爬虫入门
re模块代码结构
import re res=""" max maxl max2 max """ ret=re.findall('m.*?x',res) print(ret)
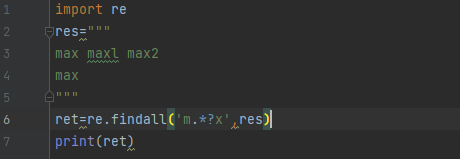
返回的是一个列表,内部包含了正则匹配到的所有数据
因为是全局匹配所以 不会匹配到一个相符的就停止
import re res=""" max maxl max2 max """ ret=re.finditer('m.*x',res) for i in ret: print(i)

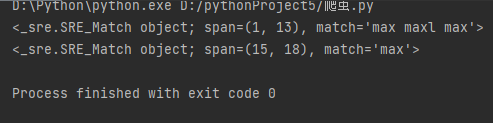
返回的是个迭代器比直接返回数据更加节省内存
只有主动添加.group才能索要数据
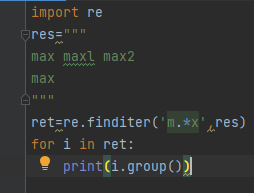

import re res=""" max maxl max2 max """ ret=re.search('m.*?x',res) print(ret)

只会匹配到一个符合结果的数据就结束
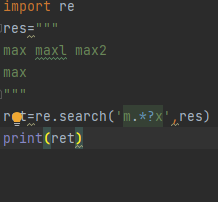
import re res=""" max maxl max2 max """ ret=re.match('m.*?x',res) print(ret)
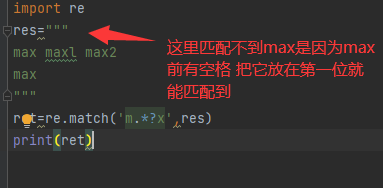

从头开始匹配 一旦第一个条件不匹配立马就停止
import re ret = re.findall('www.(oldboy).com', 'www.oldboy.com') print(ret)
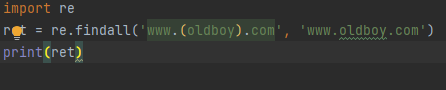

使用findall 内部加括号时 会优先匹配括号内的内容
ret1 = re.findall('www.(?:oldboy).com', 'www.oldboy.com') print(ret1)
可以使用?:取消优先匹配 其实和不加任何东西效果是一样的




爬虫模块之requests
模拟浏览器向网络请求获取数据
requests 是第三方模块点击下方terminal
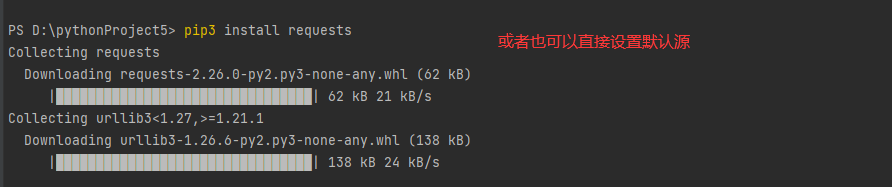
输入 pip3 install requests -i http://mirrors.aliyun.com/pypi/simple/ #通过换国内数据源提升下载速度

输入网址按回车就是在向百度服务器发送get请求索要首页
get请求也可以携带额外的条件数据,但是数据只有2-4kb并且直接写在网址后面
url?xxx=yyy&zzz=mmm

post请求(朝服务端发送数据)
朝别人提交数据
post请求也可以携带额外的数据 并且数据大小没有限制 敏感性的数据都是由post请求携带
HTTP协议
1.四大特性
1.基于请求响应(只有请求才会有相应)
2.基于TCP、IP作用于应用层之上的协议
3.无状态(数据响应完成之后服务端不会记住任何浏览器)
不保存客户端的状态
4.无连接
2.数据请求格式
请求首行 (请求方法,地址)
请求头(一堆k:v键值对)
请求体(get中没有)
响应首行(协议版本,状态码)
响应头(一堆k:v键值对)
响应体(浏览器展示给用户看的数据)
3.响应状态码
1xx:请求成功,服务器正在处理 继续上传或者等待
2xx:200ok 成功请求
3xx:重定向(原本要打开a页面 点击之后却打开了b页面)
4xx:403 请求不符合条件 404 找不到资源
5xx:服务器内部问题
import requests requests.get(url) # 发送get请求 requests.post(url) # 发送post请求
import requests # 朝百度发送get请求获取首页数据 res = requests.get('https://www.baidu.com/') # print(res.status_code) # 获取响应状态码 # 指定字符编码 # res.encoding = 'utf8' # print(res.text) # 获取网页字符串数据 # print(res.content) # 获取bytes类型的数据(在python中可以直接看成是二进制) with open(r'baidu.html', 'wb') as f: f.write(res.content)
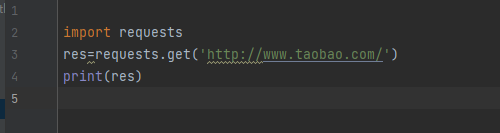

