菜鸟的Kafka完整入门学习笔记,修订一
#Kafka学习笔记
终于开始学习大名鼎鼎的消息队列Kafka了,久闻大名了。并且Kafka的官网是我目前看到的所有Apache项目中除了Dubbo之外最好看的官网了!!!而且Kafka的标志是真的酷炫!!激起了我学习的欲望!!
一、Kafka概述
1.1、定义
Kafka是一个分布式的基于发布/订阅模式的消息队列(Message Queue,MQ)主要应用于大数据实时处理领域。
1.2、消息队列(MQ)
见名知意,使用队列来有序存放数据的中间件。
1.2.1、传统应用场景——异步处理
常见的场景中,如果当前用户访问服务处于繁忙状态,如果使用传统的同步处理,用户就必须等待服务器响应,这样的情况使用体验极差!
为了提高用户的使用体验,可以将用户的请求消息放入到消息队列中,然后先加载出页面,让用户感觉服务器响应很快,与此同时服务器从消息队列中取出消息进行处理,进行结果呈现。这样的做法就是异步处理。
异步处理也是常用于调高用户体验的方式之一。、
1.2.2、使用消息队列的优点
解耦
在上述案例的场景中,就可以充分体现,使用同步处理方式,用户与服务器之间的收发消息是直连的。使用消息队列后,两者之间的耦合性大大降低,相互可以独立更改,各做各的事情而并不影响!
可恢复性
得益于使用消息队列的解耦优点,服务系统中的各个组件之间没有强烈的依赖关系,即使其中一个组件挂掉,消息队列中的数据并不受影响,重新恢复后又可以正常收发处理数据。
缓冲
当产生数据的速度大于处理数据的速度时,若不加以控制就会导致系统阻塞,严重甚至导致系统崩溃。而使用消息队列就起到了缓冲作用,协调产生和处理数据的速度,有效控制系统平稳运行。
灵活性&峰值处理能力(削峰)
在服务访问量剧增的情况下,会带给服务器巨大的压力可能导致服务崩溃,但是当这种峰值访问量只是偶尔发生,而大多数正常情况下都低于这个峰值(可能导致服务瘫痪的值)时,如果在设计时就按照峰值的处理标准来投入资源搭建损失巨大!!因为大部分时间都无法充分利用这些资源。
而只是在峰值期使用消息队列,发挥其缓冲的功能就能抗住峰值访问带来的压力。(又名削峰)这样的做法投入小,灵活性高,并且很好地解决了峰值处理的问题。
异步通信
当系统繁忙时,使用消息队列存放用户的消息,服务器按顺序进行处理,完成异步响应,提高用户的使用体验,同时缓解服务器的压力!
1.2.3、消息队列的两种模式
点对点模式(一对一)
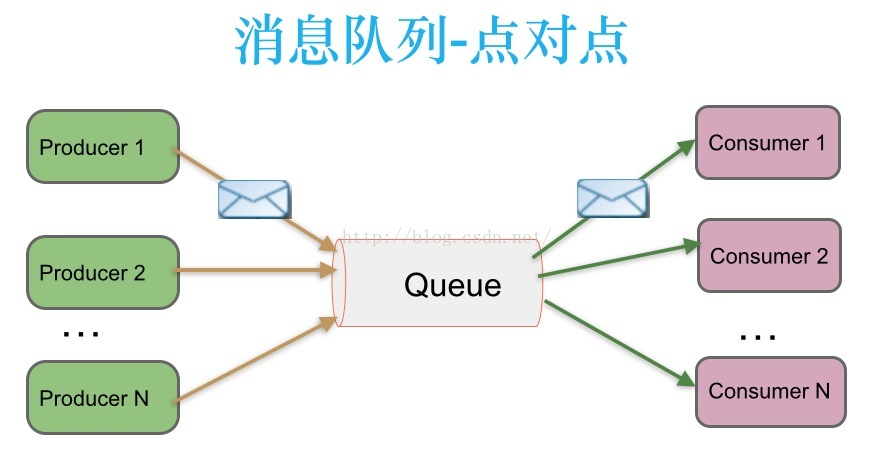
一个Queue支持多个消费者(Consumer),但是对于一条消息只能被一个消费者消费,当消息被主动消费后后Queue中清除。注意这里的主动消费,消费者是主动到Queue中Pull消息过来消费。
发布/订阅模式(一对多)
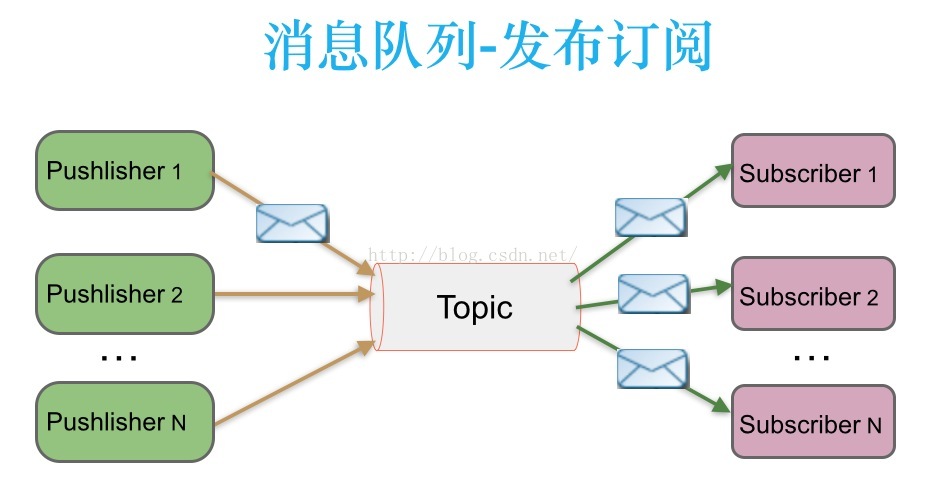
- 当消息生产者推送(发布)一个消息到Topic中后,同时有多个消费者消费(订阅)消息,并且消费消息是通过Topic推送给Consumer消费。
- 也存在各个Consumer主动从Topic中Pull数据,那么就要求被消费的数据不能被清除,需要保留。kafka就是采用这种(随之产生了重复消费的问题!)
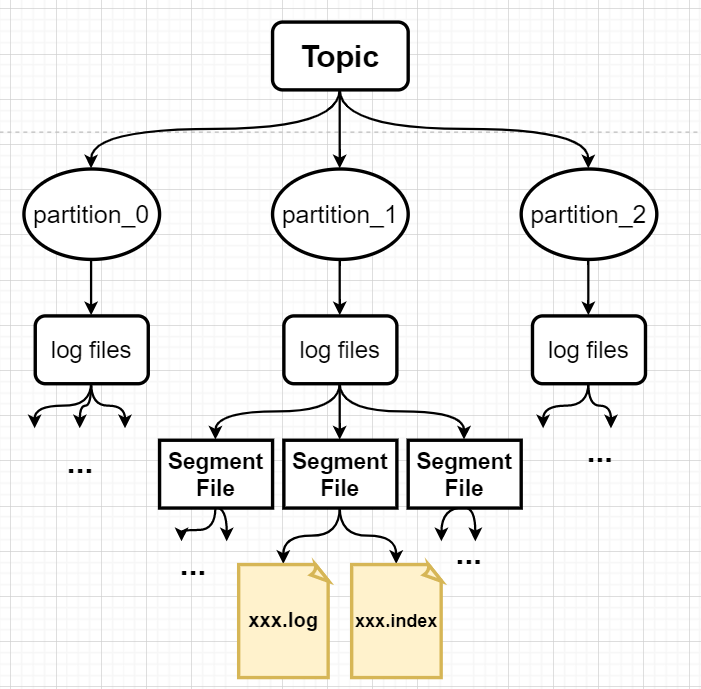
1.3、Kafka架构
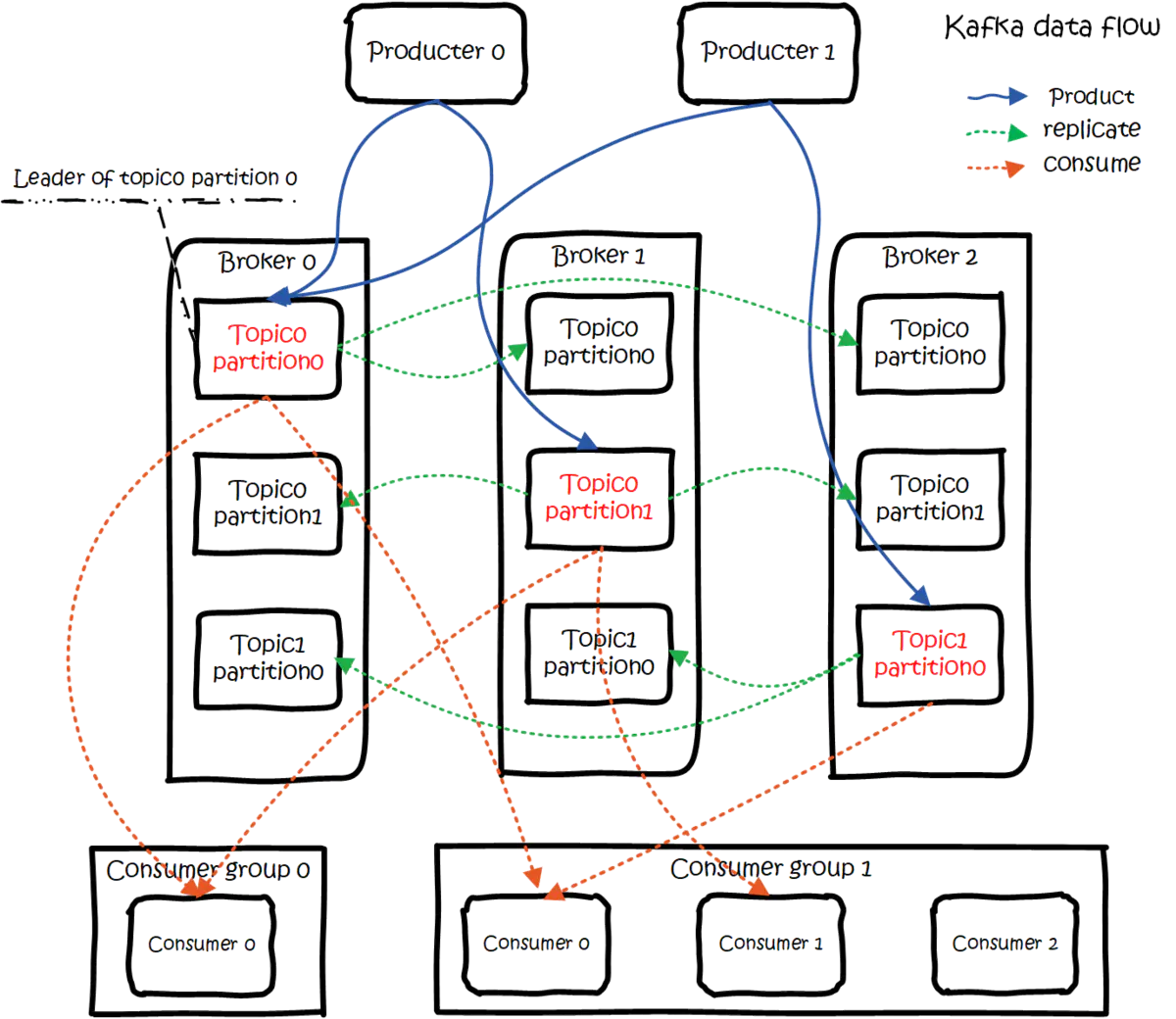
这张图可能看起来有点花,仔细看完我们来简单分析图中的各个部分。
首先我们可以把整张图划分三个区域:
- Producer(消息生产者):负责产出消息
- Kafka Cluster(集群):每个Kafka集群中由若干个Broker(Kafka服务器)组成
- Consumer Group(消费者组):每个消费者组由若干个Consumer(消费者)组成。
简化就是Producer、Kafka Broker、Consumer
Broker
生产者不用多说 ,直接看Broker的内容。
三个Broker像是复制来的。Broker中存在多个topic,而每个topic又有多个partition分区。每个Topic的所有分区又在其他Broker上存在并且存在主副的关系。
-
topic:数据按照类别存放,便于消费者 区分消息。每个topic代表一个消息分类。 -
partiton: 每个topic维护多个partition,partition的存在是为了提高消费消息的速度,结构上是一个个队列。
来看官方的解释:这个图就表示生产者在往topic写入消息的时候是写到topic的多个分区的。
每个分区都是有序且顺序不可变的记录集,并且不断地追加到结构化的commit log文件。分区中的每一个记录都会分配一个id号来表示顺序,我们称之为offset,offset用来唯一的标识分区中每一条记录。
这个offset在后面我们谈消费者的时候再详说。
-
不同Broker之间partition的主从关系
架构图中很清楚红字标识的partition就是Leader!!每一个partition leader在其他Broker上还有副本,我们称为Follower。
主从区分有什么作用呢?
