
利用prometheus监控主流数据库
(1)编写docker-compose主要服务配置文件:
version: '3.8' volumes: prometheus_data: {} grafana_data: {} networks: front-tier: back-tier: services: prometheus: image: prom/prometheus container_name: prometheus-server restart: always environment: TZ : 'Asia/Shanghai' volumes: - ./prometheus/:/etc/prometheus/ - ./prometheus_data/:/prometheus/ command: - '--web.enable-admin-api' - '--storage.tsdb.retention=15d' - '--config.file=/etc/prometheus/prometheus.yml' - '--storage.tsdb.path=/prometheus' - '--web.console.libraries=/usr/share/prometheus/console_libraries' - '--web.console.templates=/usr/share/prometheus/consoles' ports: - 9090:9090 links: - cadvisor:cadvisor - alertmanager:alertmanager depends_on: - cadvisor networks: - back-tier restart: always node-exporter: image: prom/node-exporter volumes: - /proc:/host/proc:ro - /sys:/host/sys:ro - /:/rootfs:ro restart: always container_name: prometheus-node-exporter environment: TZ : 'Asia/Shangha' command: - '--path.procfs=/host/proc' - '--path.sysfs=/host/sys' - --collector.filesystem.ignored-mount-points - "^/(sys|proc|dev|host|etc|rootfs/var/lib/docker/containers|rootfs/var/lib/docker/overlay2|rootfs/run/docker/netns|rootfs/var/lib/docker/aufs)($$|/)" ports: - 9100:9100 networks: - back-tier restart: always deploy: mode: global alertmanager: image: prom/alertmanager container_name: alertmanager environment: TZ : 'Asia/Shangha' restart: always ports: - 9093:9093 volumes: - ./alertmanager/etc:/etc/alertmanager/ - ./alertmanager/data:/alertmanager/ networks: - back-tier restart: always command: - '--config.file=/etc/alertmanager/config.yml' - '--storage.path=/alertmanager' prometheusdingtalk: image: timonwong/prometheus-webhook-dingtalk container_name: dingtalk environment: TZ : 'Asia/Shanghai' command: - --web.enable-ui - --web.enable-lifecycle - --config.file=/etc/prometheus-webhook-dingtalk/config.yml restart: always volumes: - /etc/localtime:/etc/localtime - ./webhook/ding.yml:/etc/prometheus-webhook-dingtalk/config.yml - ./webhook/template.tmpl:/etc/prometheus-webhook-dingtalk/templates/default.tmpl ports: - 8060:8060 cadvisor: image: google/cadvisor container_name: cadvisor environment: TZ : 'Asia/Shangha' restart: always volumes: - /:/rootfs:ro - /var/run:/var/run:rw - /sys:/sys:ro - /var/lib/docker/:/var/lib/docker:ro ports: - 8080:8080 networks: - back-tier restart: always deploy: mode: global grafana: image: grafana/grafana container_name: grafana environment: TZ : 'Asia/Shangha' restart: always user: "472" depends_on: - prometheus ports: - 3000:3000 volumes: - grafana_data:/var/lib/grafana - ./grafana/provisioning/:/etc/grafana/provisioning/ env_file: - ./grafana/config.monitoring networks: - back-tier - front-tier restart: always
