微服务SpringCloud之zipkin链路追踪
随着业务发展,系统拆分导致系统调用链路愈发复杂一个前端请求可能最终需要调用很多次后端服务才能完成,当整个请求变慢或不可用时,我们是无法得知该请求是由某个或某些后端服务引起的,这时就需要解决如何快读定位服务故障点,以对症下药。于是就有了分布式系统调用跟踪的诞生。
Spring Cloud Sleuth
一般的,一个分布式服务跟踪系统,主要有三部分:数据收集、数据存储和数据展示。根据系统大小不同,每一部分的结构又有一定变化。譬如,对于大规模分布式系统,数据存储可分为实时数据和全量数据两部分,实时数据用于故障排查(troubleshooting),全量数据用于系统优化;数据收集除了支持平台无关和开发语言无关系统的数据收集,还包括异步数据收集(需要跟踪队列中的消息,保证调用的连贯性),以及确保更小的侵入性;数据展示又涉及到数据挖掘和分析。虽然每一部分都可能变得很复杂,但基本原理都类似。
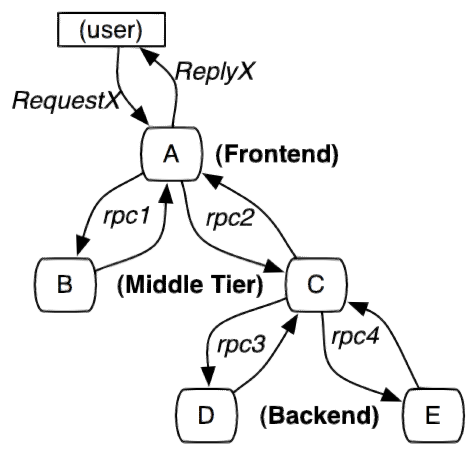
服务追踪的追踪单元是从客户发起请求(request)抵达被追踪系统的边界开始,到被追踪系统向客户返回响应(response)为止的过程,称为一个“trace”。每个 trace 中会调用若干个服务,为了记录调用了哪些服务,以及每次调用的消耗时间等信息,在每次调用服务时,埋入一个调用记录,称为一个“span”。这样,若干个有序的 span 就组成了一个 trace。在系统向外界提供服务的过程中,会不断地有请求和响应发生,也就会不断生成 trace,把这些带有span 的 trace 记录下来,就可以描绘出一幅系统的服务拓扑图。附带上 span 中的响应时间,以及请求成功与否等信息,就可以在发生问题的时候,找到异常的服务;根据历史数据,还可以从系统整体层面分析出哪里性能差,定位性能优化的目标。
Spring Cloud Sleuth为服务之间调用提供链路追踪。通过Sleuth可以很清楚的了解到一个服务请求经过了哪些服务,每个服务处理花费了多长。从而让我们可以很方便的理清各微服务间的调用关系。此外Sleuth可以帮助我们:
耗时分析: 通过Sleuth可以很方便的了解到每个采样请求的耗时,从而分析出哪些服务调用比较耗时;
可视化错误: 对于程序未捕捉的异常,可以通过集成Zipkin服务界面上看到;
链路优化: 对于调用比较频繁的服务,可以针对这些服务实施一些优化措施。
spring cloud sleuth可以结合zipkin,将信息发送到zipkin,利用zipkin的存储来存储信息,利用zipkin ui来展示数据。
测试
1.启动zipkin server
由于是参考纯洁的微笑的博客http://www.ityouknow.com/springcloud/2018/02/02/spring-cloud-sleuth-zipkin.html,但在我创建zipkin-server项目引入注解@EnableZipkinServer时提示已不能使用。建议使用默认的zipkin的jar包,具体使用方法可以查看github的文档。这里直接下载下了jar,然后使用内存方式存储,java -jar zipkin-server-2.17.0-exec.jar.
