《数据结构与算法》之数据的顺存储
导言:
数据结构中,对一些数据序列我们使用的是顺序的方式存储,比较常见的有数组,链表,这些都是最基本的顺序存储的结构,我们会用几个简单的例子来描述顺序存储的方式和演变
我们知道顺序存储中有链表,有链表我们就必须知道指针,所以我们先复习一下指针,再来看顺序存储
一.指针
在C语言中,我们第一次了解函数的时候,大多数人认识的应该都是 scanf()函数,它是stdio.h 库下的一个标准函数,用于对程序内的变量进行输入输出
我们这个时候可以来研究一下这个函数的格式: scanf ( "%d" , & var )
这里我们所看到的 & var 就是取地址符 ,我们在 var变量赋值的时候实际上是 把地址交给了 scanf 函数
scanf函数会从缓冲区去拿实际的值,那么这个时候scanf函数拿到地址和值后是怎么操作的呢?
这就是指针的作用了,指针是一个抽象的东西,当被定义出来的时候作用不大,它的目的是要有一个地址赋给它,他就会像一个箭头一样指向那个地址,此时那个空间的值就是当前指针的值
所以 scanf 拿到var 变量的地址以后,就会指向那个地址,此时 指针的值 和var 变量的值是一样的,当scanf 函数在缓冲区拿到输入值
把这个值覆盖到指针指向的地址所在的空间原有的值,然后当var 变量去访问自己的地址时就会是我们的输入值,这就实现了scanf函数的功能
说到这里我们就可以明白了:指针其实就是对一个地址所在空间的值进行更改或者访问
指针的定义: int *p
p :代表一个地址,需要使用变量地址值来赋值
*p :代表指向一个地址,取此地址上的数据
指针的使用:
我们构造一个交换函数swap(int a,int b):

我们可以看看这个主函数在使用了swap 函数会改变a , b的值吗?
只要前面在学函数的时候就知道结果肯定是没变化,因为C语言的函数是值传递,当值传入如swap的时候,在swap中a,b变量是临时的复制品,函数调用完后就挂掉了,生命周期根本活不到主函数
我们这个时候就可以使用指针,因为指针传递的是地址,全局只有一个a地址,所以基于地址改变值全局是唯一的,生命周期也是基于传入变量的,而不是调用函数的生命周期
我们来使用指针改写一下:

这个时候我们可以看到a ,b的值发生交换了,很显然我们通过地址来直接更改值,是唯一的,这也突出了指针的特点,他很灵活,它在直接操作地址
同时,我们根据这个例子也可看出指针可以带回多个值的特点,我们知道数组也可以带回多个值,其实数据在函数调用传入的就是指针(也就是传入的地址)
这就是我们在声明函数的时候数组的写法是 int arr[ ] ,即使我们写入大小也是没有的 ,它和指针的写法是等同的 : int arr [ ] = int * arr ,两种写法都能使用下标拿值(前提是主函数arr的定义是数组)
指针的运算:
指针在满足加减运算,他只得是指针的位置移动
比如 *(p ++),*(p+1),*(p -1),*(p--)
这些都是内存的地址移动,这里的 ++ 或者 +1并不是真的只移动了内存地址上的 1 bit 而是取决于 定义指针时的大小
比如 int *p 一次 *p++ 位移了四个字节 32bit
char *p 一次 *p++ 位移了一个字节 就是8bit
我们也常用指针的位移来做数组的遍历,都是可以的
小结:
其实,现在我们许多在学上层语言的人,对指针的操作很少,但是我们在使用这些语言的时候时时刻刻都在用指针,很多面向对象的语言都封装了指针,对编写者是不可见,但它存在
就比如Java的get,set方法,对同一个属性的更改都是要对地址操作的,包括spring中对象的单例模式,都是操作地址
二.结构体
谈论到结构体我们就不得不提一个常用的数据类型,那就是数组,我们都知道,数组是一种数据类型的集合,
比如:整型数组,字符型数组,它们的整个序列的类型都是一样的
那么对于不一样的数据类型我们怎么把它们弄到一个集合里面呢?
这就需要我们的结构体了:
首先结构体的类型定义:
struct 结构体名{
成员列表 ;
} ;
比如:学生结构体类型
struct student {
int id;
int age ;
char name[10];
float grade ;
} ;
我们可以看到它里面的基本数据类型都是不一样的,这就是自定义的集合类型,结果体
我们在使用结构体的时候要想基本变量一样要定义和声明,
比如 定义一个int型的变量 int a ;
定义一个结构体变量也是一样的 struct student stu ; struct student 是变量类型, stu 是变量名
C语言也提供了简化定义方式:
struct student {
int id;
int age ;
char name[10];
float grade ;
} stu ;

