Go第十二篇之避坑指南
了解goroutine的生命期时再创建goroutine#
在 Go 语言中,开发者习惯将并发内容与 goroutine 一一对应地创建 goroutine。开发者很少会考虑 goroutine 在什么时候能退出和控制 goroutine 生命期,这就会造成 goroutine 失控的情况。下面来看一段代码。
失控的 goroutine:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 | package mainimport ( "fmt" "runtime")// 一段耗时的计算函数func consumer(ch chan int) { // 无限获取数据的循环 for { // 从通道获取数据 data := <-ch // 打印数据 fmt.Println(data) }}func main() { // 创建一个传递数据用的通道 ch := make(chan int) for { // 空变量, 什么也不做 var dummy string // 获取输入, 模拟进程持续运行 fmt.Scan(&dummy) // 启动并发执行consumer()函数 go consumer(ch) // 输出现在的goroutine数量 fmt.Println("goroutines:", runtime.NumGoroutine()) }} |
代码说明如下:
- 第 9 行,consumer() 函数模拟平时业务中放到 goroutine 中执行的耗时操作。该函数从其他 goroutine 中获取和接收数据或者指令,处理后返回结果。
- 第 12 行,需要通过无限循环不停地获取数据。
- 第 15 行,每次从通道中获取数据。
- 第 18 行,模拟处理完数据后的返回数据。
- 第 26 行,创建一个整型通道。
- 第 34 行,使用 fmt.Scan() 函数接收数据时,需要提供变量地址。如果输入匹配的变量类型,将会成功赋值给变量。
- 第 37 行,启动并发执行 consumer() 函数,并传入 ch 通道。
- 第 40 行,每启动一个 goroutine,使用 runtime.NumGoroutine 检查进程创建的 goroutine 数量总数。
运行程序,每输入一个字符串+回车,将会创建一个 goroutine,结果如下:
a
goroutines: 2
b
goroutines: 3
c
goroutines: 4
注意,结果中 a、b、c 为通过键盘输入的字符,其他为打印字符。
这个程序实际在模拟一个进程根据需要创建 goroutine 的情况。运行后,问题已经被暴露出来:随着输入的字符串越来越多,goroutine 将会无限制地被创建,但并不会结束。这种情况如果发生在生产环境中,将会造成内存大量分配,最终使进程崩溃。现实的情况也许比这段代码更加隐蔽:也许你设置了一个退出的条件,但是条件永远不会被满足或者触发。
为了避免这种情况,在这个例子中,需要为 consumer() 函数添加合理的退出条件,修改代码后如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 | package mainimport ( "fmt" "runtime")// 一段耗时的计算函数func consumer(ch chan int) { // 无限获取数据的循环 for { // 从通道获取数据 data := <-ch if data == 0 { break } // 打印数据 fmt.Println(data) } fmt.Println("goroutine exit")}func main() { // 传递数据用的通道 ch := make(chan int) for { // 空变量, 什么也不做 var dummy string // 获取输入, 模拟进程持续运行 fmt.Scan(&dummy) if dummy == "quit" { for i := 0; i < runtime.NumGoroutine()-1; i++ { ch <- 0 } continue } // 启动并发执行consumer()函数 go consumer(ch) // 输出现在的goroutine数量 fmt.Println("goroutines:", runtime.NumGoroutine()) }} |
代码中加粗部分是新添加的代码,具体说明如下:
- 第 17 行,为无限循环设置退出条件,这里设置 0 为退出。
- 第 41 行,当命令行输入 quit 时,进入退出处理的流程。
- 第 43 行,runtime.NumGoroutine 返回一个进程的所有 goroutine 数,main() 的 goroutine 也被算在里面。因此需要扣除 main() 的 goroutine 数。剩下的 goroutine 为实际创建的 goroutine 数,对这些 goroutine 进行遍历。
- 第 44 行,并发开启的 goroutine 都在竞争获取通道中的数据,因此只要知道有多少个 goroutine 需要退出,就给通道里发多少个 0。
