JavaImprove--Lesson07--异常处理的两种方式,collection集合
一.Java异常处理的两种方式
Java的异常机制是一种处理程序中错误的方式,它包括异常的抛出、捕获和处理。异常是在程序运行过程中发生的异常事件,如数学运算中的除0异常、数组越界、空指针异常等。
在Java中,异常被视为一种对象,可以通过使用try-catch语句块来捕获和处理。当try块中的代码发生异常时,控制流将立即转到相应的catch块处理异常。如果没有对异常进行处理,则程序运行过程中会报错,程序也无法继续执行。
Java的异常机制还包括对异常类型的定义和管理。Java提供了一些内置的异常类,如IOException、NullPointerException等,这些类继承自Exception类。程序员也可以自定义异常类,以适应特定程序的需要。
在Java中,异常处理是一个重要的概念,可以帮助程序员更好地组织和控制程序的执行流程,确保程序的健壮性和稳定性。
在处理异常中一共有两个方式,
一种是从底层一层一层向上将异常抛出,然后交给最终的调用者处理
一种是直接在最外层捕获异常,也就是直接调用者来处理
一层一层的抛出
一层一层的抛出指的是在进行代码描绘的时候,是一个方法调用另外一个方法,当调用的底层方法有异常的时候,自己先不处理,而是交给上层调用者处理
一般这个最终调用者都是主方法(main)
值得注意的是,如果在main方法中你仍然选择抛出给上层处理,那么最终处理的就是JVM虚拟机,JVM处理的方式使用的就是try -- catch-- 来捕获异常的
示例:
public class ExceptionDemo { public static void main(String[] args) { //最外层调用者处理异常 try { getSimpleDate(); } catch (ParseException e) { throw new RuntimeException(e); } catch (FileNotFoundException e) { throw new RuntimeException(e); } } //向调用main方法抛出异常,ParseException,FileNotFoundException public static void getSimpleDate() throws ParseException, FileNotFoundException { SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"); Date parse = dateFormat.parse("2024-1-14 11:07"); System.out.println(parse); getPng(); } //向调用者getSimpleDate()方法抛出一个:找不到文件异常 public static void getPng() throws FileNotFoundException { FileInputStream stream = new FileInputStream("D:\\test.png"); } }
如上代码:
就是使用的一层一层的抛出,在子方法就是抛出异常,而主方法就捕获异常然后处理这个异常
虽然主方法也可以抛出到JVM,但是实际开发并不建议这么做,还是推荐在统一抛出到main方法,然后由main方法集中处理
最外层捕获
这一类的处理方式并不是直接异常导致的,而是底层方法的失误,导致上层调用者出现的异常
如:底层代码要求输入一个数字类型的数据,然而输入数字是可以正常运行的,而用户输入的是字符时就会报错,因为底层实现者并没有考虑到这块
所以就需要我们调用者来把这个运行时异常捕获并处理掉
示例:
public class ExceptionDemo2 { public static void main(String[] args) { //最外层调用者处理异常 try { getNumber(); //Exception in thread "main" java.util.InputMismatchException } catch (Exception e) { System.out.println(e); } } //向调用main方法抛出异常 public static void getNumber() { Scanner scanner = new Scanner(System.in); //正常输入数字是没问题的,但是输入的是字符就会报错 int number = scanner.nextInt(); System.out.println(number); } }