这两种方式都是等效的,我们在知道了变量的定义方式以后,我们就该来使用了
使用结构体有些不同,要使用结构体名 . 成员变量
比如 stu . age = 18 ,stu.name ={w,o,r,l,d}
还可以一次全部赋值,也是为了简化;
stu = {1,18,{w,o,r,l,d},2};
结构体指针:
- 普通结构体 var . 成员
- 结构体指针 pointer -> 成员
我们在定义指针的时候还可以可优化,比如 struct student stu ;这是原来的定义方式
我们要使用到一个关键字typedef 对结构体修饰
typedef struct student {
int id;
int age ;
char name[10];
float grade ;
} stu;
这样 此时的stu 就可以代表整个结构体类型了,
stu st 等同于 struct student st的结构体定义方式
结构体指针也是一个抽象,他是对一个地址操作,首先我们得有一个地址给他,然后才能操作结构体,本身结构体指针就像指针一样,是对地址的操作
结构体指针的例子:

三.数据结构之顺序存储
现在我们有一个一元多项式: f(x)= 2x^3 + 6x^4 -9x^5
这样的数据我们怎么存呢?
第一种:直接数组存储
这是最简单的一种方式,直接存在数组里,这里我们可以把f(x)拆分为成 系数和指数,数组下标来存指数,数组来存系数

如上图,这种存储方式直观,而且很容易想到,是最简单的数据存储方式,
但是这种存储方式的缺点也很明显,那就是空间浪费太大,小范围的存储还可以,多了就不行
第二种:顺序结构体数组
我们定义一个结构体数组,数组中有两个元素,一个装指数,一个装系数
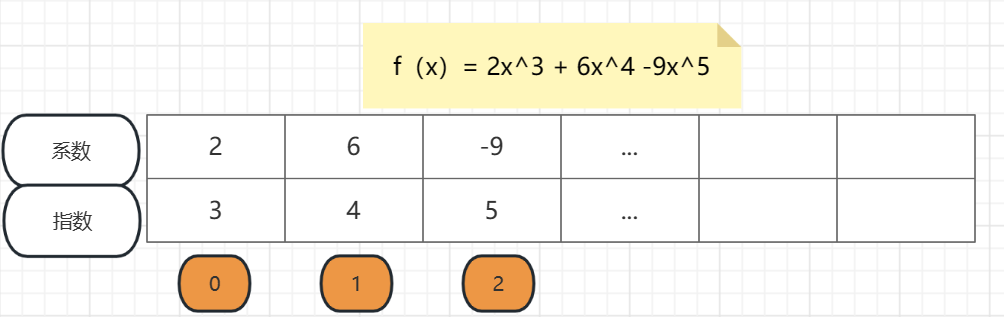
我们这样的定义就避免了前面的浪费,少存入了很多非零项,而且结构很直观,重要的一点是在存入结构体数组时要排序一下
第三种:链表存储
链表的存储比数组的存储更加灵活,他也是一个结构体指针,内部有两个成员,系数和指数

链式存储在构造上和顺序表存储无差别,可以他在更改的时候很灵活,在删除和插入,无需大量移动
顺序表的插入和删除:
顺序表是基于数组来完成的,所以插入和删除有大量的移动,比如要在中间插入一个数据,那么从最后一个位置开始都要向后一个一个的移动,
直到把要插入的位置空出来,然后让数据插入进入,这里的移动是移动覆盖,即从最后一个元素开始一个个向后移动一个元素

我们可以看到,根据我们的插入位置往后,伴随着大量的元素移动,
这是数据小的情况可能不是很明显,但是数据一旦大,往前插入就会越来越明显的难
不仅找数据需要开销,移动也需要开销
但是线性顺序表的确要便于我们理解一些