Follower永远都是Leader的备胎,消费者在消费消息的时候,只从Leader中去取消息。Follower随时准备接替Leader。
Consumer
在学习消息队列的发布订阅模式的时候,参考博客中有说道Kafka的消费模式。
每个消费者组(ConsumerGroup)相当于一个庞大的消费者,并且消费过程是消费者主动到Topic中拉取数据!
通过架构图,我们需要知道:
- 对于一个topic的某个partition,同一个消费组中,只能有一个消费者进行消费!!(即一个partition对应一个ConsumerGroup,组中只要有一个Consumer在用,其他的就不能动!!)
- 一个消费者可以同时消费 同一个topic的不同partition
- 一个消费者也可以同时消费多个topic!!
所有的消息都是从partition中的Leader中拉取的!!
关于消费顺序,以及消费者重连恢复问题
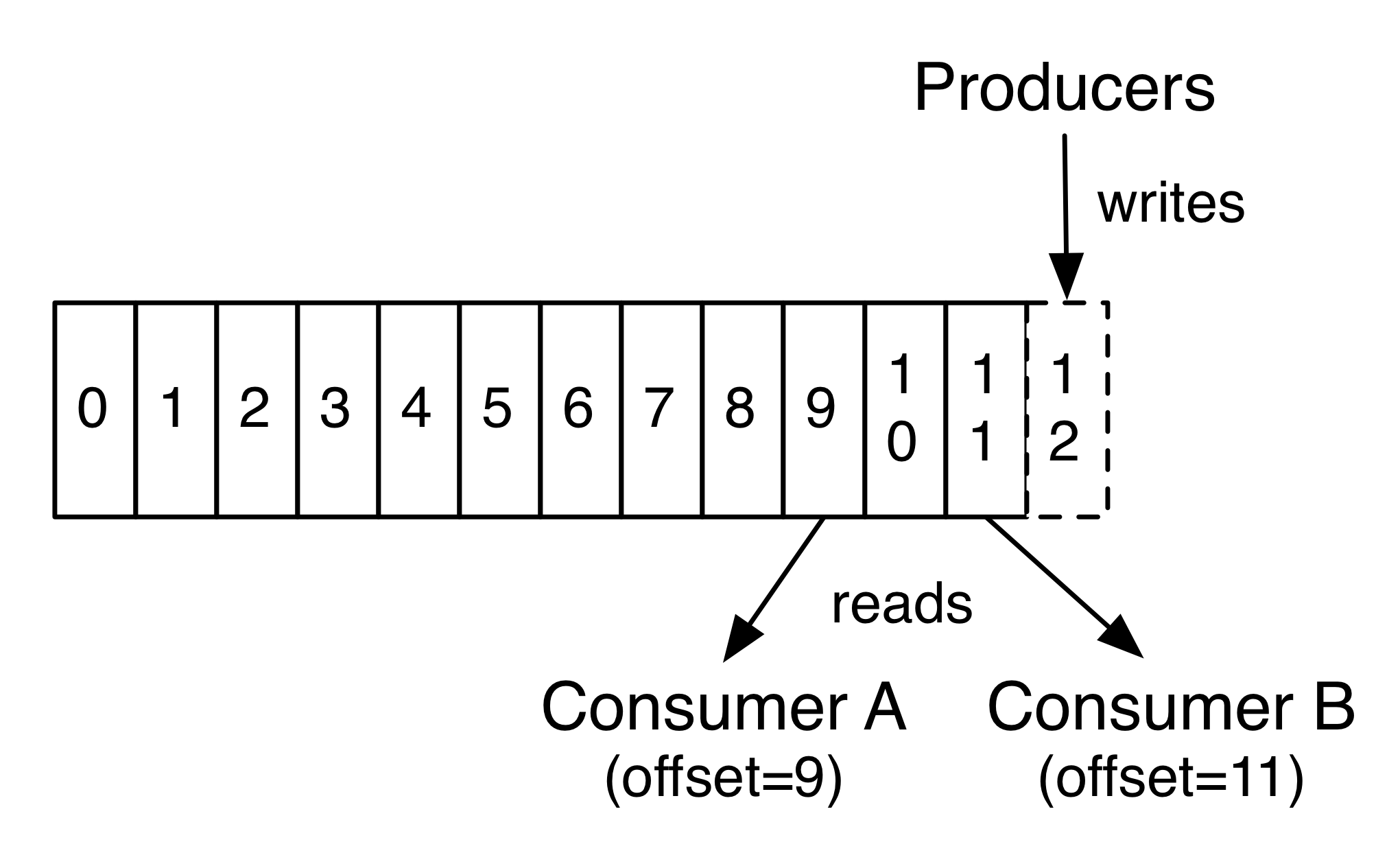
我们刚才看到的一个关键字叫offset,偏移量。
kafka为每条在分区的消息保存一个偏移量offset,这也是消费者在分区的位置。比如一个偏移量是5的消费者,表示已经消费了从0-4偏移量的消息,下一个要消费的消息的偏移量是5
这个就和Flume中TailDir使用的partitionFile.json一样,记录着当前的位置。只要这个offset得以保存,消费者重连恢复后仍然可以接着上一次消费的位置继续消费。
之前的版本中所有的集群相关的要存放的数据都由ZK(Zookeeper)进行存储管理, 现在这些信息都放在了本地。
以上内容建议学习官方文档:https://kafka.apachecn.org/intro.html
二、快速入门
Kafka版本:Scala 2.11 - kafka_2.11-0.11.0.0.tgz
2.1、安装配置与部署
-
tar包放到集群上解压
-
看一下bin目录里面有什么:
-
查看配置目录conf(配置文件挺多的,我们目前只看
server.properties,后续学习的时候在配置其他的),以下配置需要修改-
Broker.id和 topic删除开启(默认关闭)
# The id of the broker. This must be set to a unique integer for each broker. broker.id=0 # Switch to enable topic deletion or not, default value is false delete.topic.enable=trueBroker的ID在集群中应该是唯一的,所以等会分发以后,要把这个值设好!!
-
log文件存放位置:
log.dirs=/tmp/kafka-logs # 改为 log.dirs=/opt/module/kafka-0.11/logs其实在kafka中log文件中是存放的消息数据!!也叫做日志,当然kafka也有他自己的运行日志!
-
zookeeper连接配置
zookeeper.connect=localhost:2181 # 改为 zookeeper.connect=hadoop102:2181,hadoop103:2181,hadoop104:2181
-
-
分发kafka(记得改一下Broker.id)
-
群起Zookeeper,使用群起脚本(参考zookeeper大数据学习笔记)
-
kafka单点启动
bin/kafka-server-start.sh config/server.properties这种启动是阻塞式进程启动,可以加上-daemon以守护进程启动。
发现了一个版本问题:当使用的jdk版本大于9时,可以会出现
Unrecognized VM option 'PrintGCDateStamps'导致Kafka无法启动~ Stack Overflow上大神对此的解释是jdk的garbage collecttion(GC)在9.0版本后发生了变化~ 所以推荐降低jdk版本到1.8!!
详情页
-
模仿zookeeper群起脚本来写一个kafka的群起脚本
#!/bin/bash case $1 in "start"){ for i in hadoop102 hadoop103 hadoop104 do echo "******kafka-$i-start********" ssh $i "/opt/module/kafka-0.11/bin/kafka-server-start.sh -daemon /opt/module/kafka-0.11/config/server.properties" done };; "stop"){ for i in hadoop102 hadoop103 hadoop104 do echo "******kafka-$i-stop********" ssh $i "/opt/module/kafka-0.11/bin/kafka-server-stop.sh" done };; esac使用脚本时报错:
修改
bin/kafka-run-class.sh:建议最好还是先检查一下JAVA的环境变量配置!!
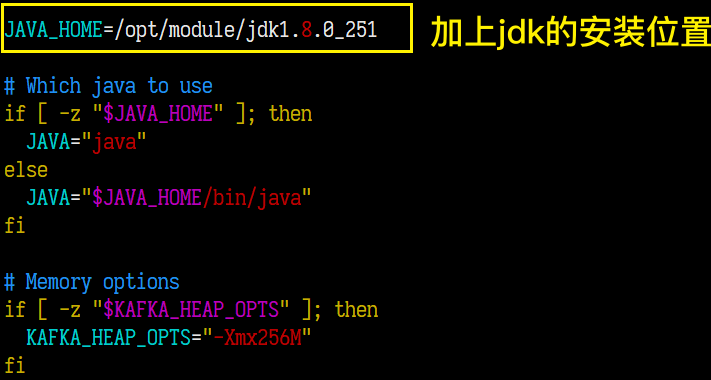
补充:kafka环境变量配置
# kafka enviroment
export KAFKA_HOME=/opt/module/kafka-0.11
export PATH=$PATH:$KAFKA_HOME/bin
然后使用source /etc/profile重新加载配置文件即可,群起脚本就可以进行简化了。
2.2、Kafka命令行操作
Topic操作
使用kafka-topics.sh。
-
创建topic
bin/kafka-topics.sh --create –zookeeper hadoop102:2181 --topic topic名字 --partitions 分区数 --replication-factor 副本数[sakura@hadoop102 logs]$ kafka-topics.sh --create --zookeeper hadoop102:2181 --topic testA --partitions 3 --replication-factor 3 Created topic "testA".在我们创建的logs目录中就存在这个topic:
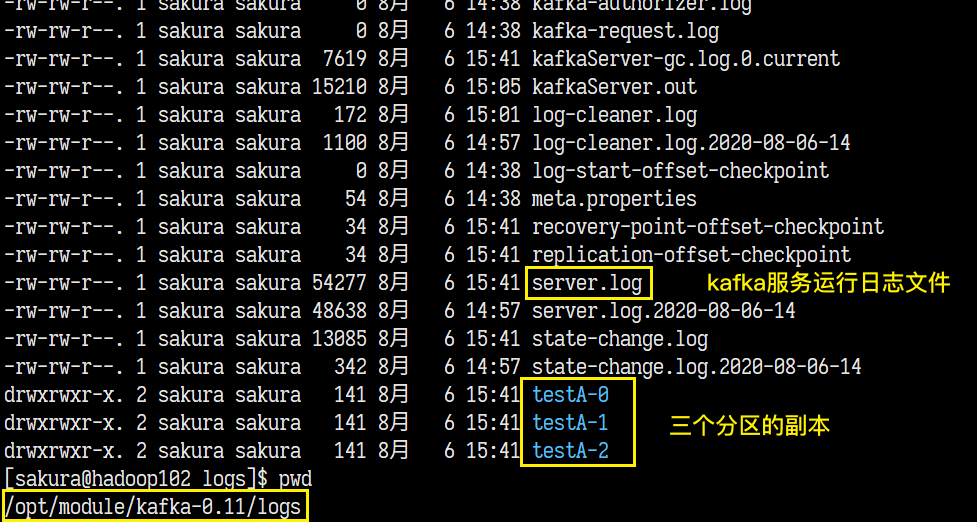
为了和这些日志文件分开来,最好还是另外创建一个目录来存放topics。
由于是3个分区,三个副本数也就意味着三台机器上都有三个分区副本,但是还不清楚每个分区的Leader在哪个Broker上。
-
列出所有topic
bin/kafka-topics.sh --list –zookeeper hadoop102:2181[sakura@hadoop102 logs]$ kafka-topics.sh --list --zookeeper hadoop102:2181 testA -
输出topic的详细信息
bin/kafka-topics.sh --describe –zookeeper hadoop102:2181 --topic topic名字[sakura@hadoop102 logs]$ kafka-topics.sh --describe --topic testA --zookeeper hadoop102:2181 Topic:testA PartitionCount:3 ReplicationFactor:3 Configs: Topic: testA Partition: 0 Leader: 1 Replicas: 1,2,0 Isr: 1,2,0 Topic: testA Partition: 1 Leader: 2 Replicas: 2,0,1 Isr: 2,0,1 Topic: testA Partition: 2 Leader: 0 Replicas: 0,1,2 Isr: 0,1,2 # 清除列举了testA的 0,1,2三个分区 其Leader依次是 1,2,0 对应我们配置的broke.id # testA-0的Leader副本在hadoop103主机上 # testA-1的Leader副本在hadoop104主机上 # testA-2的Leader副本在hadoop102主机上 # 其他字段后面再说 -
删除topic
bin/kafka-topics.sh --delete –zookeeper hadoop102:2181 --topic topic名字[sakura@hadoop102 logs]$ kafka-topics.sh --delete --topic testA --zookeeper hadoop102:2181 Topic testA is marked for deletion. Note: This will have no impact if delete.topic.enable is not set to true.提示说,已经被标记为删除,但是如果没有将
delete.topic.enable设置为true,这个操作没有任何作用。(我们在server.properties已经将其打开,详情见2.1步骤三)
注意点!!!replication-factor的参数不能操作当前的broker数量(即Kafka集群节点数量),否则会报错。
[sakura@hadoop102 logs]$ kafka-topics.sh --create --zookeeper hadoop102:2181 --topic testA --partitions 3 --replication-factor 5
Error while executing topic command : replication factor: 5 larger than available brokers: 3
[2020-08-06 15:55:18,865] ERROR org.apache.kafka.common.errors.InvalidReplicationFactorException: replication factor: 5 larger than available brokers: 3
(kafka.admin.TopicCommand$)
因为不同于Hadoop中设置副本数,那个是最大副本数,随着节点的添加自动创建的。
而Kafka是创建topic时就立即创建副本,如果副本数大于了节点数量,效果就是在同一台节点上两个testA-0?! 这当然是不允许的!!
