《数据结构》概念复习一
1.考前必背的知识点(干货)
数据(Data):
数据是描述客观事物的数值,字符以及能输入到计算机中且能被处理的各种符号集合。
数据元素(Data Element):
数据元素是组成数据的基本单位,是数据集合的个体,在数据结构中作为一个整体进行考虑和处理,一个数据元素由多个数据项构成
数据对象(Data Object):
数据对象是性质相同的数据元素的集合,是数据的一个子集,数据对象通常是指的一个集合,并不是单个的数据,如正整数集合,字符集合,或者是字符、数字集合
数据结构(Data Structure):
数据结构指的是相互之间存在的一种或多种特定关系的数据元素集合,数据对象中的数据元素并不是孤立的,而是存在某种联系,如线性关系,非线性;
例如一张师生表,一个老师对应多个学生,是一对多的关系,也就是非线性关系,所以这张师生表可以用非线性的数据结构来表示,树形结构就可以
数据类型(Data Type):
数据类型是一组性质相同的值的集合已经定义在这个值的集合上的一组操作的总称,高级语言中数据类型就是已经实现的数据结构的实例。
数据类型一共可以分为两大类:一类是非结构的原子类型(基本数据类型:int,float,char),一类是结构类型,它是可以分解的,可以分解成基本类型或者另一结构类型,多由基本类型组成的一个集合(如数组,结构体)
关系:数据项(单个数据值) ⊆ 数据元素 (一列数据)⊆ 数据对象(一张表对象)
数据结构描述数据对象的关系,一对多?一对一?多对多?
------
抽象数据类型(Abstract Data Type):
抽象数据类型简称ADT,是指一个数学模型,以及定义在该模型上的一组操作。可以变相理解为结构体和抽象类
ADT<ADTM名>
{
数据对象:<数据对象的定义>
数据关系:<结构关系的定义>
基本操作:<基本操作的定义>
}ADT<ADT名>
数据的逻辑结构:这里的关系是数据元素的逻辑关系
- 集合结构:结构中的数据元素之间除了同属于一个集合的关系外,无任何其它关系。
- 线性结构:结构中的数据元素之间存在着一对一的线性关系
- 树形结构:结构中的数据元素之间存在着一对多的层次关系
- 图形结构:结构中的数据元素之间存在着多对多的任意关系
倒背如流的公式,是个计算机人都能知道的公式:数据结构 + 算法 = 程序
数据结构是指对数据即操作对象的描述,即数据的类型和组织形式,算法则是对操作步骤的描述。
算法具有以下特性:
- 有穷性:对于任意一组合法输入,在执行完有穷步骤之后一定能结束,简记:不能有死循环
- 确定性:算法的每一步都有确切的定义,程序的每个入口对于单个进行环境都能有一条路径执行,简记:算法自上而下执行路径无歧义
- 可行性:算法都是可行的,都可以通过已经实现的基本操作运算有限次实现,简记:程序是正常终止的,无结束
- 有输入:算法对输入考察比较少,可以无输入,也可以有输入
- 有输出:算法应当有一个或多个输出,当有输入是,它和输入应当是有关系的量值
算法的评价标准:
- 正确性:程序对于合法输入都有确切的输出,程序不含语法错误,对于苛刻的输入也能处理
- 可读性:指的是代码写出来后,被其它人理解的程度,好的算法要易于理解,但并不代表代码简单,而是代码逻辑要易于理解,苦涩难懂的代码难于后期维护
- 健壮性:算分的逻辑结构强大,能抵御非法输入,处理错误的方式是通过返回标志,而不是程序中断
- 高效率与低存储:算法的运行速度要快,优化冗余的代码。但是存储空间尽量要优化,往小内存发展,但这两者往往是冲突的,要么时间换空间,要么空间换时间
数据结构是一门研究非数值计算的程序设计问题中的操作对象以及它们之间的关系和运算的学科。重点在于关系和运算,这是在概念中经常提到的两个关键词,一想到数据结构这两个词就是其代名词。
计算程序的运行的时间和空间开销并不需要在代码运行之后才能计算,而是需要运行前就要分析的,根据代码的循环层数可以很清晰的分析出代码的时间开销,根据代码当前初始化的空间大小和运行时动态申请的大小也能计算出空间开销。
算法的时间复杂度也不和计算机的硬件,软件,环境有关,因为这些因素会影响程序的运行时间,但是时间复杂度是在程序运行前预估的,程序还并未运行过,所以对其不产生影响。
线性结构的顺序存储结构是一种随机存取的存储结构,线性表的链式存储结构是一种顺序存取的存储结构。
原因:
- 顺序存取:就是存取第N个数据时,必须先访问前(N-1)个数据 (list)
- 随机存取:就是存取第N个数据时,不需要访问前(N-1)个数据,直接就可以对第N个数据操作
数据结构由数据的逻辑,存储,运算构成。
逻辑结构:数据对象中的数据元素之间的相互关系(逻辑关系),即从逻辑关系上描述数据,它与数据的物理存储无关,是独立于计算机的存储的。(如,一对多,多对一等)
关系:集合,线性表,树,图 ⊆ 线性结构和非线性结构 ⊆ 逻辑结构
物理结构(存储结构):指的是数据在计算机中的真实存储位置,数据元素的存储结构形式主要有两种:顺序存储(一片连续的物理地址),链式存储(间断的几片物理地址)
关系:顺序表,链表,hash表 ⊆ 顺序结构,链式结构,索引结构,散列结构 ⊆ 物理结构
线性结构:线性结构作为最常用的数据结构,其特点是数据元素之间存在一对一的线性关系,包括逻辑结构表示也是一对一的,常见的结构说就是顺序表和链式表
非线性结构:各个元素不在保持在一个线性结构中,也就是逻辑关系不是一对一了,而是一对多或是多对多,具有明显的层次关系,这使得线性表很难表示这种特点,所以延伸出树和图
线索二叉树:在使用链表表示二叉树时,总有n+1个指针域是没有用到的,而且这种表示方法使得每个子结点很难找到它的父结点,所以综合以上两点,可不可以把这n+1的空指针域也用起来,用来指向它的父结点呢?
