JavaImprove--Lesson09--文件操作,UTF-8字符集,IO流-字节流
一.文件操作
在前面学习的内容中,存储数据的方式有很多,可以申请一个变量,一个数组,一个集合等方式,这些方式都可以记住数据,但是都是暂时的
因为这些方式的运行都是在内存中,内存运行快,对数据处理有很大的好处,但是缺点就是断电即失,所以不便于长期保存的场景
如果想长久的保存数据,就需要用到今天所讲的内容了:File类
File代表的是文件/文件目录,它存储在计算机的硬盘中,不易丢失,即使断电了,数据依旧还在,所以很适合长久的保存数据,但是效率低
File类是java.io包下的类,file类代表的是当前系统的文件:
- 获取文件信息(时间,大小)
- 判断文件类型
- 创建/删除文件
但是注意File类代表的是文件本身,只能对文件进行操作,不能读写文件中的数据,操作数据使用IO流
IO流:读写文件数据(可以是本地数据,也可以是网络数据)
File:代表文件 IO流:读写数据
创建文件
创建文件需要使用到的方法:public File(String pathname)
这是File类的构造器,使用此构造器,填写地址就可以拿到文件对象
//public File(String path) File f1 = new File("D:\\java\\test.txt"); System.out.println(f1.getName());//test.txt System.out.println(f1.length());//13 //路径写法二 / 单斜杠 File f2 = new File("D:/java/test.txt"); System.out.println(f2.length());//13 //路径写法三 File f3 = new File("D:" + File.separator + "java" + File.separator + "test.txt"); System.out.println(f3.length());//13
File类也可以指向一个不存在的路径,这并不会报错,因为后面会学创建文件的命令,既然是创建,原来的此路径肯定是没有文件的
//File可以指向一个不存在的路径 File f4 = new File("D:/java/test1.txt"); System.out.println(f4.length()); //0 //如上路径是不存在的,如果不确定路径是否有文件,Java提供了一个exists()方法 System.out.println(f4.exists());//false
文件路径的表达方式:绝对路径和相对路径
//路径表达的两种方式 //方式一:绝对路径:绝对路径是带盘符,也就是在找此文件时会从盘符开始找 File f5 = new File("D:\\java\\test.txt"); System.out.println(f5.exists());//true //方式二:相对路径:相对路径是不带盘符的,且是从当前项目向下找文件的,灵活一些,也推荐使用 File f6 = new File("static/text/test.txt"); System.out.println(f6.exists());//true
File类常用方法
public static void main(String[] args) throws IOException { //创建文件对象,指代某个文件 File f1 = new File("D:/java/js.txt"); //public boolean exists()判断当前文件对象是否存在,存在则返回ture System.out.println(f1.exists());//false //public boolean isFile()判断当前文件对象是否指代的文件,是文件则是true,反之 System.out.println(f1.isFile());//false,应该是true,但是此文件不存在 //public boolean isDirectory()判断当前文件对象是否为文件夹,是则true System.out.println(f1.isDirectory());//false //public String getName()获取文件名称(包含后缀) System.out.println(f1.getName());//js.txt //public long length()获取文件大小,字节个数 System.out.println(f1.length());//0 //public long lastModified() 获取文件最后的修改时间戳 boolean CNF = f1.createNewFile(); SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy/MM/dd hh:mm:ss"); String format = dateFormat.format(f1.lastModified()); System.out.println(format);//2024/04/17 10:45:07 //public String getPath()获取文件对象使用的路径 System.out.println(f1.getPath());//D:\java\js.txt //public String getAbsolutePath()获取绝对路径 System.out.println(f1.getAbsoluteFile());//D:\java\js.txt }
文件创建和删除方式
创建和删除需要选中一个文件对象
