
数据分析之pandas模块②
series数据操作:
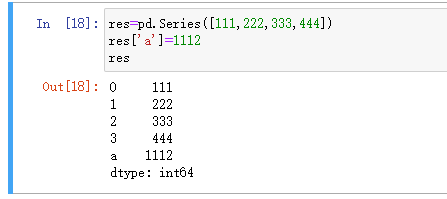
增:
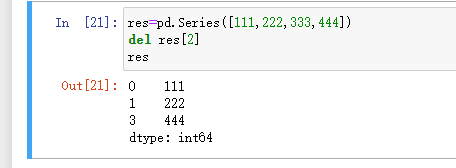
删:
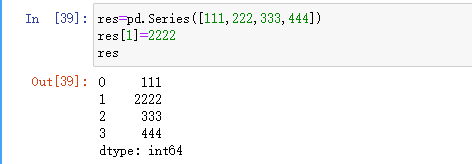
改:
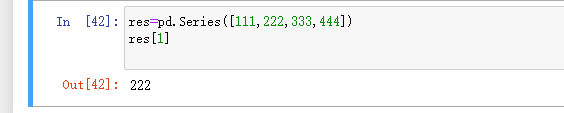
查:
算术运算符:
""" add 加(add) sub 减(substract) div 除(divide) mul 乘(multiple) """
加:
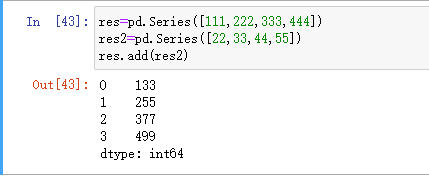
减:
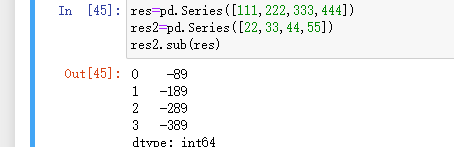
乘:
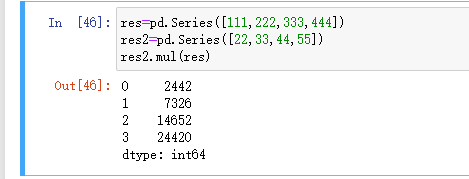
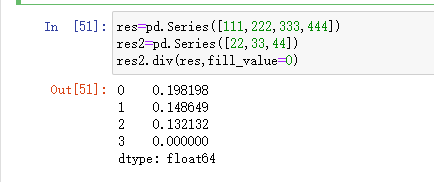
除:

当数据数量不相等时,可以通过fill_value=0或者其他数值
DataFrame创建方式:
表格型数据结构,相当于一个二维数组,含有一组有序的列也可以看作是由Series组成的共用一个索引的字典,呈现形式类似于表格
创建方式1:
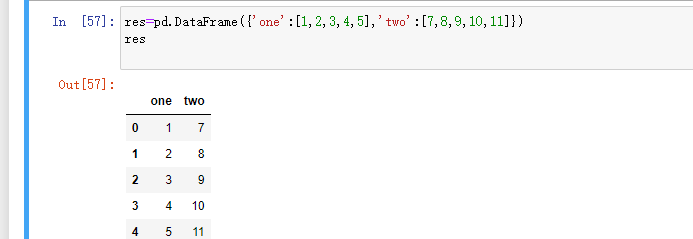
创建方式2:
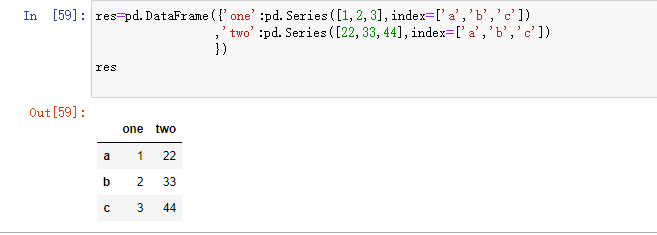
创建方式3:
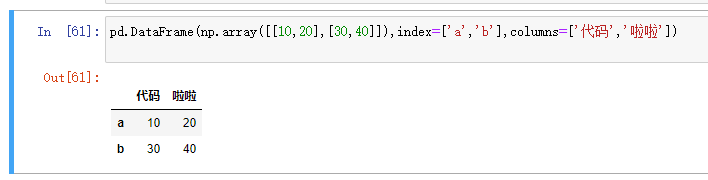
#以上创建方式都仅仅做一个了解即可因为工作中dataframe的数据一般都是来自于读取外部文件数据,而不是自己手动去创建
常见属性:
1.index 行索引
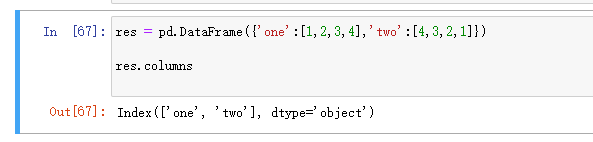
2.columns 列索引
3.T 转置
4.values 值索引
5.describe 快速统计
行索引:

