Django框架 (七) Django ORM模型
ORM简介#
查询数据层次图解:如果操作mysql,ORM是在pymysq之上又进行了一层封装
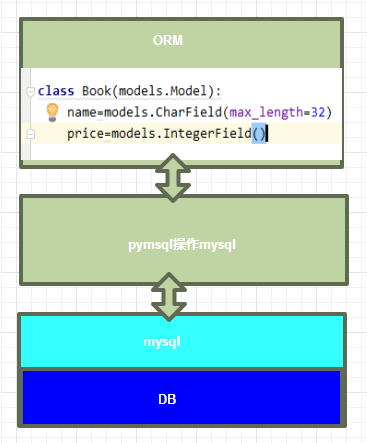
- MVC或者MTV框架中包括一个重要的部分,就是ORM,它实现了数据模型与数据库的解耦,即数据模型的设计不需要依赖于特定的数据库,通过简单的配置就可以轻松更换数据库,这极大的减轻了开发人员的工作量,不需要面对因数据库变更而导致的无效劳动
- ORM是“对象-关系-映射”的简称。

1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 | #sql中的表 #创建表: CREATE TABLE employee( id INT PRIMARY KEY auto_increment , name VARCHAR (20), gender BIT default 1, birthday DATA , department VARCHAR (20), salary DECIMAL (8,2) unsigned, );#sql中的表纪录 #添加一条表纪录: INSERT employee (name,gender,birthday,salary,department) VALUES ("alex",1,"1985-12-12",8000,"保洁部"); #查询一条表纪录: SELECT * FROM employee WHERE age=24; #更新一条表纪录: UPDATE employee SET birthday="1989-10-24" WHERE id=1; #删除一条表纪录: DELETE FROM employee WHERE name="alex" #python的类class Employee(models.Model): id=models.AutoField(primary_key=True) name=models.CharField(max_length=32) gender=models.BooleanField() birthday=models.DateField() department=models.CharField(max_length=32) salary=models.DecimalField(max_digits=8,decimal_places=2)#python的类对象#添加一条表纪录: emp=Employee(name="alex",gender=True,birthday="1985-12-12",epartment="保洁部") emp.save() #查询一条表纪录: Employee.objects.filter(age=24) #更新一条表纪录: Employee.objects.filter(id=1).update(birthday="1989-10-24") #删除一条表纪录: Employee.objects.filter(name="alex").delete() |
单表操作#
创建表#
创建模型#
创建名为book的app,在book下的models.py中创建模型
1 2 3 4 5 6 7 8 9 10 11 | from django.db import models# Create your models here.class Book(models.Model): id = models.AutoField(primary_key=True) name = models.CharField(max_length=64) pub_data = models.DateField() price = models.DecimalField(max_digits=5, decimal_places=2) publish = models.CharField(max_length=12) def __str__(self): return self.name |
更多字段和参数#
每个字段有一些特有的参数,例如,CharField需要max_length参数来指定VARCHAR数据库字段的大小。还有一些适用于所有字段的通用参数。 这些参数在文档中有详细定义,这里我们只简单介绍一些最常用的:
字段
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 | AutoField(Field) - int自增列,必须填入参数 primary_key=True BigAutoField(AutoField) - bigint自增列,必须填入参数 primary_key=True 注:当model中如果没有自增列,则自动会创建一个列名为id的列 from django.db import models class UserInfo(models.Model): # 自动创建一个列名为id的且为自增的整数列 username = models.CharField(max_length=32) class Group(models.Model): # 自定义自增列 nid = models.AutoField(primary_key=True) name = models.CharField(max_length=32) SmallIntegerField(IntegerField): - 小整数 -32768 ~ 32767 PositiveSmallIntegerField(PositiveIntegerRelDbTypeMixin, IntegerField) - 正小整数 0 ~ 32767 IntegerField(Field) - 整数列(有符号的) -2147483648 ~ 2147483647 PositiveIntegerField(PositiveIntegerRelDbTypeMixin, IntegerField) - 正整数 0 ~ 2147483647 BigIntegerField(IntegerField): - 长整型(有符号的) -9223372036854775808 ~ 9223372036854775807 自定义无符号整数字段 class UnsignedIntegerField(models.IntegerField): def db_type(self, connection): return 'integer UNSIGNED' PS: 返回值为字段在数据库中的属性,Django字段默认的值为: 'AutoField': 'integer AUTO_INCREMENT', 'BigAutoField': 'bigint AUTO_INCREMENT', 'BinaryField': 'longblob', 'BooleanField': 'bool', 'CharField': 'varchar(%(max_length)s)', 