

selenium模块
关于selenium模块:
该模块最初是一个自动化测试工具,但是由于可以自动操作浏览器的功能,可以应用到爬虫领域,并且可以做到避免了很多防爬措施.
模块下载:
pip3 install selenium
file-setting-项目文件-双击搜索 输入selenium 选择国内源
驱动下载:(必不可少)
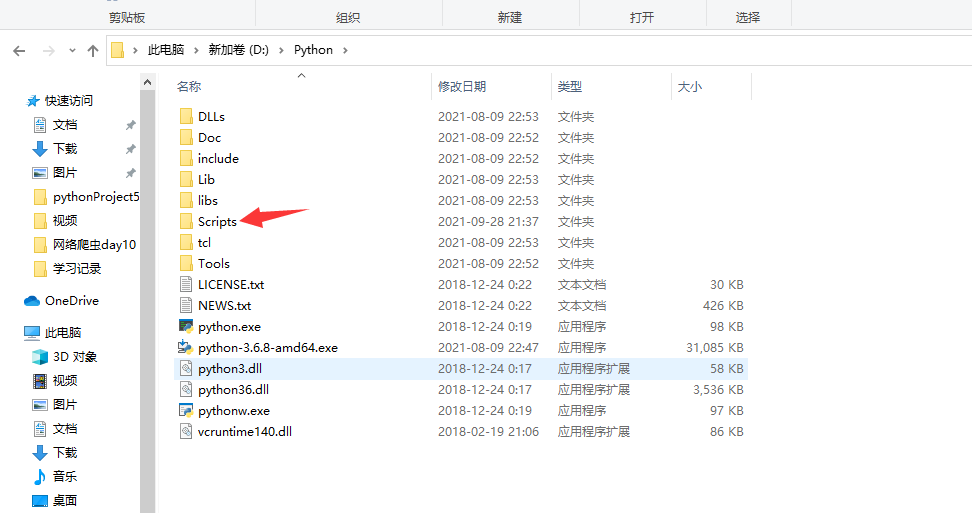
建议直接存放在python解释器中的script文件夹内即可
下载网址:http://npm.taobao.org/mirrors/chromedriver/2.35/
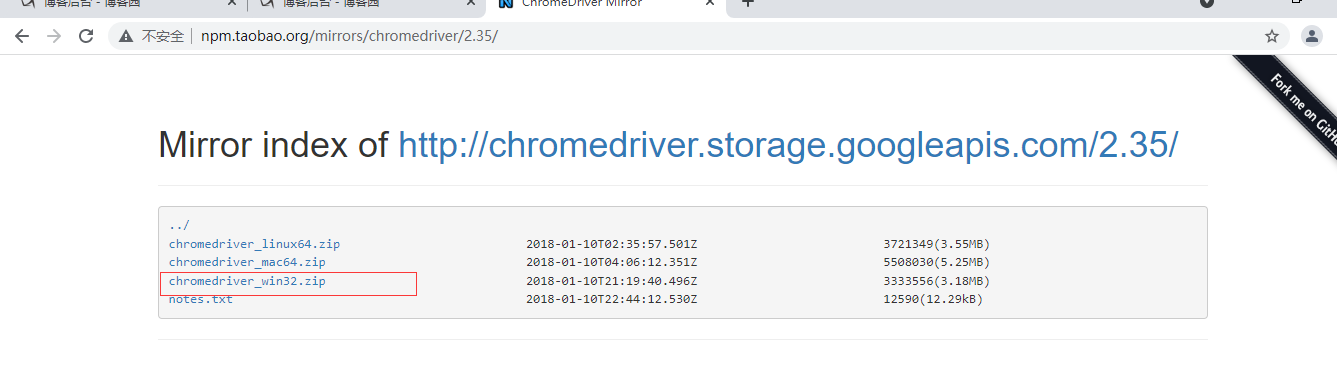
用什么浏览器就下载对应浏览器的类型,win64位兼容32位
解压到使用python的文件夹内部的scripts即可
安装完成
------------恢复内容开始------------
关于selenium模块:
该模块最初是一个自动化测试工具,但是由于可以自动操作浏览器的功能,可以应用到爬虫领域,并且可以做到避免了很多防爬措施.