列索引:
T转置:
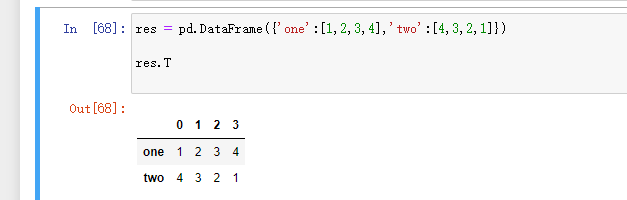
values 值索引:
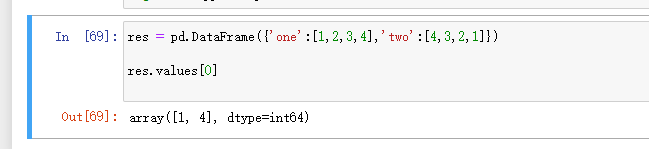
describe 快速统计

------------恢复内容开始------------
series数据操作:
增:
删:
改:
查:
算术运算符:
""" add 加(add) sub 减(substract) div 除(divide) mul 乘(multiple) """
加:
减:
乘:
除:
当数据数量不相等时,可以通过fill_value=0或者其他数值
DataFrame创建方式:
表格型数据结构,相当于一个二维数组,含有一组有序的列也可以看作是由Series组成的共用一个索引的字典,呈现形式类似于表格
创建方式1:
创建方式2:
创建方式3:
#以上创建方式都仅仅做一个了解即可因为工作中dataframe的数据一般都是来自于读取外部文件数据,而不是自己手动去创建
常见属性:
1.index 行索引
2.columns 列索引
3.T 转置
4.values 值索引
5.describe 快速统计
行索引:
列索引:
T转置:
values 值索引:
describe 快速统计
------------恢复内容开始------------
series数据操作:
增:
删:
改:
查:
算术运算符:
""" add 加(add) sub 减(substract) div 除(divide) mul 乘(multiple) """
加:
减:
乘:
除:
当数据数量不相等时,可以通过fill_value=0或者其他数值
DataFrame创建方式:
表格型数据结构,相当于一个二维数组,含有一组有序的列也可以看作是由Series组成的共用一个索引的字典,呈现形式类似于表格
创建方式1:
创建方式2:
创建方式3:
#以上创建方式都仅仅做一个了解即可因为工作中dataframe的数据一般都是来自于读取外部文件数据,而不是自己手动去创建
常见属性:
1.index 行索引
2.columns 列索引
3.T 转置
4.values 值索引
5.describe 快速统计
行索引:
列索引:
T转置:
values 值索引:
describe 快速统计
# 在DataFrame中所有的字符类型数据在查看数据类型的时候都表示成object