修改程序并运行,结果如下:
a
goroutines: 2
b
goroutines: 3
quit
goroutine exit
goroutine exit
c
goroutines: 2
避免在不必要的地方使用通道#
通道(channel)和 map、切片一样,也是由 Go 源码编写而成。为了保证两个 goroutine 并发访问的安全性,通道也需要做一些锁操作,因此通道其实并不比锁高效。
下面的例子展示套接字的接收和并发管理。对于 TCP 来说,一般是接收过程创建 goroutine 并发处理。当套接字结束时,就要正常退出这些 goroutine。
下面是对各个部分的详细分析。
1) 套接字接收部分#
套接字在连接后,就需要不停地接收数据,代码如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 | // 套接字接收过程func socketRecv(conn net.Conn, exitChan chan string) {// 创建一个接收的缓冲 buff := make([]byte, 1024) // 不停地接收数据 for { // 从套接字中读取数据 _, err := conn.Read(buff) // 需要结束接收, 退出循环 if err != nil { break } } // 函数已经结束, 发送通知 exitChan <- "recv exit"} |
代码说明如下:
- 第 2 行传入的 net.Conn 是套接字的接口,exitChan 为退出发送同步通道。
- 第 5 行为套接字的接收数据创建一个缓冲。
- 第 8 行构建一个接收的循环,不停地接收数据。
- 第 11 行,从套接字中取出数据。这个例子中,不关注具体接收到的数据,只是关注错误,这里将接收到的字节数做匿名处理。
- 第 14 行,当套接字调用了 Close 方法时,会触发错误,这时需要结束接收循环。
- 第 21 行,结束函数时,与函数绑定的 goroutine 会同时结束,此时需要通知 main() 的 goroutine。
2) 连接、关闭、同步 goroutine 主流程部分#
下面代码中尝试使用套接字的 TCP 协议连接一个网址,连接上后,进行数据接收,等待一段时间后主动关闭套接字,等待套接字所在的 goroutine 自然结束,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | func main() { // 连接一个地址 conn, err := net.Dial("tcp", "www.163.com:80") // 发生错误时打印错误退出 if err != nil { fmt.Println(err) return } // 创建退出通道 exit := make(chan string) // 并发执行套接字接收 go socketRecv(conn, exit) // 在接收时, 等待1秒 time.Sleep(time.Second) // 主动关闭套接字 conn.Close() // 等待goroutine退出完毕 fmt.Println(<-exit)} |
代码说明如下:
- 第 4 行,使用 net.Dial 发起 TCP 协议的连接,调用函数就会发送阻塞直到连接超时或者连接完成。
- 第 7 行,如果连接发生错误,将会打印错误并退出。
- 第 13 行,创建一个通道用于退出信号同步,这个通道会在接收用的 goroutine 中使用。
- 第 16 行,并发执行接收函数,传入套接字和用于退出通知的通道。
- 第 19 行,接收需要一个过程,使用 time.Sleep() 等待一段时间。
- 第 22 行,主动关闭套接字,此时会触发套接字接收错误。
- 第 25 行,从 exit 通道接收退出数据,也就是等待接收 goroutine 结束。
在这个例子中,goroutine 退出使用通道来通知,这种做法可以解决问题,但是实际上通道中的数据并没有完全使用。
3) 优化:使用等待组替代通道简化同步#
通道的内部实现代码在 Go 语言开发包的 src/runtime/chan.go 中,经过分析后大概了解到通道也是用常见的互斥量等进行同步。因此通道虽然是一个语言级特性,但也不是被神化的特性,通道的运行和使用都要比传统互斥量、等待组(sync.WaitGroup)有一定的消耗。