/** * @deprecated Custom servers are possible, but not supported by the community. Please use our * <a href="https://github.com/openzipkin/zipkin#quick-start">default server build</a> first. If you * find something missing, please <a href="https://gitter.im/openzipkin/zipkin">gitter</a> us about * it before making a custom server. * * <p>If you decide to make a custom server, you accept responsibility for troubleshooting your * build or configuration problems, even if such problems are a reaction to a change made by the * OpenZipkin maintainers. In other words, custom servers are possible, but not supported. */
2.项目中添加zipkin的支持
在SpringColudZuulSimple、EurekaClient中引入依赖spring-cloud-starter-zipkin。
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-zipkin</artifactId> <version>2.1.3.RELEASE</version> </dependency>
然后在application.properties中设置属性
spring.zipkin.base-url=http://localhost:9411
spring.sleuth.sampler.probability=1.0
spring.zipkin.base-url指定了Zipkin服务器的地址,spring.sleuth.sampler.percentage将采样比例设置为1.0,也就是全部都需要。
Spring Cloud Sleuth有一个Sampler策略,可以通过这个实现类来控制采样算法。采样器不会阻碍span相关id的产生,但是会对导出以及附加事件标签的相关操作造成影响。 Sleuth默认采样算法的实现是Reservoir sampling,具体的实现类是PercentageBasedSampler,默认的采样比例为: 0.1(即10%)。不过我们可以通过spring.sleuth.sampler.percentage来设置,所设置的值介于0.0到1.0之间,1.0则表示全部采集。
3.验证
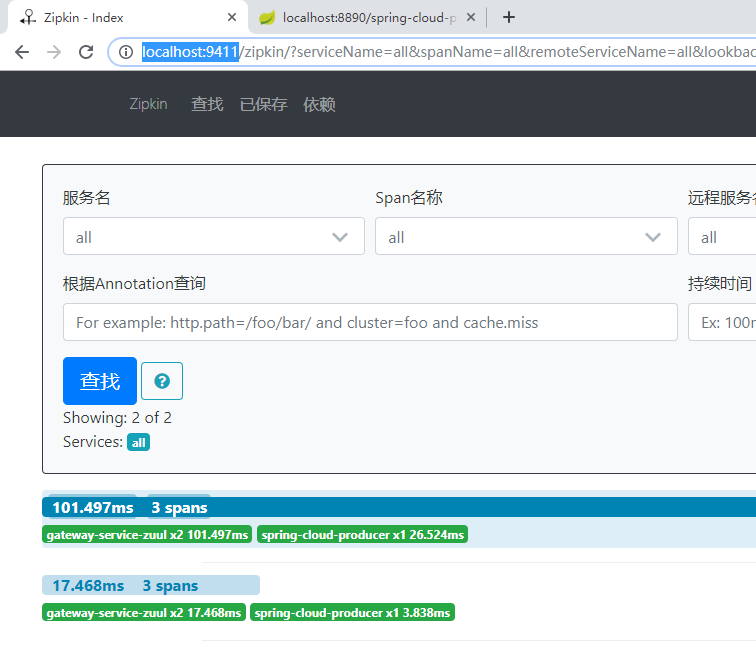
依次启动EurekaServer、EurekaClient、SpringColudZuulSimple,然后在浏览器中输入http://localhost:8890/spring-cloud-producer/hello?name=cuiyw&token=123,刷新几次,然后在http://localhost:9411页面点击查询,可以看到如下信息。
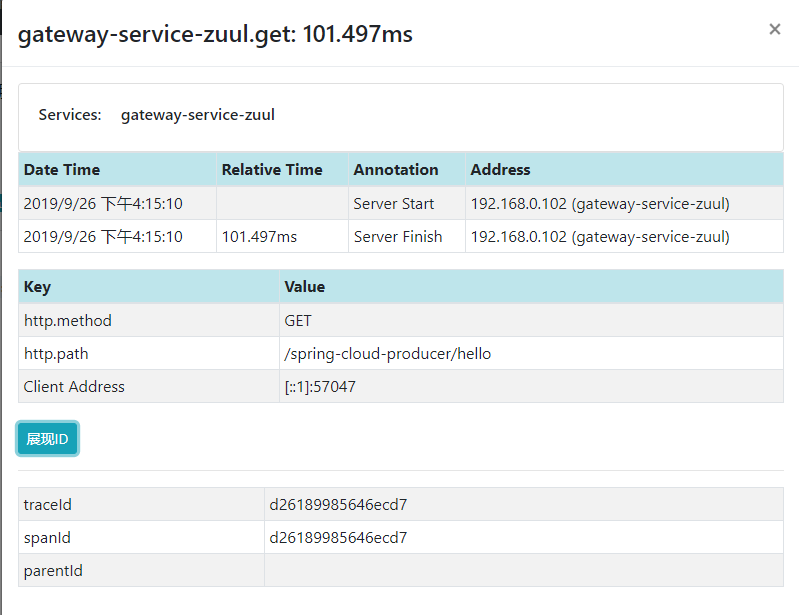
点击每项记录都能看到每项的具体耗时信息和顺序。
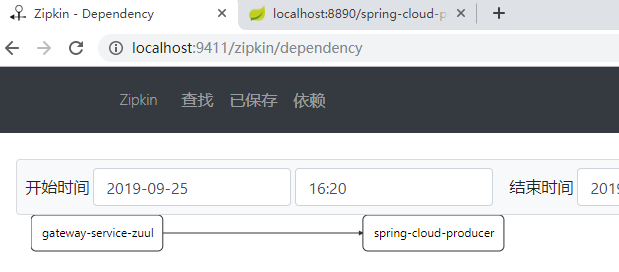
点击依赖分析,可以看到项目之间的调用关系
总结
这里使用的内存的方式来存储数据,生产环境一般会使用消息队列RabbitMQ、Kafka或者数据库mysql存储,具体使用方法可以查看zipkin的官方文档。
参考:http://www.ityouknow.com/springcloud/2018/02/02/spring-cloud-sleuth-zipkin.html
作者:社会主义接班人
出处:http://www.cnblogs.com/5ishare/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
如果文中有什么错误,欢迎指出。以免更多的人被误导。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号