与之相反,是允许分区数量大于节点数量的,testA-0~testA-9在一个节点上不会冲突!
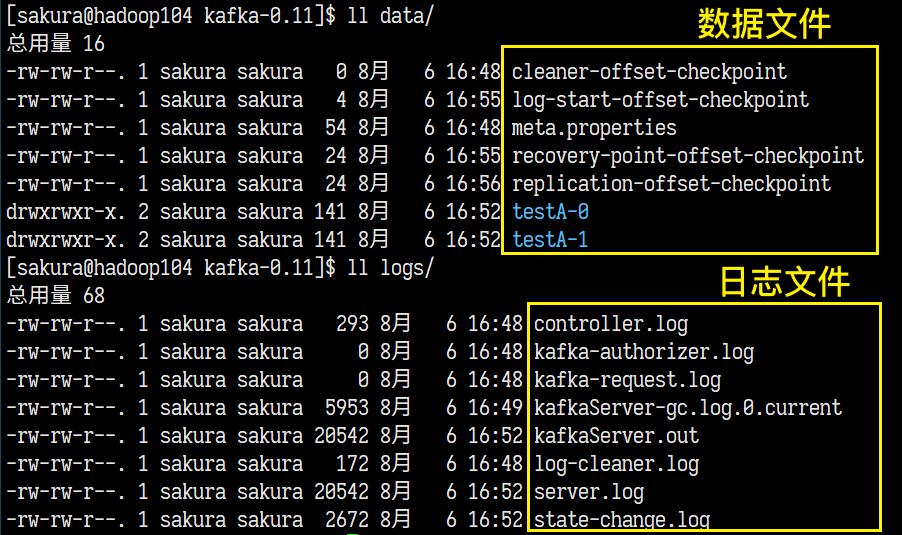
日志与数据分离
logs目录是Kafka默认存放日志的位置。所以我们要将消息数据与日志文件分离开。
-
首先关闭kafka集群和Zookeeper集群
-
删除kafka中logs目录
-
因为我们之前操作topic连接了Zookeeper了,所以zookeeper上还残留很多kafka的相关文件:
除了zookeeper都要删除。
暴力的办法就是删除zkData(修改后的zookeeper数据目录,参考zookeeper学习笔记)中的version-2,即删除zookeeper的之前所有的使用记录。(慎用!!) -
修改server.properties,将
log.dirs修改为:(/opt/module/kafka-0.11/data) -
重启生效
Consumer & Producer
-
确保当前已有一个topic,若没有则创建。
kafka-topics.sh --create --zookeeper hadoop102:2181 --topic testA --partitions 2 --replication-factor 2 -
启动消息生产者,连接到broker0(hadoop102:9092)==9092是Kafka的端口!!牢记!!==并准备向testA这个topic中存放消息
kafka-console-producer.sh --broker-list hadoop102:9092 --topic testA启动后,进入生产者命令行,随时可以发送消息到topic中。
-
启动消费者,从topic中消费数据
连接zookeeper启动:
kafka-console-consumer.sh --zookeeper hadoop102:2181 --topic testA提示:Using the ConsoleConsumer with old consumer is deprecated and will be removed in a future major release. Consider using the new consumer by passing [bootstrap-server] instead of [zookeeper].(告诉我们连接到zookeeper这种方式马上要过时啦!!尝试使用连接bootstrap-server吧)这就是我们之前说的新版本中kafka的数据存放到本地而不是zookeeper上了
不过还是可以正常接收消息的:
测试连接bootstrap-server启动消费者:
kafka-console-consumer.sh --bootstrap-server hadoop102:9092 --topic testA同样可以接受到消息。
加上
--from-beginning启动消费者,就会从头开始接受消息,但是消息是无序的!!一个奇怪的东西:
这个
__consumer_offsetstopic 一共50个分区,并且每个分区仅有一个副本(即只有leader)这个就是我们使用–bootstrap-server产生的 之前放在zookeeper中的数据文件!!
-
完成消息的生产与消费,我们来看看topic的文件夹里面到底有什么:
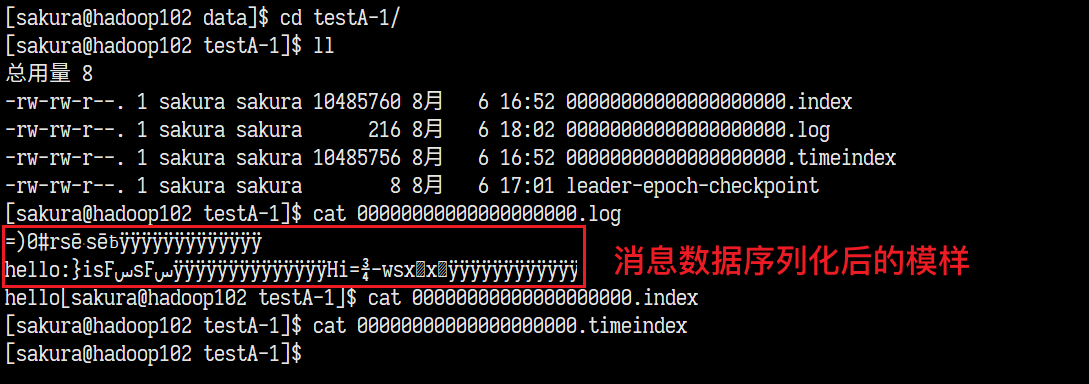
这还仅仅是一个分区中的内容,另外一个分区中也存放着一些消息的序列化内容。
三、Kafka高级—架构深入
3.1、Kafka运作流程及消息文件存储
用图来表示吧:
整个流程中,生产者生产的数据放入哪个分区,消费者组中各个消费者怎么划分消费的分区都有大有讲究的!!
并且在kafka的架构中,topic只是概念理论上的东西,实际上并不存在,而partition确是在物理上实实在在存在的。
数据文件的存储
首先官方文档中这几段话细品:
首先第一段话中所说的结构化的commit log文件正是我们在topic分区目录中看到的像0000000000.log的文件,所有的消息数据都存在了这个里面。同一个分区中每一条消息都有一个唯一offset记录这条消息的"位置"。
再看第二段话,消息存在log文件中是有期限的!!默认配置是七天,在server.properties中查看=>
以下就是配置文件中log文件的保留策略。
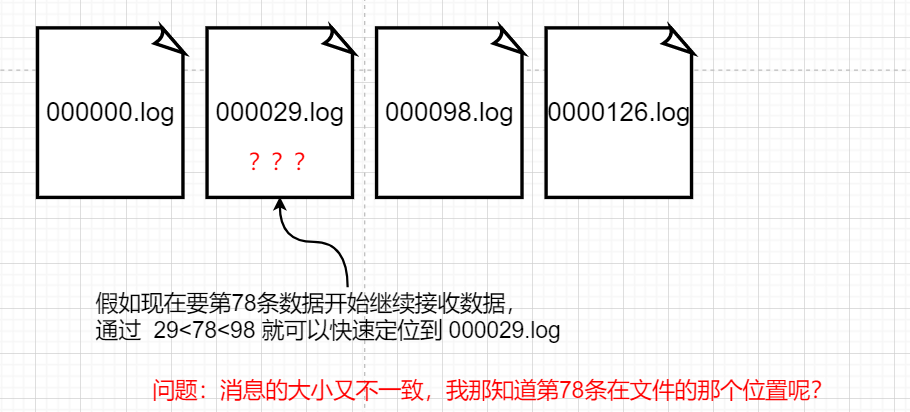
其中提到了segment file也就是log文件也是会有大小上限的,达到1G后,就会新建一个log文件。
其实与log segment file一起创建的还有对应的一个.index文件!!

画图表示就是这样的:
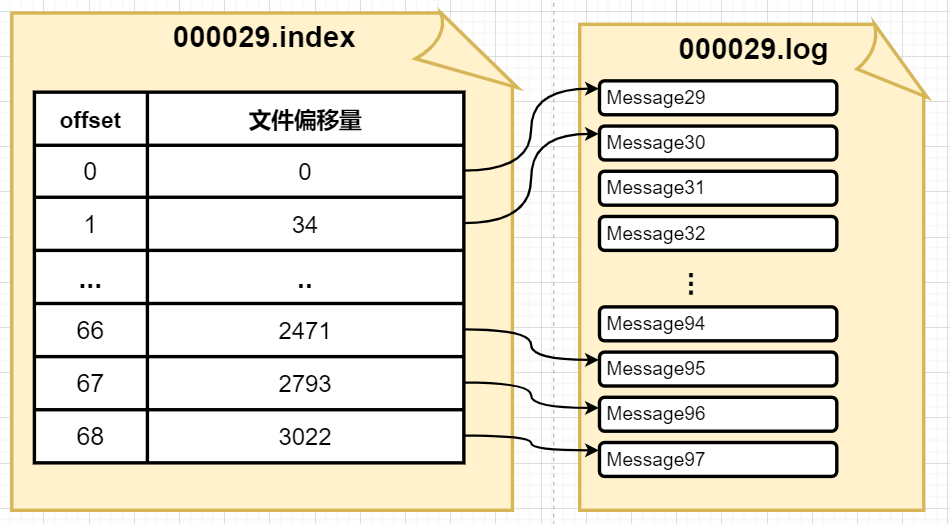
index文件和log文件 就是以其Segment File的第一条消息的offset命名的!
index文件和log文件的关系
前面我们说到offset用于标识消息的位置,而log文件和index文件又是以offset命名的,那么通过一个全局的offset值,就可以快速定位到消息在哪个segment中,但是在log中定位到这条消息的位置就遇到了麻烦了。你可以算出消息在log文件中是第x条消息,但是并不知道消息的起始位置和结束位置。
这时候就要讲到这个index文件了,kafka之所以速度不受信息量影响,就是因为其采用了分片和索引每一个.log文件都有一个index文件作为索引,记录着消息在log文件中的文件偏移量!!(注意是文件偏移量不是那个offset)
那么我要的78条数据,在index里面对应的offset就是78-29=48,然后取到这个log文件中offset为49的文件偏移量,就能快速定位到消息在log文件中的位置了!!
3.2、生产者
3.2.1、数据分区存放策略
为什么要分区?分区的优点何在?
这个分区和我们刚才说的log文件分片半毛钱关系没有,不要混淆了。
首先我们要了解分区,一个topic可以创建无限量的分区,而每个分区有管理着若干log段,而单个log的文件大小是受限制的。且生产者的消息就是发到这些分区里面的,若果不分区,每个topic能存下的消息就会非常受限。这就引出了分区的第一个优点:
- 当日志大小超过了单台服务器的限制,允许日志进行扩展。每个单独的分区都必须受限于主机的文件限制,不过一个主题可能有多个分区,因此可以处理无限量的数据。
以上是官方的话,说白了就是虽然分区中文件大小受限,但是由于分区的数量是不受限制的,我们就可以无限扩展,等同于可以处理无限量的数据了!!