所以在这个例子中,更建议使用等待组来实现同步,调整后的代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 | package mainimport ( "fmt" "net" "sync" "time")// 套接字接收过程func socketRecv(conn net.Conn, wg *sync.WaitGroup) { // 创建一个接收的缓冲 buff := make([]byte, 1024) // 不停地接收数据 for { // 从套接字中读取数据 _, err := conn.Read(buff) // 需要结束接收, 退出循环 if err != nil { break } } // 函数已经结束, 发送通知 wg.Done()}func main() { // 连接一个地址 conn, err := net.Dial("tcp", "www.163.com:80") // 发生错误时打印错误退出 if err != nil { fmt.Println(err) return } // 退出通道 var wg sync.WaitGroup // 添加一个任务 wg.Add(1) // 并发执行接收套接字 go socketRecv(conn, &wg) // 在接收时, 等待1秒 time.Sleep(time.Second) // 主动关闭套接字 conn.Close() // 等待goroutine退出完毕 wg.Wait() fmt.Println("recv done")} |
调整后的代码说明如下:
- 第 45 行,声明退出同步用的等待组。
- 第 48 行,为等待组的计数器加 1,表示需要完成一个任务。
- 第 51 行,将等待组的指针传入接收函数。
- 第 60 行,等待等待组的完成,完成后打印提示。
- 第 30 行,接收完成后,使用 wg.Done() 方法将等待组计数器减一。
现在的一些流行设计思想需要建立在反射基础上,如控制反转(Inversion Of Control,IOC)和依赖注入(Dependency Injection,DI)。Go 语言中非常有名的 Web 框架 martini(https://github.com/go-martini/martini)就是通过依赖注入技术进行中间件的实现,例如使用 martini 框架搭建的 http 的服务器如下:
1 2 3 4 5 6 7 8 9 10 11 | package mainimport "github.com/go-martini/martini"func main() { m := martini.Classic() m.Get("/", func() string { return "Hello world!" }) m.Run()} |
第 7 行,响应路径/的代码使用一个闭包实现。如果希望获得 Go 语言中提供的请求和响应接口,可以直接修改为:
1 2 3 | m.Get("/", func(res http.ResponseWriter, req *http.Request) string { // 响应处理代码……}) |
martini 的底层会自动通过识别 Get 获得的闭包参数情况,通过动态反射调用这个函数并传入需要的参数。martini 的设计广受好评,但同时也有人指出,其运行效率较低。其中最主要的因素是大量使用了反射。
虽然一般情况下,I/O 的延迟远远大于反射代码所造成的延迟。但是,更低的响应速度和更低的 CPU 占用依然是 Web 服务器追求的目标。因此,反射在带来灵活性的同时,也带上了性能低下的桎梏。
要用好反射这把双刃剑,就需要详细了解反射的性能。下面的一些基准测试从多方面对比了原生调用和反射调用的区别。
1) 结构体成员赋值对比#
反射经常被使用在结构体上,因此结构体的成员访问性能就成为了关注的重点。下面例子中使用一个被实例化的结构体,访问它的成员,然后使用 Go 语言的基准化测试可以迅速测试出结果。
反射性能测试的完整代码位于./src/chapter12/reflecttest/reflect_test.go,下面是对各个部分的详细说明。
原生结构体的赋值过程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | // 声明一个结构体, 拥有一个字段type data struct { Hp int}func BenchmarkNativeAssign(b *testing.B) { // 实例化结构体 v := data{Hp: 2} // 停止基准测试的计时器 b.StopTimer() // 重置基准测试计时器数据 b.ResetTimer() // 重新启动基准测试计时器 b.StartTimer() // 根据基准测试数据进行循环测试 for i := 0; i < b.N; i++ { // 结构体成员赋值测试 v.Hp = 3 }} |
代码说明如下:
- 第 2 行,声明一个普通结构体,拥有一个成员变量。
- 第 6 行,使用基准化测试的入口。
- 第 9 行,实例化 data 结构体,并给 Hp 成员赋值。
- 第 12~17 行,由于测试的重点必须放在赋值上,因此需要极大程度地降低其他代码的干扰,于是在赋值完成后,将基准测试的计时器复位并重新开始。
- 第 20 行,将基准测试提供的测试数量用于循环中。
- 第 23 行,测试的核心代码:结构体赋值。
接下来的代码分析使用反射访问结构体成员并赋值的过程
