

linux各文件名及操作
异常情况处理:
在linux编辑过程中出现连接中断,再次编辑文件会提示相应信息
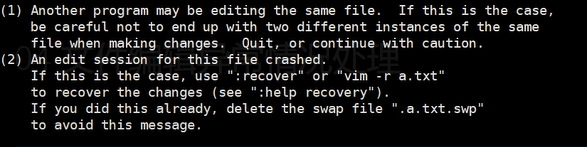
出现原因:
1.编辑过程中突然出现了中断
2.文件被多个人使用
解决方式:删除显示的隐藏文件
rm-f .oldboy.txt.swp
结论:出现了隐藏文件,没有及时删除
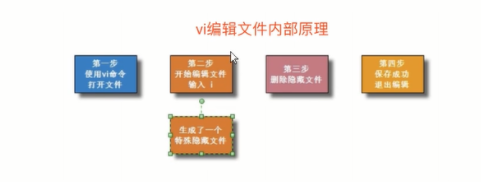
挂载的概念:
结构特点说明:
linux根下面的目录是一个有层次的树状结构
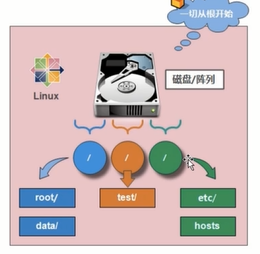
挂载:
磁盘-设备(房间) 需要储存东西
从门进入-目录(挂载点)
实践操作实现挂载操作:
步骤一:
拥有一个储存设备
步骤二:
找到相应光驱设备
ls /dev/cdrom
步骤三:
进行挂载操作
mount/dev/cdrom/mnt
步骤四:
确认是否挂载成功
is/mnt
linux目录结构
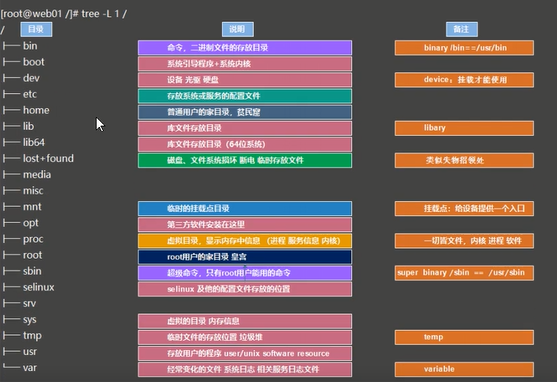
主要目录
etc目录 # 系统和服务的配置文件存放区 home目录 # 普通用户信息存放区 mnt目录 # 临时挂载点目录 opt目录 # 第三方软件安装存放区 sbin目录 # 管理员可以执行的命令 tmp目录 # 临时存放数据 usr目录 # 存放用户程序 var目录 # 存放日志文件数据
重要目录数据信息
网卡配置文件
/etc/sysconfig/network-scripts/ifcfg-eth0
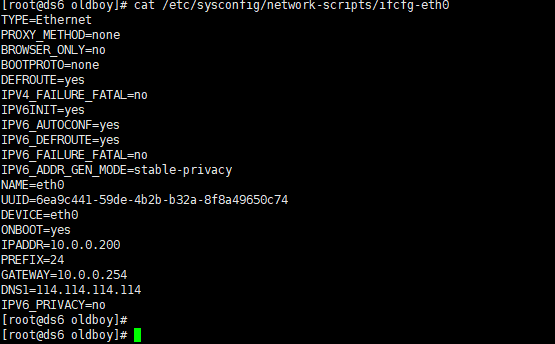
进入 insert 模式 将ip地址进行修改
ip地址修改后 必须重启网络服务
网卡信息解释:

DNS服务设置方法:
1.设置为阿里云服务器地址
223.5.5.5
223.6.6.6
2.通用dns服务器地址
114.114.114.114
114.114.114.119
3.利用移动dns服务器
8.8.8.8
4.使用网关地址充当dns服务器地址
10.0.0.254
网卡域名解析配置文件
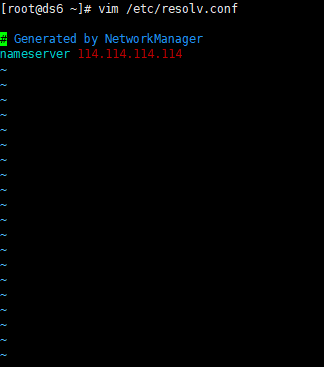
可以加入第二个name sever 以备第一个坏掉的情况也可以是多个

保存并退出
主机名称配置文件
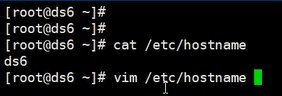
修改完之后通过reboot重启机器
本地域名解析文件