'CommaSeparatedIntegerField': 'varchar(%(max_length)s)', 'DateField': 'date', 'DateTimeField': 'datetime', 'DecimalField': 'numeric(%(max_digits)s, %(decimal_places)s)', 'DurationField': 'bigint', 'FileField': 'varchar(%(max_length)s)', 'FilePathField': 'varchar(%(max_length)s)', 'FloatField': 'double precision', 'IntegerField': 'integer', 'BigIntegerField': 'bigint', 'IPAddressField': 'char(15)', 'GenericIPAddressField': 'char(39)', 'NullBooleanField': 'bool', 'OneToOneField': 'integer', 'PositiveIntegerField': 'integer UNSIGNED', 'PositiveSmallIntegerField': 'smallint UNSIGNED', 'SlugField': 'varchar(%(max_length)s)', 'SmallIntegerField': 'smallint', 'TextField': 'longtext', 'TimeField': 'time', 'UUIDField': 'char(32)', BooleanField(Field) - 布尔值类型 NullBooleanField(Field): - 可以为空的布尔值 CharField(Field) - 字符类型 - 必须提供max_length参数, max_length表示字符长度 TextField(Field) - 文本类型 EmailField(CharField): - 字符串类型,Django Admin以及ModelForm中提供验证机制 IPAddressField(Field) - 字符串类型,Django Admin以及ModelForm中提供验证 IPV4 机制 GenericIPAddressField(Field) - 字符串类型,Django Admin以及ModelForm中提供验证 Ipv4和Ipv6 - 参数: protocol,用于指定Ipv4或Ipv6, 'both',"ipv4","ipv6" unpack_ipv4, 如果指定为True,则输入::ffff:192.0.2.1时候,可解析为192.0.2.1,开启刺功能,需要protocol="both" URLField(CharField) - 字符串类型,Django Admin以及ModelForm中提供验证 URL SlugField(CharField) - 字符串类型,Django Admin以及ModelForm中提供验证支持 字母、数字、下划线、连接符(减号) CommaSeparatedIntegerField(CharField) - 字符串类型,格式必须为逗号分割的数字 UUIDField(Field) - 字符串类型,Django Admin以及ModelForm中提供对UUID格式的验证 FilePathField(Field) - 字符串,Django Admin以及ModelForm中提供读取文件夹下文件的功能 - 参数: path, 文件夹路径 match=None, 正则匹配 recursive=False, 递归下面的文件夹 allow_files=True, 允许文件 allow_folders=False, 允许文件夹 FileField(Field) - 字符串,路径保存在数据库,文件上传到指定目录 - 参数: upload_to = "" 上传文件的保存路径 storage = None 存储组件,默认django.core.files.storage.FileSystemStorage ImageField(FileField) - 字符串,路径保存在数据库,文件上传到指定目录 - 参数: upload_to = "" 上传文件的保存路径 storage = None 存储组件,默认django.core.files.storage.FileSystemStorage width_field=None, 上传图片的高度保存的数据库字段名(字符串) height_field=None 上传图片的宽度保存的数据库字段名(字符串) DateTimeField(DateField) - 日期+时间格式 YYYY-MM-DD HH:MM[:ss[.uuuuuu]][TZ] DateField(DateTimeCheckMixin, Field) - 日期格式 YYYY-MM-DD TimeField(DateTimeCheckMixin, Field) - 时间格式 HH:MM[:ss[.uuuuuu]] DurationField(Field) - 长整数,时间间隔,数据库中按照bigint存储,ORM中获取的值为datetime.timedelta类型 FloatField(Field) - 浮点型 DecimalField(Field) - 10进制小数 - 参数: max_digits,小数总长度 decimal_places,小数位长度 BinaryField(Field) - 二进制类型 |
参数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 | (1)null 如果为True,Django 将用NULL 来在数据库中存储空值。 默认值是 False. (1)blank 如果为True,该字段允许不填。默认为False。要注意,这与 null 不同。null纯粹是数据库范畴的,而 blank 是数据验证范畴的。如果一个字段的blank=True,表单的验证将允许该字段是空值。如果字段的blank=False,该字段就是必填的。 (2)default 字段的默认值。可以是一个值或者可调用对象。如果可调用 ,每有新对象被创建它都会被调用。 (3)primary_key 如果为True,那么这个字段就是模型的主键。如果你没有指定任何一个字段的primary_key=True,Django 就会自动添加一个IntegerField字段做为主键,所以除非你想覆盖默认的主键行为,否则没必要设置任何一个字段的primary_key=True。 (4)unique 如果该值设置为 True, 这个数据字段的值在整张表中必须是唯一的 (5)choices由二元组组成的一个可迭代对象(例如,列表或元组),用来给字段提供选择项。 如果设置了choices ,默认的表单将是一个选择框而不是标准的文本框,<br>而且这个选择框的选项就是choices 中的选项。 |
