关于网络爬虫
使用pymysql模块完成登录注册


import pymysql # 调用第三方pymysql模块 conn = pymysql.connect( host='127.0.0.1', # ip地址 port=3306, # 端口号 user='root', # mysql 登录用户名 password='123456', # mysql 登录密码 database='t3', # 使用的database charset='utf8', # 定义字符编码 autocommit=True, # 自动确认sql命令 ) # 自定义参数 cursor = conn.cursor(cursor=pymysql.cursors.DictCursor) # 行成游标对象 def login(): # 定义登录部分 username = input('username>>>:').strip() # 获取用户名 password = input('password>>>:').strip() # 获取密码 if len(username) == 0 or len(password) == 0: # 定义用户名和密码不能为空 print('用户名或密码不能为空') # 打印结果 return sql = 'select * from userinfo where username=%s' # sql命令 从 userinfo中找一个输入的username cursor.execute(sql, (username)) # 执行sql语句,并将避免了sql注入现象 res = cursor.fetchall() # 获取所有的数据库数据 列表套字典的形式 if res: # 如果用户名存在 进入校验密码步骤 user_dict = res[0] # 获取第一条列表中字典数据 if str(user_dict.get('password')) == password: # 从字典中获取的密码 如果等于用户输入的密码 print('%s登录成功' % username) # 打印登录成功 else: print('用户名或者密码错误') # 密码不匹配打因登录失败 else: print('用户名不存在请先注册') # 用户名如果不存在 打印请先注册 def register(): username = input('username>>>:').strip() # 获取用户名 password = input('password>>>:').strip() # 获取密码 if len(username) == 0 or len(password) == 0: # 定义用户名和密码不能为空 print('用户名或密码不能为空') # 打印结果 return sql = 'select * from userinfo where username=%s' # sql命令 从 userinfo中找一个输入的username cursor.execute(sql, (username)) # 执行sql语句,并将避免了sql注入现象 res = cursor.fetchall() # 获取所有的数据库数据 列表套字典的形式 if res: print('用户名已存在') # 如果用户名重复则打印用户已存在 else: sql = 'insert into userinfo(username,password) values(%s,%s)' # sql语句 从userinfo中插入 用户输入的username 和password cursor.execute(sql, (username, password)) # 执行sql语句 并将关键词username 和password传入 避免了sql 注入 print('%s注册成功' % username) # 打印用户注册成功 while True: func_dict = {'1': register, '2': login} # 定义一个字典,1对应注册部分 2 对应登录部分 print(""" 1.