模块下载:
pip3 install selenium
file-setting-项目文件-双击搜索 输入selenium 选择国内源
驱动下载:(必不可少)
建议直接存放在python解释器中的script文件夹内即可
下载网址:http://npm.taobao.org/mirrors/chromedriver/2.35/
用什么浏览器就下载对应浏览器的类型,win64位兼容32位
解压到使用python的文件夹内部的scripts即可
安装完成
爬取城市数据https://www.aqistudy.cn/historydata/
需求 爬取热门城市及其他城市
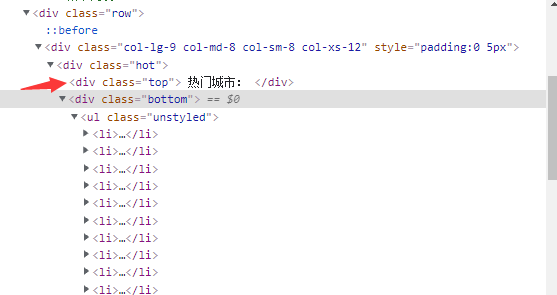
热门城市在div class=hot 中
hot_name=html.xpath('//div[@class="hot"]/div[2]/ul/li/a/text()')
其他城市在div class=all中
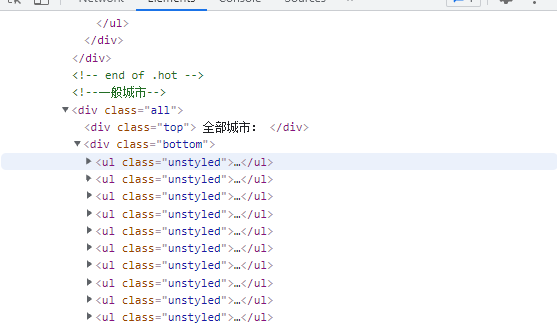
all_name=html.xpath('//div[@class="all"]/div[2]/ul/div[2]/li/a/text()')
import requests from lxml import etree headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.61 Safari/537.36'} res=requests.get('https://www.aqistudy.cn/historydata/',headers=headers) # 通过检查文本发现有防爬措施,添加请求头useragent html=etree.HTML(res.text) hot_name=html.xpath('//div[@class="hot"]/div[2]/ul/li/a/text()') # print(li_list) all_name=html.xpath('//div[@class="all"]/div[2]/ul/div[2]/li/a/text()') full_name=hot_name+all_name print(full_name) """ 也可以写成 full_name=html.xpath('//div[@class="hot"]/div[2]/ul/li/a/text()|//div[@class="all"]/div[2]/ul/div[2]/li/a/text()') """
爬取猪八戒岗位
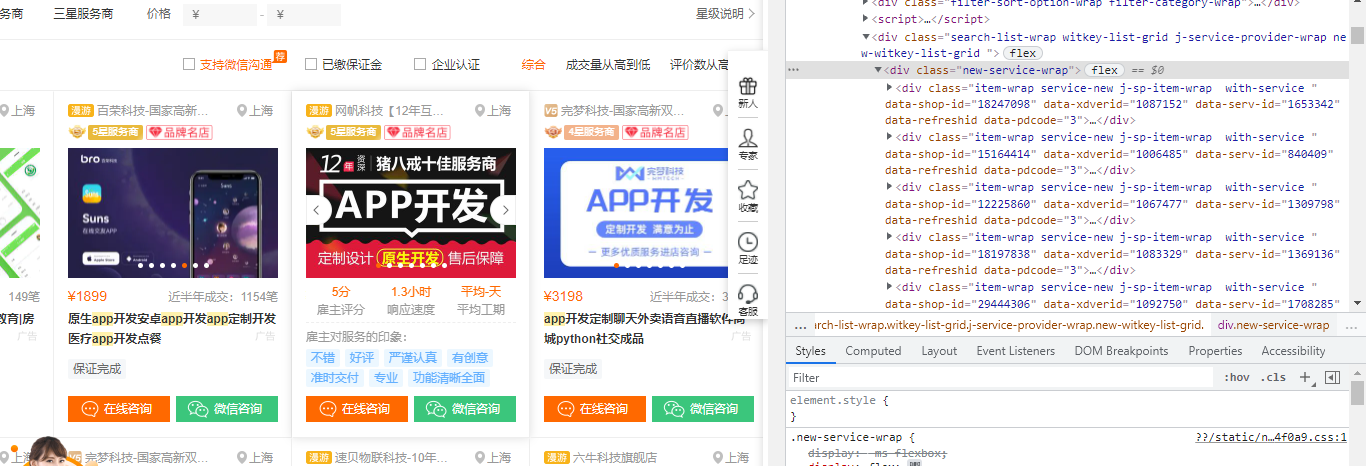
每个项目都在class="new-service-wrap"中 只需逐一查找各个内容所在的标签即可
import requests from lxml import etree from openpyxl import Workbook wb=Workbook() wb1=wb.create_sheet('岗位表',0) wb1.append(['公司名','位置','价格','成交量(近半年)','介绍']) headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.61 Safari/537.36'} res=requests.get('https://shanghai.zbj.com/search/f/',params={'kw':'app'}) list=etree.HTML(res.text) name_list=list.xpath('//div[@class="new-service-wrap"]/div') for div in name_list: name=div.xpath('./div/div/a/div[1]/p/text()') if not name: # 针对广告位没有名字 添加if not 判断 continue 继续循环 continue com_name=name[-1].strip() # 由于是另起一行所以需要去掉/n符号 # print(com_name) loc=div.xpath('./div/div/a/div[1]/div/span/text()')[0] # print(loc) price=div.xpath('./div/div/a[2]/div[2]/div/span[1]/text()')[0] amout=div.xpath('./div/div/a[2]/div[2]/div/span[2]/text()')[0] src=div.xpath('./div/div/a[2]/div[2]/div[2]/p/text()') src1=('app'.join(src)) wb1.append([com_name,loc,price,amout,src1]) wb.save('岗位表.xlsx')
爬取百度贴吧
思路: 1.观察网页规律,获取请求方式,为普通加载
2.搜索什么贴吧 后面网址都会有kw:xxx的请求头
3.朝初第一次网址发送请求,筛选出所有帖子的网址
4.通过观察每个帖子的网址规律发现 网址由baidu.tieba.com+各个href属性拼接而成
5.完成网址拼接,向拼接网址发送请求,进入每个帖子网站
6.筛选出每个帖子的网站的图片标签地址
7.循环这些图片标签地址并写入文件夹内
import requests import os from lxml import etree import time choice=input('输入你想逛的贴吧') if not os.path.exists('贴吧图片'): os.mkdir('贴吧图片') params={'kw':choice} headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.61 Safari/537.36'} res=requests.get('https://tieba.baidu.com/f',params=params) # 这里注意不要加user agent 否则会找不到内容 tree=etree.HTML(res.text) src=tree.xpath('//a[@class="j_th_tit "]/@href') #由于每个贴子地址都是一样的 所以直接找a标签中的href属性 time.sleep(1) # print(src) base_src='https://tieba.baidu.com' #每个帖子的网址就是之前的https://tieba.baidu.com加上href属性内容即可 for link in src: # 循环获取link标签 即 href属性 在src这个所有列表中 real_src=base_src+link # 完成每个帖子的拼接 # print(real_src) time.sleep(1) res1=requests.get(real_src) #向拼接完毕的地址发送请求 time.sleep(1) tree1=etree.HTML(res1.text) img=tree1.xpath('//img[@class="BDE_Image"]/@src') #获得地址的图片标签地址 time.sleep(1) # print(img) for img_src in img: #对这些图片的标签地址进行for循环 res2=requests.get(img_src) #向图片地址发送get请求 time.sleep(1) file_path=os.path.join('贴吧图片',img_src[-15:]) #做文件路径拼接 with open(file_path,'wb') as f: f.write(res2.content)# 以二进制模式写入文件

