

爬虫简单操作
因为http协议无状态的特点导致服务端向浏览器客户端发送数据完毕之后并不会保存用户端状态
早期的网站不需要保存用户状态,所有人访问的网站都是相同的数据
随着时代的发展,越来越多的网站需要有注册登录等功能
这时候就需要cookies来保存客户端浏览器上面的键值对数据
即用户第一次登陆成功之后浏览器会保存用户名和密码
而session就是保存在服务端上面的用户相关的数据
只要涉及到用户登陆都要使用到cookie
浏览器也可以拒绝保存数据
cookie实战
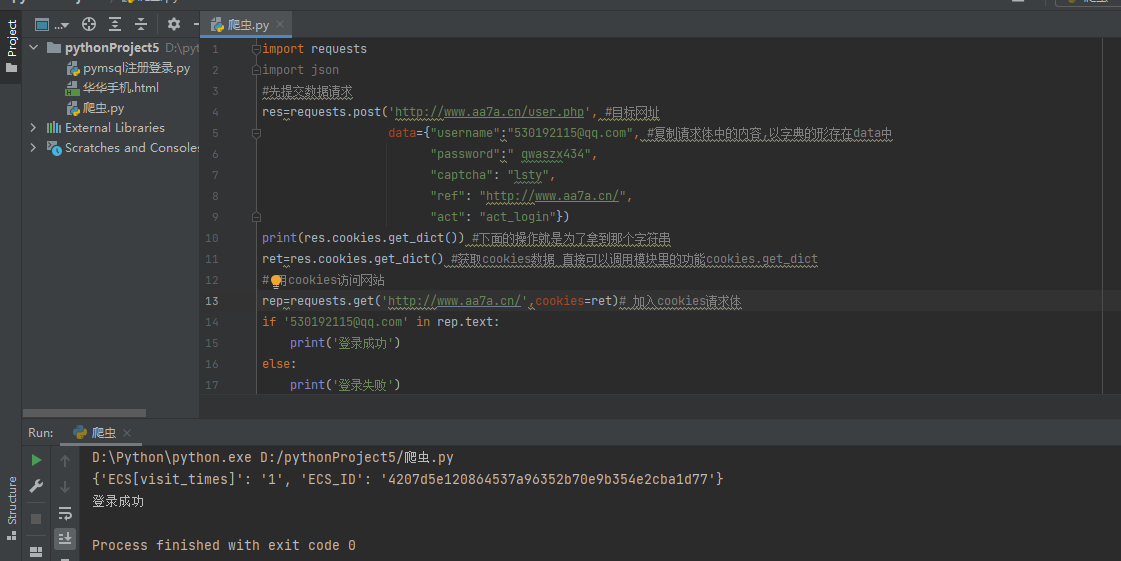
浏览器network选项中 请求体对应的关键字是Form Data

请求体的数据格式:
username: 13585515712 password: 123456789 captcha: lsty ref: "http://www.aa7a.cn/user.php?act=logout" act: act_login
import requests import json #先提交数据请求 res=requests.post('http://www.aa7a.cn/user.php', #目标网址 data={"username":"530192115@qq.com", #复制请求体中的内容,以字典的形存在data中 "password":" qwaszx434", "captcha": "lsty", "ref": "http://www.aa7a.cn/", "act": "act_login"}) print(res.cookies.get_dict()) #下面的操作就是为了拿到那个字符串 """ 用户名或密码错误的情况下返回的cookie数据 {'ECS[visit_times]': '1', 'ECS_ID': '69763617dc5ff442c6ab713eb37a470886669dc2'} 用户名和密码都正确的情况下返回的cookie数据 { 'ECS[password]': '4a5e6ce9d1aba9de9b31abdf303bbdc2', 'ECS[user_id]': '61399', 'ECS[username]': '616564099%40qq.com', 'ECS[visit_times]': '1', 'ECS_ID': 'e18e2394d710197019304ce69b184d8969be0fbd' } """ ret=res.cookies.get_dict() #获取cookies数据 直接可以调用模块里的功能cookies.get_dict # 用cookies访问网站 rep=requests.get('http://www.aa7a.cn/',cookies=ret)# 加入cookies请求体 if '530192115@qq.com' in rep.text: print('登录成功') else: print('登录失败')
import requests response=requests.get('https://www.bilibili.com/video/BV1LK4y1W7v3/?spm_id_from=333.788.recommend_more_video.0',stream=True) with open(r'爬视频.mp4','wb')as f: for line in response.iter_content():# 一行行读取内容
f.write(line)#一行行写入 避免内存爆炸

json格式
json格式数据最大的特点就是引号一定是双引号
在网络爬虫数据,内部很多采用的都是json格式来做交互的
前后端数据交互一般都使用的json格式

import requests res=requests.get('https://api.bilibili.com/x/player/pagelist?bvid=BV1LK4y1W7v3&jsonp=jsonp') print(res.json()) # .json 直接将json格式字符串转换成python对应的数据类型
SSL相关报错
仅针对苹果本报错 可以通过百度解决
防爬措施2 ip代理池
有些服务端针对客户端的ip地址存在防爬措施
比如一分钟请求了很多次如果超出了设定的次数,就会封禁ip地址
针对这种情况
可以搜索ip代理池
选用一些免费的ip地址选几个用上就行
import requests proxies={ 'http':'114.99.223.131:8888', 'http':'119.7.145.201:8080', 'http':'175.155.142.28:8080', } respone=requests.get('https://www.12306.cn', proxies=proxies)
其实就是对自己的ip地址进行掩饰
但是如果只使用一层ip代理池 其实还是能反追到真正的ip地址
与ip代理池相同,针对防爬cookie
可以自己先注册好多账号,然后放到文件里去随机选择
respone=requests.get('https://www.12306.cn', cookies={})