在线索二叉树中,使用两个标志记号:lTag和rTag用来表示此结点的左右结点是子树还是父结点,0表示装的是孩子结点,1表示装的父结点,当为1时,需要通过遍历的方式来装填父结点,由于左右子树在相同的遍历方式下,父结点的位置不一样,所以会分开遍历装值。
标志位为1且在左子树,则采用先序遍历记录父结点,参考:“根节点--左子树--右子树”,利用pre指针,每次延后指向结点,当遍历到左子树结点时,pre指针刚好在根节点位置
标志位为1且在右子树,则采用后序遍历记录父结点,参考:“左子树--右子树--根节点”,也是用pre指针延后指向结点,只不过要注意现在的遍历方式,父结点在右子树后面,所以pre现在才代表右子树,而遍历的结点是根结点
哈夫曼树:指的是带权路径长度最短树
完全图:图中有n个顶点,n(n-1)/2条边的无向图称为完全图
有向完全图:图中有n个顶点,n(n-1)条弧的有向图被称为有向完全图
邻接表表示图,对于有n个顶点和e条边的无向图,采用邻接表存储,需要n个表头结点和2e个表结点
最小生成树:连通网中所有生成树中权值之和为最小的生成树,图的一个极小连通子图,含有图中的全部n个顶点,但只有足以构成一棵树的n-1条边,显然生成树不唯一,可以有多棵
判断一个有向图是否有回路:求关键路径法和拓扑排序
拓扑排序的判别条件是:有向无环图
AOV网中,结点表示活动,边表示优先关系,AOE网中,结点表示事件,边表示活动
2.问答题(理解)
------算法和程序的区别与联系是什么?
- 算法是半形式化的语言,侧重点在于描述程序的执行逻辑,一般用类C来描述;程序是形式化的语言,它能直接在计算机上运行。
- 算法是基本运算及规定的运算顺序所构成的完整解题步骤;程序则是计算机命令的有序集合。
- 程序不会满足算法的所有要求,但是局部程序可能会满足,如算法的有穷性,在服务器端是不适用的,服务器对于请求必须是循环响应,可以说服务器端必须是一个死循环
- 算法需要程序来实现其定义的功能;程序则需要算法思想来作为灵魂
- 程序 = 数据结构 + 算法
------什么是数据结点?什么是存储结点?它们有什么关系?
数据结点主要指是数据集合中的数据元素,表示具有相同属性或特征的数据;数据结点主要包括两个域:数据域和指针域,数据域存储实际的数据,指针域则是存储指向其它结点的指针,这些指针可以表示数据之间的关系。
存储结点是存放数据的内存单元,不仅要存储数据内容,还要存储这些结点之间的关系,换言之,它是数据结构在内存中的表示,它包含了数据结构的实际内容和相应的逻辑结构
数据结点和存储结点之间的关系是密切的,最明显的就是其映射关系,在实际的数据结构中,一个数据结点可能对于一个或多个存储结点,如:链表中一个数据结点就对应一个存储结点,而在树形中一个数据结点就对应多个存储结点
------为什么说链式存储之所以既提高了存储的利用率又降低了存储的利用率?
优点:
- 动态分配:链式存储根据需求动态开辟空间的大小和释放空间,提高物理存储的利用率
- 便于扩充:链式存储可以方便的增加和删除结点,使得数据易于扩充
- 便于维护:链式存储结点具有指针,可以方便的维护数据结构
缺点:
- 存储空间利用率低:每一个链表结点都需要包含数据结点和指针结点,用于指向下一个结点
- 访问速度慢:每次访问数据都需要从头结点开始访问,然后依次向后访问
------树型结构是一种常见的数据结构,列举几个数据之间具有树型结构的实际例子?
- 文件系统:文件系统采用了树型结构来组织和管理文件和目录。在根目录下,可以有多个子目录,每个子目录下又可以有多个子目录,这样可以很方便地查找和管理文件。
- 数据库系统:数据库系统采用了树型结构来组织和管理数据。在数据库中,表与表之间可以通过外键建立联系,从而形成树型结构。
- HTML文档:HTML文档采用了树型结构来组织和管理网页内容。在HTML文档中,每个元素都可以看作是一个节点,节点之间可以通过标签建立联系,从而形成树型结构。
- 操作系统:在操作系统的目录结构中,采用了树型结构来组织和管理文件和目录。在根目录下,可以有多个子目录,每个子目录下又可以有多个子目录,这样可以很方便地查找和管理文件。
------数据运算是数据结构的一个重要方面。举例子说明两个数据结构的逻辑结构和存储方式相似,只是对运算的定义不同,因而两个数据结构具有明显不同的特性,是两种不同的数据结构?
线性表:其元素之间存在着一对一的关系,在顺序存储的线性结构中,数据元素是连续的,每个元素都有固定的位置,可以通过索引直接访问,对于数据的存取操作都是随机的,可以通过索引直接操作结点元素
栈:它也是线性结构,特点是先进后出(FILO),栈的存储也是顺序存储,但是其操作出栈和入栈都是可以通过下标也索引操作节点,但是这样做的意义不大,它的运算操作更侧重于只对栈顶元素操作,插入新元素和删除元素都在栈顶
综上,正因为二者都是线性顺序存储结构,但是操作上,线性表都是通过索引直接操作任意节点,而栈只能在栈顶操作,使得线性表的自由运算和栈的约束运算的区别间接导致这也成为了两种数据结构。
------描述以下四个概念的区别:头指针变量,头指针,头结点,首结点,(第一个结点)?