读取外部数据
pd.read_csv() # 可以读取文本文件和.csv结尾的文件数据 pd.read_excel() # 可以读取excel表格文件数据 pd.read_sql() # 可以读取MySQL表格数据 pd.read_html() # 可以读取页面上table标签内所有的数据
delimiter=None, header='infer', names=None, index_col=None, usecols=None, squeeze=False, prefix=None, mangle_dupe_cols=True, dtype=None, engine=None, converters=None, true_values=None, false_values=None, skipinitialspace=False, skiprows=None, skipfooter=0, nrows=None, na_values=None, keep_default_na=True, na_filter=True, verbose=False, skip_blank_lines=True, parse_dates=False, infer_datetime_format=False, keep_date_col=False, date_parser=None, dayfirst=False, cache_dates=True, iterator=False, chunksize=None, compression='infer', thousands=None, decimal: str = '.', lineterminator=None, quotechar='"', quoting=0, doublequote=True, escapechar=None, comment=None, encoding=None, dialect=None, error_bad_lines=True, warn_bad_lines=True, delim_whitespace=False, low_memory=True, memory_map=False, float_precision=None, storage_options: Union[Dict[str, Any], NoneType] = None, )
常用的这些:
pd.read_csv(filepath_or_buffer, sep=',', header='infer', names=None, usecols=None, skiprows=None, skipfooter=None, converters=None, encoding=None)
filepath_or_buffer:指定txt文件或者.csv文件所在的具体路径
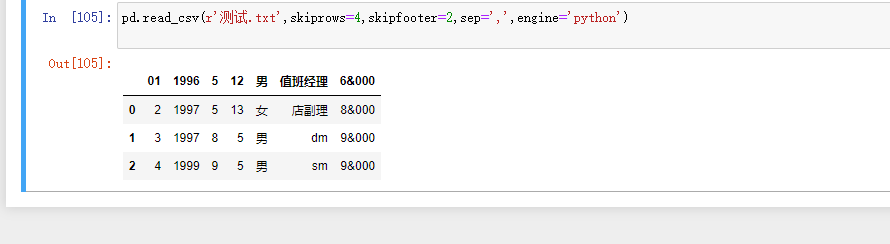
sep:指定原数据集中各字段之间的分隔符,默认为逗号”,”
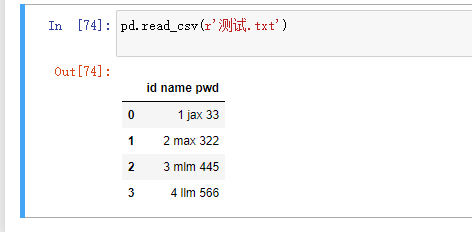
不加是这样 加了sep之后 指定是空格
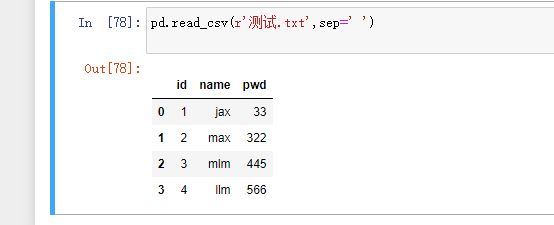
header:是否需要将原数据集中的第一行作为表头,默认将第一行用作字段名称如果原始数据没有表头需要将该参数设置为None
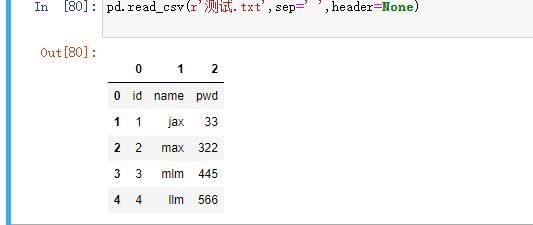
names:如果原数据集中没有字段,可以通过该参数在数据读取时给数据框添加具体的表头
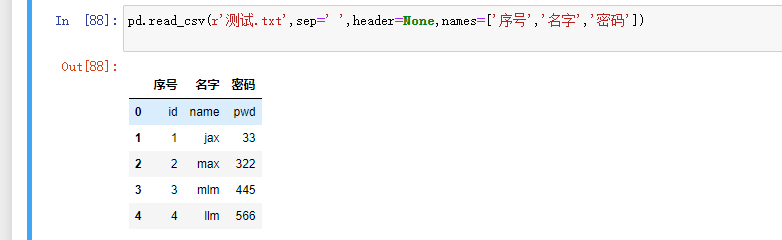
usecols:指定需要读取原数据集中的哪些变量名
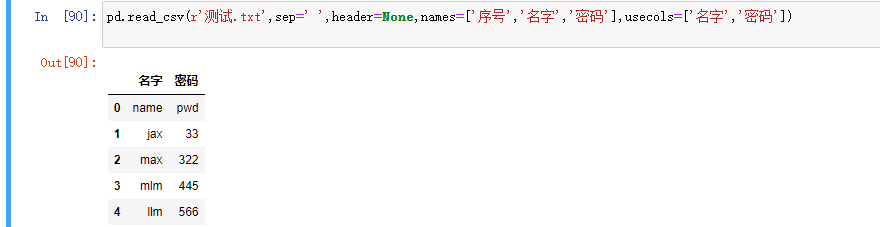
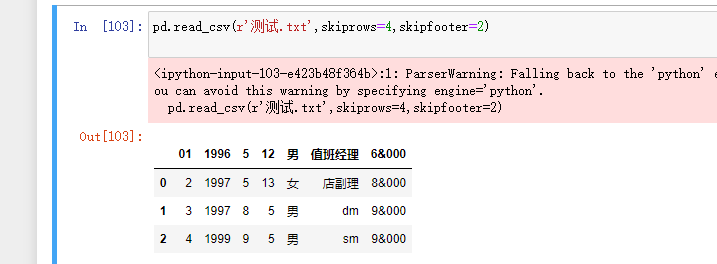
skiprows:数据读取时,指定需要跳过原数据集开头的行数有一些表格开头是有几行文字说明的,读取的时候应该跳过
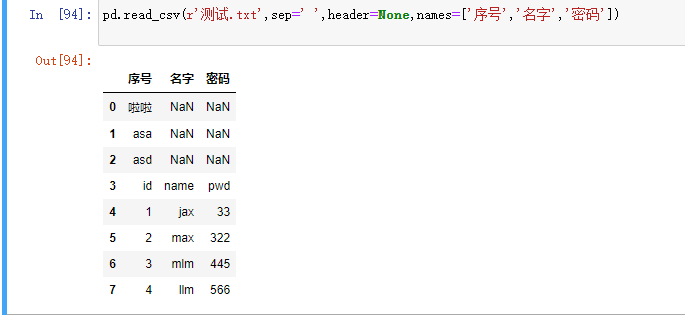

skipfooter:数据读取时,指定需要跳过原数据集末尾的行数和skiprows用法一样
converters:用于数据类型的转换(以字典的形式指定)
encoding:如果文件中含有中文,有时需要指定字符编码
基本使用:
现有数据

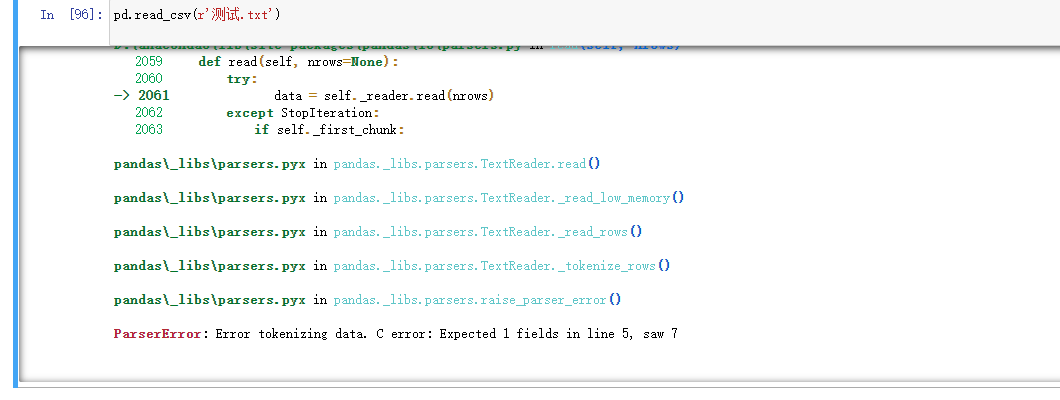
如果直接读取的话 会报错 是因为开头的数据不是有效数据,需要添加skiprows参数 python能自动过滤掉完全无内容的空行(写2、3都行)
如果出现了乱码的现象,加上encoding='utf8'