数组的删除一定要先判断有没有这个元素,然后再去执行删除
删除就是从删除位置的后一个元素开始,一个一个的向前移动,然后覆盖掉这些元素
都是伴随大量的元素移动
链式表的插入和删除:
链式存储并不需求在物理上就是相邻的,而是链也就是地址来建立联系
插入或者删除都不需要移动数据元素,只需要修改链
插入元素:
1.构造一个新的节点,用另一个指针s指向
2.再找到链表的第i - 1个节点,用 指针 p 指向
3.然后修改指针,插入新节点
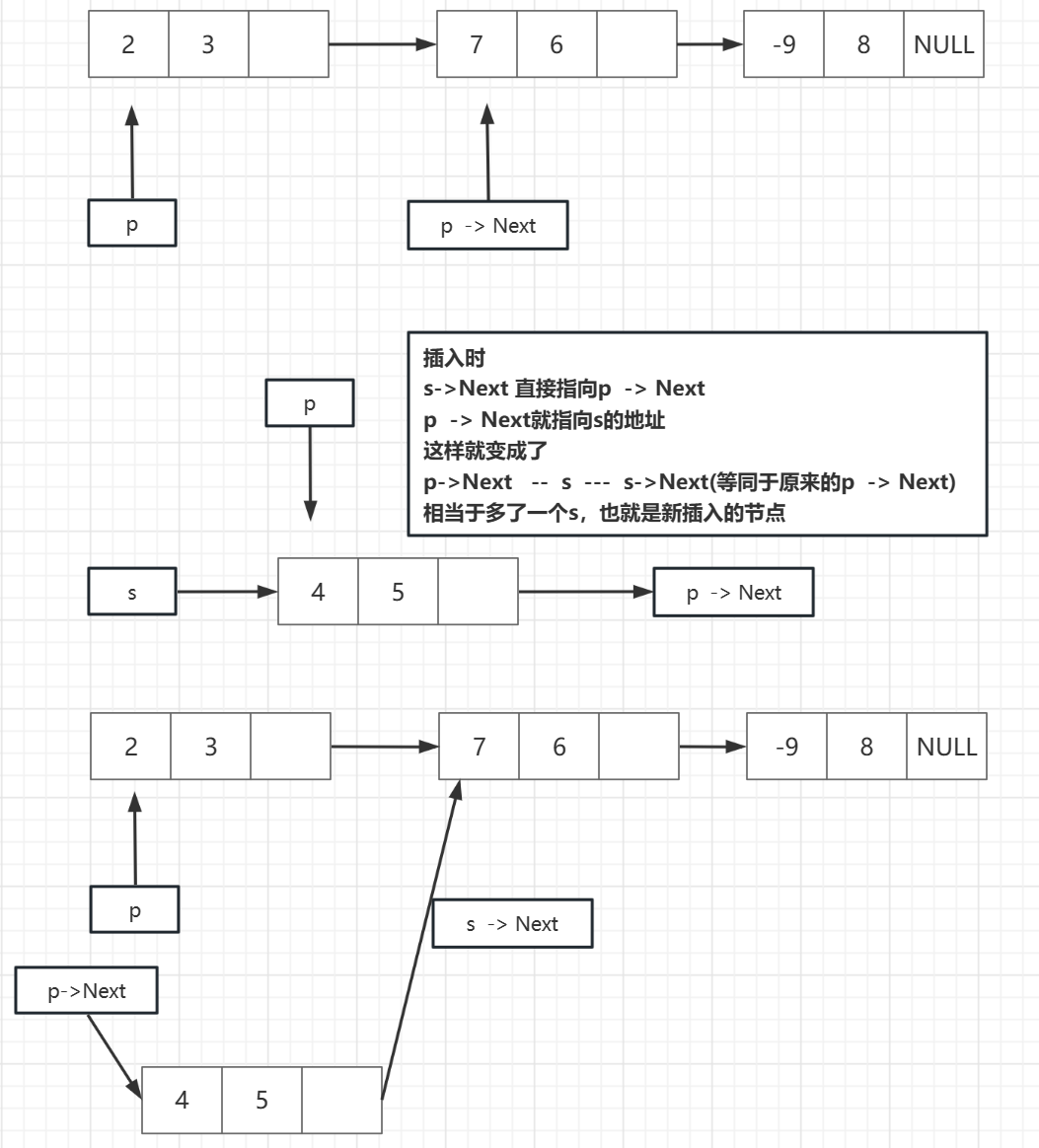