头指针变量:头指针变量是一个变量,它存储了链表头结点的地址,是用户自定义的变量,用于存储头结点的位置
头指针:指向链表头部的指针,它指向链表的第一个结点,用它来访问链表的第一个结点并且可以访问整个链表
头结点:链表的第一个结点,它没有前驱结点,头结点通常包含一些元数据,如链表的结点个数,头结点使得链表的插入和删除都更加的方便
首结点:链表的起始点,它通常包含链表的第一个数据元素,并对下一个结点具有指针。
简而言之,头指针变量是存储头节点地址的变量,头指针是指向头节点的指针,头结点是链表的第一个节点(同时也是头节点),而首结点是与头结点相邻的第一个节点。
------简述线性表的两种存储结构有哪些主要优缺点及各自适用的场合?
顺序存储结构的优点:无需为元素中的逻辑关系额外开辟空间,可以通过索引快速取数据元素,其缺点是插入和删除需要有大量的删除,并且占用固定的大小,无论是否有足够的数据,对于数据有序且不常改动的场合适用
链式存储结构的优点:优点是插入删除很方便,只需要修改指针域;缺点是需要为逻辑结构单独开辟空间,但是结点间可以动态开辟空间,内存利用率高,链式存储适合于需要频繁插入和删除的操作的场合
------什么是线性表中的静态链表?
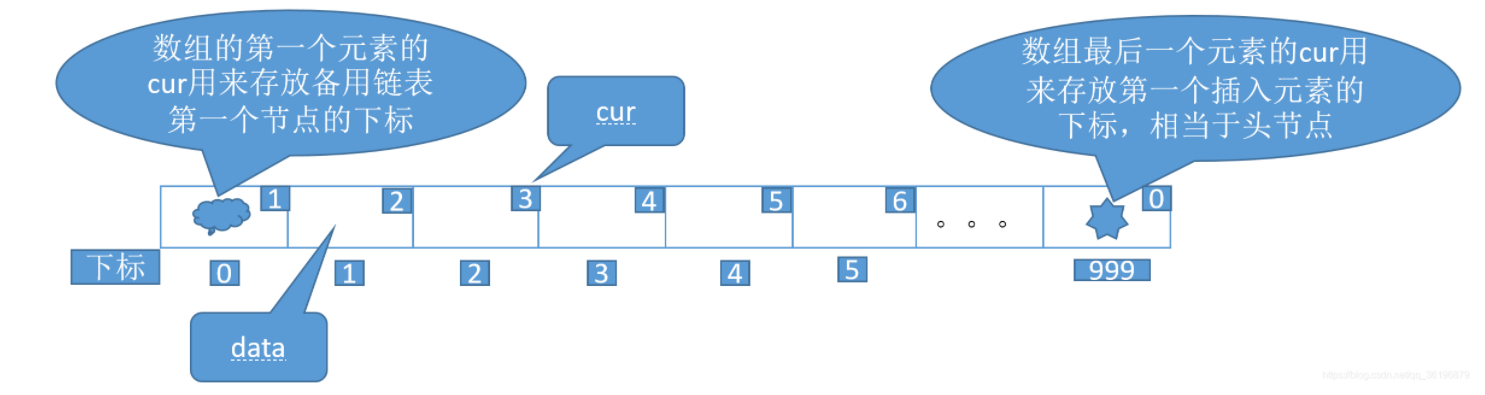
静态链表,用一个数组来模拟链表存储元素,数组中的元素都是由两个数据域组成, data 和 cur。也就是说,数组的每个下标都对应一个data和一个 cur。
数据域data,用来存放数据元素,也就是通常我们要处理的数据;而游标 cur 相当于单链表中的 next 指针,存放该元素的后继在数组中的下标。
我们把这种用数组描述的链表叫做静态链表,这种描述方法还有起名叫做游标实现法。
另外我们对数组第一个和最后一个元素作为特殊元素处理,不存数据。我们通常把未被使用的数组元素称为备用链表。
而数组第一个元素,即下标为 0 的元素的 cur 就存放备用链表的第一个结点的下标;而数组的最后一个元素的 cur 则存放第一个有数值的元素的下标,相当于单链表中的头结点作用
优点:在插入和删除操作时,只需要修改游标,不需要移动元素,从而改进了在顺序存储结构中的插人和删除操作需要移动大量元素的缺点
缺点:没有解决连续存储分配带来的表长难以确定的问题;失去了顺序存储结构随机存取的特性
------ 递归程序调用过程中,递归工作栈包含的数据有那些?
- 返回地址:每次递归调用是就会存储上一次函数执行到的地址,当这次函数执行完,工作栈就会根据上一次函数的地址来继续执行程序
- 局部变量和参数:函数调用时,会有主函数传递参数到函数中,工作栈也要保存这些数据
- 此次函数的返回值:当一个子函数执行后有返回值时,会有特殊的生命周期,会被保存到上一级函数内
- 上一级函数的信息:包括函数名,参数列表等,,这些信息对调试和异常处理非常重要
------非递归算法和递归算法比较,都有那些各自的优缺点?