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | func BenchmarkReflectAssign(b *testing.B) { v := data{Hp: 2} // 取出结构体指针的反射值对象并取其元素 vv := reflect.ValueOf(&v).Elem() // 根据名字取结构体成员 f := vv.FieldByName("Hp") b.StopTimer() b.ResetTimer() b.StartTimer() for i := 0; i < b.N; i++ { // 反射测试设置成员值性能 f.SetInt(3) }} |
代码说明如下:
- 第 6 行,取v的地址并转为反射值对象。此时值对象里的类型为 *data,使用值的 Elem() 方法取元素,获得 data 的反射值对象。
- 第 9 行,使用 FieldByName() 根据名字取出成员的反射值对象。
- 第 11~13 行,重置基准测试计时器。
- 第 18 行,使用反射值对象的 SetInt() 方法,给 data 结构的
Hp字段设置数值 3。
这段代码中使用了反射值对象的 SetInt() 方法,这个方法的源码如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | func (v Value) SetInt(x int64) { v.mustBeAssignable() switch k := v.kind(); k { default: panic(&ValueError{"reflect.Value.SetInt", v.kind()}) case Int: *(*int)(v.ptr) = int(x) case Int8: *(*int8)(v.ptr) = int8(x) case Int16: *(*int16)(v.ptr) = int16(x) case Int32: *(*int32)(v.ptr) = int32(x) case Int64: *(*int64)(v.ptr) = x }} |
可以发现,整个设置过程都是指针转换及赋值,没有遍历及内存操作等相对耗时的算法。
2) 结构体成员搜索并赋值对比#
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | func BenchmarkReflectFindFieldAndAssign(b *testing.B) { v := data{Hp: 2} vv := reflect.ValueOf(&v).Elem() b.StopTimer() b.ResetTimer() b.StartTimer() for i := 0; i < b.N; i++ { // 测试结构体成员的查找和设置成员的性能 vv.FieldByName("Hp").SetInt(3) }} |
这段代码将反射值对象的 FieldByName() 方法与 SetInt() 方法放在循环里进行检测,主要对比测试 FieldByName() 方法对性能的影响。FieldByName() 方法源码如下:
1 2 3 4 5 6 7 | func (v Value) FieldByName(name string) Value { v.mustBe(Struct) if f, ok := v.typ.FieldByName(name); ok { return v.FieldByIndex(f.Index) } return Value{}} |
底层代码说明如下:
- 第 3 行,通过名字查询类型对象,这里有一次遍历过程。
- 第 4 行,找到类型对象后,使用 FieldByIndex() 继续在值中查找,这里又是一次遍历。
经过底层代码分析得出,随着结构体字段数量和相对位置的变化,FieldByName() 方法比较严重的低效率问题。
3) 调用函数对比#
反射的函数调用,也是使用反射中容易忽视的性能点,下面展示对普通函数的调用过程。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | // 一个普通函数func foo(v int) {}func BenchmarkNativeCall(b *testing.B) { for i := 0; i < b.N; i++ { // 原生函数调用 foo(0) }}func BenchmarkReflectCall(b *testing.B) { // 取函数的反射值对象 v := reflect.ValueOf(foo) b.StopTimer() b.ResetTimer() b.StartTimer() for i := 0; i < b.N; i++ { // 反射调用函数 v.Call([]reflect.Value{reflect.ValueOf(2)}) }} |
代码说明如下:
- 第 2 行,一个普通的只有一个参数的函数。
- 第 10 行,对原生函数调用的性能测试。
- 第 17 行,根据函数名取出反射值对象。
- 第 25 行,使用 reflect.ValueOf(2) 将 2 构造为反射值对象,因为反射函数调用的参数必须全是反射值对象,再使用 []reflect.Value 构造多个参数列表传给反射值对象的 Call() 方法进行调用。