如上:
这种方式处理的是,底层未考虑到或者底层未处理的异常的,由于底层没有抛出异常,所以上层调用者是不可预知的,只有在开发中遇到了就处理掉就行了
二.单列集合
集合是一种容器,用于装数据的,类似数组,但集合的大小可变,开发中常常用到
集合大致可以分为两类,一类是单列集合,另外一列是双列集合
单列集合顾名思义,它存放数据是以单个为一体的,各个数据之间没有关联
双列集合,则是两个数据为一体的,它们之间是有关联的,这也是我们常说的键值对
集合类是用于存储和操作对象组的类库。这些类允许开发人员存储和检索数据,以实现诸如排序、搜索、过滤和映射等功能。
Java集合类主要分为两大类:Collection(单列集合)和Map(双列集合)。

List系列集合的特点:
添加元素是有序的,可以重复添加,有索引
Set系列集合的特点:
添加元素是无序的,不重复,无索引
Collection接口的一些方法是直接被子类所继承的,所以我们需要先了解单列集合的祖宗类有那些方法
1. public boolean add(E e);
往集合中添加元素
Collection<String> list = new ArrayList<>(); //public boolean add(E e); //添加元素,成功返回ture list.add("java"); list.add("mysql"); list.add("spring"); System.out.println(list); //[java, mysql, spring]
2.public void clear();
清空集合中的元素
//public void clear(); //清空集合中的元素 list.clear(); System.out.println(list);//[]
3.public boolean isEmpty()
判断集合中的元素是否为空
//public boolean isEmpty() //判断集合是否为空,为空则返回ture,反之则返回false boolean empty = list.isEmpty(); System.out.println(empty);//ture
4.public int size();
判断集合的大小
//public int size(); //获取集合大小 int size = list.size(); System.out.println(size);//3
5.public boolean contains(Object obj);
判断集合中是否包含某个元素
//public boolean contains(Object obj); //判断集合中是否包含某个元素,包含则返回ture boolean contains = list.contains("java"); System.out.println(contains);//ture
6.public E boolean remove(E e);
删除某个元素
//public E boolean remove(E e); //删除某个元素,如果有多个重复元素,删除查找到的第一个 boolean remove = list.remove("java"); System.out.println(remove);
7.public Object[ ] toArray()
将集合转换为数组
//public Object[] toArray() //把集合替换成数组 String[] array = list.toArray(new String[list.size()]);//转换为字符串数组 System.out.println(Arrays.toString(array)); //[mysql, spring]
8.public boolean addAll(E extend Collection e)
主调集合复制参数集合中的数据到主调集合中
//public boolean addAll(E extend Collection e) //将集合中的元素全部复制到另一个集合中 ArrayList<String> list1 = new ArrayList<>(); list1.add("java"); list1.add("mybatis"); list.addAll(list1); System.out.println(list);//[mysql, spring, java, mybatis]