非递归算法的优点:
- 运行速度快:非递归的程序一般都比递归程序要运行的快,它们在每次迭代的时候都不需要进行函数调用,只用在本函数内进行迭代
- 空间复杂度低:非递归程序的运行只需要一个栈来进行,所以空间复杂度时O(1),而递归算法需要大量的栈帧,所以空间开销很大
非递归程序的缺点:
- 代码难以编写和理解:非递归程序在进行同一问题解决时,往往需要更多的代码,并且逻辑比递归程序更加复杂
- 不适用于所用问题:对于一些算法程序,递归程序比非递归要更易于解决
递归程序的优点:
- 代码更加简洁:递归程序的代码比普通程序代码要更加简洁和便于理解
- 自上而下的思考方式:递归算法通常是自上而下的思考方式,这使得它解决某些问题更加的直观
递归程序的缺点:
- 运行速度慢:递归算法需要多次的函数调用,这会增加执行的时间,因为每次执行都需要额外开辟空间和执行相应的指令
- 空间复杂度高:递归程序的每次函数调用都会涉及到分配栈帧,当有大量的函数调用时还会有栈溢出的风险。
- 不适用于所有问题:对于某些问题,使用非递归算法可能更加有效和直观,而不是使用递归算法。
------ 栈的上溢操作和栈的下溢操作是什么?
栈的上溢:当栈的深度或容量超过了特定的需求,例如程序的函数调用次数过多,导致挤压在栈中,栈已经满了,还在调用函数到达了栈允许的最大深度,这就是栈的上溢。
栈的下溢:当栈的深度和容量不满足程序的要求时,则会发生下溢,例如一个程序需要使用的栈深度超过了系统所允许的最大深度,这可能导致栈的下溢。
------设长度为n的链队,用单循环链表表示,若设头指针,则入队,出队操作的时间为何?若只设尾指针呢?
若只设置头指针,则入队时间复杂度是O(1),出队的操作时间复杂为O(n),因为出队操作需要在链表尾部操作,而我们只有一个头指针,所以它要一直移动到尾部,才能入队,这步操作时间取决于链表长度n,入队则只需要在队头操作,而头指针就在这个位置,所以直接出队就行了,即复杂度为1