我们之前也说了,消费者组在消费数据的时候,**同一个分区同时只能由组中一个消费者消费!**这个限制是为什么暂且不说,但是从集群性能来说,多几个分区,就能多几个消费者同时消费消息,何乐而不为?这就是优点二:
-
可以作为并行的单元集
多个分区之间是可以被消费者组中多个消费者并行消费的,提高了并行度!
生产者消息分区存放的策略
首先我们要记住一个点!:生产者生产的消息在Kafka消息队列中存放是要封装为ProducerRecord对象的!!
Kafka JavaAPI手册——KafkaProducer
在API手册中就能找到这个类:
先看文档的第一段话:
一个kv数据发到Kafka,要包含一个要发送到的topic名,以及分区号(可选),和key(可选,和分区有关)和value消息数据。
刚好下面给出了方法列表:
图中文档的第二段话,就简述了消息存放分区的策略:
- 如果分区号有效,消息直接放入该分区中
- 若每个没有分区号,而有key,使用key的hash值对分区数取模,得到最终的分区号
- 如果没有分区号也没有key,那就循环放置到各个分区中
3.2.2、数据可靠性保证
学习之前看看官方文档的关于replication的介绍=> 4.7、replication
数据的可用性和一致性对于这样一个消息系统是非常重要的,所以基本上所有的消息系统、分布式系统都有副本功能来保证数据的可用性。
Kafka官方认为这个副本功能并不常用,并且还可能对吞吐性能带来影响,Follower一直处于待命的状态也要消耗资源。所以默认配置中replication的数量是1(即只有一个Leader!!)!
副本功能设置的初衷:为了在Leader遇到故障掉线的时候,Follower能够临危受命担起Leader的重任。这就要求Follower中的数据要尽可能与Leader的数据保持一致(一致性),并且在正常情况下Follower同步Leader的数据的速度要快(延迟低,可用性)!!
一致性如何保证?
生产者在往Partition中追加消息的时候,并不是一股脑往里面发,也要确保消息确实被topic接收并且同步。这个机制叫做ACK应答机制由Producer配置,目前我们只需要知道Producer需要一个回应后才会继续写消息。
Follow和普通的Consumer一样,从Leader中拉取消息进行保存写入log文件。
目前有两种常用的副本备份的策略:
-
多数投票机制
2f+1个节点,最多冗余f次故障。
优点:延迟较低,只要前f个节点完成了同步,topic就能响应生产者开始写下一条数据。
缺点:当故障数量大于f,可能就久久无法响应,并且在Leader故障的时候,也迟迟选不出新的Leader来,并且存在Follower数据不完整。 -
最少同步数
f+1个节点,就能冗余f次故障
优点:数据的一致性得以保证,所有的节点同步完成才会响应。
缺点:延迟高,整体的同步速度取决于最慢的那个Follower的同步速度。
如果它死活完成不了同步,那也会久久无法继续读取消息了。
以上的两种策略都存在比较严重的缺点,Kafka的选择更偏向后者,但是引出了一个新的东西a set of in-sync replicas简称ISR,其实我们已经见过面了,只是没有留意。
Kafka 动态维护者这个同步状态的备份的集合,ISR集合中都Follower中挑出来的“精英”,集合中的Follower必须和Leader保持高度一致。并且这个集合中的Follower信息是要写到Zookeeper中的!**只要这个集合中的Follower都同步完成就视为同步完成。当集合中Follower没有达到精英要求就会被从集合中剔除…**这就解决了死活无法完成同步Follower带来的问题了。
精英要求?入选IRS的要求
0.9版本前:两个要求:
- 信息滞后的数量小于一定值(对应配置:
replica.lag.max.messages) - 从Leader抓取数据和同步所用的时间小于一定值(对应配置:
replica.lag.time.max.ms)
但是0.9版本,删除了条件一:
什么原因?很简单啊。
生产者批次写入数据到Leader的时候,只要批次的数据量大于这个replica.lag.max.message,简直就是灾难,Leader刚把这批消息追加到log文件后,此时Follower刚要开始拉取的时候,Leader来了一句ISR中的所有Follower都不符合要求,都滚出去!Zookeeper执行删除操作,Follower拉取的差不多了,Leader又重新把他们加到了ISR中。下一批消息一来,又是同样的过程,反反复复Zookeeper的操作就要消耗大部分资源!!
这样的做法其实是牺牲了数据的一致性但是提高了可用性。
Kafka使用ISR的Leader选取 & Unclean leader 选举
使用IRS后,一旦Leader故障 ,新的Leader一定是从IRS集合中产生!!
【问题】:所有的节点就崩了,怎么选?!
请注意,Kafka 对于数据不会丢失的保证,是基于至少一个节点在保持同步状态,一旦分区上的所有备份节点都挂了,就无法保证了。
对于这个问题,官方也给出了两种策略:
-
选取第一个恢复的ISR中的副本作为Leader
因为它极有可能拥有全部数据,数据丢失的成本最小!但是如果IRS中的副本迟迟不能恢复就会使服务长期不可用。 -
选取第一个恢复的副本(不一定是ISR中)作为Leader
它可能会丢失大部分消息,但是能保证服务的最快恢复。
这是可用性和一致性之间的简单妥协
kafka默认是使用策略二!!当所有的 ISR 副本都挂掉时,会选择一个可能不同步的备份作为 leader。
可以配置unclean.leader.election.enable禁用策略二,这样就会使用策略一了。
看看ISR:
3.2.3、ACK应答机制
ack的策略有三种,对应三个可选配置值:
acks = 0: Producer发送消息后,就不管了,也不管你到底有没有收到,有没有同步,我发我的。
**这种做法很容易导致数据丢失!!**当Leader故障下线,选取Leader期间Producer并不知情,它仍然高高兴兴发着消息,这期间所有的消息也就丢失了。acks = 1: Producer只要接到了Leader的应答,就继续发消息。
当Leader正在追加生产者发来的消息的时候发生故障,Follower还没来得及拉取Leader中数据就发生了数据丢失。acks = all(-1): Producer要接收到Leader和所有Follower(ISR集合中的Follower)的响应才继续发送消息
这样的做法看起来万无一失,可是也存在问题:- 当副本数量只有1个(只有Leader)的时候,这个配置毫无意义,同样会产生数据丢失。只有配合副本数量>=2d的情况使用才有效果。
- ==可能存在消息重复的问题!==当所有的ISR中Follower同步完成,Leader还没来得及响应就掉线了,此时重新选举Leader后,又会重新发一遍数据,就造成了数据重复…
3.2.4、面向消费者保持消息一致
之前说的 Leader即使和ISR集合中的Follower高度一致,也难免产生消息同步不完整的情况。可能Leader中存放的消息有20条消息,可能ISR中Follower 一个只同步到13条,一个只同步到16条。
【问题】:当消费者正常消费Leader中的数据的时候,Leader崩了,选了那个只同步了16条的Follower上来,结果消费者嚷嚷着:“我不管我不管,我明明都消费到了19了,我现在要20,你不给我不走!!”
这就是我们要解决的消息副本面向消费者保持一致的问题,前提说明:这个并不能保证数据的完整性,无可避免消息丢失!
我们先知道两个东西:
- HW(High Watermark, 高水位线)
- LEO(Log End Offset, 日志结束偏移量)
画个图吧:
这个高水位线就很像木桶效应里面的最高水位,而每个长度不同的副本呢就像木桶的长短不一的木板。
回到问题,为了防止用户的“超前消费”,规定HW之前的消息,对Consumer可见,这样就不会出现换了Leader,Consumer死皮赖脸了。
【新问题】那么后续生产者追加数据的时候,各个副本怎么做呢?不采取措施的话就可能出现生产者的消息 消费者无法消费的问题。
在选取了新的Leader后,首先把所有“木板”高于最高水位的部分截掉,这样Leader和Follower就又回到了同一条线上。但是就难免会出现数据部分丢失的情况。
其中所有的副本仅限于ISR!!
这俩东西还可以解决Follower故障:当发现了Follower发生了故障会立即将其踢出ISR,此时HW已经变化,恢复后Follower读取故障前的HW,将高于上一次的HW的log截掉,然后和Leader进行同步,直到追上当前的的HW,就可以重新加入ISR。
3.2.5、消息交付语义以及幂等性
按照惯例,先看官方文档:消息交付语义
三种交付语义:
- At most once——消息可能会丢失但绝不重传。
- At least once——消息可以重传但绝不丢失。
- Exactly once——这正是人们想要的, 每一条消息只被传递一次.
At most once,很好理解,就是不管收没收到我就传一次。类似于acks=0
At least once,至少传一次,如果没有得到响应则重传,直到得到响应为止。可能产生数据重复。
Exactly once,刚刚好一次,这是最理想的状态,消息只传一次并且不会传丢。
前两者分别存在的问题是:消息丢失和消息重复。
我们的理想状态是,消息完整的情况下,保证不重复!
所以我们要从At least once开始改造,解决消息重复的问题。谈到消息重复就不得不提到幂等性
什么是幂等性?
所谓幂等性,就是同一个操作的多次执行,得到的结果不变,并且不会产生其他副作用。(例如一条消息被反复提交,最终只能有一条提交被持久化。)
Kafka在0.11版本开始,也开启了幂等性的传递选项:
那么 at least once + 幂等性 = Exactly once;
消息传递幂等性如何实现的?
消息是Producer发出去,它自己可能也不知情,那么我们能操作的地方就只有broker和consumer了。按官方文档的说明,其实是对Producer做了一定的改造,并且对消息的封装也做了优化。
首先Broker会给每个Producer一个ID(又称PID),并且Producer发送的每一条消息,都要有一个序列号(这个序列号就是区分存放信息的关键),这些消息过来就有了三个部分:<Producer ID, 分区号, 消息序列号>,一旦三者同时重复,就可以认为是重复的消息,Leader持久化以后就会覆盖原先的提交。
那么就有局限性了:
- Producer故障重启后,重新分配的Producer ID不同了,即使是消息重复也检查不到了
- 分区之间的(partition_1 和 partition_2)中重复消息无法检测
所以,幂等性仅能保证单个生产者会话中单个分区的消息不重复
官方文档还提到,0.11版本加入了类似事务的语义将Producer消息写入topic。自行阅读官方文档学习。
3.3、消费者
3.3.1、两种消费方式
-
broker向consumer推送(push)其订阅的topic的消息。
但是推送速度由broker决定,它的目标是尽可能快地推送数据给consumer,但是他根本不了解每个consumer的处理消息的速度,就很容易造成消费者端的消息积压,从而导致拒绝服务或者网络拥塞。
-
consumer主动去其订阅的topic中拉取(pull)消息
这样的的做法,每个consumer可以根据自己的消费能力,以适合自己的工作节奏去拉取数据。
但是也存在【问题】:consumer需要反复判断topic中是否有消息,倘若队列中长时间没有消息,那么consumer就会陷入无限的循环中,并且每次拉取返回的都是空数据,浪费资源。
为了解决这个问题,kafka要求消费者在消费数据的时候,传入一个时长参数timeout,当拉取到空数据后,在timeout时长期间都不会再去拉取数据,时间结束再去尝试拉取。
3.3.2、分区分配策略
只有当有消费者组存在的时候,才涉及到分区分配的问题!!
每个Consumer Group由若干个Consumer组成,而每个Topic中分为若干的partition。但是==规定每个消费者组中,不允许存在两个消费者同时消费同一个topic的同一个分区!!(即同一个分区只能同时由消费者组中一个消费者消费)==所以才出现了分区分配的问题!!