三.单列集合的遍历
集合的遍历是不能使用for循环的,因为大多数集合都是无序的,且是无索引的,使用for循环必须要有严格的索引要求的
- 迭代器
- For增强
- Lambda表达式
迭代器
Java中的迭代器(Iterator)是一种设计模式,它提供了一种遍历集合对象元素的方法,而不需要知道集合对象底层的表示方式。迭代器是一种对象,它可以遍历并选择序列中的对象,而开发者不需要了解该序列的底层结构。
迭代器通常用于遍历数组、列表、字符串或其他可迭代的数据结构。通过使用迭代器,开发人员可以逐个访问集合中的元素,而无需了解集合的底层表示方式。这有助于降低代码的复杂性,并使代码更易于维护。
迭代器是用来遍历集合的专用方式,数组是没有迭代器的,Java中迭代器的代表是Iterator
使用迭代器首先要创建一个Iterator对象,它可以理解为指针,且是指向集合的第一个元素的指针
使用hasNext()方法可以判断判断当前位置是否有元素存在
next()方法可以取出当前元素,并且将指针移到下一个位置
//使用迭代器遍历 //1.创建迭代器对象,目标是指向集合的第一个元素 Iterator<String> iterator = list.iterator(); //2.使用hasNext()和Next()组合的while循环遍历集合 while(iterator.hasNext()){//判断当前位置是否有元素,有则可以执行循环 System.out.println(iterator.next());//取出当前元素,并把指针指向下一个元素 }
For增强
For增强是这三个方法中遍历集合最简单的,也是推荐使用的,并且它还可以遍历数组
Java中的增强for循环(也称为for-each循环)是一种简化数组和集合遍历的语法结构。它的作用是提供一种更简洁、更清晰的遍历方式,而不需要使用传统的for循环语法。
增强for循环可以遍历所有实现了Iterable接口的集合,以及数组类型。在循环中,每次循环会自动获取下一个元素,并将该元素存储在指定的变量中,可以直接对该元素进行操作。
相比传统的for循环,增强for循环具有简洁、清晰的语法结构,使代码更加优雅。
格式:
for (元素类型 元素变量:数组或集合){
循环体
}
//使用for增强来遍历集合 for(String s:list){ System.out.println(s); }
如上代码,真的很简洁,推荐使用
Lambda表达式
从JDK8以后之后,提供了一种更简单,更直接的遍历集合的方式
需要使用到Collection的方法forEach()来完成
default void forEach(Consumer<? super T> action)
其中Consumer是一个函数式接口
它其中的方法就是陆续取集合中的元素
//使用Lambda表达式来遍历(原接口) list.forEach(new Consumer<String>() { @Override public void accept(String s) { System.out.println(s); } }); //lambda表达式优化 list.forEach((s)-> System.out.println(s)); //方法引用优化 list.forEach(System.out::println);
值得注意的是consumer接口的实现类依旧使用的是for增强来遍历的集合
小实例:利用集合存储自定义对象
public class CollectionDemo2 { public static void main(String[] args) { //创建一个Collection集合对象 Collection<Student> list = new ArrayList<>(); //添加对象在其中 list.add(new Student("李华","201",19)); list.add(new Student("王明","201",18)); list.add(new Student("李浩","202",22)); //For增强遍历:简单,快捷 for(Student s : list){ System.out.println("学生姓名:"+s.getName()+ ",学生班级:"+s.getClassName()+ ",学生年龄:"+s.getAge()); //学生姓名:李华,学生班级:201,学生年龄:19 //学生姓名:王明,学生班级:201,学生年龄:18 //学生姓名:李浩,学生班级:202,学生年龄:22 } } } class Student{ private String name; private String className; private int age; public Student(String name, String className, int age) { this.name = name; this.className = className; this.age = age; } public String getName() { return name; } public void setName(String name) { this.name = name; } public String getClassName() { return className; } public void setClassName(String className) { this.className = className; } public int getAge() { return age; } public void setAge(int age) { this.age = age; } @Override public String toString() { return "Student{" + "name='" + name + '\'' + ", className='" + className + '\'' + ", age=" + age + '}'; } }
四.List特有方法
List接口是ArrayList和Linked集合的父接口
所以List有的方法,这两个实现类也会有,所以使用的时候就照葫芦画瓢就行了
List集合是支持索引的,所以有很多索引相关的方法,当然Collection拥有的方法,它肯定也有
1.public void add(int index ,E element);
根据索引增加元素
//public void add(int index ,E element); //在某个索引处插入元素 list.add(2,"vue"); System.out.println(list); //[java, mysql, vue, Html, css]
2.public E remove(int index);
根据索引删除数据,并且返回被删除的数据
//public E remove(int index); //根据索引删除元素,并且返回被删除的元素 list.remove(2); System.out.println(list);//[java, mysql, Html, css]
3.public E get(int index);
根据索引取值
//public E get(int index); //根据索引取集合中的元素 String s = list.get(2); System.out.println(s);//Html
4.public E set(int index,E element);
改变传入索引中的值,并且返回旧的值
//public E set(int index,E element); //改变索引的值,并返回旧值 String html = list.set(2, "html"); System.out.println(html);//Html System.out.println(list);//[java, mysql, html, css]
List集合的特有遍历方式
我们说过list集合是线性的,有序的(存取顺序),且是有索引的,所以它除了可以使用Collection接口的三种遍历方式外
还可以使用for循环来遍历,因为List系列都是有索引的
for (int i = 0; i < list.size(); i++) { System.out.println(list.get(i)); //java //mysql //html //css }
ArrayList的实现原理
- 利用无参构造创造集合,会在底层创建一个默认长度为0的数组
- 添加一个元素时,会在底层创建一个新的长度为10的数组

- 存满时,重新申请数组扩容1.5倍,然后把数据移动过去,新增元素在新数组后面

- 如果一次添加多个元素,扩充1.5倍还不够,则创建新数组以实际长度为准

LinkedList实现原理