若只设置尾指针,则入队的操作时间复杂度为O(1),出队的时间复杂度O(1),因为出队需要在尾部操作,而尾部指针刚好是指向队列尾部的,所以时间复杂度是O(1),而入队需要在链表头部操作,并将下一个结点设置为新结点,找到尾部指针的下一个结点,更改此结点的下一个结点为新结点,就可以完成入队操作,时间复杂度依旧是O(1)
------一棵含有50个结点的二叉树,度为0的结点个数为5个,度为1的结点个数为?
答案:41
公式1:
总结点个数N :N = n2 + n1 + n0
n2:表示结点的度为 2 的结点个数
n1:表示结点的度为1 的结点个数
n0:表示结点的度为0 的结点个数
公式2:
n0 = n2 + 1
合并公式1,2:
n1 = N - 2n0 +1
带入题目: 50 - 2 * 5 + 1 = 41
------求二叉树先序和中序序列相同的情况,先序和后续呢?中序和后续呢?
解析:
- 先序遍历:根结点 -> 左子树 -> 右子树
- 中序遍历:左子树 -> 根结点 -> 右子树
- 后序遍历:左子树 -> 右子树 -> 根结点
先序和中序相同,没有左子树的二叉树
中序和后序相同,没有右子树的二叉树
先序和后序相同,只有根结点的二叉树
------将一颗二叉树转为森林?
情况一:这颗二叉树没有右子树,这一颗二叉树就是森林
情况二:二叉树有右子树
从右子树开始断链,当前的根结点和左子树组成第一棵树,然后右子树形成新的二叉树,依旧从根结点开始,断链右子树,左子树和当前根结点构成一棵新树,直到没有右子树
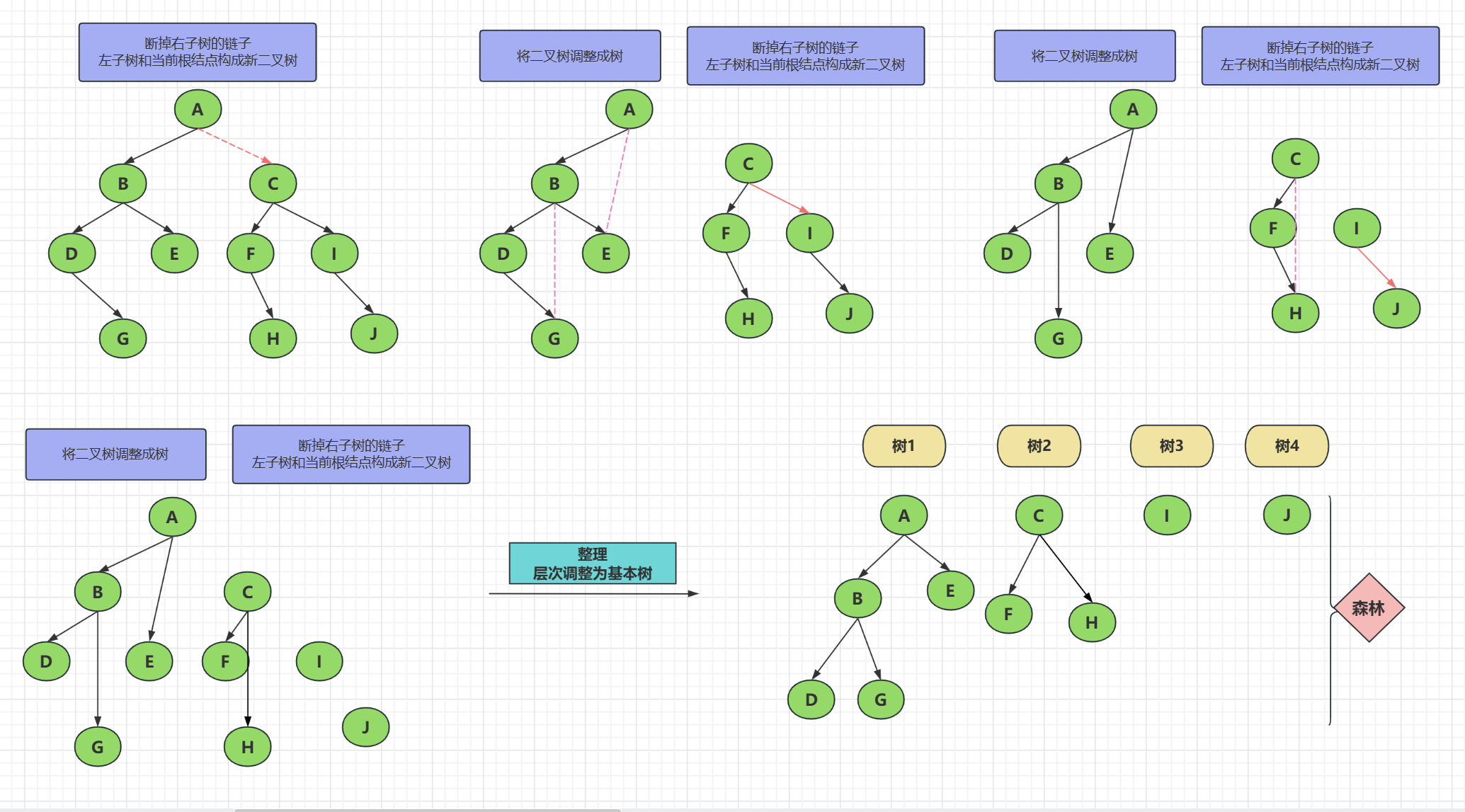
如上图,最后整理后,森林中的树都是基本树,而不是二叉树,只是这个例子刚好是二叉树的样子,但是它本来是树的,树的子结点是不一定是两个的,因该是0个或多个
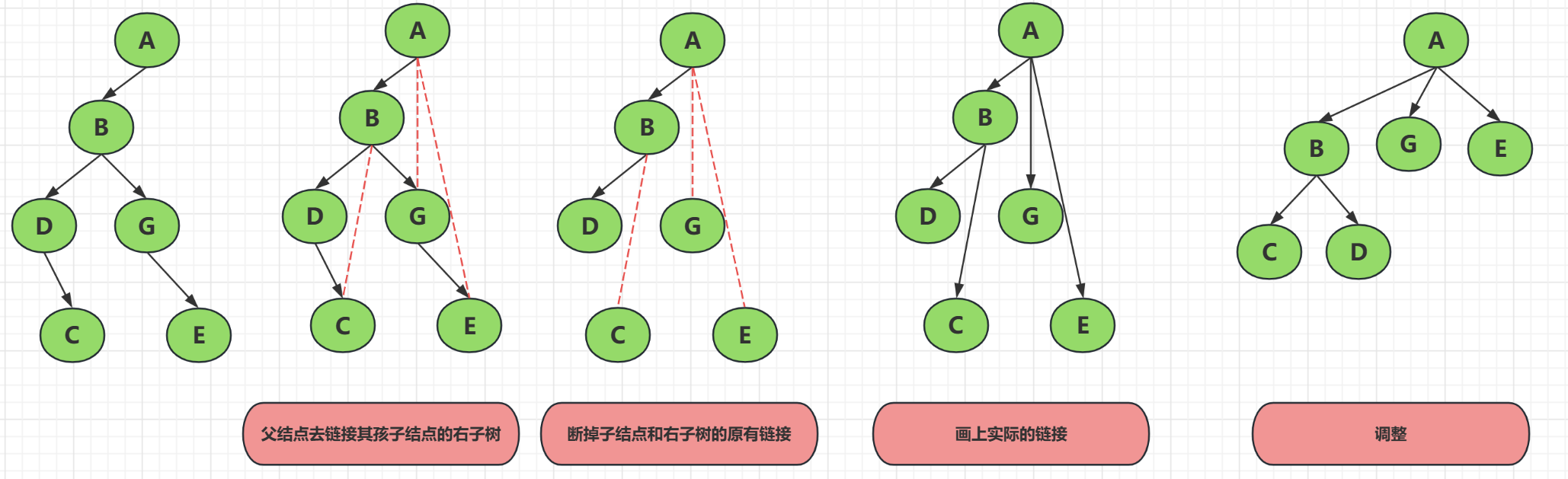
------将一颗二叉树转为树?