出现报错 加上engine='python'即可
header=None
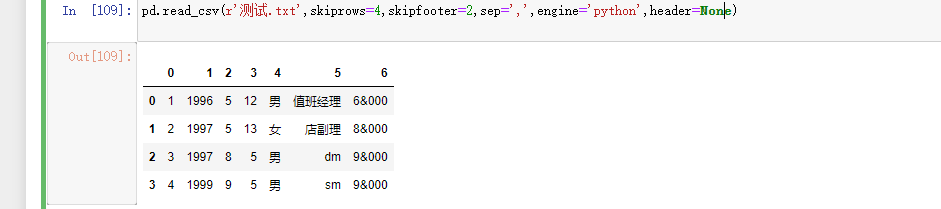
names=['序号','年份','月份','日','性别','岗位','薪资']

thousands = '&' 指定千分位
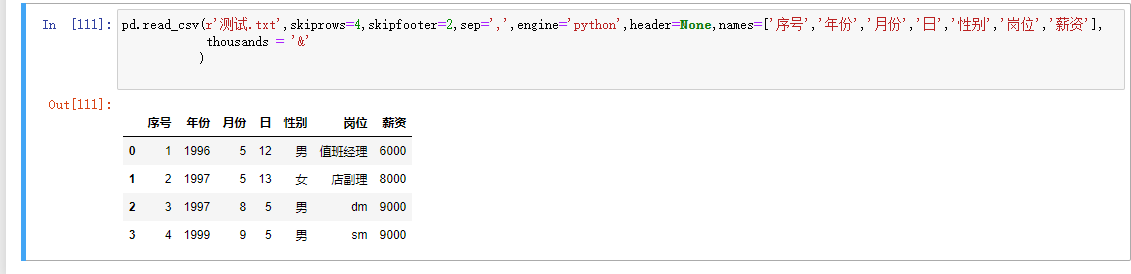
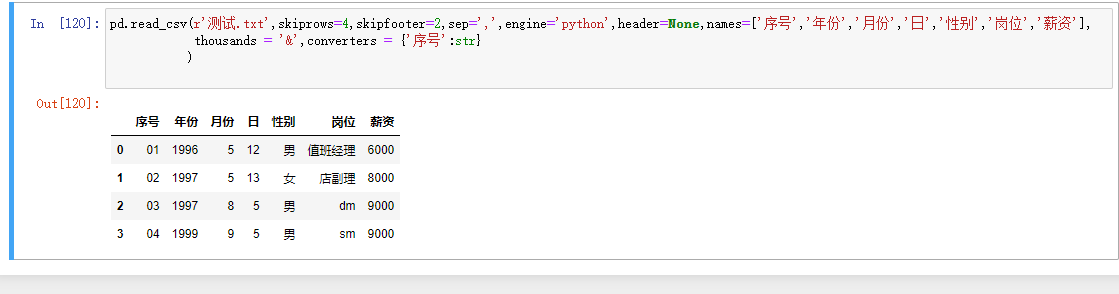
converters = {'id':str}针对id原本是01、02自动变成了1、2...
pd.read_excel(io, sheetname=0, header=0, skiprows=None, skip_footer=0, index_col=None, names=None,
na_values=None, thousands=None, convert_float=True)
现有excel表格数据:
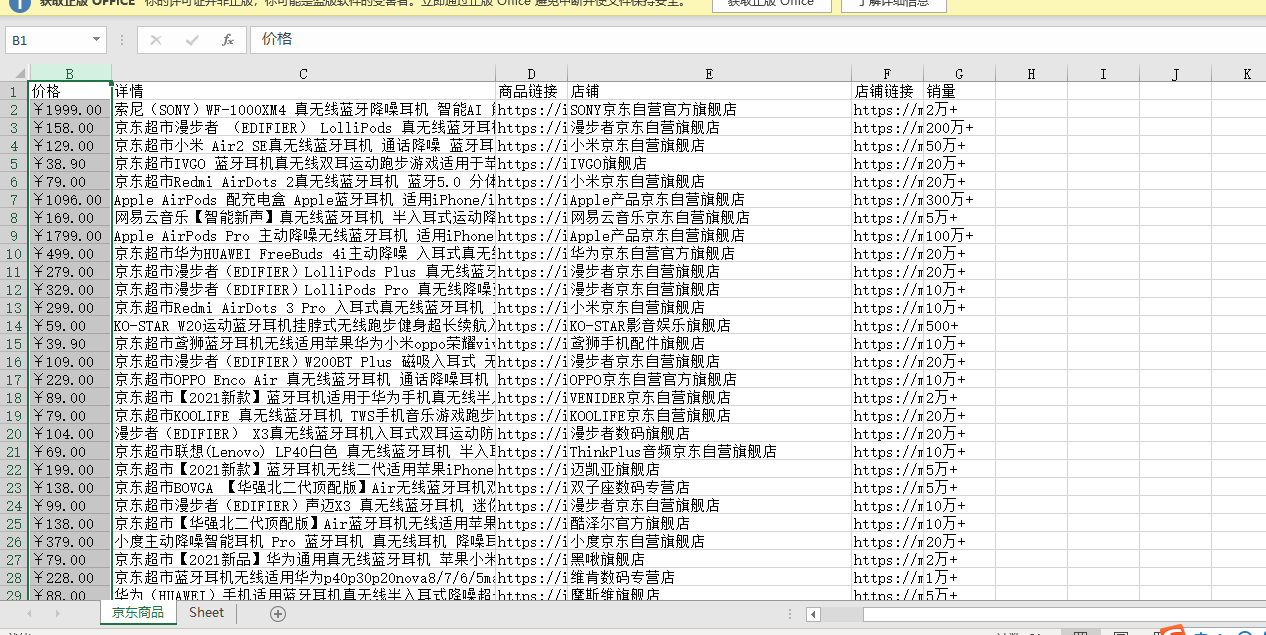
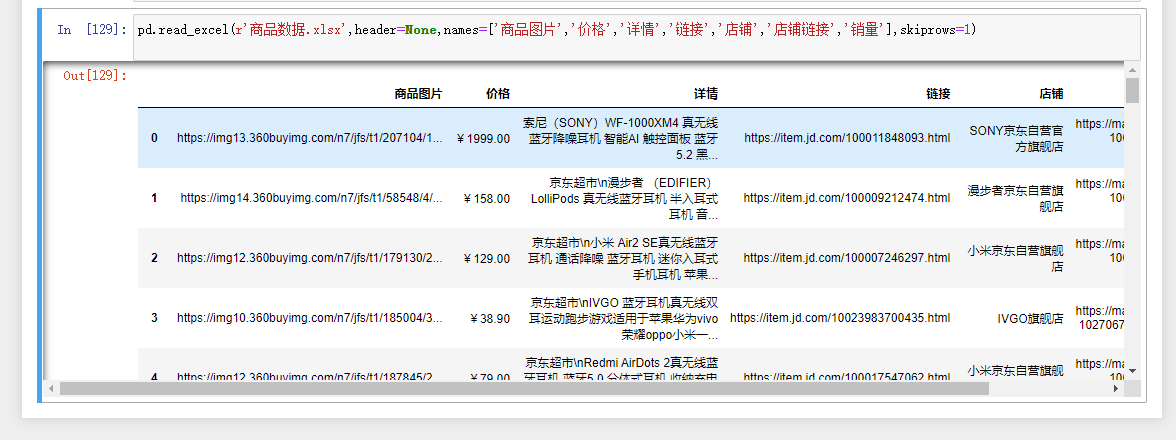
io:指定电子表格的具体路径