//文件创建和删除的方法 //public boolean createFile() 创建一个新的文件,创建成功则是true File f2 = new File("D:\\java\\jk.txt"); System.out.println(f2.createNewFile());//true //public boolean mkdir()用于创建文件夹,但是只能创建一级文件夹 File f3 = new File("D:/java/txt"); System.out.println(f3.mkdir());//true //public boolean mkdirs()用于创建文件夹,而且是创建多级文件夹 File f4 = new File("D:/ts/ta/tb"); System.out.println(f4.mkdirs());//true //public boolean delete()删除文件,或空文件夹,但是有文件的文件夹删除不了 System.out.println(f4.delete());//true
文件的遍历
public static void main(String[] args) { //遍历文件夹 //public String[] list()获取当前文件夹下的所有一级文件名称,并且保存到一个字符串数组中 File f1 = new File("D:/java"); String[] list = f1.list(); for (String s : list) { System.out.print(s+","); } //apache-maven-3.2.5,apache-maven-3.8.6,apache-tomcat-10.1.7,Dall,idea,JAVAWeb,javaweb-01-maven, // javaweb-01-maven02,javaweb-02-servlet,JavaWeb-QModel,javaweb-session-cookie,JAVAWebjsp,jk.txt,js.txt, // maven-webap,MySQL,OUR-test,spring-study,SpringBoot-Hellow,SpringMVC,ssmBuild,Study-mybatis, // Test,test.txt,Tomcat,Tomcat.rar,txt, //public File[] listFiles()重点方法,获取当前文件夹下的所有一级文件对象,保存到File数组中 File[] f3 = f1.listFiles(); System.out.println(Arrays.toString(f3)); //[D:\java\apache-maven-3.2.5, D:\java\apache-maven-3.8.6, D:\java\apache-tomcat-10.1.7, // D:\java\Dall, D:\java\idea, D:\java\JAVAWeb, D:\java\javaweb-01-maven, // D:\java\javaweb-01-maven02, D:\java\javaweb-02-servlet, D:\java\JavaWeb-QModel, // D:\java\javaweb-session-cookie, D:\java\JAVAWebjsp, D:\java\jk.txt, // D:\java\js.txt, D:\java\maven-webap, D:\java\MySQL, D:\java\OUR-test, // D:\java\spring-study, D:\java\SpringBoot-Hellow, D:\java\SpringMVC, // D:\java\ssmBuild, D:\java\Study-mybatis, // D:\java\Test, D:\java\test.txt, D:\java\Tomcat, // D:\java\Tomcat.rar, D:\java\txt] }
使用listFiles方法的注意事项:
- 当主调是文件或路径不存在时,返回null
- 当主调是一个空文件夹时,返回一个长度为0的数组
- 当主调是一个有内容的文件夹时,将里面的一级文件和文件夹路径存放在File数组中返回
- 当主调是一个文件夹时,有隐藏文件也会被包含返回
- 当主调是文件夹,但是没有权限访问时,返回null
文件的递归查找
文件的查找实际上是使用了递归的算法
当进入一个文件夹后,从第一个文件开始寻找,如果文件不是要找的文件,则判断此文件是文件夹还是文件
是文件夹则递归的进去找文件,不是文件夹则进行当前循环的下一次循环
public static void main(String[] args) { //D盘文件夹 File file = new File("D:/Tencent"); File[] files = file.listFiles(); //查找QQ.exe LoopFile(files,"QQ.exe"); } public static Boolean LoopFile(File[] files,String fileName){ Boolean flag =false; //判断传入参数是否为空,换句话说就是判断文件是否存在 if (files.length == 0 && files == null){ return false; } //遍历文件夹 for (File file : files) { String name = file.getName(); //拿到文件名字,如果是找到的返回 