反射函数调用的参数构造过程非常复杂,构建很多对象会造成很大的内存回收负担。Call() 方法内部就更为复杂,需要将参数列表的每个值从 reflect.Value 类型转换为内存。调用完毕后,还要将函数返回值重新转换为 reflect.Value 类型返回。因此,反射调用函数的性能堪忧。
4) 基准测试结果对比#
测试结果如下:
$ go test -v -bench=. goos: linux goarch: amd64 BenchmarkNativeAssign-4 2000000000 0.32 ns/op BenchmarkReflectAssign-4 300000000 4.42 ns/op BenchmarkReflectFindFieldAndAssign-4 20000000 91.6 ns/op BenchmarkNativeCall-4 2000000000 0.33 ns/op BenchmarkReflectCall-4 10000000 163 ns/op PASS
结果分析如下:
- 第 4 行,原生的结构体成员赋值,每一步操作耗时 0.32 纳秒,这是参考基准。
- 第 5 行,使用反射的结构体成员赋值,操作耗时 4.42 纳秒,比原生赋值多消耗 13 倍的性能。
- 第 6 行,反射查找结构体成员且反射赋值,操作耗时 91.6 纳秒,扣除反射结构体成员赋值的 4.42 纳秒还富余,性能大概是原生的 272 倍。这个测试结果与代码分析结果很接近。SetInt 的性能可以接受,但 FieldByName() 的性能就非常低。
- 第 7 行,原生函数调用,性能与原生访问结构体成员接近。
- 第 8 行,反射函数调用,性能差到“爆棚”,花费了 163 纳秒,操作耗时比原生多消耗 494 倍。
经过基准测试结果的数值分析及对比,最终得出以下结论:
- 能使用原生代码时,尽量避免反射操作。
- 提前缓冲反射值对象,对性能有很大的帮助。
- 避免反射函数调用,实在需要调用时,先提前缓冲函数参数列表,并且尽量少地使用返回值。
nil 在 Go 语言中只能被赋值给指针和接口。接口在底层的实现有两个部分:type 和 data。在源码中,显式地将 nil 赋值给接口时,接口的 type 和 data 都将为 nil。此时,接口与 nil 值判断是相等的。但如果将一个带有类型的 nil 赋值给接口时,只有 data 为 nil,而 type 为 nil,此时,接口与 nil 判断将不相等。
接口与nil不相等#
下面代码使用 MyImplement() 实现 fmt 包中的 Stringer 接口,这个接口的定义如下:
- type Stringer interface {
- String() string
- }
在 GetStringer() 函数中将返回这个接口。通过 *MyImplement 指针变量置为 nil 提供 GetStringer 的返回值。在 main() 中,判断 GetStringer 与 nil 是否相等,代码如下:
- package main
- import "fmt"
- // 定义一个结构体
- type MyImplement struct{}
- // 实现fmt.Stringer的String方法
- func (m *MyImplement) String() string {
- return "hi"
- }
- // 在函数中返回fmt.Stringer接口
- func GetStringer() fmt.Stringer {
- // 赋nil
- var s *MyImplement = nil
- // 返回变量
- return s
- }
- func main() {
- // 判断返回值是否为nil
- if GetStringer() == nil {
- fmt.Println("GetStringer() == nil")
- } else {
- fmt.Println("GetStringer() != nil")
- }
- }
代码说明如下:
- 第 9 行,实现 fmt.Stringer 的 String() 方法。
- 第 21 行,s 变量此时被 fmt.Stringer 接口包装后,实际类型为 *MyImplement,值为 nil 的接口。
- 第 27 行,使用 GetStringer() 的返回值与 nil 判断时,虽然接口里的 value 为 nil,但 type 带有 *MyImplement 信息,使用 == 判断相等时,依然不为 nil。
发现nil类型值返回时直接返回nil#
为了避免这类误判的问题,可以在函数返回时,发现带有 nil 的指针时直接返回 nil,代码如下:
- func GetStringer() fmt.Stringer {
- var s *MyImplement = nil
- if s == nil {
- return nil
- }
- return s
- }