通过拆分LinkedList集合的英文单词也可以看出来它是由什么数据类型构造的
Linked即链表,所以它的实现底层是利用链表实现的
在数据结构中,常见的链表类型有两种,一种是单链表,一种是双向链表
单向链表实现比较简单,只用单个方向,而双向链表则是可以正向反向检索。
链表一个空间存储具体的数据,另外一个空间存储下一个节点的地址,双向链表则是两个空间存储地址
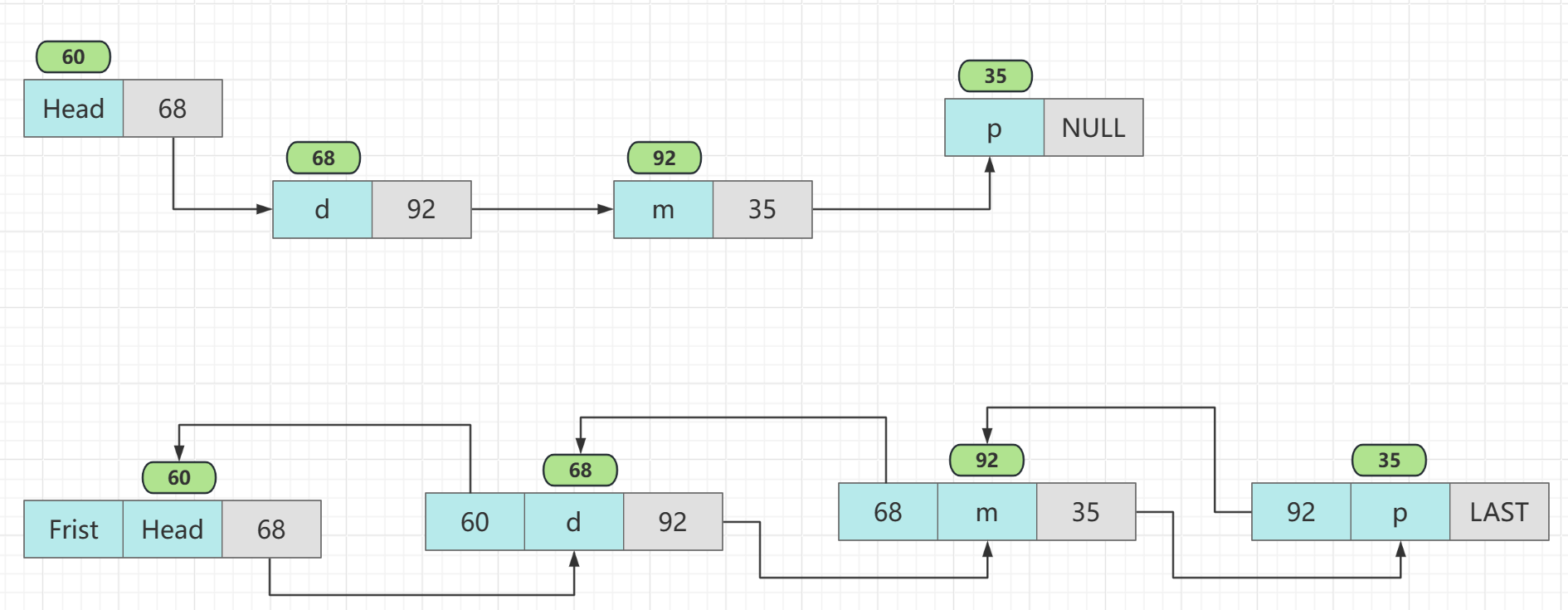
在LinkedList结构中,使用的是双向链表结构。所以LinkedList的特点就是:
- 首尾节点操作敏感(操作快)
- 删除新增节点迅速
示例:利用LinkedList构造队列
队列是一种先进先出的数据结构,所以构造队列只需要删除数据在队首,新增数据在队尾就可以完成
刚好LinkedList是一种首尾操作敏感的数据结构,所以做队列很可以
LinkedList<String> list = new LinkedList<>(); //常见LinkedList方法 //public void addFirst(E e) 在头节点插入元素 list.addFirst("first"); //public void addLast(E e) 在尾节点插入元素 list.addLast("last"); //public E getFirst() 得到第一个节点值 list.getFirst(); //public E getLast() 得到最后一个节点值 list.getLast(); //public E removeFirst() 删除第一个节点,并且返回此值 list.removeFirst(); //public E removeLast() 删除最后一个节点,并且返回此值 list.removeLast();
构造队列,出队与入队:
LinkedList<String> queue = new LinkedList<>(); //入队 queue.addLast("1"); queue.addLast("2"); queue.addLast("3"); //出队 queue.removeFirst(); //"1" System.out.println(queue); //"2" "3"
五.Set集合
set集合的特点:无序,添加数据的顺序和取出数据的顺序是不一致的,不重复,无索引
HashSet:无序,不重复,无索引
LinkedHashSet:有序,不重复,无索引
TreeSet:排序,不重复,无索引
Set集合的常用方法也是单列集合中的,并没有其它独有的set方法,所以不过多赘述了
Set<Integer> set = new HashSet<>(); set.add(123); set.add(365); set.add(894); set.add(422); for (Integer s : set) { System.out.println(s); }//422 123 365 894
HashSet底层实现原理
HashSet实现是基于Hash表的思想来实现的
通过对具体的数字进行哈希值计算,最后确定这个值存放的位置
Hash值是一个int类型的变量,Java每个对象都有一个hash值,通过调用HashCode()方法拿到
对象Hash值的特点:
同一个对象调用HashCode获得的值是一样
不同对象调用绝大数情况是不同的,但也会有相同的情况(哈希碰撞)--int类型一共可容纳42亿左右的值,而当有45亿个对象时,必然发生哈希碰撞
在JDK8之前,HashSet实现方式是通过数组+链表的方式实现的,而JDK8之后都是使用数组+链表+红黑树实现的
JDK8之前
- 在底层实现中先实现一个长度为16的数组,默认加载因子0.75,
- 使用元素的哈希值对数组长度取余,计算出对应存入的位置
- 判断当前位置是否为NULL,如果是null直接存入
- 不为Null,则表示有数据,调用equals方法进行比较,相等,则不存入(set无重复),不相等,存入数组
- jdk8之前,新元素存入数组,占老元素位置,老元素挂下面;jdk8之后,直接挂在老元素后面

当数组长度被占满0.75(默认加载因子)倍后,即16*0.75 =12,就会扩容数组的一倍,16*2 =32
为什么是占满0.75倍就扩容而不是占满后扩容呢?因为当占12个空间后,大概率这12个空间下已经有挂着的数据了,加一起可能已经超过16个了
JDK8之后
JDK8之后HashSet的实现和JDK8实现多了一个红黑树,在少量数据上依旧是数组+链表