可以通过在本地修改映射关系

网络不通排查流程
1.确认网关地址是否通畅
2.确认网卡配置是否正确
3.确认网络管理服务关闭
查看网络状态
systemctl status NetworkManger
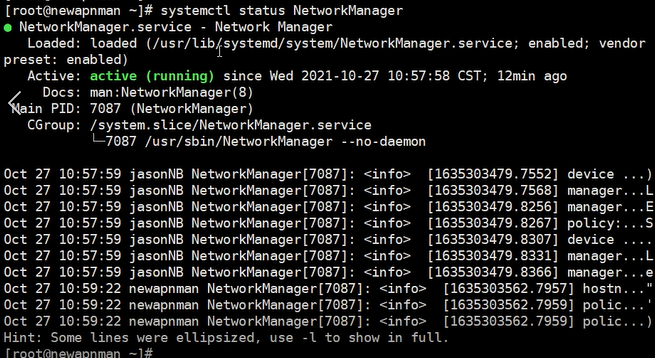
etc目录下数据文件








.::::. .::::::::. ::::::::::: ..:::::::::::' '::::::::::::' .:::::::::: ':::::::::::::::::. ..::::::::::::::. ``:::::::::::::::: ::::``:::::::::' .:::. ::::' ':::::::' .::::::::. .::::' :::::: .:::::::'::::. .:::' ::::: .:::::::::' ':::::. .::' :::::.:::::::::' ':::::. .::' ::::::::::::::' `::::. ...::: ::::::::::::' `::::. ```` ':. ':::::::::' :::::.. '.:::::' ':'````..
reboot之后 每次登陆都会出现一些文字图案

usr目录下重要数据文件
/user/local/ 用于保存用户安装软件程序信息
linux系统安装软件
1.yum安装软件
yum install -y tree vim bash-completion
2.rpm包方式安装软件
rpm -ivh xxx .rpm

3.编译安装软件
4.二进制包安装软件
var目录下重要数据文件
经常发生变化的文件保存在variable
比如:日志文件


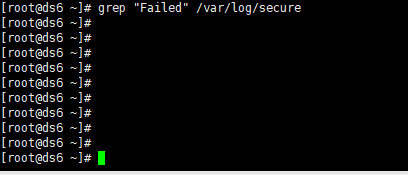
查看登录失败的信息

proc目录重要数据文件

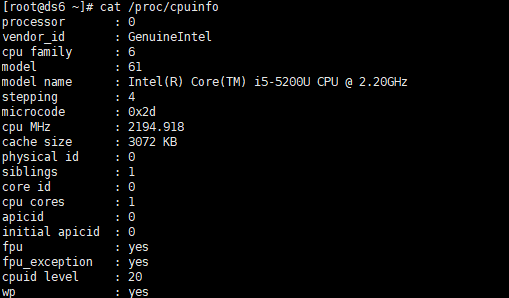
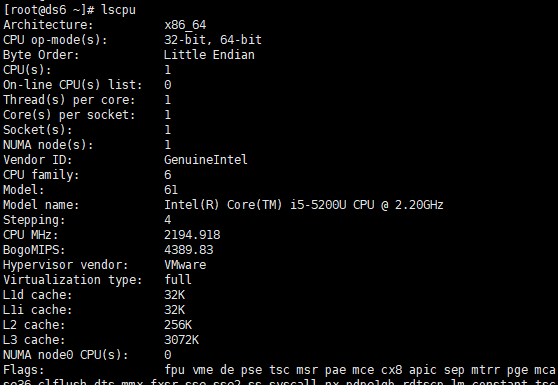
lscpu 查看计算机信息
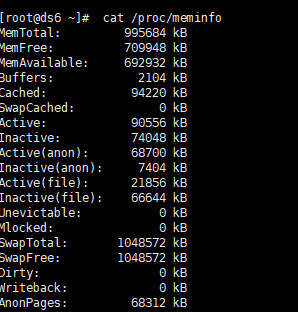
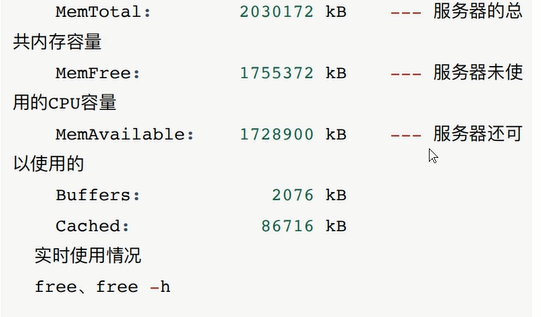
cat /proc/meminfo 查看内存信息
df -h 查看磁盘信息
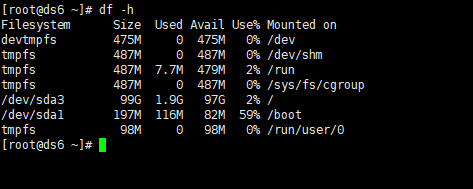
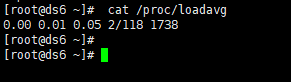
cat /proc/loadavg 查看负载情况