要将一棵二叉树调整成树,首先要保证这棵二叉树应该在根节点没有右子树,如果有右子树,则需要将右子树转换为新树,简单点讲就是把有右子树的二叉树转为森林,森林中的二叉树才能被调整为树。
步骤:
- 链接子结点的右子树
- 去掉子结点和它右子树的链接
- 层次整理
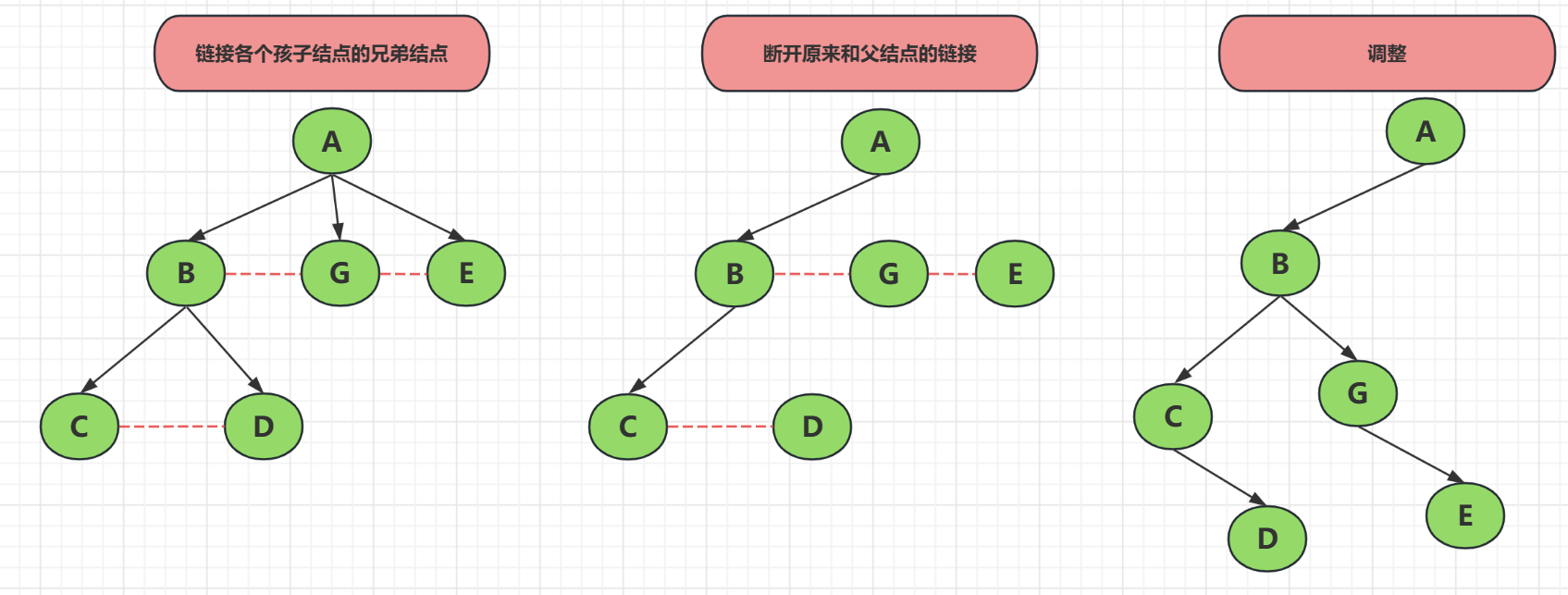
------将一颗树转为二叉树?
步骤:
- 子结点的兄弟结点链接
- 去掉父结点和非左子树的结点
- 层次调整
------将一颗森林转为二叉树?
步骤:
- 如果当前的森林是树,则先将树转为二叉树
- 转为二叉树后,以第一棵二叉树为根树,且其顶点为根结点,后面的二叉树都链接到右子树上,依次循环
- 层次调整

------为什么二叉树有中序遍历,而一般的树没有?
中序遍历是二叉树的重要遍历方式,它按照“左子树--根结点--右子树”的规则遍历所有结点,具有唯一性。而一般的树,结点的度是任意的,无法按照这种方式遍历。
二叉树中每个结点可以很快的找到左子树和右子树(没有任意一个子树通过位置也可以找到任意一棵子树),而在一般的树中,结点是任意的可以为一个,也可以为多个,所以有很大的可能分不清左子树和右子树。
所以对一般的树而言,通过中序遍历的结果不能保证唯一性,故而不适用中序遍历。
------设有三叉树中,度为1、2和3的结点数目分别为15、6和7,则度为0的结点数为?
结点数:N = n0 + n1 + n2 + n3
N = 15+6+7+n0
N=28 + n0
总度数:D = 0 * n0 + 1 * n1 + 2 * n2 + 3 * n3 +1
D= 1 * 15 + 2 * 6 + 3 * 7 +1
D = 49
公式 :结点数等于总度数 N=D
n0 = 49 - 28
n0 = 21
------有一个长度为12的有序表,按二分查找法对该表进行查找,在表内各元素等概率查找情况下,查找成功所需的平均比较次数为?
答案:37/12
12个元素进行二分查找在查找成功的情况下有
1个元素需查找1次,2个元素需查找2次,4个元素需查找3次,5个元素需查找4次;
故查找成功所需的平均比较次数:(1×1+2×2+4×3+5×4)/12=37/12
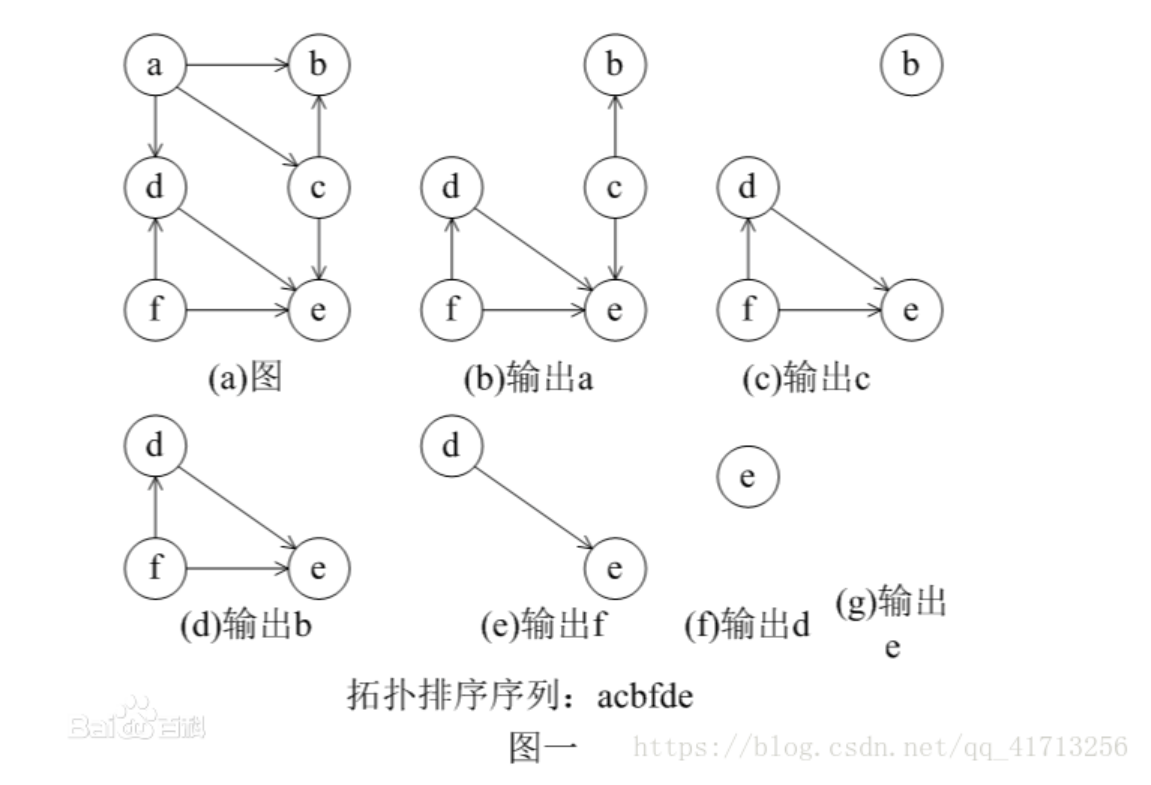
------拓扑排序的关键?