if (name.equals(fileName)) { System.out.println("找到了,路径在:" + file); Runtime runtime = Runtime.getRuntime(); try { runtime.exec(file.getAbsolutePath()); } catch (IOException e) { throw new RuntimeException(e); } //返回一个True,上层的函数接收到了以后,就会直接向上层返回,不在继续寻找 return true; } else { //当此文件不是要找的时候,继续向下层寻找 boolean f1 = file.isDirectory();//判断是否为文件夹 System.out.println(file.getName()); if (f1) { //是文件夹向下找 File[] f2 = file.listFiles(); if (f2 == null){ //判断文件是否为空,空则进行下一次循环 continue; }else { //不为空,向下一个文件夹继续找 flag = LoopFile(f2,fileName); } } else { //不是文件夹又不是要找的文件,直接进行下一次循环 continue; } } //下层函数返回的结果,如果为ture,则找到了,不需要继续找了,直接返回 if (flag){ return true; } } //一个文件夹刷完了都没找到,返回false return false; }
其中有些时候文件夹内容可能很多,所以我们可以在找到文件后设置标志符,让函数直接返回,减小开销
如果文件不止一个,则不要设置标识符
删除文件夹
删除文件夹需要注意的是:Java不支持直接删除不为空的文件夹,所以删除文件夹时,先要删除文件夹中的内容
当文件夹还有内容时,继续进去删除,又是递归思想
public static void main(String[] args) { File file = new File("D:/86173/"); removeDir(file); } public static void removeDir(File file){ //文件本来就不存在,路径错误,删除不了 if (file == null || !file.exists()){ System.out.println(file.length()); System.out.println(file.exists()); return; } //单纯就是文件,直接删除 if (file.isFile()){ System.out.println("删除了:"+file.getName()); file.delete(); }else { if (file.listFiles() == null){ //无权限,不能删除 return; } File[] files = file.listFiles(); //当是文件夹时,进入下一级继续删除 for (File f1 : files) { if (f1.isFile()){ //是文件直接删除 f1.delete(); }else { if (f1.listFiles() == null){ //有空文件夹直接删除 System.out.println("删除了:"+f1.getName()); f1.delete(); continue; } //又有文件且非空,继续进行删除 removeDir(f1); } } //删除到最后注意要删除自己这个目录 if (file.listFiles().length == 0){ System.out.println("删除了:"+file.getName()); file.delete(); } } }
二.UTF-8字符集
在计算机中,存储的从来就只有0或者1,但是在现实世界中,我们的世界却是千变万化的,并不只有0或1
所以计算机在存储这千变万化的世界要怎么存储呢?
在计算机发明之后,美国人采用编码的方式存储字符,一个字节是8位,所以最多可以表示256个字符
但是最著名的ASCII编码只用了128位,其中一些常用的字符0 - {48},a - {97} , A - {65}
对于字符少的一个字节完全够用,但是我们国家的汉字使用一个字节表示就完全不可能了
根据最新的《通用规范汉字表》(2013年发布),共收录了8105个汉字。但是,这并不意味着汉字的数量就只有这么多,因为除了通用的汉字外,还有很多生僻字、古汉字以及一些方言中使用的汉字没有被收录
所以汉字有自己的编码。即GBK,GBK编码兼容了ASCII编码,同时汉字使用两个字节表示可以表示32768个汉字

如上图:当我们拿到一个字节之后,首先通过首位判断是中文还是ASCII码,
如果是0开始,则读取一个字节的数据,翻译ASCII
如果是1开始,则读取两个字节的数据,翻译成中文

UTF-32编码
看了GBK编码之后,我们可以发现中国人使用计算机有自己的编码,那么,外国人使用计算机也会有自己的编码
但是世界上的国家太多了,如果任其自行编码,很难做到统一,也就是我编写的代码在中国能用,到外国去就要改,这样很不利于我们编码
所以,国际标准化组织就站出来了,它们的目标是设计一种编码,包含直接上的每一种语言,这样在编码时,就可以不用再关注编码标准,使用这一款就可以了
它们的想法是,使用4个字节来编码,并且不管你的字符占不占的了4个字节,这样编码后,在解码时每次固定截取4个字节解码就行,也很方便
4个字节可以包罗42亿个字符,所以肯定是可以包括完世界上所有的字符的
那为什么我们使用的却不是UTF-32字符集呢?