然后把各个服务都起起来,检查状态,我的配置目录结构如下:
root@dba-ops-manager:/data/monitor# tree . . ├── alertmanager │ ├── data │ └── etc │ ├── config.yml ├── grafana │ ├── config.monitoring │ └── provisioning ├── prometheus │ ├── linux-rules.yml │ ├── mongo-rules.yml │ ├── mysql-rules.yml │ ├── prometheus-rules.yml │ ├── prometheus.yml │ ├── rabbitmq-rules.yml │ └── redis-rules.yml ├── prometheus_data │ │ ├── chunks │ │ │ └── 000001 │ │ ├── index │ │ ├── meta.json │ │ └── tombstones │ ├── 01F9GVKMEP1QPZ5J849PR9SX4E │ │ ├── chunks │ │ │ └── 000001 │ │ ├── index │ │ ├── meta.json │ │ └── tombstones │ ├── 01F9JSD4FR4C7N06W3K2XC67KY │ │ ├── chunks │ │ │ └── 000001 │ │ ├── index │ │ ├── meta.json │ │ └── tombstones │ ├── 01F9MGATA29KZC5YEWM3R9FG6P │ │ ├── chunks │ │ │ └── 000001 │ │ ├── index │ │ ├── meta.json │ │ └── tombstones │ ├── 01F9MQ6HHZ97JB9H62EC0CRYWC │ │ ├── chunks │ │ │ └── 000001 │ │ ├── index │ │ ├── meta.json │ │ └── tombstones │ ├── 01F9MQ6PBYNQVEJDMQX3S0GPWE │ │ ├── chunks │ │ │ └── 000001 │ │ ├── index │ │ ├── meta.json │ │ └── tombstones │ ├── 01F9MY28T4H2SQYG00VAAJWHWH │ │ ├── chunks │ │ │ └── 000001 │ │ ├── index │ │ ├── meta.json │ │ └── tombstones │ ├── 01F9N4XZYA02MS06CZN98M6GBE │ │ ├── chunks │ │ │ └── 000001 │ │ ├── index │ │ ├── meta.json │ │ └── tombstones │ ├── chunks_head │ │ ├── 000054 │ │ ├── 000055 │ │ ├── 000056 │ │ └── 000057 │ ├── lock │ ├── queries.active │ └── wal │ ├── 00000158 │ ├── 00000159 │ ├── 00000160 │ ├── 00000161 │ └── checkpoint.00000157 │ └── 00000000 ├── prometheus_server.yaml └── webhook ├── ding.yml └── template.tmpl
其中各个配置文件我都已经上传至github,主要有2个点需要自己配置,一个是钉钉告警消息推送模板,一是各个服务之间一些配置文件依赖以及详细参数修改。
由于alertmanager是转发消息,没办法持久化存储告警消息,然后我用了网友的一个镜像,把告警消息实时推送至钉钉的同时,也一并存到mysql存一份,方便统计告警消息。
这个镜像yaml配置如下:
version: '3.7' services: alertsnitch: image: registry.gitlab.com/yakshaving.art/alertsnitch container_name: alertsnitch ports: - "9567:9567" environment: ALERTSNITCH_DSN:"username:passwd@tcp(x.x.x:3306)/alertsnitch" ALERSTNITCH_BACKEND: "mysql"
需要自己先把这个镜像需要的表结构再数据库创建好,具体的搜一下这个镜像名称,就可以找到方法,配置好以后,可以再数据库查询到,发送一条告警消息的同时,也向mysql写一条告警。
alertmanager主要配置:
global: resolve_timeout: 5m route: receiver: 'webhook' group_by: ['alertname','target'] group_wait: 10s group_interval: 10s repeat_interval: 30m receivers: - name: 'webhook' webhook_configs: - url: 'http://x.x.x.x:8060/dingtalk/webhook/send' - url: 'http://x.x.x.x:9567/webhook' send_resolved: true inhibit_rules: - source_match: ## 源报警规则 severity: 'critical' target_match: ## 抑制的报警规则 severity: 'warning' equal: ['alertname','target','job','env']
