP2.1 |
Personal Software Process Stages |
预估耗时(分钟) |
实际耗时(分钟) |
| Planning |
计划 |
20 |
20 |
| Estimate |
估计这个任务需要多少时间 |
720 |
|
| Development |
开发 |
|
|
| Analysis |
需求分析 (包括学习新技术) |
180 |
240 |
| Design Spec |
生成设计文档 |
60 |
60 |
| Design Review |
设计复审 |
20 |
20 |
| Coding Standard |
代码规范 (为目前的开发制定合适的规范) |
30 |
50 |
| Design |
具体设计 |
30 |
30 |
| Coding |
具体编码 |
180 |
240 |
| Code Review |
代码复审 |
30 |
30 |
| Test |
测试(自我测试,修改代码,提交修改) |
60 |
60 |
| Reporting |
报告 |
60 |
60 |
| Test Report |
测试报告 |
30 |
30 |
| Size Measurement |
计算工作量 |
10 |
10 |
| Postmortem & Process Improvement Plan |
事后总结, 并提出过程改进计划 |
30 |
45 |
| 合计 |
|
740 |
895 |
解题思路描述
起初思路
- 主要问题
- 给的数据每一项有的关键信息是个人、项目、事件。其中个人和项目都有Id 和 name属性(个人是login,项目是repo),事件有四种。第一时间想到的是把每一个人和每一个项目都建一个类,读数据的过程,如果是新的人或项目就实例化一个,如果是之前实例化过的就根据数据修改参数。
- 根据上诉思路我将代码完成,类有主类,用户类,项目类,cli指令类(现在想想估计是面向对象课上多了)。在主类中定义了用户数组和项目数组。最后读数据的时候就出问题了:数据条数低于三千左右工作正常,但在大致高于三千的时候程序就崩了。原因应该是实例化的类太多把内存占满了导致错误。
更改后的思路
- 阅读给出的python实例代码之后。
- 因为数据量比较大,并且数据中信息大多是互不相关的。所以在读数据的时候要做的就是把数据中有用的部分解析后存储下来(用数组都行)
关于具体实施过程
- gradle工具的构建。使用idea打开gradle工程出现错误。具体原因可能是我用的idea2018对gradle6.x的支持有点问题。网络上参考有使用较低版本的gradle,尝试过5.x版本和3.x版本之后问题都没有解决并且idea还在提醒尽量使用6.x以上版本。然后在群里问过之后将idea升级到最新版本问题就不见了。玄学
- json包的选择,目前在用在java上使用的主要json包有google的gson,alibaba的fastjson,还有springboot自带的jackson.简略的查了资料发现fastjson的速度最快就选了。
- github 上的pull request功能:大概意思就是每个同学将提供的代码结构fork到自己的仓库并将修改Push到自己的仓库上,代码完成后向原仓库发送Pull request请求,之后根据actions的配置就会自动在github的服务器上跑代码完成测试
制定代码规范
- 代码规范
- 参考阿里的java代码规范,制定了现在有需要用到的规范。
任务分解
编码结构
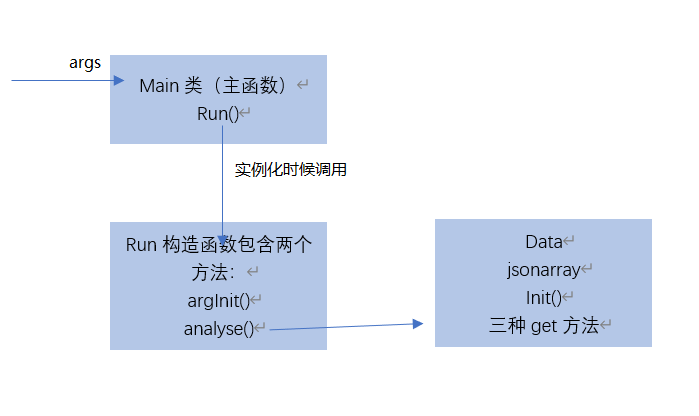
- 参考给出的示例代码后大致编码结构
![]()
- argInit()包含指令解释器的生成
- analyse()根据指令,通过调用data类中的三种get方法返回三种查询所需要的值
- Data中init()根据传入的地址读取json包并解析后存放在jsonarray中
测试
- 用自定义数组模拟了控制台输入
![]()
优化
Bug记录
- 下面是我一开始写的简单的读取,看起来没有错,可以读几千条的数据,但是数据再多到几万条就会报错。
try {
String line = null;
FileReader fileReader = new FileReader(f);
BufferedReader bufferedReader = new BufferedReader(fileReader);
JSONObject itemjsonline = null;
while ((line = bufferedReader.readLine()) != null) {
itemjsonline = JSONObject.parseObject(line);
jsonObject = new JSONObject();
jsonObject.fluentPut("user", itemjsonline.getJSONObject("actor").getString("login"));
jsonObject.fluentPut("event", itemjsonline.getString("type"));
jsonObject.fluentPut("repo", itemjsonline.getJSONObject("repo").getString("name"));
jsonarray.add(jsonObject);
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
try {
LineIterator iterator = null;
iterator = FileUtils.lineIterator(f, "UTF-8");
String line = null;
JSONObject itemjsonline = null;
while (iterator.hasNext()) {
line = iterator.nextLine();
itemjsonline = JSONObject.parseObject(line);
jsonObject = new JSONObject();
jsonObject.fluentPut("user", itemjsonline.getJSONObject("actor").getString("login"));
jsonObject.fluentPut("event", itemjsonline.getString("type"));
jsonObject.fluentPut("repo", itemjsonline.getJSONObject("repo").getString("name"));
jsonarray.add(jsonObject);
}
} catch (FileNotFoundException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
总结
- 这次的题目是大数据处理,如果不进行优化的话不需要用到算法知识,主要是库的调用。
- 本次作业我学习到了
- 用gradle创建工程,用groovy进行相关调试
- actions的基本概念和语法,虽然本次作业不需要我们自己配置
- github上pull request的发起
- apache cli包的使用
- alibaba fastjson的使用
- java 玄学读文件
- 制定了自己的编码规范,编码严格按照编码规范执行
- 原本以为是几天就能完成的项目,一直做到最后一天,期间处理了太多的bug,(本质还是自己写了太多的bug)而因此浪费了很多时间。改Bug的同时,我也学到了一件事,编译报错的时候与其直接访问搜索引擎,不如Control+左键直接进错误的函数里面看看,这次大部分的问题都是由于第三方库的使用不熟练导致的。进源码看简单而直接。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号