原因就是太奢侈了,如世界上使用最多的语言英语,它的字符集一个只占一个字节,使用UTF-32之后,白白多了三个字节来存,这三个字节是直接浪费掉了,就为了对其4字节
所以UTF-32我们是不用的,而使用的是UTF-8
UTF-8字符集
UTF-8是Unicode采用可变长字符编码方案,共分为4个长度区:1个字节,2个字节,3个字节,4个字节
ASCII字符依旧是占一个字节,汉字则占3个字节
UTF-8的边长方案则是根据UTF-8二进制表来确定的
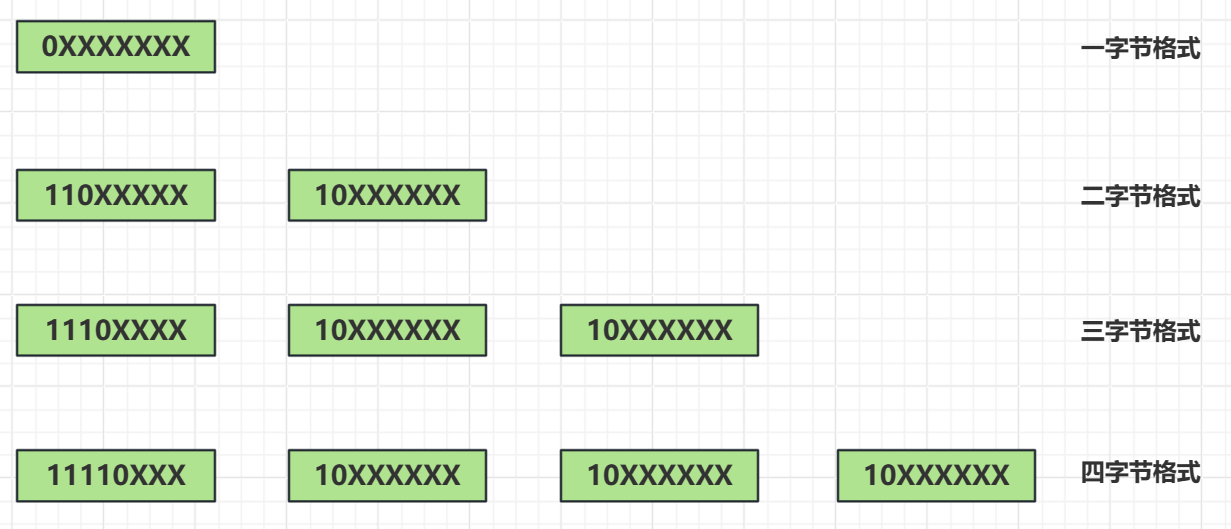
按照这个表,如果一个字符的编码满足一个字节,则它的首位一定是0
如果一个汉字,则它肯定是三个字节,则第一个字节为1110开始,第二个字节为10开始,第三个字节是从10开始
如一个汉字的编码值为:25105
则二进制为:110 001000 010001

则最后25105的UTF-8编码为: 11100110 10001000 10010001
注意点:
- 我们在程序开发时尽量使用UTF-8编码
- 使用哪种字符集就一定要使用此种字符解码
- 英文,数字一般不会乱码,因为绝大多数字符集都兼容了ASCII
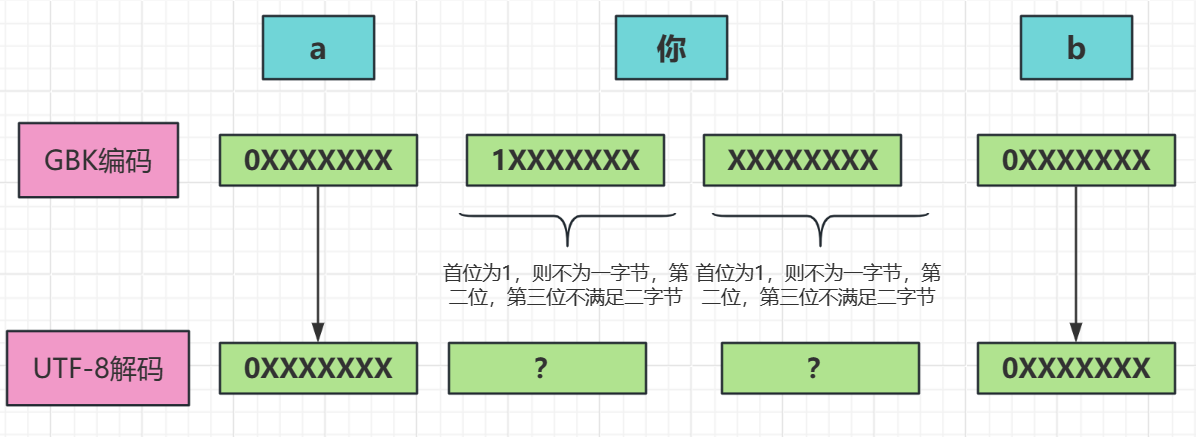
当使用GBK编码 a 你 b 时,解码使用UTF-8则会被解码成 a ? ? b
原因:
Java编码和解码
Java对字符进行编码:
byte[ ] getBytes();使用平台默认的字符集,对字符串进行编码,并且把它存在字节数组中
byte[ ] getBytes(String charsetName);使用指定的字符集 ,对字符串进行编码,并把它存在字节数组中
public static void main(String[] args) throws UnsupportedEncodingException { //byte[] getBytes()使用默认的字符集编码,默认是UTF-8 String s = "ac你"; byte[] b1 = s.getBytes(); System.out.println(Arrays.toString(b1)); //[97, 99, -28, -67, -96] 两个字符2字节,一个汉字三字节,一共五个字节 //byte[] getBytes(String charsetName) 使用指定的字符集编码 byte[] b2 = s.getBytes("GBK"); System.out.println(Arrays.toString(b2)); //[97, 99, -60, -29] 两个字符占2字节,一个汉字两个字节,一共四个字节 }
Java对字符进行解码:
String(byte[ ] bytes);使用平台的默认字符集解码,将字节数组转换为字符串
String (byte[ ] bytes,String charsetName); 使用指定的字符集解码,将字节数组转为String
//使用平台的默认字符集,UTF-8 //String(byte[ ] bytes) String s1 = new String(b1); System.out.println(s1);//ac你 //String(byte[ ] bytes,String charsetName) String s2 = new String(b2, "GBK"); System.out.println(s2);//ac你
三.IO流
I指的是Input,即为输入流,负责把数据写到内存中去
O指的是Output,即为输出流,负责将数据写出去
IO流主体有四种流:分别是字节输入流,字节输出流,字符输入流,字符输出流


其中IO流的体系分为字节流和字符流
它们这两个类下面的抽象类有:
字节流:InputStream,OutputStream
字符流:Reader,Writer

FileInputStream文件字节输入流