print(res.status_code) # 获取响应状态码
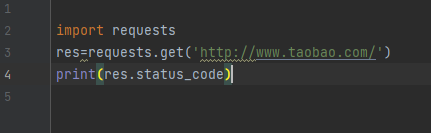

res.encoding='utf8' # 转码
print(res.text) # 获取网页字符串数据

需要转码~
print(res.content) # 获取bytes类型的数据(在python中可以直接看成是二进制)
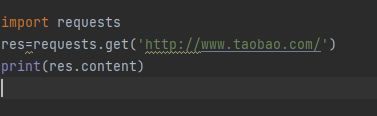
携带参数的get请求
requests.get(url,params={})
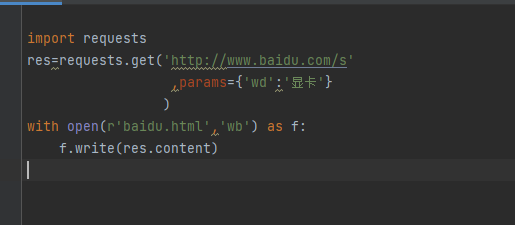
但是网页并不能打开
用于校验当前请求是否是浏览器发出的
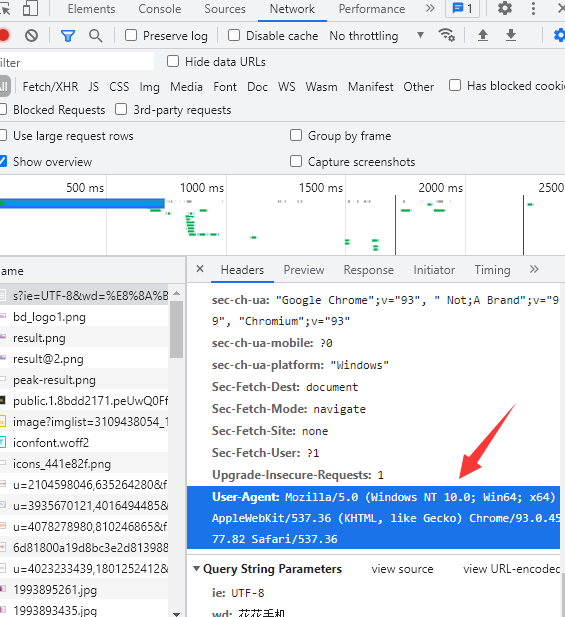
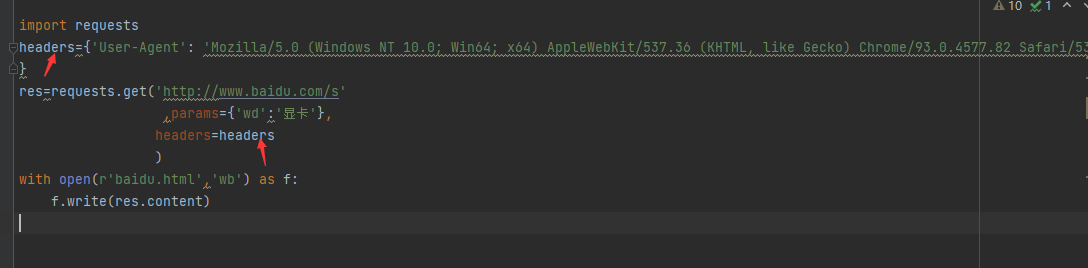
即可将自己伪装成浏览器访问页面 完成访问