sheet—name:指定需要读取电子表格中的第几个Sheet,既可以传递整数也可以传递具体的Sheet名称
同样也有 header=以及names=参数
index_col:指定哪些列用作数据框的行索引(标签)
na_values:指定原始数据中哪些特殊值代表了缺失值
thousands:指定原始数据集中的千分位符
convert_float:默认将所有的数值型字段转换为浮点型字段
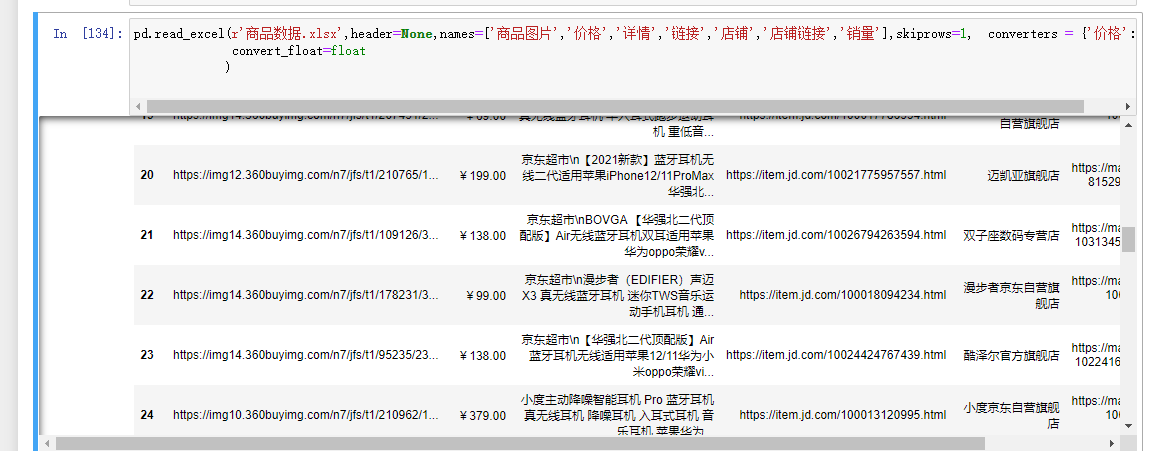
converters:通过字典的形式,指定某些列需要转换的形式
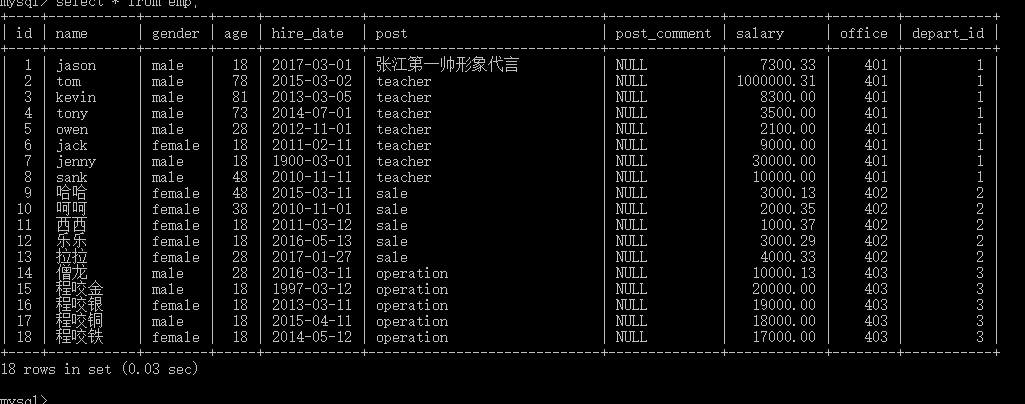
conn = pymysql.connect(host,port,user,password, database, charset)
host:指定需要访问的mysql服务器
port:访问mysql端口号
user:指定mysql数据库用户名
password:指定访问mysql数据库密码
database:指定访问mysql具体库名