在大多数的编程语言中,映射容器的键必须以单一值存在。这种映射方法经常被用在诸如信息检索上,如根据通讯簿的名字进行检索。但随着查询条件越来越复杂,检索也会变得越发困难。下面例子中涉及通讯簿的结构,结构如下:
- // 人员档案
- type Profile struct {
- Name string // 名字
- Age int // 年龄
- Married bool // 已婚
- }
// 人员档案
type Profile struct {
Name string // 名字
Age int // 年龄
Married bool // 已婚
}
并且准备好了一堆原始数据,需要算法实现构建索引和查询的过程,代码如下:
- func main() {
- list := []*Profile{
- {Name: "张三", Age: 30, Married: true},
- {Name: "李四", Age: 21},
- {Name: "王麻子", Age: 21},
- }
- buildIndex(list)
- queryData("张三", 30)
- }
func main() {
list := []*Profile{
{Name: "张三", Age: 30, Married: true},
{Name: "李四", Age: 21},
{Name: "王麻子", Age: 21},
}
buildIndex(list)
queryData("张三", 30)
}
需要用算法实现 buildIndex() 构建索引函数及 queryData() 查询数据函数,查询到结果后将数据打印出来。
下面,分别基于传统的基于哈希值的多键索引和利用 map 特性的多键索引进行查询。
基于哈希值的多键索引及查询
传统的数据索引过程是将输入的数据做特征值。这种特征值有几种常见做法:
- 将特征使用某种算法转为整数,即哈希值,使用整型值做索引。
- 将特征转为字符串,使用字符串做索引。
数据都基于特征值构建好索引后,就可以进行查询。查询时,重复这个过程,将查询条件转为特征值,使用特征值进行查询得到结果。
基于哈希的传统多键索引和查询的完整代码位于./src/chapter12/classic/classic.go,下面是对各个部分的分析。
1) 字符串转哈希值#
本例中,查询键(classicQueryKey)的特征值需要将查询键中每一个字段转换为整型,字符串也需要转换为整型值,这里使用一种简单算法将字符串转换为需要的哈希值,代码如下:
- func simpleHash(str string) (ret int) {
- // 遍历字符串中的每一个ASCII字符
- for i := 0; i < len(str); i++ {
- // 取出字符
- c := str[i]
- // 将字符的ASCII码相加
- ret += int(c)
- }
- return
- }
func simpleHash(str string) (ret int) {
// 遍历字符串中的每一个ASCII字符
for i := 0; i < len(str); i++ {
// 取出字符
c := str[i]
// 将字符的ASCII码相加
ret += int(c)
}
return
}
代码说明如下:
- 第 1 行传入需要计算哈希值的字符串。
- 第 4 行,根据字符串的长度,遍历这个字符串的每一个字符,以 ASCII 码为单位。
- 第 9 行,c变量的类型为 uint8,将其转为 int 类型并累加。
哈希算法有很多,这里只是选用一种大家便于理解的算法。哈希算法的选用的标准是尽量减少重复键的发生,俗称“哈希冲撞”,即同样两个字符串的哈希值重复率降到最低。
2) 查询键#
有了哈希算法函数后,将哈希函数用在查询键结构中。查询键结构如下:
- // 查询键
- type classicQueryKey struct {
- Name string // 要查询的名字
- Age int // 要查询的年龄
- }
- // 计算查询键的哈希值
- func (c *classicQueryKey) hash() int {
- // 将名字的Hash和年龄哈希合并
- return simpleHash(c.Name) + c.Age*1000000
- }
// 查询键
type classicQueryKey struct {
Name string // 要查询的名字
Age int // 要查询的年龄
}
// 计算查询键的哈希值
func (c *classicQueryKey) hash() int {
// 将名字的Hash和年龄哈希合并
return simpleHash(c.Name) + c.Age*1000000
}
代码说明如下:
- 第 2 行,声明查询键的结构,查询键包含需要索引和查询的字段。
- 第 8 行,查询键的成员方法哈希,通过调用这个方法获得整个查询键的哈希值。
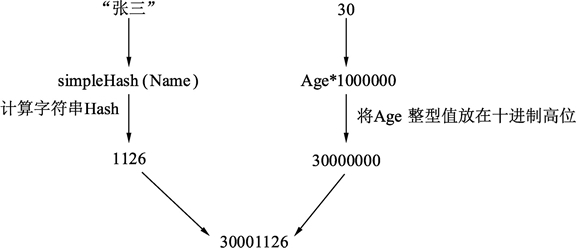