作用:以内存为基准,可以把磁盘文件中的数据以字节的形式读到内存中(文件字节输入流)
构造器:
public FileInputStream(File file)//传入一个文件
//public FileInputStream(File file) File file = new File("JavaSeImprove/static/test/test.txt"); InputStream is1 = new FileInputStream(file);
pulic FileInputStream(String path)//传入一个路径
//pulic FileInputStream(String path) InputStream is2 = new FileInputStream("D:\\其它\\Markdown\\Project\\JavaSeImprove\\static\\text\\test.txt");
方法:
public int read()每次读取流中的一个字节,并输出编码,当文件没有数据后输出-1
//pulic FileInputStream(String path) InputStream is2 = new FileInputStream("D:\\其它\\Markdown\\Project\\JavaSeImprove\\static\\text\\test.txt"); //读取一个字节,没有字节输出-1 //文本为 :abc int r1 = is2.read(); System.out.println((char) r1);//a int r2 = is2.read(); System.out.println((char) r2);//b int r3 = is2.read(); System.out.println((char) r3);//c int r4 = is2.read(); System.out.println(r4);//-1
像这样一行一行的读取是一种效率低的表现,我们完全可以使用循环读取,直接读取完一个文件
public static void main(String[] args) throws IOException { //pulic FileInputStream(String path) InputStream is2 = new FileInputStream("D:\\其它\\Markdown\\Project\\JavaSeImprove\\static\\text\\test.txt"); //读取一个字节,没有字节输出-1 //文本为 :abc int a; //循环读取字节 while ((a = is2.read()) != -1){ //由于流读取一次就没了,所以在比较循环时,先存储到变量中 System.out.print((char) a); //abc } is2.close(); }
注意:
- read()方法一个一个读字节性能很差
- 读取汉字会乱码,无法避免,(1/2字节原因)
- 流使用完了必须关闭,释放系统资源(io流的实现就是调用操作系统的接口,使用完了之后就释放,将接口管理交给系统)
一次读入多个字节
public int read(byte[ ] buffer)每次用一个字节数组去读取数据,返回字节数组读取了多少个字节,没有数据读时可返回-1
public static void main(String[] args) throws IOException { //拿取到操作文件的管道,并建立链接 FileInputStream is = new FileInputStream("static/text/test.txt"); //循环读取文件 byte[] buffer = new byte[8];//创建一次读取的容器 int len;//方法会返回字节大小,len用来存储 while ((len = is.read(buffer)) != -1){ String rs = new String(buffer,0,len);//将buffer中的字符进行解码,从字节数组的0开始,len结束 System.out.print(rs);//abcdefghijklmnopqrstuvwxyz } }