运行后没有报错 就可以读取库下的表格书数据
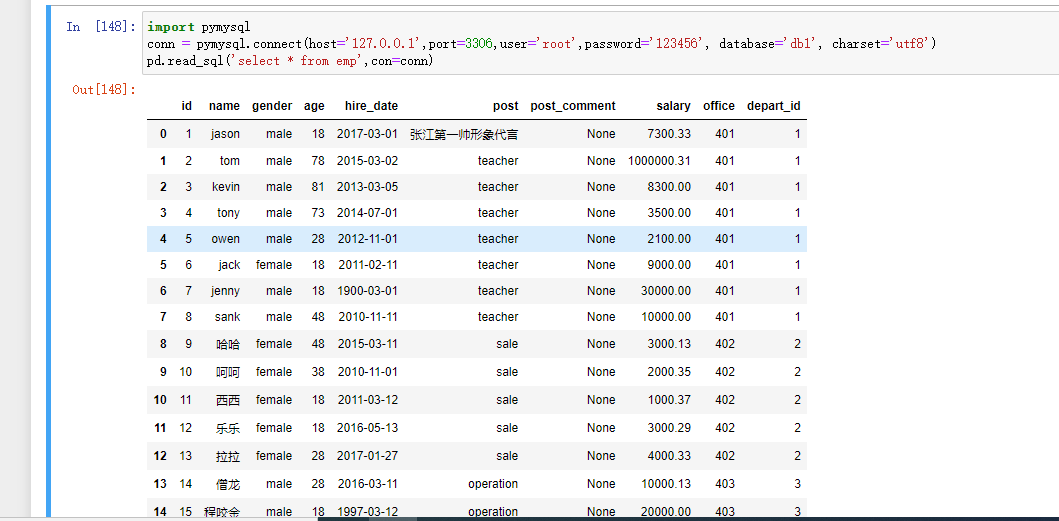
记得conn.close()关闭链接

pd.read_html(r'https://baike.baidu.com/item/NBA%E6%80%BB%E5%86%A0%E5%86%9B/2173192?fr=aladdin')
获得的是一个列表 可以进行索引取值

df.columns # 查看列

df.index # 查看行

df.shape # 行列
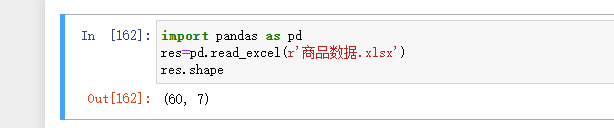
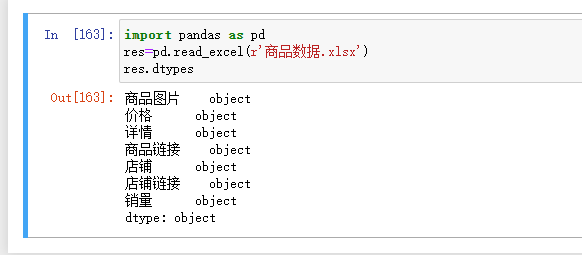
df.dtypes # 数据类型
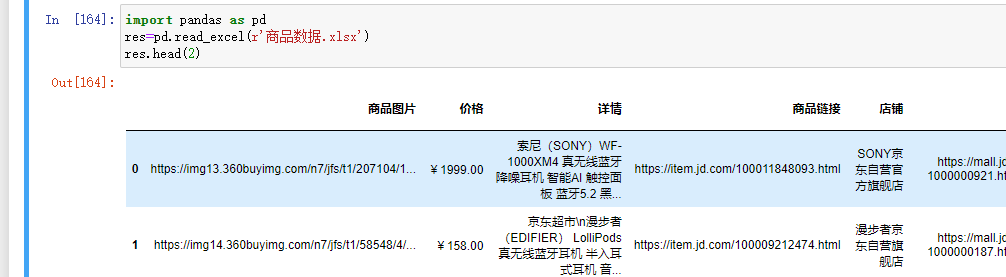
df.head() # 取头部多条数据
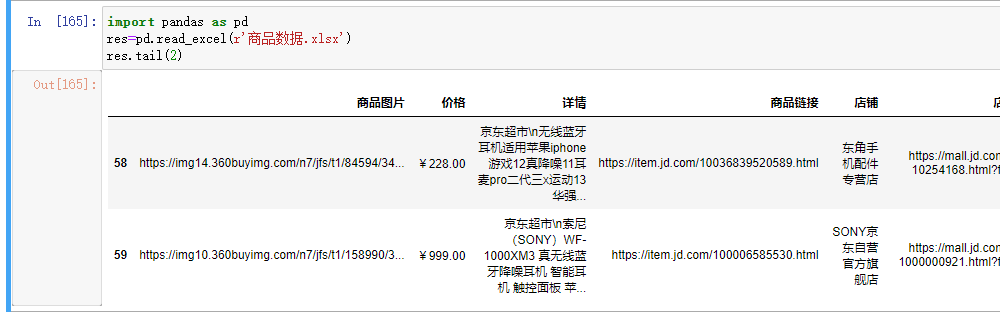
df.tail() # 取尾部多条数据
行列操作:
1.获取指定列对应的数据