系统优化
性能优化
安全优化
编码优化

环境变量
特征:
1.由大写字母组成
2.配置的环境变量所有用户都必须遵循
3.系统中默认就有变量信息


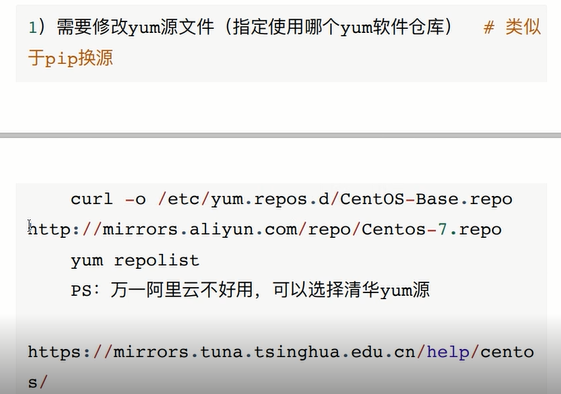
下载软件优化操作

大数据概念:
具备哪些特点才能称为大数据?
1.海量数据
2.高增长率
3.多样化,数据种类千奇百怪
研究大数据目的:
1.海量数据的存储
2.海量数据的分析计算
单位换算 从小到大
bit、Byte、KB、MB、GB、TB、PB、EB、ZB、YB、BB、NB、DB
Hadoop

狭义上说hadoop可以看做一个数据库软件
广义上说hadoop是一个大数据生态圈
创始人:

Hadoop主要版本
Apache版本 最原始(最基础)的版本,对于⼊⻔学习最好。2006 Cloudera 内部集成很多⼤数据框架,对应产品CDH。 2008 Hortonworks ⽂档较好,对应产品HDP。 2011



# Hadoop1.X MapReduce # 计算与资源调度 HDFS # 数据存储 Common # 辅助工具 # Hadoop2.X与3.X MapReduce # 计算 Yarn # 资源调度 HDFS # 数据存储 Common # 辅助工具
NameNode(nn):存储文件的元数据 # 相当于目录 DataNode(dn):存储文件的真实数据 # 当对于文本内容 Secondary NameNode(2nn):辅助NameNode工作 # 相当于备用设施
Resource Manager:类似于大老板
Node Manager:类似于各部门经理
Application Master:类似于部门中真正干活的员工
Container:类似于每个部门拥有的各项资源
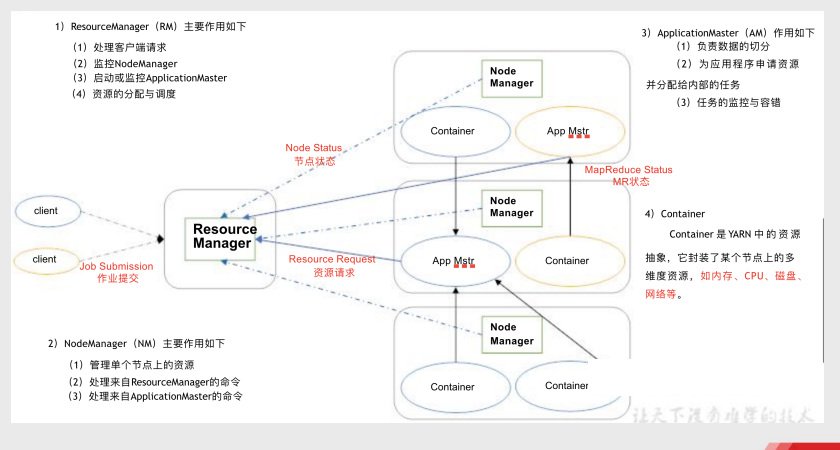
Map就是将复杂的任务拆分成多个小任务分发给不同的节点完成
Reduce就是将每个节点完成的小人物汇总到一起

技术生态圈
1.数据来源层
针对结构化数据(关系型数据库)采用sqoop进行数据同步
针对半结构化、非结构化数据(非关系型数据库)采用flume、kafka进行同步
更多请参考群内pdf文件