其中9567这个端口就是转发消息到alertsnitch,使告警消息入库,再数据库建一个视图,方便查询告警消息:
create view alerts_view as select `ti`.`AlertID` AS `alertid`, `rt`.`startsAt` AS `startsat`, `rt`.`endsAt` AS `endsat`, json_unquote(json_extract(`el`.`value`, '$.job')) AS `job`, json_unquote(json_extract(`el`.`value`, '$.env')) AS `env`, json_unquote(json_extract(`el`.`value`, '$.group')) AS `machine_group`, json_unquote(json_extract(`el`.`value`, '$.alertname')) AS `alertname`, `ti`.`Value` AS `msg` from ((`alertsnitch`.`alert` `rt` left join `alertsnitch`.`alertannotation` `ti` on ((`rt`.`ID` = `ti`.`AlertID`))) left join (select `alertsnitch`.`alertlabel`.`AlertID` AS `AlertID`, concat('{', group_concat(concat('"', `alertsnitch`.`alertlabel`.`Label`, '"', ':', '"', `alertsnitch`.`alertlabel`.`Value`, '"') separator ','), '}') AS `value` from `alertsnitch`.`alertlabel` group by `alertsnitch`.`alertlabel`.`AlertID`) `el` on ((`ti`.`AlertID` = `el`.`AlertID`))) order by `rt`.`startsAt` desc;
然后可以查看每条告警消息详细信息。
自定义的钉钉通知模板:
{{ define "__subject" }}
[{{ .Status | toUpper }}{{ if eq .Status "firing" }}:{{ .Alerts.Firing | len }}{{ end }}]
{{ end }}
{{ define "__alert_list" }}{{ range . }}
> - 报警主题: <font color=#FF0000 size=3 > 检测到故障</font>
> - 监控指标: {{ .Labels.alertname }}
> - 告警时间: {{ dateInZone "2006.01.02 15:04:05" (.StartsAt) "Asia/Shanghai" }}
> - 告警内容: {{ .Annotations.summary }}
> - 告警主机: {{ .Labels.job }}
> - 机器环境: {{ .Labels.env }}
> - 机器分组: {{ .Labels.group }}
{{ end }}{{ end }}
{{ define "__resolved_list" }}{{ range . }}
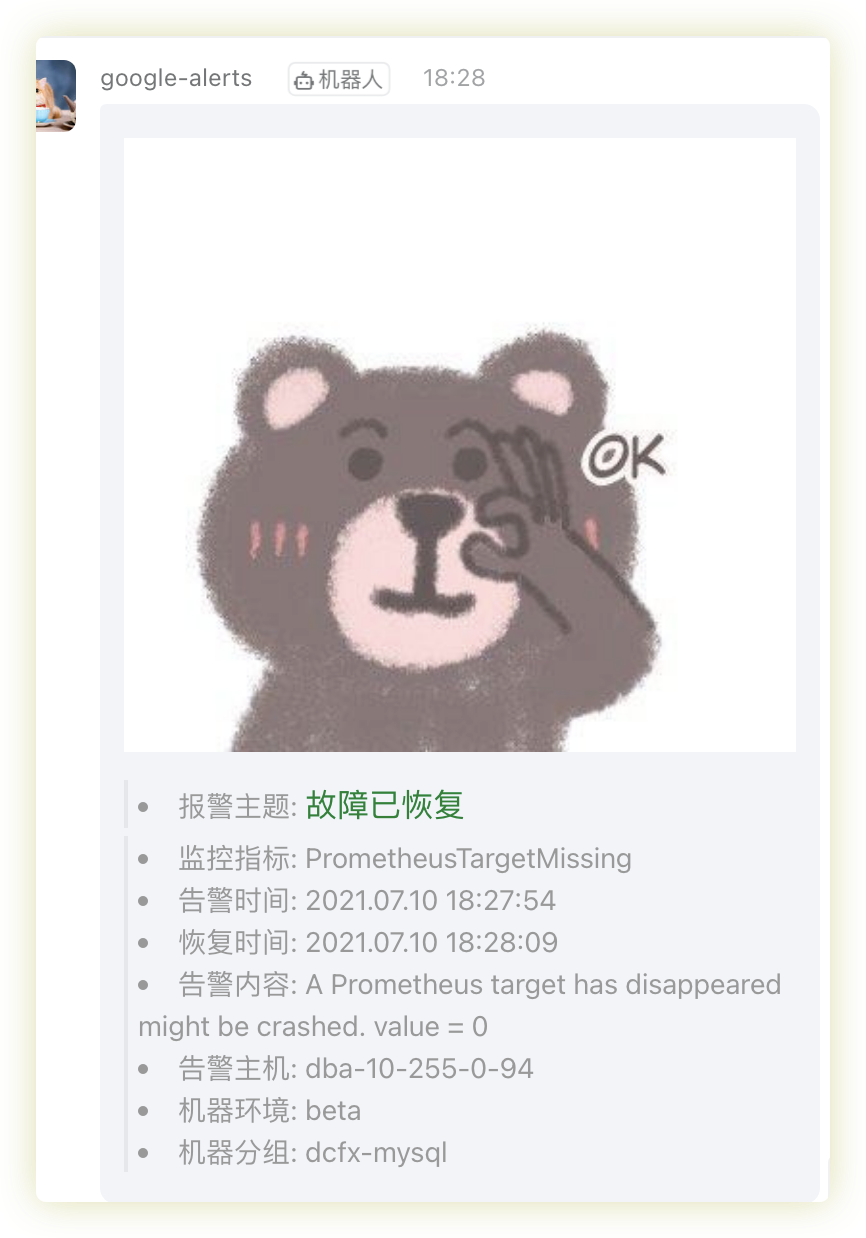
> - 报警主题: <font color=#008230 size=3 > 故障已恢复</font>
> - 监控指标: {{ .Labels.alertname }}
> - 告警时间: {{ dateInZone "2006.01.02 15:04:05" (.StartsAt) "Asia/Shanghai" }}
> - 恢复时间: {{ dateInZone "2006.01.02 15:04:05" (.EndsAt) "Asia/Shanghai" }}
> - 告警内容: {{ .Annotations.summary }}
> - 告警主机: {{ .Labels.job }}
> - 机器环境: {{ .Labels.env }}
> - 机器分组: {{ .Labels.group }}
{{ end }}{{ end }}
{{ define "default.title" }}
{{ template "__subject" . }}
{{ end }}
{{ define "default.content" }}
{{ if gt (len .Alerts.Firing) 0 }}

{{ template "__alert_list" .Alerts.Firing }}
{{ end }}
{{ if gt (len .Alerts.Resolved) 0 }}

{{ template "__resolved_list" .Alerts.Resolved }}
{{ end }}
{{ end }}
{{ define "ding.link.title" }}{{ template "default.title" . }}{{ end }}
{{ define "ding.link.content" }}{{ template "default.content" . }}{{ end }}
{{ template "default.title" . }}
{{ template "default.content" . }}
通知消息如下:

各种数据库,mysql,redis,rabbitmq,mongo,如需alert-rules,可以留言。
业余经济爱好者

 浙公网安备 33010602011771号
浙公网安备 33010602011771号