2.重命名列字段名称
df.rename(columns={'旧列名称':'新列名称'})
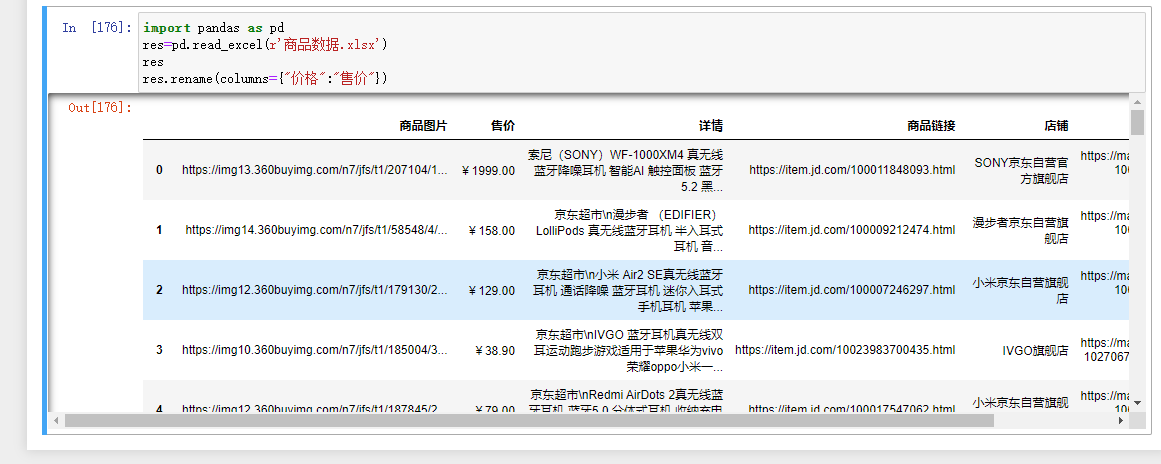
这里直接显示了 所以原数据并没有改变只是在显示中改变了
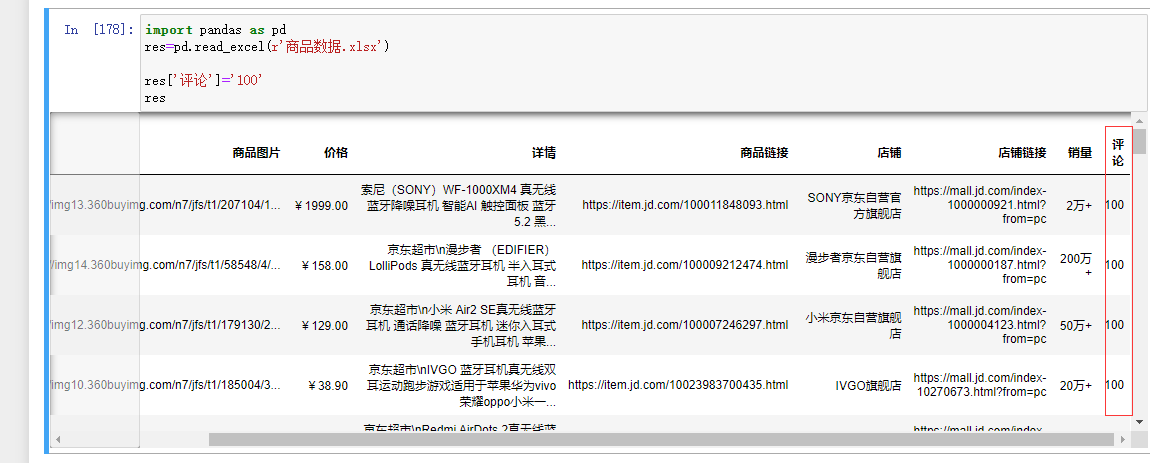
3.创建新的列:
res[''']=''
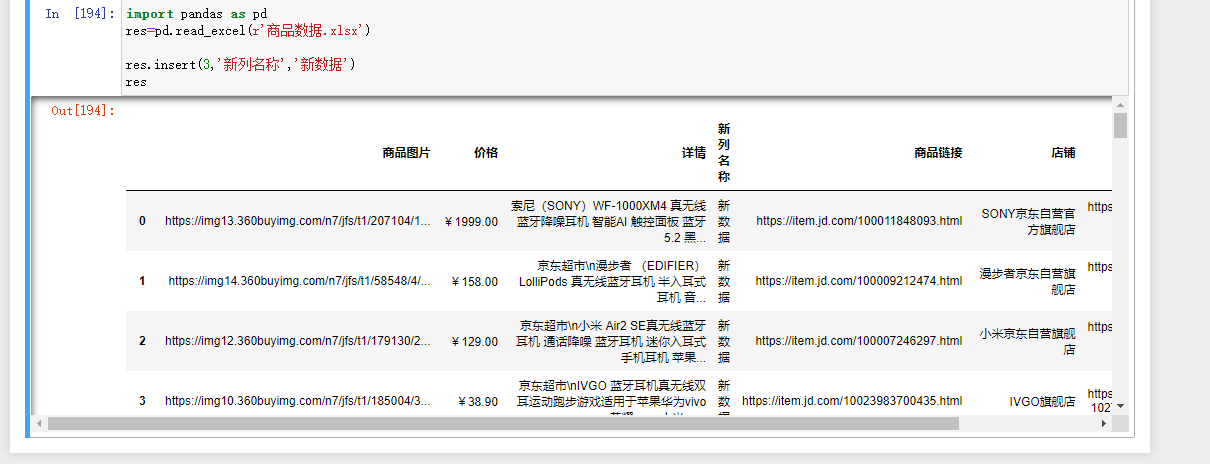
4.自定义位置
res.insert(3,'新列名称',新数据)
5.添加行
res1=res.append(res2)
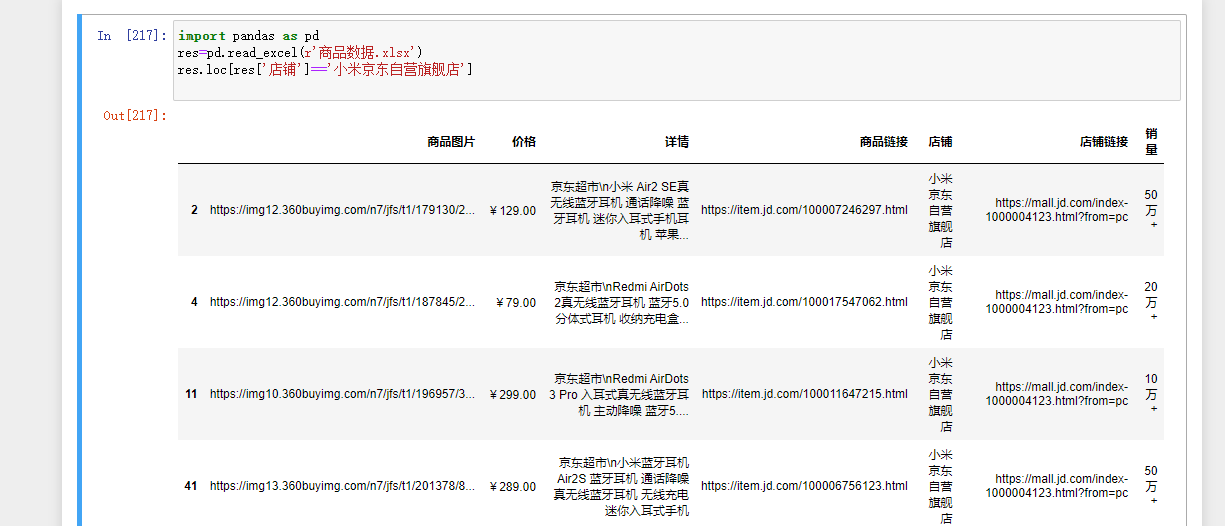
数据筛选:
获取多个指定列数据:

获取指定行数据:
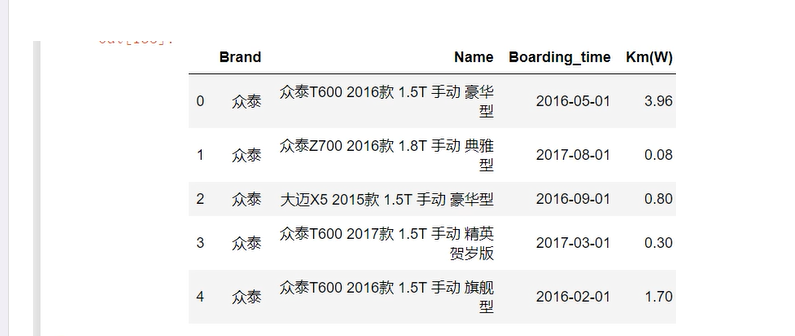
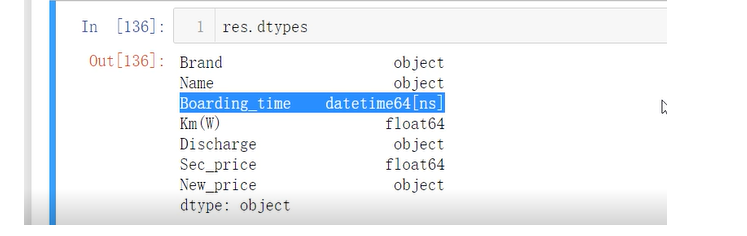
sec_car = pd.read_csv(r'sec_cars.csv') sec_car.head() sec_car.dtypes sec_car.Boarding_time = pd.to_datetime(sec_car.Boarding_time, format = '%Y年%m月')

 浙公网安备 33010602011771号
浙公网安备 33010602011771号