使用buffer字节容器来装可以快速的读取多个字节是一种快速方式,但是它也会有乱码的情况,毕竟中英文在UTF-8所占的字节不一致
而想要不乱码,可选的方式是一次将全部字节读取完,这样就可以避免乱码了
public static void main(String[] args) throws Exception{ //建立链接管道 FileInputStream is = new FileInputStream("static/text/test.txt"); //拿取到文件实例 File file = new File("static/text/test.txt"); //通过文件拿取到文件的大小 long length = file.length(); byte[] buffer = new byte[(int)length];//文件大小为long ,而数组仅支持int,所以强转一下 //由于buffer和文件等大,所以直接读就行,不需要循环读 int len; len = is.read(buffer); String rs = new String(buffer, 0, len); System.out.println(rs); //关闭流,不要忘了!!!! is.close(); }
一次读取完里面有个注意点
在通过文件对象拿取文件大小的时候,返回的大小类型是long,这是因为拿取为文件一般在硬盘上,所以大小会很大,一个文件几十G都是有可能的,所以long类型才可以装下
而在申请buffer数组时,很显然是在内存中,我pc的内存是16G很显然int容纳不了long类型的数组,所以new数组只支持int,这就是我们在代码中要强转一下的原因
此外,Java官方也知道,我们在使用IO流拿取一个文件时,大概率要一次读完,所以也提供了一个方法专门用于一次读取完字节
public byte[ ] readAllBytes() throw IOException 直接将当前字节输入流对应的文件对象的字节装到一个数组中返回
public static void main(String[] args) throws Exception{ //建立链接管道 FileInputStream is = new FileInputStream("static/text/test.txt"); //使用readAllBytes()方法读取完一个文件 byte[] buffer = is.readAllBytes(); String s = new String(buffer); System.out.println(s); //关闭流,不要忘了!!!! is.close(); }
但是要注意:此方法是JDK9才支持的方法,注意更新自己的JDK,不要万年1.8了
在读写文本方面,还是字符流更擅长,字节流更适合写非文本的数据
FileOutputStream文件字节输出流
作用:以内存为基础,把内存中的数据以字节的形式写入到文件中去
构造器:
public FileOutputStream(File file);创建字节输出流管道与文件对象接通
public FileOutputStream(String pathName);使用路径创建链接
public FileOutputStream(String pathNmae,boolean append);创建链接,是否在源文件后追加;默认false,即覆盖原文件