提供了两种分区分配的策略:
- 轮询分配(roundrobin)
- 划块分配(Range)
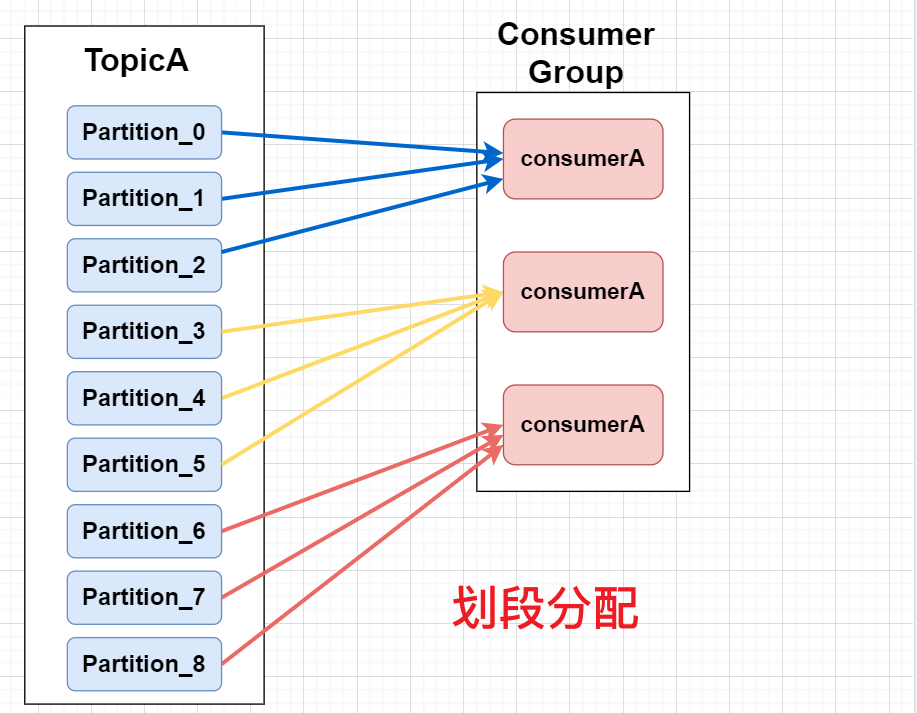
我们用两张图先简单认识一下:
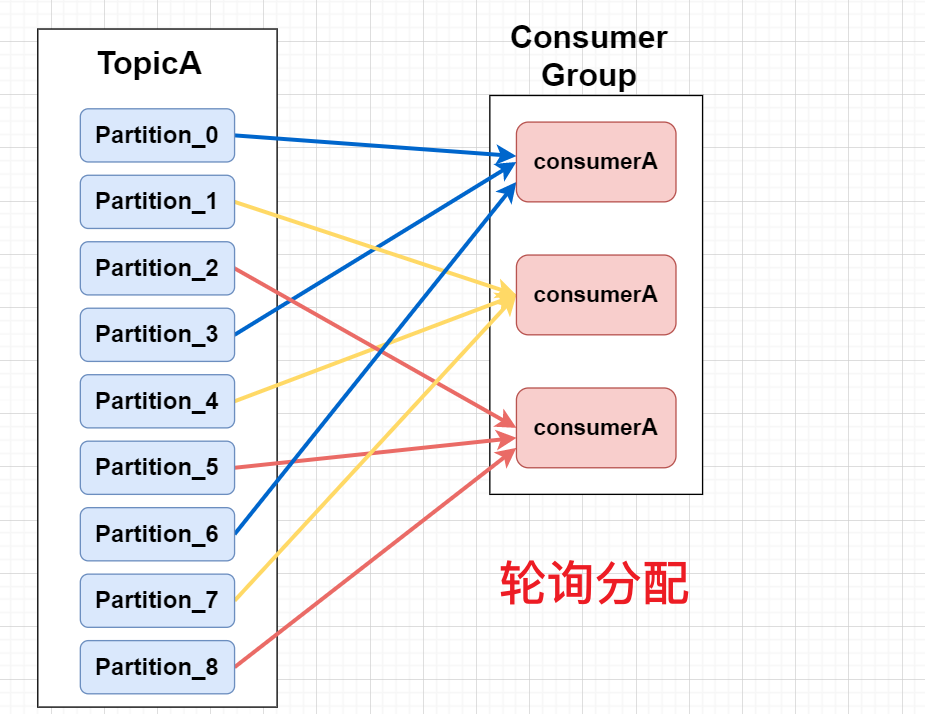
只还只是针对于一个Topic,当消费者组中,每个消费者订阅的Topic有多个时,两者的区别就出来了。
轮询分配的策略(RoundRobin)
当有多个topic时,由于每个partition被封装为一个TopicAndPartition对象,先将所有Topic的Partition混合,按照Partition的对象Hash值,做排序,然后轮询分配分区。但是存在【限制】!要想混合Topic中的Partition,这些Topic必须同时被消费者组中的所有消费者同时订阅,否则消费者将会收到他没有订阅的Topic的消息。。
划段分配策略(Range)
每次划段是单独对一个topic进行划段分配,按照订阅这个topic的消费者数量,均匀划段然后分配。划段不均匀,在topic数量增加的时候就会暴露出分区分配不均匀的缺点!!(最后一个每次都只能喝汤分一个,久而久之就失去平衡了)
【问题】:何时会触发分区分配策略的执行?
==当消费者组中消费者数量发生变化的时候,就会触发分区分配策略进行重新分配。==就算加进来没有分区可以给它,只要数量变了就要重新分配!!
默认使用划段分配(Range)!!!
3.3.3、Offset的维护
在初次接触Kafka的结构的时候,我们就知道了Offset这个东西,是用于确定Consumer在Partition中消费数据的位置的,也是为了方便消费者故障重连后能继续恢复消费数据。
现在现在我们引入了消费者组的概念,那么你觉得Offset由什么决定和保存呢?每个Consumer自己保存吗?还是Partition?还是Consumer组?亦或是Topic?
首先如果是Consumer自己保存,那么一旦他被分配到其他分区,当他再次回去消费原来的分区的时候,有可能出现消息重复消费的情况!! 你总不能在坑上面贴个纸条说“就这就我的坑,谁都不能碰!”Consumer自己保存❌
Partition?一样的道理,Consumer的来回切换很容易造成消息重复消费!!。❌
正确答案:Offset由消费者组、Topic、Partition三方共同决定!!
口说无论,上才艺!!首先我们按照老版本方式,将Offset存到Zookeeper上来查看。也趁此机会来看看Kafka到底在ZK上存了些什么。
-
启动生产者,消费者,并将Offset存放到ZK上:
kafka-console-producer.sh --broker-list hadoop102:9092 --topic testAkafka-console-consumer.sh --zookeeper hadoop102:2181 --topic testA -
启动zkClient,查看目录结构:
ls / [admin, brokers, cluster, config, consumers, controller, controller_epoch, isr_change_notification, latest_producer_id_block, zookeeper]我们这次只看
/brokers和/consumers两个节点 -
/brokers 存放着Kafka集群的节点信息:
# 节点信息 ls /brokers [ids, seqid, topics] ls /brokers/ids [0, 1, 2] get /brokers/ids/0 {"listener_security_protocol_map":{"PLAINTEXT":"PLAINTEXT"},"endpoints":["PLAINTEXT://hadoop102:9092"],"jmx_port":-1,"host":"hadoop102","timestamp":"1596868875187","port":9092,"version":4} get /brokers/ids/1 {"listener_security_protocol_map":{"PLAINTEXT":"PLAINTEXT"},"endpoints":["PLAINTEXT://hadoop103:9092"],"jmx_port":-1,"host":"hadoop103","timestamp":"1596868876629","port":9092,"version":4} # topics 和 partition ls /brokers/topics [__consumer_offsets, testA] get /brokers/topics/testA {"version":1,"partitions":{"1":[2,0],"0":[1,2]}} ls /brokers/topics/testA/partitions [0, 1] get /brokers/topics/testA/partitions/0/state {"controller_epoch":4,"leader":1,"version":1,"leader_epoch":3,"isr":[1,2]} -
重头戏开始,看看/consumers
# 所有的Consumer Group 我说了你也不会信 # 两个消费者组对应 我们开启的两个消费者(独立成组) ls /consumers [console-consumer-38940, console-consumer-45452] # 每个消费者组管理的东西 ls /consumers/console-consumer-38940 [ids, offsets, owners] # 消费者组的信息 ls /consumers/console-consumer-38940/ids [console-consumer-38940_hadoop103-1596870156366-40daf766] get /consumers/console-consumer-38940/ids/console-consumer-38940_hadoop103-1596870156366-40daf766 {"version":1,"subscription":{"testA":1},"pattern":"white_list","timestamp":"1596870156399"}下面我们直接看我们关心的Offset!!
ls /consumers/console-consumer-38940/offsets [testA] ls /consumers/console-consumer-38940/offsets/testA [0, 1] get /consumers/console-consumer-38940/offsets/testA/0 2 get /consumers/console-consumer-38940/offsets/testA/1 3认了吧!我们先找到了消费者组,然后找到topic标题,然后选择了分区号,取到的数值不同。就可以说明要通过
ConsumerGroup,topic,partition才能确定Offset!!我们现在模拟生产消费几条数据,看看数值会不会变化。
get /consumers/console-consumer-38940/offsets/testA/0 4 get /consumers/console-consumer-38940/offsets/testA/1 5共生产消费了4条数据,消息按照轮询的规则放入分区,消费者组中消费者同时消费两个分区,offset也是轮询增长。没毛病哦!!
-
退出消费者,重启看Offset是否被保存
由于上线后,节点下没有offset,所以又生产消费了一条数据,offset节点出现,并且保留之前的Offset。
**奇怪的是,消费者组明显变化了,但是Offset保留了,这是为什么呢??**我们对消费者组的认知出现了偏差?!get /consumers/console-consumer-63155/offsets/testA/0 5 get /consumers/console-consumer-63155/offsets/testA/1 5
以上是在Zookeeper上看到的,现在我们连接bootstrap-server将Offset存在本地,实质上是存在一个名为:__consumer_offsets的topic中。
那么实际上对于这个Topic,我们启动的消费者 在另一个角度上变为了这个topic的生产者,我们每次消费数据 导致的Offset变化就成为消息发送到这个Topic中。所以我们要再启动一个消费者,来消费这个Topic中的数据。
-
首先要关闭对这个topic的消费控制
consumer.properties中增加:exclude.internal.topics=false -
正常启动生产者和消费者,连接bootstrap服务器!!
-
再次启动一个消费者,消费__consumer_offsets中的数据,需要格式化,,为了不产生影响,连接到zookeeper
bin/kafka-console-consumer.sh --topic __consumer_offsets --zookeeper hadoop102:2181 --formatter "kafka.coordinator.group.GroupMetadataManager\$OffsetsMessageFormatter" --consumer.config config/consumer.properties --from-beginning -
康康控制台的输出:
按看是五秒一组,每组两条分别对应两个分区,这个topic一共50个分区,至于这个数据 是从那个分区中取出来的我也不知道,但是数据的KV形式,肯定和Key的hash值有关。我们也不需要知道这些数据是放在那个分区的。
我们重点只看:KEY是由 [消费者组名,topic名,分区号]三部分组成的,对应的Value中就包含着Offset!!近一步验证了我们的说法!
3.3.4、消费者组
默认情况下不指定配置文件,消费者组的ID是随机分配的,所以就很难做到多个消费者分到一个组里面。其实消费者启动是应该制定配置文件的,配置文件中写好消费者组ID,就能保证消费者启动时加入对应的组中。
-
修改consumer.properties
默认是test-consumer-group,我们现在修改一个自定义的组名(sakura-group)。
-
现在启动消费者,就要指定配置文件了
bin/kafka-console-consumer.sh --topic testA --zookeeper hadoop102:2181 --consumer.config config/consumer.properties使用
--consumer。config选项来指定配置文件。 -
到zookeeper里面去瞅瞅:
这也印证了我之前说这里的东西就是消费者组的ID!
-
测试分区分配
现在我们使用topic:testA 有两个分区,如果我们再启动一个消费者加入到这个组并订阅testA,那么两个人应该是一人一个分区,交替接收到消息。
现在我们再加一个消费者进来,即使他可能没有分区分配,但是也会进行一次重新分配
当加入新的消费者后,所有的消费者都收到了一条分区分配Range策略执行警告,告知有一个小可怜消费者订阅了testA这个主题,但是没有可用的partition让她消费,并且给出了消费者的id: sakura-group_hadoop102-15968xxxxxx。
所以理所当然也就没有拉取到消息。。。
以上就是消费者组的配置,就算是跨机器,只要连接的是同一个zookeeper集群,并且配置文件中配置的是消费者组的id没有问题,也是可以加入对应组的!!!
3.4、高效读写数据
都说Kafka很快,但是为什么Kafka这么快呢?