注册 2.登录 """) choice = input('请选择想要的功能').strip() # 获取用户输入的序列号 # 如果用户输入的是1 或者2 则获取到用户输入的内容 并执行1 或者2 if choice in func_dict: func_name = func_dict.get(choice) func_name() else: print('请选择正确的序列号') # 如果输入的不是1或者2 则打印内容
常见收集数据网站(免费类)
1.百度指数网址
百度搜索关键字的网站,有大量的用户搜索数据
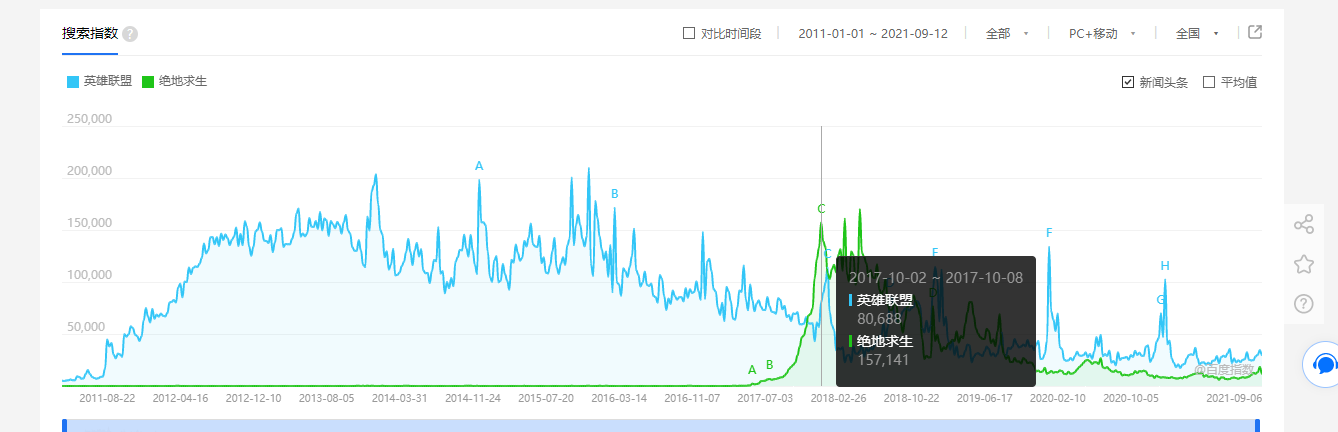
可以相对直观的看出一个事物被用户搜索的次数
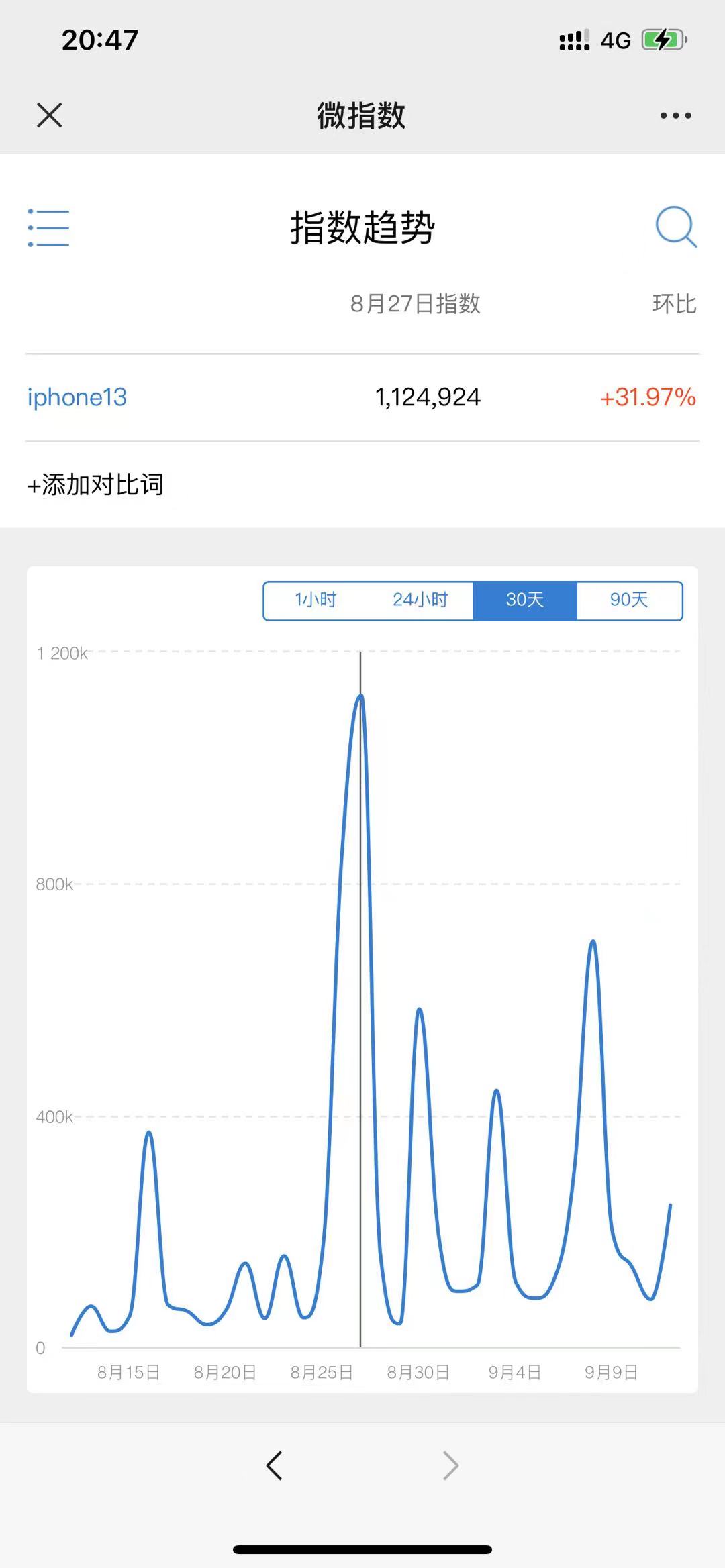
2.新浪指数网址
关于新浪搜索热搜的数据收集网站
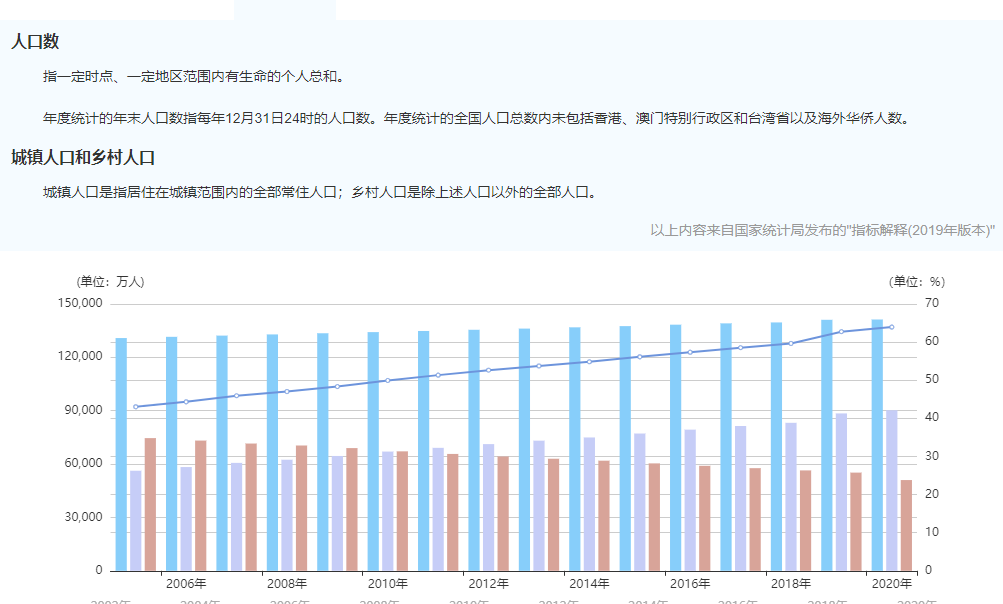
3.国家数据网站
能够获取关于一些国家公开展示的数据 但数据普遍滞后,更新会较慢
以及一些境外的数据网站,加载速度会较国内网站慢很多
4.世界银行
5.纳斯达克
6.联合国数据网
# 这类国外网站大部分都是英文
常见收集数据网站(收费类)
1.艾瑞咨询
可以为用户量身打造数据服务并提供研究报告等

2.埃森哲 (境外)
也是数据服务相关的内容网站
3.麦肯锡 (境外)
第三方平台:
4.数据堂 (人工智能数据网站)
5.贵阳大数据 (功能较多,收费便宜)
抓取互联网上的数据,为我所用,有了大量的数据,就如同有了一个数据银行一样,下一步做的就是如何将这些爬取的数据产品化,商业化。
爬虫的分类
通用爬虫
其实我们日常使用的浏览器就是一个巨大的爬虫
以百度为例 百度就是去互联网爬取所有的数据,把你需要的数据并保存到自己的本地,用户再通过百度客户端获取到百度的信息
1.搜索引擎如何获取一个网站URL?