- 第 10 行,查询键哈希的计算方法:使用 simpleHash() 函数根据给定的名字字符串获得其哈希值。同时将年龄乘以 1000000 与名字哈希值相加。
哈希值构建过程如下图所示
3) 构建索引#
本例需要快速查询,因此需要提前对已有的数据构建索引。前面已经准备好了数据查询键,使用查询键获得哈希即可对数据进行快速索引,参考下面的代码:
- // 创建哈希值到数据的索引关系
- var mapper = make(map[int][]*Profile)
- // 构建数据索引
- func buildIndex(list []*Profile) {
- // 遍历所有的数据
- for _, profile := range list {
- // 构建数据的查询索引
- key := classicQueryKey{profile.Name, profile.Age}
- // 计算数据的哈希值, 取出已经存在的记录
- existValue := mapper[key.hash()]
- // 将当前数据添加到已经存在的记录切片中
- existValue = append(existValue, profile)
- // 将切片重新设置到映射中
- mapper[key.hash()] = existValue
- }
- }
// 创建哈希值到数据的索引关系
var mapper = make(map[int][]*Profile)
// 构建数据索引
func buildIndex(list []*Profile) {
// 遍历所有的数据
for _, profile := range list {
// 构建数据的查询索引
key := classicQueryKey{profile.Name, profile.Age}
// 计算数据的哈希值, 取出已经存在的记录
existValue := mapper[key.hash()]
// 将当前数据添加到已经存在的记录切片中
existValue = append(existValue, profile)
// 将切片重新设置到映射中
mapper[key.hash()] = existValue
}
}
代码说明如下:
- 第 2 行,实例化一个 map,键类型为整型,保存哈希值;值类型为 *Profile,为通讯簿的数据格式。
- 第 5 行,构建索引函数入口,传入数据切片。
- 第 8 行,遍历数据切片的所有数据元素。
- 第 11 行,使用查询键(classicQueryKey)来辅助计算哈希值,查询键需要填充两个字段,将数据中的名字和年龄赋值到查询键中进行保存。
- 第 14 行,使用查询键的哈希方法计算查询键的哈希值。通过这个值在 mapper 索引中查找相同哈希值的数据切片集合。因为哈希函数不能保证不同数据的哈希值一定完全不同,因此要考虑在发生哈希值重复时的处理办法。
- 第 17 行,将当前数据添加到可能存在的切片中。
- 第 20 行,将新添加好的数据切片重新赋值到相同哈希的 mapper 中。
具体哈希结构如下图所示。

图:哈希结构
这种多键的算法就是哈希算法。map 的多个元素对应哈希的“桶”。哈希函数的选择决定桶的映射好坏,如果哈希冲撞很厉害,那么就需要将发生冲撞的相同哈希值的元素使用切片保存起来。
4) 查询逻辑#
从已经构建好索引的数据中查询需要的数据流程如下:
- 给定查询条件(名字、年龄)。
- 根据查询条件构建查询键。
- 查询键生成哈希值。
- 根据哈希值在索引中查找数据集合。
- 遍历数据集合逐个与条件比对。
- 获得结果。
- func queryData(name string, age int) {
- // 根据给定查询条件构建查询键
- keyToQuery := classicQueryKey{name, age}
- // 计算查询键的哈希值并查询, 获得相同哈希值的所有结果集合
- resultList := mapper[keyToQuery.hash()]
- // 遍历结果集合
- for _, result := range resultList {
- // 与查询结果比对, 确认找到打印结果
- if result.Name == name && result.Age == age {
- fmt.Println(result)
- return
- }
- }
- // 没有查询到时, 打印结果
- fmt.Println("no found")
- }
func queryData(name string, age int) {
// 根据给定查询条件构建查询键
keyToQuery := classicQueryKey{name, age}
// 计算查询键的哈希值并查询, 获得相同哈希值的所有结果集合
resultList := mapper[keyToQuery.hash()]
// 遍历结果集合
for _, result := range resultList {
// 与查询结果比对, 确认找到打印结果
if result.Name == name && result.Age == age {