public static void main(String[] args) throws IOException { //使用文件输出流,填写的路径可以不存在,写出时自己创建 //创建文件对象和输出流的链接 FileOutputStream os = new FileOutputStream("static/text/testOut.txt"); //以文件的方式创建,且追加的形式写入文件 File file = new File("static/text/test.txt"); FileOutputStream osf = new FileOutputStream(file, true); }
文件写入的相关方法write():
public void write(int a );写一个字节出去
public static void main(String[] args) throws IOException { //使用文件输出流,填写的路径可以不存在,写出时自己创建 //创建文件对象和输出流的链接 FileOutputStream os = new FileOutputStream("static/text/testOut.txt"); os.write('a');//一个字符底层就是int os.write(99); //关闭流,好习惯要养成 os.close(); }
public void write(byte[ ] buffer );写一个字节数组出去
public static void main(String[] args) throws IOException { //使用文件输出流,填写的路径可以不存在,写出时自己创建 //创建文件对象和输出流的链接 FileOutputStream os = new FileOutputStream("static/text/testOut.txt"); byte[] buffer = "我爱中国,我爱世界!".getBytes(); os.write(buffer); //关闭流,好习惯要养成 os.close(); }
public void write(byte[] , int pos , int len);写限定长度出去
public static void main(String[] args) throws IOException { //使用文件输出流,填写的路径可以不存在,写出时自己创建 //创建文件对象和输出流的链接 FileOutputStream os = new FileOutputStream("static/text/testOut.txt"); byte[] buffer = "我爱中国,我爱世界!".getBytes(); os.write(buffer,0,12);//一个汉字3个字节 //关闭流,好习惯要养成 os.close(); }
文件复制
文件复制的思想是将已有的一个文件读入到内存,形成一个文件输入流
在利用这个流写出到目的位置,使用字节流就可以完成
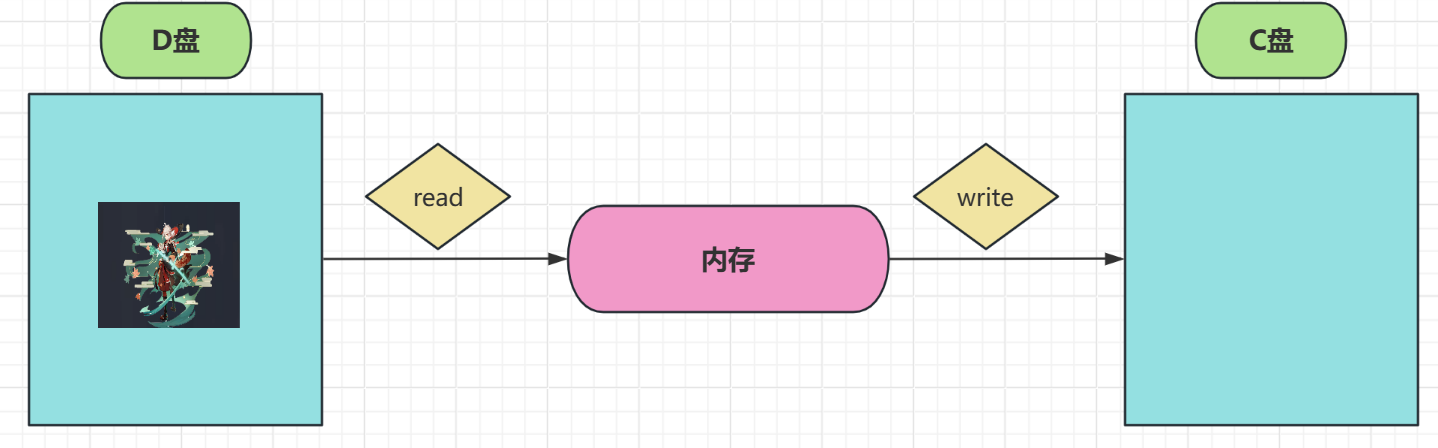
代码实现:
public static void main(String[] args) throws Exception { //拿取到文件管道 FileInputStream is = new FileInputStream("C:\\Users\\86173\\Pictures\\原神.photo\\fywy.jpeg"); //拿取到字节输入流 byte[] buffer = is.readAllBytes(); //拿取到文件输出管道 FileOutputStream os = new FileOutputStream("D:/fywy.png");//直接写出到D盘 //开始写出 os.write(buffer); //关闭流 is.close(); os.close(); }
总结:任何文件的底层都是字节,使用字节流来完成复制时肯定没问题的,当然最后解析时的文件类型必须一致
资源释放
在上面写的关闭输入输出流的方法中,是直接关闭的,这样直接将OS.close()和is.close()方法写在最后其实是不安全的
当资源被申请后,如果中间的代码出现意外,那么程序就直接终止了,而关闭流的方法根本来不及执行,所以流就没有被关闭