(1).主动向搜索引擎提交网址
网址收录
(2).在其他网址设置网站外链(友情链接)
彼此引流之外,可以让搜索引擎一次性把网站全部收入
(3).与DNS服务商合作(DNS即域名解析技术)
简便获取ip地址:ping URL -t
2.关于robots协议
通用爬虫并不是万物皆可爬需要遵循robots协议
协议内会指明可以爬取网页的部分
但是协议是双方的可以不用遵循
#通常大型网络爬虫会遵循
3.通用爬虫工作流程
爬取网页 存储数据 内容处理 提供检索及排名服务
排名:
1.PageRank值
根据网站的流量(点击、浏览、人气)统计
2.竞价排名
通过付费提升排名
聚焦爬虫
就是爬虫程序员写的针对指定内容的爬虫
网页组成
# 爬虫的工作就是模拟浏览器朝目标网站发送请求的过程,拿到的网页筛选相应的数据
网页展示的界面其实内部对应就是一堆HTML代码

爬虫程序就是对这一堆HTML代码做数据筛选,所以要先熟悉html代码基本组成
HTML:超文本标记语言(浏览器展示出来的界面都是由HTML组成的)
前端与后端
前端
任何与用户直接接触的操作界面都可以称之为前端
手机界面, 电脑界面, 汽车中控
HTML 网页骨架
css 网页样式
javascript 网页动态效果
后端
就是程序员写的一堆程序代码,普通用户一般无法接触
HTML基本组成
网页文件都是以.html结尾 这个文件可以用浏览器打开

HTML语法基本结构
<html> <head>书写的一般都是给浏览器看的</head> <body>书写的就是浏览器要展示给用户看的</body> </html>
head内常见标签
通过谷歌浏览器可以查看网页
1.title标签: 添加名字