删除结点:
删除结点为 i
1.首先找到 i -1 个位置结点
2. 用指针s指向结点,即要删除的结点
3.然后修改指针,删除s所指的结点
4.最后释放s所指的空间
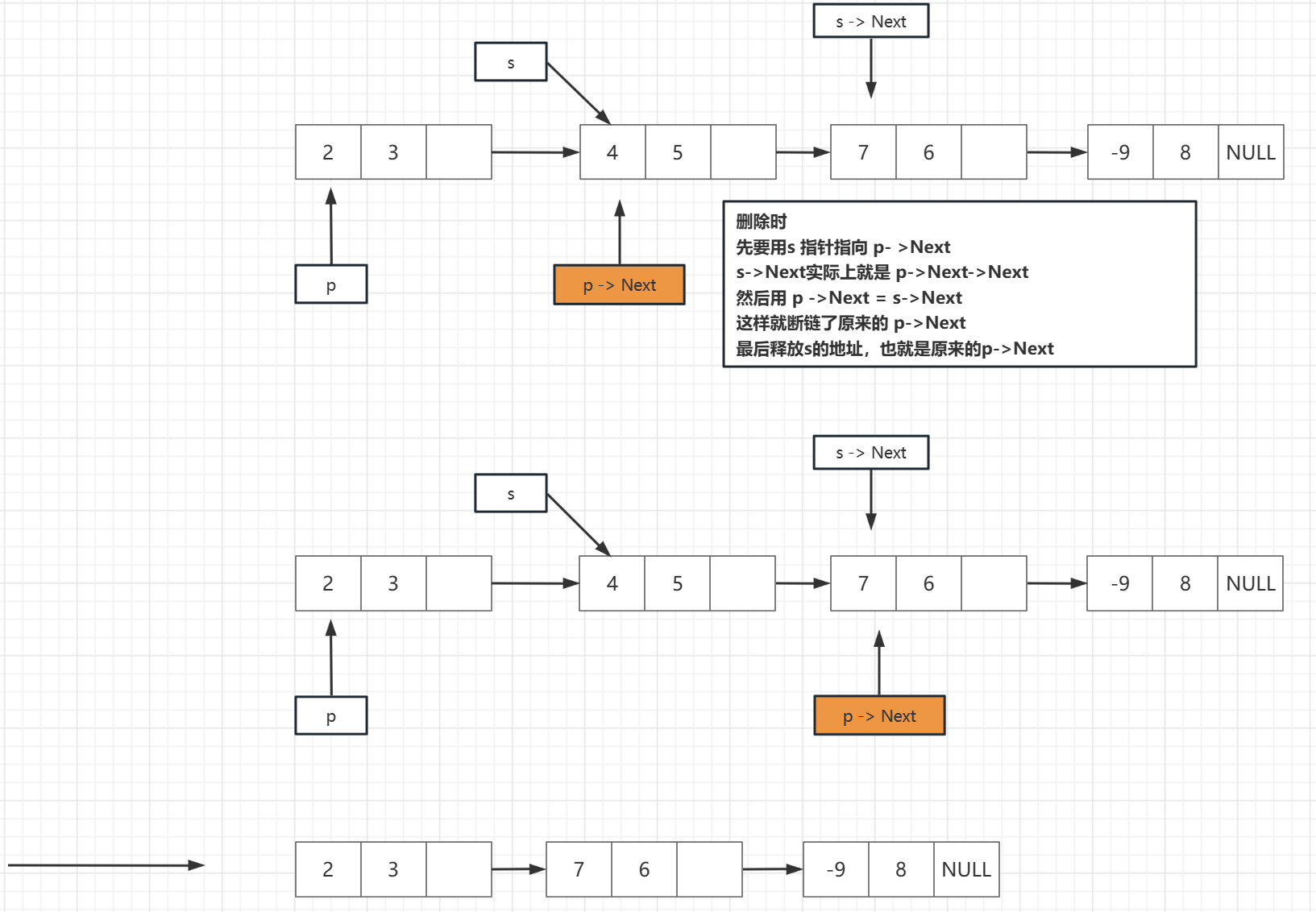

链表的删除和插入没有大量的移动,只是断链的时候麻烦,要跟着步骤一步一步来,不然就会出错
尤其是删除结点时,一定不哟啊直接使用 : p->Next = p->Next->Next;
会发生丢失的,就是找不到后面链的数据

 浙公网安备 33010602011771号
浙公网安备 33010602011771号