推荐阅读:Kafka为什么这么快
关键在于Kafka使用的两个高效操作:
- 顺序写磁盘
- 页缓存和零拷贝
顺序写磁盘
首先在操作系统的课程学习中,我们知道磁盘的结构包括,磁头和磁盘,磁头通过扫描具体磁道和扇区,定位存储单元然后完成信息数据的写入和读出。那么这过程中磁盘的旋转和磁头的来回移动扫描寻址都是十分耗时的操作。唯一能减少这部分操作的,就是选出一大片连续的存储单元进行读写,这样大大减少了那些耗时操作。官方有数据表明,顺序写的速度能达到600M/s 而随机写只有100K/s
页缓存(PageCache)和零拷贝
传统的应用程序实现文件拷贝,都需要经多次拷贝,操作系统内核将文件内容拷贝到页缓存中,再从页缓存使用IO读取到应用程序里面,再通过应用程序IO写到缓存,然后操作系统从缓存中拿数据写入到磁盘上。这期间多次拷贝和IO,耗时是相当严重了。
而Kafka是将数据内容写入到页缓存中,而没有直接到磁盘中,消费者如果消费消息,直接在页缓存中进行数据拉取,就减少了一次从磁盘到页缓存的一次IO。
分区和分布式
分区和分布式,都大大提高了开发时候的并行度,充分发挥了人多力量大的优势。
其他
包括之前提到的,日志文件分片和索引,日志文件的压缩编码等等。。
3.5、Zookeeper在Kafka集群中的作用
Zookeeper其主要功能,还是离不开他的本质工作:数据存储和消息提醒,主要也是存储了Kafka集群,Topic的一些重要消息,以及帮助集群高效有序地运行。说到集群的管理就不得不提到Kafka集群的Controller,虽然说broker之间人人平等,但是俗话说“国一日不可无君,家一日不可无主”集群中,总要有一个能管事的,我们将其称为Controller。
官方对于Controller的描述:
我们会选择一个 broker 作为 “controller”节点。controller 节点==负责 检测 brokers 级别故障,并负责在 broker 故障的情况下更改这个故障 Broker 中的 partition 的 leadership 。==这种方式可以批量的通知主从关系的变化,使得对于拥有大量partition 的broker ,选举过程的代价更低并且速度更快。如果 controller 节点挂了,其他 存活的 broker 都可能成为新的 controller 节点。
说白了就是当出现故障,或者某些选举任务时,都由Controller来主持,确保过程有序进行。
怎么选这个Controller呢?
很粗暴!就是抢,谁抢到就是谁的。集群启动谁第一个起来,谁就是Controller。当Controller了挂了,剩下的Broker继续抢,谁抢到就是谁。
**怎么看谁是Controller?**这么重要的消息当然要到Zookeeper里面去找到的呀!
3.6、事务
生产者事务
使用幂等性,只能保证单次会话中的数据不重复,而当生产者故障中断,重启后重新分配PID,此时重新发送消息幂等性也无法保证消息无重复。
**场景:**在生产者批量向三个分区发送数据的时候,前面两个分区都已经发送成功,在向第三个分区发送消息的时候发生了故障。此时就算是重启了由于PID不同幂等性不起作用,重新发送消息,前两个分区中就会发生消息重复。
事务性质的利用,就可以解决这一问题,首先为了管理事务,Kafka引入了一个新的组件Transaction Coordinator,每次Producer向topic写入数据都会开启一个事务,并且分配一个全局唯一的TransactionID与ProducerID(PID)进行绑定。消息发送要么全部成功要么全部失败
若由于服务崩溃导致事务中断,Transaction Coordinator可以通过TransactionID来查出事务的状态,事务也可以继续进行。
消费者事务
对于消费者来说,事务性的存在可能没有那么重要。
常见于,当消费者使用Offset消费任意一处数据的时候,可能刚好log文件段(SegmentFile)结束生命周期,文件被清理,消息丢失。此时就会触发事务,本次消费全部失败。
四、Kafka API
4.1、Producer API
先简单了解一些,Producer发送消息的过程。不仅仅是一个发送和就收反馈的过程。看看官方API文档:
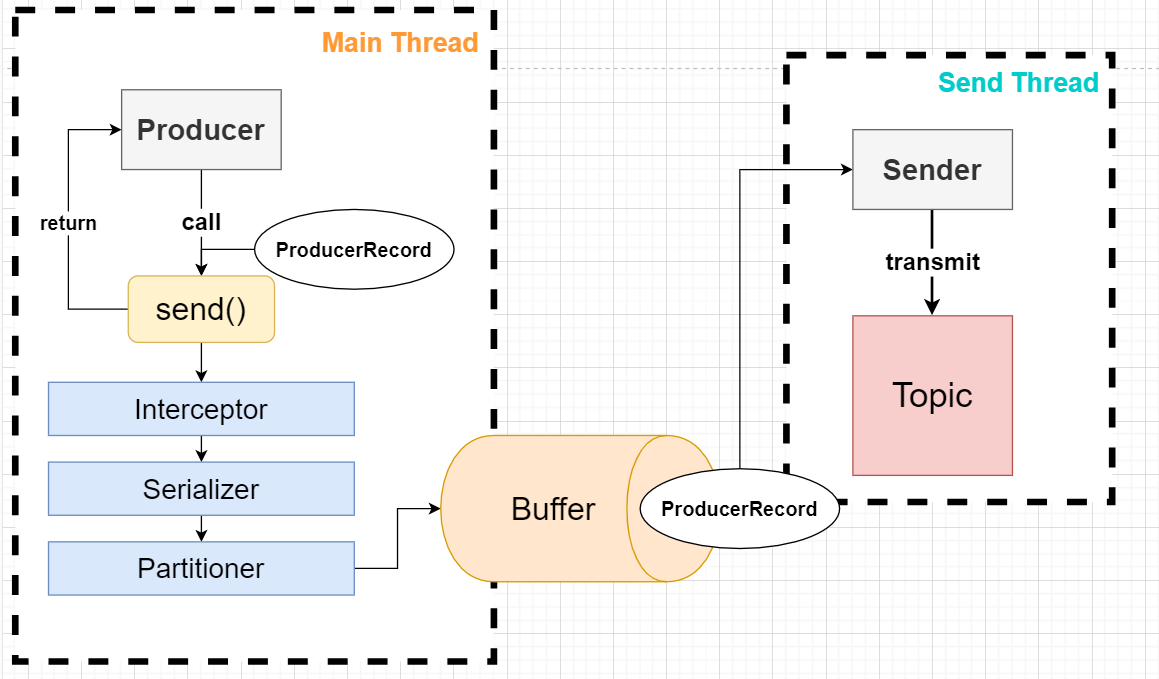
第一段告诉我们一个Producer包含
- 一个用于存放未传输的消息记录的缓冲池(RecordAccumulator)
- 一个发送请求和发送数据到集群的后台进程(Send线程)
第二段给出以下信息:
- send()方法是一个异步方法,当调用的时候,会将消息记录(record)加入待发送的记录缓冲池,然后立马返回,提高了生产者发送消息的效率。
我们再来看官方的第一个实例程序:
应该很明了了,消息被封装为ProducerRecord对象,然后Producer对象在Main线程调用send()方法,发送到到缓冲池中,由Send这个后台线程完成消息发送到Topic。主线程的send()方法立即返回后,开始下一次的调用。
这并不是我们想象的生产者发送一个消息,等到Broker响应给我们ack,然后再干下一单。发送消息应该是完完全全异步,不断地发,使用一个线程来接收响应的ack,出现问题再重发。
==并且主线程调用send()后,还可能经过拦截器、序列化器、分区器;==下面用一张图来展示一下:
4.1.1、第一个简单的Producer
-
创建Maven项目,导入一下依赖:
<dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-clients</artifactId> <version>0.11.0.0</version> </dependency> -
自定义类,MyProducer
public class MyProducer { public static void main(String[] args) { // 创建配置类 Properties props = new Properties(); // 1. 设置连接集群 props.put("bootstrap.servers", "hadoop102:9092"); // 2. 设置ack应答策略 props.put("acks", "all"); // 3. 设置重试次数 props.put("retries", 0); // 4. 设置批次大小 props.put("batch.size", 16384); // 5. 设置消息发送等待时间 props.put("linger.ms", 1); // 6. 设置缓冲区的大小 props.put("buffer.memory", 33554432); // 7. 设置key/value的序列化器 props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); // 8. 通过配置文件创建一个Producer对象 KafkaProducer<String, String> producer = new KafkaProducer<>(props); for (int i = 0; i < 10; i++) { // 9. 调用send()发送消息到缓冲区 producer.send(new ProducerRecord<String, String>("testA", "message-->" + i)); } // 10. 关闭释放资源 producer.close(); } } -
启动一个集群的消费者
-
运行程序,观察消费者控制台输出
message-->0 message-->2 message-->4 message-->6 message-->8 message-->1 message-->3 message-->5 message-->7 message-->9
小朋友你是否有很多问号?!下面我们对代码和输出来进行分析。
明明是0到9顺次发送的,为什么输出确是 0 2 4 6 8 1 3 …
答:因为我们封装的信息对象 ProducerRecord 没有指定key,所以按分区循环放置。并且是批次发送!!所以0 2 4 6 8进了分区1,并且消费者按批次消费数据,先分区1后分区2,于是就成了这样。
配置设置中有两个点:
linger.ms和batch.size需要说一下前面我们就说了,消息实际发送是由另一个线程掌管的,我们在主线程的程序是干预不到的。那么问题来了:
【问题】:Send线程怎么判断我们的消息之间的批次划分呢?
若所有数据都等到达到批次(batch)数据大小上限的话,那么达不到批次大小的数据就不会发送。所以这两个参数就起到了关键作用!
- batch.size 批次数据的大小上限
- linger.ms 发送批次数据的等待时间
linger.ms的设置,是告诉生产者每次调用send()后,你还有这些毫秒数的时间用于继续向此批次中继续添加数据,一旦调用了send()后这段时间内,你没有往里面添加数据,Send线程就认为这个批次数据已经装填完毕,就发送了。
batch.size的设置,就是当批次数据达到这个大小,Send线程就自动发过去了。
我们来针对linger.ms这个参数的设置来做个试验!!
-
linger.ms=1,即每次Producer都有1ms时间继续装填数据,原程序应该就是10条数据同一个批次。
以上是10条数据一个批次过去,消费者的消费顺序。
-
linger.ms=1保存不变,我们设置每次send()后sleep 2ms:
乱套了,但是我们可以保证这绝对是一个批次过去的!!
-
我现在 在此基础上将linger.ms调高设置为25ms
现在就又是一个批次过去了。
-
当linger.ms=1的时候,我们只sleep 2ms 就不再是一个批次的数据了。现在我们来尝试更极端的,我们将linger.ms设置为2000ms 我们send()之间sleep 1s, 按逻辑来说一个还是10条数据一个批次过来!!=>
很遗憾失败了,不知道什么原因还是多批次发送,但是每个批次都有2~3条数据,当linger.ms设置为10000ms时,就可以得到我们想要的结果。
-
现在反转,linger.ms=1000ms 每次send()间隔2s,就清晰可见,消息是一条一批,发送过来的,消费者一条一条消费:
这个自己测测,效果很直观!!