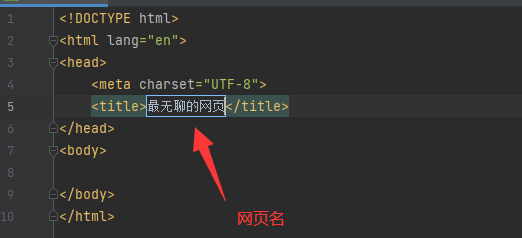
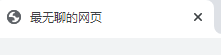
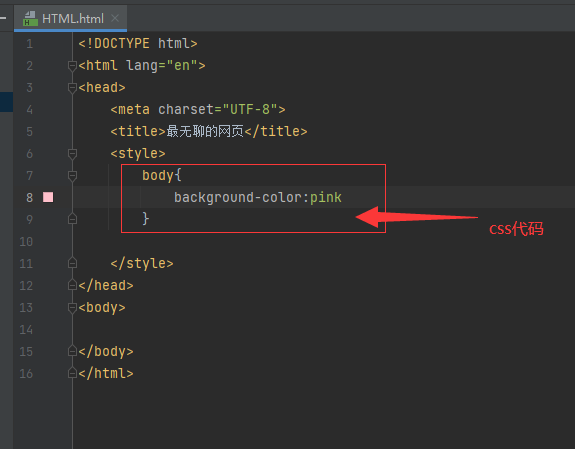
2.更改网络背景颜色 style标签
3.link标签 引入外部css文件
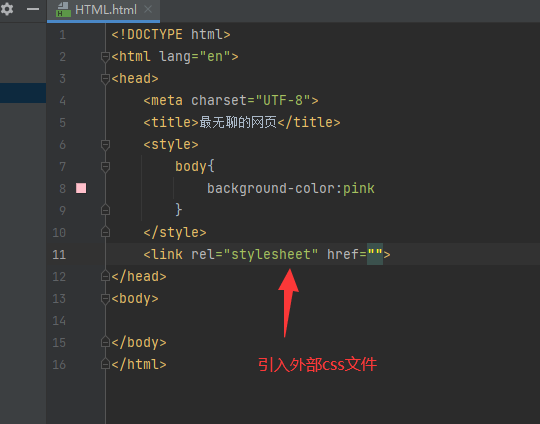
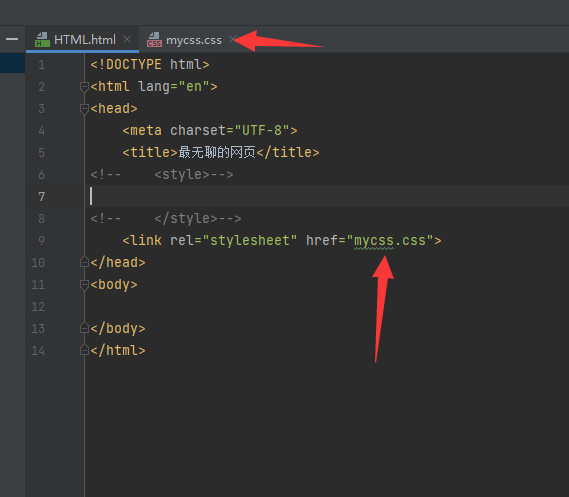
将写HTML 和css代码进行分离,更加精简
4.scrpit (js代码)动态标签
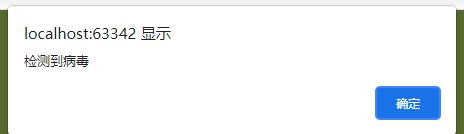
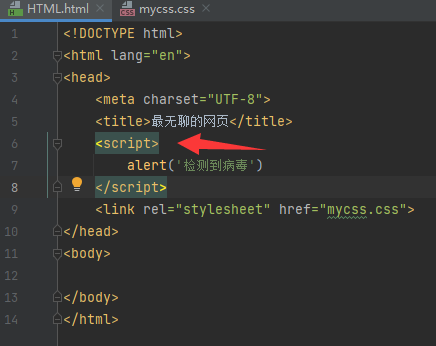
mata 标签 定义网页原信息
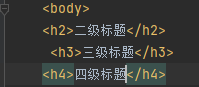

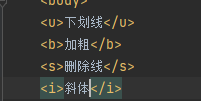
ubsi(下划线 加粗 删除线 斜体)
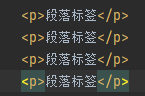
p标签

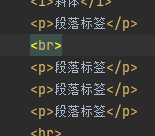
hr 水平分割线

br 换行

双标签(有头有尾)
<a></a>
单标签(自闭和)
<img/>
a 加入网络连接
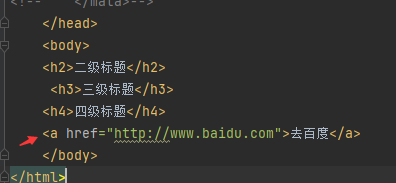
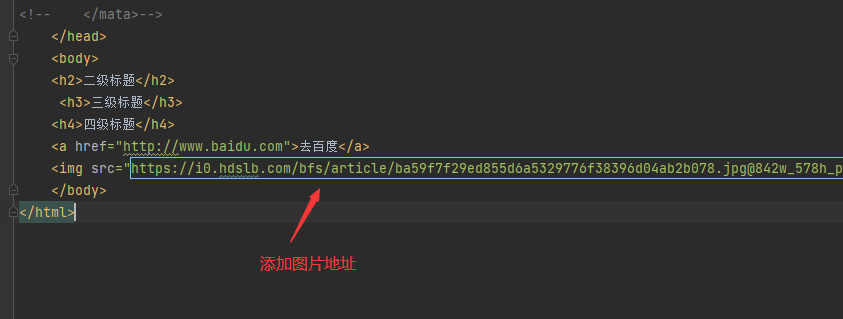
img添加图片地址