所以更高级的写法应该将关闭流也要纳入安全考虑
第一种写法:try -- catch -- finally
使用try - catch,都知道是用来捕捉代码异常的,最后这个finally的主要工作是,不管try{ }语句中的代码有没有报错,都会被执行
此外,当try{}语句块中,有终止程序时,如return,break等关键字,finally也会被执行一次,才会被终止
唯一不被执行的情况就是jvm宕机了,jvm都没了,是程序肯定都是执行不了的
所以,根据以上观点,我们可以将流的关闭放在finally代码块中
如下:
public static void main(String[] args) { FileInputStream is = null; FileOutputStream os = null; try { //拿取到文件管道 is = new FileInputStream("C:\\Users\\86173\\Pictures\\原神.photo\\fywy.jpeg"); //拿取到字节输入流 byte[] buffer = is.readAllBytes(); //拿取到文件输出管道 os = new FileOutputStream("D:/fywy.png");//直接写出到D盘 //开始写出 os.write(buffer); //关闭流,从内往外关 } catch (IOException e) { throw new RuntimeException(e); } finally { //流为空就不要关闭了,只有流存在才需要关闭 try { if (os != null) os.close(); } catch (IOException e) { throw new RuntimeException(e); } try { if (is != null) is.close(); } catch (IOException e) { throw new RuntimeException(e); } } }
finally语句块可以用于资源释放(专业做法)
但是,写法虽然很安全,但是代码很臃肿,看起来一大片的try--catch,很不优雅
既然我们想到了流关闭的安全问题,官方肯定也想到了,所以接下来看看官方推荐怎么做
第二种写法:try -- catch -- resource
这是jdk7之后的新增的写法,专门用于流的释放
在释放资源时,不在需要自己释放,而是由系统调用,因为资源都实现了AutoCloseable的接口

如上图:以后申请资源的时候,应当写道try()的括号里,在这个括号内的资源,当try语句块执行完后,会自动调用close()方法,就不再需要我们取手动关闭流
代码如下:
public static void main(String[] args) { try ( //拿取到文件管道 FileInputStream is = new FileInputStream("C:\\Users\\86173\\Pictures\\原神.photo\\fywy.jpeg"); //拿取到文件输出管道 FileOutputStream os = new FileOutputStream("D:/fywy.png");//直接写出到D盘 ){ //拿取到字节输入流 byte[] buffer = is.readAllBytes(); //开始写出 os.write(buffer); //关闭流,从内往外关 } catch (IOException e) { throw new RuntimeException(e); } }
这样写法释放资源,代码就很简洁,推荐使用
注意点:
- 括号中的只能时资源,对资源的定义是实现或简洁实现了AutoCloseable接口
- 当写入括号的是普通变量时,就会报错
- 括号中是资源,try语句块执行完成后,自动关闭这些资源

 浙公网安备 33010602011771号
浙公网安备 33010602011771号