请注意!当linger.ms使用默认值0的时候,间隔短(没有刻意sleep)的数据,也将划为一个批次处理。
4.1.2、带CallBack函数的生产者
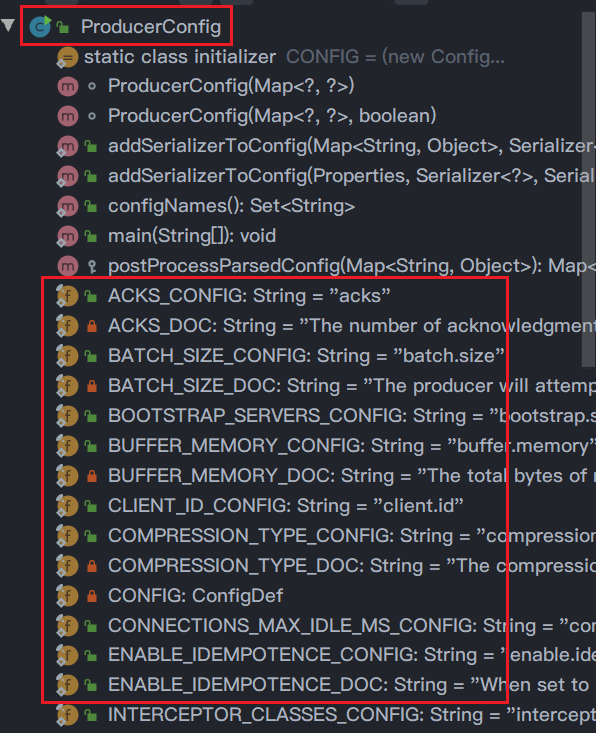
之前忘了说,在进行配置类进行put配置KV时,太多配置项不可能全部记下,ProducerConfig已经将所有配置项名设置为了常量,直接使用就可以了,就不怕把配置项写错了。
ProducerWithCallback类:
public class ProducerWithCallback {
public static void main(String[] args) {
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop102:9092");
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
for (int i = 0; i <= 10; i++) {
producer.send(new ProducerRecord<>("testB", "message-->" + i),
new Callback() {
/**
* @param recordMetadata
* @param e
* 回调函数,结束后执行
*/
@Override
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
System.out.println("[" +
recordMetadata.timestamp() +
"," +
recordMetadata.partition() +
"," +
recordMetadata.offset() +
"]"
);
}
});
}
producer.close();
}
}
控制台输出:
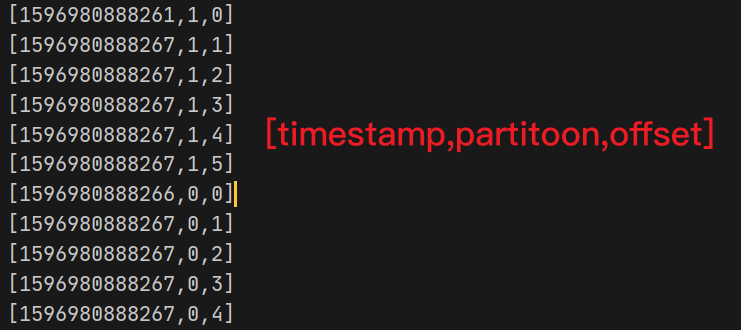

消费的顺序,和控制台回调函数的执行顺序也对得上。
主要是调用send()方法的时候,第二参数使用一个匿名内部类实现Callback接口,实现其中仅有的onCompletion方法。
onCompletition方法会在消息发送完成后调用,可以用于异步处理消息异常。
由于这个接口只有一个接口方法,所以可以使用lambda表达式简化。。。
4.1.3、消息分区放置测试
这个测试主要是在ProducerRecord的参数上做变动,之前在3.2.1看过JavaAPI文档中其所有的构造器。现在我们来看看本尊:
public ProducerRecord(String topic, Integer partition, Long timestamp, K key, V value, Iterable<Header> headers) {
if (topic == null) {
throw new IllegalArgumentException("Topic cannot be null.");
} else if (timestamp != null && timestamp < 0L) {
throw new IllegalArgumentException(String.format("Invalid timestamp: %d. Timestamp should always be non-negative or null.", timestamp));
} else if (partition != null && partition < 0) {
throw new IllegalArgumentException(String.format("Invalid partition: %d. Partition number should always be non-negative or null.", partition));
} else {
this.topic = topic;
this.partition = partition;
this.key = key;
this.value = value;
this.timestamp = timestamp;
this.headers = new RecordHeaders(headers);
}
}
public ProducerRecord(String topic, Integer partition, Long timestamp, K key, V value) {
this(topic, partition, timestamp, key, value, (Iterable)null);
}
public ProducerRecord(String topic, Integer partition, K key, V value, Iterable<Header> headers) {
this(topic, partition, (Long)null, key, value, headers);
}
public ProducerRecord(String topic, Integer partition, K key, V value) {
this(topic, partition, (Long)null, key, value, (Iterable)null);
}
public ProducerRecord(String topic, K key, V value) {
this(topic, (Integer)null, (Long)null, key, value, (Iterable)null);
}
public ProducerRecord(String topic, V value) {
this(topic, (Integer)null, (Long)null, (Object)null, value, (Iterable)null);
}
其实你会发现,其实即使写了分区号,也会要求写上key,虽然这个Key在有分区号的情况下,不会对放置在哪个分区造成影响。但其实key是会被Topic存起来的,只是消费者消费输出时候只输出了value。
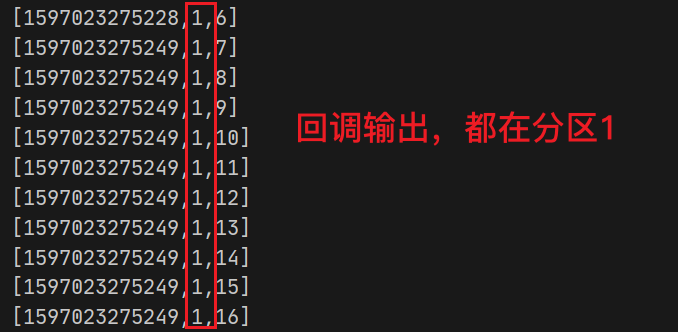
现在我们把程序中ProducerRecord的构造器中加上分区号:
for (int i = 0; i <= 10; i++) {
producer.send(new ProducerRecord<>("testB", 1,"sakura","message-->" + i));
}
producer.close();
4.1.4、自定义分区器(Partitioner)
在介绍ProducerAPI的时候,就提到了ProducerRecord在调用send()是会经过分区器的。现在我们来自定义我们的分区器。
-
实现
partitioner接口,实现所有接口方法。 -
参考
DefaultPartitioner(partitioner接口的实现类)的写法。partition方法被调用获取分区号,所有分区规则都放在此方法中。- 此类用于没有指定partition的Record获取分区号!!
-
因为具体的分区规则按照业务逻辑编写,那么我们就直截了当直接return 1;
public class MyPartitioner implements Partitioner { @Override public int partition(String s, Object o, byte[] bytes, Object o1, byte[] bytes1, Cluster cluster) { // 业务逻辑中的分区策略:... return 1; } @Override public void close() { } @Override public void configure(Map<String, ?> map) { } } -
重点是:我们如何使用这个自定义的分区器?
在创建Producer的配置文件中,配置
partitioner.class!!值为分区器的全限定名props.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, "com.sakura.partitioner.MyPartitioner"); // ProducerConfig.PARTITIONER_CLASS_CONFIG = "partitioner.class" -
启动测试:
4.1.5、同步消息发送生产者
前面我们一直使用的是异步消息的发送和处理,当然也可以使用同步的消息发送。
send()以后获取一个Future对象,其中存放是的send()的后的运算结果。可以使用get()方法获取,必要时会阻塞直到获取到结果。
那么我们每次send后都调用一下get()方法,就不得不等数据发送完毕获取结果,再进行下一次send(),于是异步就变为了同步!!
public class SyncProducer {
public static void main(String[] args) {
Properties props = new Properties();
props.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop102:9092");
props.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
props.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringSerializer");
KafkaProducer<String, String> producer = new KafkaProducer<>(props);
for (int i = 0; i < 10; i++) {
// 9. 调用send()发送消息到缓冲区
Future<RecordMetadata> metadataFuture = producer.send(new ProducerRecord<String, String>("testB", "message-->" + i));
try {
// 获取计算结果
metadataFuture.get();
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
producer.close();
}
}
4.2、Consumer API
4.2.1、一个简单的消费者
public class MyConsumer {
public static void main(String[] args) {
Properties props = new Properties();
// 连接集群
props.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "hadoop102:9092");
// 开启自动提交
props.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, true);
// 自动提交的间隔
props.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, 100);
// 配置 KV 反序列化器
props.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
props.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
// 配置消费者组ID
props.put(ConsumerConfig.GROUP_ID_CONFIG, "Sakura-Group");
// 获取Consumer对象
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
// 消费者订阅topics
ArrayList<String> topics = new ArrayList<>();
topics.add("testC");
consumer.subscribe(topics);
while (true) {
// 消费者拉取消息
ConsumerRecords<String, String> records = consumer.poll(100);
for (ConsumerRecord<String, String> record : records) {
System.out.println(record.key() + "->" + record.value() +
" partition:" + record.partition() + " ,offset:" + record.offset());
}
}
// 关闭consumer
//consumer.close();
}
}
- 配置类创建,添加基本的配置信息(集群,自动提交,反序列化器,消费者组ID)
- 使用配置类创建一个
KafkaConsumer对象。- consumer调用
subscribe订阅topics(注意不是在配置文件中配置的哦!)- 无限循环使用
poll拉取数据,并设置超时时间。(当拉取到空数据后,这段时间内不会继续拉取)- 输出消息(key,value,partition,offset)
注意,我们使用死循环来保证消费者一直存活。
并且我们订阅的topic是不存在的时候,会自动创建一个topic,默认一个分区一个副本。
启动生产者发送消息:
for (int i = 0; i < 10; i++) {
// 9. 调用send()发送消息到缓冲区
producer.send(new ProducerRecord<String, String>("testC", "message" , String.valueOf(i)));
}
消费者控制台输出:
4.2.2、offset重置
AUTO_OFFSET_RESET_CONFIG = "auto.offset.reset";与消费者API中这个配置项有关。
可选值:
earliestlatest
何时触发Offset重置?
官方解释:What to do when there is no initial offset in Kafka or if the current offset does not exist any more on the
server (e.g. because that data has been deleted):
- earliest: automatically reset the offset to the earliest offset
- latest: automatically reset the offset to the latest offset
- none: throw exception to the consumer if no previous offset is found for the consumer's group
- anything else: throw exception to the consumer.
当没有初始化Offset时,或者Offset已经不存在时,常见的两种情况就是:
- Offset所在的SegmentFile已经过期删除
- Consumer切换了消费者组,没有被分配初始Offset
配置earliest,消费者会拿到当前这个分区的最早的可用的(已经删除的为不可用)offset!(意味着目前所有有效的消息都以可以消费一遍)
相反配置latest,消费者拿到的Offset,是这个分区目前最新的Offset
4.2.3、自动提交Offset
初始程序中,我们配置ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG为true,即开启了Offset的自动提交。
现在我们将其设置为false,看看有什么不同:
启动消费者后,开启生产者生产了10条数据,消费者成功接收到。又生产了10条数据,还是正常接收到。
但是当我们重启消费者后,刚刚的20条消费记录,由会被重新输出一遍。
原因就是:Offset没有被提交修改
看这张图,就能很好理解:
其实我们的Offset是持久化在zookeeper节点或者__consumer_offsets这个topic中的,每当我们启动consumer时,都会将offset读取到consumer的进程内存中,以减少每次读取offset的资源消耗。那么就存在内存中offset和持久化的offset不一致的问题,所以需要定时提交一下offset
那么如果我们关闭了自动提交,又没有手动提交,虽然内存中offset在变化,可以正常消费信息,但是并没有持久化,下一次启动又会去读取持久化的offset,内存中offset的变化就都是"无用功",所以才出现了已经消费的数据二次消费。(图中状态一到状态二)
只要我们提交了offset,offset就会被重新持久化一次,更新节点或者topic中offset的数据信息,下一次读取也就是最新的了。(图中状态一到状态三)
4.2.4、手动提交Offset
自动提交Offset的缺点
开发人员不容易把握提交的间隔时间。
当提交时间间隔较短,在拉取了消息进行处理的过程中,就提交了offset,但是在处理数据过程中Consumer故障下线,再次上线上次没有处理完的消息也取不到了,因为早就提交了。(消费者级别的消息丢失)
当提交时间间隔较长,拉取的数据已经处理完成,都准备拉取下一批数据了,Offset还没有提交,在提交前Consumer故障下线,再次上线,上一批已经处理的数据又要处理一遍(重复消费)
手动提交API
官方给出的两种提交方式
-
commitSync 同步提交
consumer.commitSync(); -
commitAsync 异步提交
consumer.commitAsync(new OffsetCommitCallback() { @Override public void onComplete(Map<TopicPartition, OffsetAndMetadata> offsets, Exception exception) { if (exception != null) { exception.printStackTrace(); } else { System.out.println(offsets); } } });
同步提交会阻塞当前线程,失败重试,直到提交成功
异步提交有专门的线程提交,没有重试,可能提交失败。
但是即使改为手动提交,消息丢失和重复消费的情况还是会存在。
只要消息处理和Offset提交是一前一后就可能会在提交Offset的时候出问题,导致提交不成功。
我们唯一可以想到的就是把这两个部分放在一个事务中!!