每次查找当前图的入度为0的结点,去掉它与后继结点的连线,重复操作,直到图中没有结点。
------设G是一个非连通无向图,共有28条边,则该图至少有( )个顶点?
答案:9个
该图分为两个连通分量,且其中一个连通分量只有一个结点,另一个连通分量是一个无向完全图,一个连通分量只有1个顶点,不占用边;另外一个连通分量有n个顶点,一共占用了28条边
无向完全图最多有n(n-1)/2条边
故:n(n-1)/2 >= 28 ;解得:n = -7 或 8 丢弃-7
n=8,加上另一个连通分量的1个顶点;解得: 8+1 = 9
------一个无向图有16条边,度为4的顶点有3个,度为3的顶点有4个,其余顶点的度均小于3,则该图中至少有_个顶点。
答案:11个
一共16条边,每个边固定带来两个度,一个入度一个出度;则有16*2=32
度为4的顶点有3个:4 * 3 = 12
度为3的顶点有4个:3 * 4 = 12
32 - 12 -12 = 8
因为题目问的是最少顶点有多少个,而剩下的8个度的结点都小于3,所以单个顶点只能为2
8/2 = 4
结果:3 + 4 + 4 = 11
------设二叉树中关键字由l至1000的整数构成,现要检索关键字为363的结点,下述关键字序列中不可能的是 .设二叉树中关键字由l至1000的整数构成,现要检索关键字为363的结点,下述关键字序列中,_____不可能是二叉排序树上搜索到的序列。
A、2, 252, 401, 398, 330, 344, 397, 363
B、924, 220, 911, 244, 898, 258, 362, 363
C、925, 202, 911, 240, 912, 045, 363
D、2, 399, 387, 219, 266, 382, 381, 278, 363;
答案:C
从末尾363为根结点构造一棵二叉树查找树,会发现ABD都是有序的集中在363结点的全部的左子树和全部的右子树,而C选项,912和911和925它们在右子树的左子树和右子树,并没有全在右子树的右子树上
------对长度为10的顺序表进行搜索,若搜索前面5个元素的概率相同,均为1/8,搜索后面5个元素的概率相同,均为3/40,则搜索到表中任一元素的平均搜索长度为( )?
答案:39/8
前五个元素为1/8(1,2,3,4,5号元素),后五个元素3/40(6,7,8,9,10号)
1/8 * 1 + 1/8 * 2 + 1/8 * 3+ 1/8 *4 + 1/8 * 5 +3/40 * 6 + 3/40 * 7 +3/40 * 8 +3/40 * 9 + 3/40 * 10 = 39/8
------C语言中的格式控制符有那些?
%d:输出十进制的数
%u:输出十进制无符号整数
%f:输出单精度浮点数
%s:输出字符串
%c:输出字符
%p:用于输出指针的值
%x:用于输出十六进制的整数
%o:输出八进制的整数
%n:用于记录到%n前输入了多少个字符
&[]:用于指定字符的宽度,需要结合其它格式控制符,如%2d输出个空间的整数
%*:用于指定输出宽度,也需要结合其它控制符,指定前面字符所留空间长度
int width = 10; // hello printf("%*s", width, "hello"); // 输出宽度为10的字符串"hello"
%-15:使输出内容向左对齐 %- ,左对齐,15带上输出字符串的长度一共对齐15个空间
printf("%-15s\n", "Hello, world!");
%15:使输出内容向右对齐,%15,连上字符串长度对齐右边一个15个空间
printf("%15s\n", "Hello, world!");
%hd:用于短整型的输出格式
%ld:用于指定长整型的输出格式
%Lf:用于指定双精度的浮点数输出格式
%g:以科学计数的方式输出浮点数,当小数点后右多个0时,自动抹除,算式不合法时会输出NAN,INF
- %g用来输出实数,它根据数值的大小,自动选f格式或e格式(选择输出时占宽度较小的一种),且不输出无意义的0。即%g是根据结果自动选择科学记数法还是一般的小数记数法
- 且%.5g中,5指定的是保留整数部分5位,如果超过5位则使用科学计数法,如果整数小于5位但是又有小数部分就和小数一起输出5位,当整数等于5位时四舍五入小数部分
%i:有符号类型,用法和%d差不多,可以理解为专用的负数输出符
%% :输出一个%符号
------C语言中数据类型的长度表示?