fmt.Println(result)
return
}
}
// 没有查询到时, 打印结果
fmt.Println("no found")
}
代码说明如下:
- 第 1 行,查询条件(名字、年龄)。
- 第 4 行,根据查询条件构建查询键。
- 第 7 行,使用查询键计算哈希值,使用哈希值查询相同哈希值的所有数据集合。
- 第 10 行,遍历所有相同哈希值的数据集合。
- 第 13 行,将每个数据与查询条件进行比对,如果一致,表示已经找到结果,打印并返回。
- 第 20 行,没有找到记录时,打印 no found。
利用map特性的多键索引及查询
使用结构体进行多键索引和查询比传统的写法更为简单,最主要的区别是无须准备哈希函数及相应的字段无须做哈希合并。看下面的实现流程。
利用map特性的多键索引和查询的代码位于./src/chapter12/multikey/multikey.go,下面是对各个部分的分析。
1) 构建索引#
代码如下:
- // 查询键
- type queryKey struct {
- Name string
- Age int
- }
- // 创建查询键到数据的映射
- var mapper = make(map[queryKey]*Profile)
- // 构建查询索引
- func buildIndex(list []*Profile) {
- // 遍历所有数据
- for _, profile := range list {
- // 构建查询键
- key := queryKey{
- Name: profile.Name,
- Age: profile.Age,
- }
- // 保存查询键
- mapper[key] = profile
- }
- }
// 查询键
type queryKey struct {
Name string
Age int
}
// 创建查询键到数据的映射
var mapper = make(map[queryKey]*Profile)
// 构建查询索引
func buildIndex(list []*Profile) {
// 遍历所有数据
for _, profile := range list {
// 构建查询键
key := queryKey{
Name: profile.Name,
Age: profile.Age,
}
// 保存查询键
mapper[key] = profile
}
}
代码说明如下:
- 第 2 行,与基于哈希值的查询键的结构相同。
- 第 8 行,在 map 的键类型上,直接使用了查询键结构体。注意,这里不使用查询键的指针。同时,结果只有 *Profile 类型,而不是 *Profile 切片,表示查到的结果唯一。
- 第 17 行,类似的,使用遍历到的数据的名字和年龄构建查询键。
- 第 23 行,更简单的,直接将查询键保存对应的数据。
2) 查询逻辑#
- // 根据条件查询数据
- func queryData(name string, age int) {
- // 根据查询条件构建查询键
- key := queryKey{name, age}
- // 根据键值查询数据
- result, ok := mapper[key]
- // 找到数据打印出来
- if ok {
- fmt.Println(result)
- } else {
- fmt.Println("no found")
- }
- }
// 根据条件查询数据
func queryData(name string, age int) {
// 根据查询条件构建查询键
key := queryKey{name, age}
// 根据键值查询数据
result, ok := mapper[key]
// 找到数据打印出来
if ok {
fmt.Println(result)
} else {
fmt.Println("no found")
}
}
代码说明如下:
- 第 5 行,根据查询条件(名字、年龄)构建查询键。
- 第 8 行,直接使用查询键在 map 中查询结果。
- 第 12 行,找到结果直接打印。
- 第 14 行,没有找到结果打印 no found。
总结
基于哈希值的多键索引查询和利用map特性的多键索引查询的代码复杂程度显而易见。聪明的程序员都会利用Go语言的特性进行快速的多键索引查询。
其实,利用 map 特性的例子中的 map 类型即便修改为下面的格式,也一样可以获得同样的结果:
- var mapper = make(map[interface{}]*Profile)
var mapper = make(map[interface{}]*Profile)
代码量大大减少的关键是:Go 语言的底层会为 map 的键自动构建哈希值。能够构建哈希值的类型必须是非动态类型、非指针、函数、闭包。
- 非动态类型:可用数组,不能用切片。
- 非指针:每个指针数值都不同,失去哈希意义。
- 函数、闭包不能作为 map 的键。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架