4.2.5、自定义存储Offset
第三章就学到了,Offset在当前版本中有两种选择:Zookeeper、__consumer_offsets但是两种方案都不能满足我们将数据处理和offset提交放入到事务中完成的要求。那么我们只好自定义存储Offset。(例如将Offset存放到MySQL中,使用MySQL的事务)
需要解决的问题
- 由于是存放到自定义的位置:存取Offset的步骤需要我们一手实现
- 要考虑到ConsumerGroup变动导致的消费者Rebalance从而带动的Offset变动的问题。
需要使用ConsumerRebalanceListener监听消费者组的变化,并采取对应的动作。
4.3、拦截器API
对于拦截器各位应该不陌生了,Kafka中拦截器主要应用在生产者一端,拦截ProducerRecord,然后对Key Value进行修改。==最好不要修改分区相关的信息,容易导致计算出错。==并且它也可以接收到消息发送后返回的元数据消息。从而判断消息是否发送成功。
4.3.1、自定义拦截器
-
实现
ProducerInterceptor接口 -
实现接口方法
onSend()onAcknowledgement()close()configure()
-
代码框架:
public class TimestampInterceptor implements ProducerInterceptor { /** * 拦截ProducerRecord 对数据进行处理并返回 * @param record * @return */ @Override public ProducerRecord onSend(ProducerRecord record) { return null; } /** * 接收消息发送到服务器后的发送结果信息,在close()方法调用时调用 * @param metadata * @param exception */ @Override public void onAcknowledgement(RecordMetadata metadata, Exception exception) { } /** * 拦截器关闭 */ @Override public void close() { } /** * 增加和获取配置 * @param configs */ @Override public void configure(Map<String, ?> configs) { } }
4.3.1、拦截器案例
案例描述:
使用拦截器链,为消息加上时间戳,在发送结束后输出发送成功和失败的消息条数。
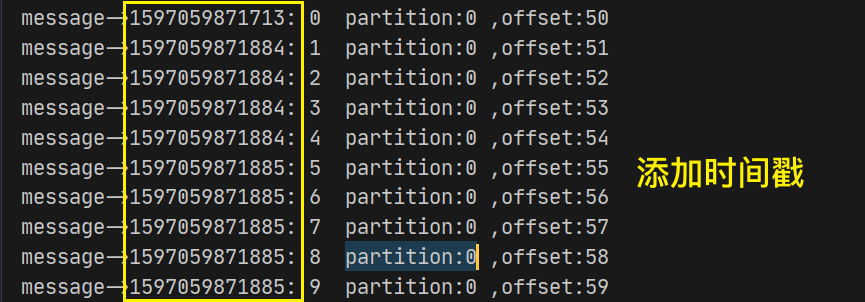
这个需求是可以放在一个拦截器的两个方法(onSend onAcknowledgement)中完成,但是…我偏不,我就要用两个拦截器!!
实现
拦截器一:TimestampInterceptor
public class TimestampInterceptor implements ProducerInterceptor<String, String> {
/**
* 拦截ProducerRecord 对数据进行处理并返回
*
* @param record
* @return
*/
@Override
public ProducerRecord onSend(ProducerRecord<String, String> record) {
// 由于ProducerRecord没有set方法,只能创建新对象
ProducerRecord<String, String> producerRecord = new ProducerRecord<>(
record.topic(),
record.partition(),
record.key(),
System.currentTimeMillis() + ": " + record.value()
);
return producerRecord;
}
/**
* 接收消息发送到服务器后的发送结果信息,在close()方法调用时调用
*
* @param metadata
* @param exception
*/
@Override
public void onAcknowledgement(RecordMetadata metadata, Exception exception) {
}
/**
* 拦截器关闭
*/
@Override
public void close() {
}
/**
* 增加和获取配置
*
* @param configs
*/
@Override
public void configure(Map<String, ?> configs) {
}
}
拦截器二:CountInterceptor
public class CountInterceptor implements ProducerInterceptor<String, String> {
private static int success = 0;
private static int fail = 0;
@Override
public ProducerRecord<String, String> onSend(ProducerRecord<String, String> record) {
// 这里要将null 修改为record
return record;
}
@Override
public void onAcknowledgement(RecordMetadata metadata, Exception exception) {
if (metadata != null && exception == null) {
success++;
} else {
fail++;
}
}
@Override
public void close() {
System.out.println("sucess: " + success);
System.out.println("fail: " + fail);
}
@Override
public void configure(Map<String, ?> configs) {
}
}
注意这里的Close方法,在Producer调用close()时候才会调用。如果生产者不调用close方法,拦截器的close方法也不会调用的!
生产者配置拦截器
配置类中,配置INTERCEPTOR_CLASSES_CONFIG
ArrayList<String> interceptors = new ArrayList<>();
interceptors.add("com.sakura.interceptor.TimestampInterceptor");
interceptors.add("com.sakura.interceptor.CountInterceptor");
props.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG, interceptors)
启动
消费者输出
生产者输出:
bingo!!!
五、Kafka监控
前面学习使用了Kafka,但是我们并不清楚集群的状态,现在我们使用KafkaEagle作为监控平台,实时监控集群的状态。
5.1、Kafka Eagle安装和配置启动
-
官网下载tar.gz包 KafkaEagle官方地址
-
第一次解压后,对其中的 Kafka-eagle-web再次解压并解压到/opt/module目录下。
-
修改kafka启动脚本
kafka-server-start.shif [ "x$KAFKA_HEAP_OPTS" = "x" ]; then export KAFKA_HEAP_OPTS="-Xmx1G -Xms1G" fi改为
if [ "x$KAFKA_HEAP_OPTS" = "x" ]; then export KAFKA_HEAP_OPTS="-server -Xms2G -Xmx2G -XX:PermSize=128m -XX:+UseG1GC -XX:MaxGCPauseMillis=200 -XX:ParallelGCThreads=8 -XX:ConcGCThreads=5 -XX:InitiatingHeapOccupancyPercent=70" export JMX_PORT="9999" fi改完后分发。
-
配置Eagle环境变量
export KE_HOME=/opt/module/kafka-eagle-web-2.0.1 export PATH=$PATH:$KE_HOME/binsource /etc/profile 重新加载环境变量
-
修改kafka-eagle配置文件 :
/opt/module/kafka-eagle-web-2.0.1/conf/system-config.propertieskafka.eagle.zk.cluster.alias=cluster1,cluster2 cluster1.zk.list=tdn1:2181,tdn2:2181,tdn3:2181 cluster2.zk.list=xdn10:2181,xdn11:2181,xdn12:2181这个默认配置是监控的两个集群,我们只有一个所以改为:
kafka.eagle.zk.cluster.alias=cluster1 cluster1.zk.list=hadoop102:2181,hadoop103:2181,hadoop103:2181
kafka.eagle.webui.port=8048这是web页面的端口
cluster1.kafka.eagle.offset.storage=kafka cluster2.kafka.eagle.offset.storage=zkoffset的存储位置:kafka、zk,我们只保留集群一的,并设置存储在kafka
kafka.eagle.metrics.charts=true检查图表功能开启
kafka JDBC连接,这里给了两套配置(Sqlite,Mysql),我们选择MySQL的配置
kafka.eagle.driver=com.mysql.jdbc.Driver kafka.eagle.url=jdbc:mysql://127.0.0.1:3306/kafka_eagle?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull kafka.eagle.username=root kafka.eagle.password=123456数据库不存在会自动创建。
-
重启Kafka和zookeeper集群
-
检查kafka-eagle-web bin目录下的ke.sh文件的执行权限,使用
ke.sh start启动!!
-
访问web页面,并使用默认的账号密码登录
里面的使用慢慢摸索吧
-
使用
ke.sh stop停止服务。
六、Flume对接Kafka
为什么Flume要对接Kafka?应用场景?
首先Flume和Kafka在实际应用场景中都存在一些缺陷:
- Flume无法动态扩展 采集数据传输的目的地
- Kafka的生产者的数据来源有限,例如监控目录就有困难
现在将两者结合,Flume使用功能强大的Source组件监控数据 使用KafkaSink,作为Kafka的生产者传输数据到Kafka,Kafka这边动态上下线消费者实现动态扩展 传输目的地。
对接实现
-
配置Flume(flume-kafka.conf)
# 组件命名 a1.sources = r1 a1.sinks = k1 a1.channels = c1 # Source Netcat a1.sources.r1.type = netcat a1.sources.r1.bind = hadoop102 a1.sources.r1.port = 44444 # Sink KafkaSinke a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink a1.sinks.k1.kafka.topic = testC a1.sinks.k1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092,hadoop104:9092 a1.sinks.k1.kafka.flumeBatchSize = 20 a1.sinks.k1.kafka.producer.acks = 1 a1.sinks.k1.kafka.producer.linger.ms = 1 # Channel MemoryChannel a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 # 对接Channel a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1KafkaSink的配置项都是Producer的一些配置,官方给出的配置清单:
-
启动一个Kafka的消费者
-
Flume启动Agent
bin/flume-ng agent -c conf/ -f job/netcat-kafka.conf -n a1 -
启动netcat连接agent
nc hadoop102 44444 -
netcat发送消息,查看消费者控制台输出:
进化 (数据分类放置到不同的Topic)
我们从外界采集的数据,可能需要分类放置到不同的Topic中,按照之前Flume的学习案例,我们会在Flume中设置一个拦截器,为特定的数据添加header,然后通过配置Channel选择器为对应的header属性选择Channel,然后发送到不同的Sink组。所以我们需要在原来的基础上增加一个Channel和KafkaSink。这样的做法十分繁杂,Flume官方对于Kafka做了很多的适配,不信你看这段话:
说KafkaSink中对于Event的header中的topic,key这两个属性是可以直接被Kafka所使用!!
当header中存在 topic属性,那么将覆盖配置文件中的topic配置,将数据写入到header中指定的topic。
当header中存在key属性,其可以作为消息的key,同样可以用于分区的选择,若不存在则为null,在没有指定topic的情况下随机发送到topic
Event的Header里面的topic,key是可以直接被Kafka拿去用的,并且没有什么不同
那么现在我们实现数据分类,只需要一个Flume拦截器,判断数据内容,在Header上设置好topic属性就行了!!
-
Flume拦截器代码
public class NumberInterceptor implements Interceptor { private static final Pattern NUMBER_PATTERN = Pattern.compile("[0-9]+"); private ArrayList<Event> handleEvents; @Override public void initialize() { handleEvents = new ArrayList<>(); } @Override public Event intercept(Event event) { String data = new String(event.getBody()); Map<String, String> headers = event.getHeaders(); Matcher matcher = NUMBER_PATTERN.matcher(data); if (matcher.find()) { headers.put("topic", "testB"); } else { headers.put("topic", "testC"); } return event; } @Override public List<Event> intercept(List<Event> list) { handleEvents.clear(); list.forEach(event -> handleEvents.add(intercept(event))); return handleEvents; } @Override public void close() { } public static class Builder implements Interceptor.Builder { @Override public Interceptor build() { return new NumberInterceptor(); } @Override public void configure(Context context) { } } } -
打包发到集群上(/opt/module/flume1.7.0/lib)
-
Flume配置文件修改:
# 拦截器配置 a1.sources.r1.interceptors = i1 a1.sources.r1.interceptors.i1.type = com.sakura.interceptor.NumberInterceptor$Builder -
启动topicB topicC的消费者
-
启动Agent,netcat连接发送消息
七、常见面试题
- Kafka中的 ISR(InSyncRepli)、OSR(OutSyncRepli)、AR(AllRepli)
- Kafka的HW、LED
- 消息顺序性如何体现?(分区内有序)
- 分区器、序列化器、拦截器,处理的顺序
- 客户端架构,几个线程
- 消费者和topic分区数量的控制
- 那些情况会导致重复消费、消息漏消费(提交Offset故障)
- topic的分区可不可以增加?可不可以减少?(可增不可减)
- Kafka内部Topic,有什么作用?
- 分区分配的概率和策略
- Kafka的log目录结构(消息数据文件=>index、log),如何定位消息?
- Kafka Controller的作用
- 为什么Kafka性能高,速度快?采用了那些机制?
- ExactlyOnce语义和幂等性

 浙公网安备 33010602011771号
浙公网安备 33010602011771号