当满足:链表长度超过8,且数组长度 大于等于64,自动将链表转为红黑树
注意:是将链表转为红黑树,而不是整体都是红黑树结构,数组表还是存在的,此时应当满足,数组长度 >= 64了
当链表大于8时,使用红黑树来存储,检索更加高效

拓展
当我们希望两个内容相同的对象,在存储的过程HashSet的过程中,不重复存入
在直接进行存入中,由于对象的初始HashCode是随机的,所以即使内容相同的对象,它们的Hashcode都是不一样的,所以需要更改此类的HashCode方法和equals方法
@Override public boolean equals(Object o) { if (this == o) return true; if (o == null || getClass() != o.getClass()) return false; Student student = (Student) o; return grade == student.grade && Objects.equals(name, student.name) && Objects.equals(sec, student.sec); } @Override public int hashCode() { return Objects.hash(name, sec, grade); }
重写后,让此对象更具自己的属性来构造Hashcode,就能保证相同的属性值产生相同的HashCode
Student s1 = new Student("msf", "boy", 18); Student s2 = new Student("msf", "boy", 18); System.out.println(s1.hashCode()==s2.hashCode());//true
LinkedHashSet底层原理
LinkedHashSet的主要特点是有序,不重复,无索引
这里的有序指的是添加元素的顺序,并不是对元素排序
LinkedHashSet依旧是使用的数组+链表+红黑树,但是与HashSet不同的是,LinkedHashSet有一个双链表负责链接存入的元素,也就是首尾指针指向第一个元素和最后一个元素
使用双链表的机制就可以做到存储数据后还能存储插入数据的顺序,由此可知存储数据是哈希表,而存储顺序是双链表;但是这样的方式肯定是更消耗空间的,适用于要求更严苛的情况
如下图:

如图:LinkedHashSet除了要保存链表结构,还有存储数据的顺序,通过头尾指针可以快速的定位到这些数据的位置
所以在遍历数据时,HashSet时直接遍历hash表,从0号位置开始,然后链表,而LinkedHashSet则是从头指针开始,到尾指针结束,可记录到数据的插入顺序,但是空间开销比HashSet大
TreeSet底层实现原理
Treeset的特点是排序,不重复,无索引
这里的排序指的是按照某种排序规则进行升序的,实现的数据结构就是红黑树
红黑树是一种很复杂的数据结构,在了解红黑树前必须了解树结构,详细了解红黑树可以看数据结构与算法之二叉树
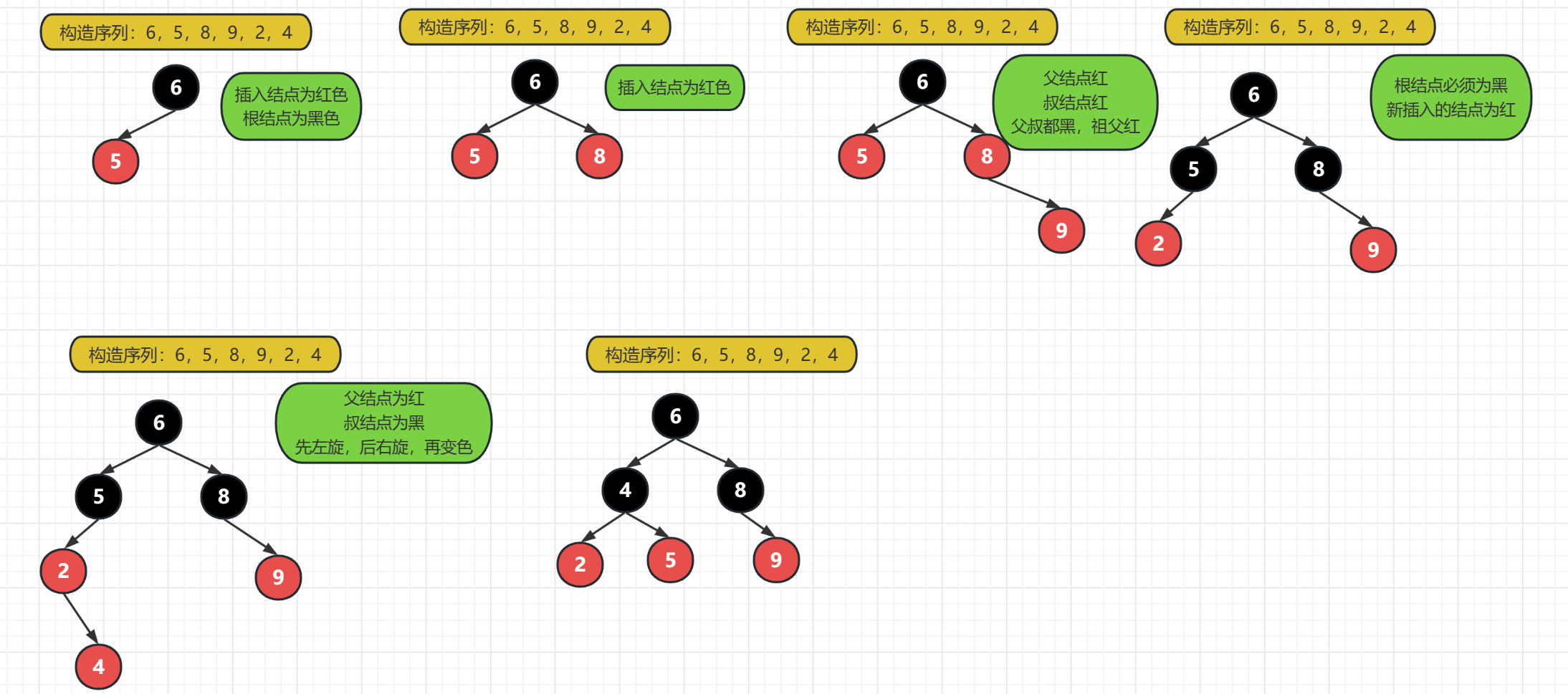
注意点:在排序基本类型时,TreeSet可以根据数据大小进行排序,而对象结构是不能直接进行排序的,因为TreeSet不知道排序规则
所以针对对象比较TreeSet可以使用两种方式来解决:
- 实现Comparable接口
@Override public int compare(Student o1, Student o2) { return o1.grade-o2.grade; }
- 调用TreeSet集合有参构造器,设置Comparator
Set<Student> s = new TreeSet<>(new Comparator<Student>() { @Override public int compare(Student o1, Student o2) { return o1.getGrade()-o2.getGrade(); } }); //Lambda表达式优化 Set<Student> s = new TreeSet<>((o1, o2) -> { return o1.getGrade()-o2.getGrade(); });
集合并发的修改异常
使用迭代器遍历集合时,又同时删除集合的数据,程序就会发生修改异常的错误