int类型:
在大多数计算机系统中,int类型通常占用4个字节(32位),因此它的取值范围是-2147483648到2147483647(-2^31到2^31 - 1)。
long类型:
在大多数计算机系统中,long类型通常占用4个字节(32位),因此它的取值范围是-2147483648到2147483647(-2^31到2^31 - 1)。与int类型一样。
long long类型:
long long类型通常占用8个字节(64位),因此它的取值范围更大。在大多数计算机系统中,long long类型的取值范围是-9223372036854775808到9223372036854775807(-2^63到2^63 - 1)。
short类型:
short类型通常占用2个字节(16位),因此它的取值范围相对较小。在大多数计算机系统中,short类型的取值范围是-32768到32767(-2^15到2^15 - 1)。
------C语言中的unsigned和signed的区别?
在C语言中,unsigned和signed是两种修饰符,用于指定整数类型的符号状态。
signed:带符号整数类型。对于signed类型的整数,如果其值大于0,则最高位(符号位)为0,其余位表示数值;
如果其值小于0,则最高位(符号位)为1,其余位表示数值的负值。因此,signed类型的整数可以表示正数、负数和零。
unsigned:无符号整数类型。对于unsigned类型的整数,其最高位也是符号位,但该位始终为0。
因此,unsigned类型的整数只能表示非负整数。
------C语言中的常用数学函数(需导入math.h)?
double atan2(double y,double x):函数是C语言中的一个数学函数,它用于计算两个数的反正切值。这个函数接受两个参数,第一个参数是y值,第二个参数是x值。
函数的返回值是以弧度表示的反正切值。它的返回值的范围是 -π 到 +π。
double sqrt(double x):把 x 开平方根
double pow(double x,double y):计算x的y次方
double exp(double x):计算以e为底的x次方
double log(double x):以e为底计算对数,log2(x)一为底,log10(x)以10为底
double ceil(double x):向上取整
double floor(double x):向下取整
double fabs(double x):取浮点数x的绝对值
double fmod(double x,double y):x mod y ,浮点数专用函数
int abs(int x):求整数的绝对值
int round(double x):四舍五入小数部分,注意是整个小数部分,和MySQL不同
------C语言中的字符串函数(声明:string.h)?
int strlen(str):返回一个字符串的长度
void strcpy(str,str1):复制字符串,将str1复制到str中
void strcat(str,str1):链接字符串,将字符串str1链接到str的后面
int strcmp(char *a,char *b):比较字符,a>b:1,a<b:-1 ,a=b:0,传入的参数是地址
char * strrev(str):反转字符串,返回反转后第一个元素的指针
void strset(str,c):将字符串全部替换成字符c(可用于初始化字符串)
double strtod(str,**a):用于将字符串转化为浮点型,str是被转换的字符串,a是个二级指针,用于指向不能被转换的字符地址
long strtol(str,**a,number):用于将字符串转化为长整型,str是待转换的字符串,a指向非数字的第一个字符,number是指的转化为多少进制
long strtoul(str,**a,number):用于将字符串转换为无符号长整形,str是字符串,a指向非数字的字符,number是转换的进制数,(unsigned long int 中4294967295 = -1)
#include<stdio.h> #include<ctype.h> #include<string.h> #include <stdlib.h> #include<math.h> int main() { char *a; char str[9]="-1234ab6"; unsigned long int n; long n1; double n2; n2=strtod(str,&a); n1=strtol(str,&a,10);//转为10进制长整型 n =strtoul(str,&a,10); printf("%.2lf\n",n2); printf("%ld\n",n1); printf("%lu\n",n); //结果集 /* -1234.00 -1234 4294966062 */ }
C语言中的单字符操作函数(声明:ctype.h)?
int isalpha(a):判断变量a是否为字母,小写字母:2,大写字母:1,数字和其它符号:0
int isdigit(a) :判断变量a是否为数字,数字:1,字母和其它字符:0
int isnum(a):判断变量是否为字母或数字,小写字母:2,大写字母:1,数字:4
int isspace(a):判断a是否是空格,换行符,制表符;是:8,字母,数字,其它字符:0
int isupper(a):判断字符是否为大写;大写字母:1,小写,数字,其它字符:0
int islower(a):判断字符是否为小写;小写字符:2;其它字符数字:0
char toupper(a):将变量a转换为大写
char tolower(a):将变量a转换为小写
char getchar():读入一个字符
void putchar(a):输出一个字符(只能输出一个字符,故参数不能是数组)
------C语言中数学用到的计算公式(全是数学思想)?
12 +22 +32 +42 + 52 +62 +.....+n2 = n(n+1)(2n+1)/6
13 +23 +33 +43 +53 +63 +......+n3 = [ n(n+1) ]2 /4
计算一元二次方程的求根公式:ax2 + bx + c = 0
sqrt(pow((double)b,2)-(4.0*a*c)) >= 0 有两个相同或不同的根
x1=(-b+sqrt(pow((double)b,2)-(4.0*a*c)))/(2*a);
x2=(-b-sqrt(pow((double)b,2)-(4.0*a*c)))/(2*a);
sqrt(pow((double)b,2)-(4.0*a*c)) < 0 无根,特别注意
注:会用到数学库,math.h
计算二元一次方程,带入消元法就可以,但是注意判解
(1)a1 x+b1 y=c1
(2)a2 x+b2 y=c2
对于这个二元一次方程组
①当a1/a2 ≠ b1/b2 时,方程组有唯一解。
②当a1/a2 = b1/b2 = c1/c2时,方程组有无数组解。
③当a1/a2 = b1/b2 ≠ c1/c2时,方程组无解。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号