ArrayList<String> list = new ArrayList<>(); list.add("吴一凡"); list.add("菜许坤"); list.add("顶正"); list.add("小一"); list.add("黄明浩"); list.add("刘一博"); System.out.println(list);//[吴一凡, 菜许坤, 顶正, 小一, 黄明浩, 刘一博] Iterator<String> iterator = list.iterator(); while (iterator.hasNext()){ String name = iterator.next(); if (name.contains("一")){ list.remove(name); } }
如上代码:需要删除名字中带“一”的人,使用迭代器删除,但是会报错并发修改异常.ConcurrentModificationException
并发即多线程在操作,我们在使用迭代器的时候,进行删除操作是一条线程,而Collection集合也有一个线程在维护集合中的数据
如ArrayList就是当数据有删除时,就会向前进行移动,以确保数组时充盈的
使用for循环就可以明显看出来
ArrayList<String> list = new ArrayList<>(); list.add("吴一凡"); list.add("菜许坤"); list.add("顶正"); list.add("小一"); list.add("刘一博"); list.add("黄明浩"); System.out.println(list);//[吴一凡, 菜许坤, 顶正, 小一, 黄明浩, 刘一博] for (int i = 0; i < list.size(); i++) { if (list.get(i).contains("一")){ list.remove(list.get(i)); } } System.out.println(list);//[菜许坤, 顶正, 刘一博, 黄明浩]
如上,使用for循环可以看到,我们少删除了一个人名,这就是在删除小一时,集合向前移动了一格,导致刘一博在已经删除过的位置,下次循环就跳走了
所以解决方式可以在有删除动作的情况下,执行一个i--,i--就到来删除的前一个元素,在配合for循环的i++就是当前位置,则可以删除掉刘一博
ArrayList<String> list = new ArrayList<>(); list.add("吴一凡"); list.add("菜许坤"); list.add("顶正"); list.add("小一"); list.add("刘一博"); list.add("黄明浩"); System.out.println(list);//[吴一凡, 菜许坤, 顶正, 小一, 黄明浩, 刘一博] for (int i = 0; i < list.size(); i++) { if (list.get(i).contains("一")){ list.remove(list.get(i)); i--; } } System.out.println(list);//[菜许坤, 顶正, 黄明浩]
知道了问题的出现,迭代器则可以通过另外一种方式,是官方的一种方法,使用迭代器自带的删除,删除元素,就不会报错了
在迭代器的底层也是执行了类似i--的操作,让指针回来了
ArrayList<String> list = new ArrayList<>(); list.add("吴一凡"); list.add("菜许坤"); list.add("顶正"); list.add("小一"); list.add("刘一博"); list.add("黄明浩"); System.out.println(list);//[吴一凡, 菜许坤, 顶正, 小一, 黄明浩, 刘一博] Iterator<String> iterator = list.iterator(); while (iterator.hasNext()){ String name = iterator.next(); if (name.contains("一")){ iterator.remove(); } } System.out.println(list);//[菜许坤, 顶正, 黄明浩]
注意点:其它的遍历方式是不能解决这个并发删除异常的,forEach不能拿到迭代器对象,for增强拿不到下标,所以解决方式只能是迭代器,Set系列不能用for循环

 浙公网安备 33010602011771号
浙公网安备 33010602011771号