源信息
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | class UserInfo(models.Model): nid = models.AutoField(primary_key=True) username = models.CharField(max_length=32) class Meta: # 数据库中生成的表名称 默认 app名称 + 下划线 + 类名 db_table = "table_name" # 联合索引 index_together = [ ("pub_date", "deadline"), ] # 联合唯一索引 unique_together = (("driver", "restaurant"),) # admin中显示的表名称 verbose_name # verbose_name加s verbose_name_plural |
settings配置
若想将模型转为mysql数据库中的表,需要在settings中配置:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 | DATABASES = { 'default': { 'ENGINE': 'django.db.backends.mysql', 'NAME': 'lqz', 'USER': 'root', 'PASSWORD': '123456', 'HOST': '127.0.0.1', 'PORT': 3306, 'ATOMIC_REQUEST': True, 'OPTIONS': { "init_command": "SET storage_engine=MyISAM", } }}''''NAME':要连接的数据库,连接前需要创建好'USER':连接数据库的用户名'PASSWORD':连接数据库的密码'HOST':连接主机,默认本机'PORT':端口 默认3306'ATOMIC_REQUEST': True,设置为True统一个http请求对应的所有sql都放在一个事务中执行(要么所有都成功,要么所有都失败)。是全局性的配置, 如果要对某个http请求放水(然后自定义事务),可以用non_atomic_requests修饰器 'OPTIONS': { "init_command": "SET storage_engine=MyISAM", }设置创建表的存储引擎为MyISAM,INNODB''' |
注意1:NAME即数据库的名字,在mysql连接前该数据库必须已经创建,而上面的sqlite数据库下的db.sqlite3则是项目自动创建 USER和PASSWORD分别是数据库的用户名和密码。设置完后,再启动我们的Django项目前,我们需要激活我们的mysql。然后,启动项目,会报错:no module named MySQLdb 。这是因为django默认你导入的驱动是MySQLdb,可是MySQLdb 对于py3有很大问题,所以我们需要的驱动是PyMySQL 所以,我们只需要找到项目名文件下的__init__,在里面写入
import pymysql pymysql.install_as_MySQLdb()
最后通过两条数据库迁移命令即可在指定的数据库中创建表
python manage.py makemigrations python manage.py migrate
注意2:确保配置文件中的INSTALLED_APPS中写入我们创建的app名称
1 2 3 4 5 6 7 8 9 | INSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', "book"] |
注意3:如果报错如下:
django.core.exceptions.ImproperlyConfigured: mysqlclient 1.3.3 or newer is required; you have 0.7.11.None
MySQLclient目前只支持到python3.4,因此如果使用的更高版本的python,需要修改如下:
通过查找路径C:\Programs\Python\Python36-32\Lib\site-packages\Django-2.0-py3.6.egg\django\db\backends\mysql
这个路径里的文件把
if version < (1, 3, 3):
raise ImproperlyConfigured("mysqlclient 1.3.3 or newer is required; you have %s" % Database.__version__)
注释掉就可以了
注意4: 如果想打印orm转换过程中的sql,需要在settings中进行如下配置:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | LOGGING = { 'version': 1, 'disable_existing_loggers': False, 'handlers': { 'console':{ 'level':'DEBUG', 'class':'logging.StreamHandler', }, }, 'loggers': { 'django.db.backends': { 'handlers': ['console'], 'propagate': True, 'level':'DEBUG', }, }} |
增加,删除字段#
删除,直接注释掉字段,执行数据库迁移命令即可
新增字段,在类里直接新增字段,直接执行数据库迁移命令会提示输入默认值,此时需要设置
publish = models.CharField(max_length=12,default='人民出版社',null=True)
注意:
1 数据库迁移记录都在 app01下的migrations里
2 使用showmigrations命令可以查看没有执行migrate的文件
3 makemigrations是生成一个文件,migrate是将更改提交到数据量
添加表纪录#
方式1
# create方法的返回值book_obj就是插入book表中的python葵花宝典这本书籍纪录对象 book_obj=Book.objects.create(title="python葵花宝典",state=True,price=100,publish="苹果出版社",pub_date="2012-12-12")
方式2
1 2 3 4 5 6 | import datetimectime=datetime.datetime.now()#生成对象,再调save方法book_obj=Book(title="python葵花宝典",state=True,price=100,publish="苹果出版社",pub_date="ctime") #传时间对象也满足book_obj.save() #把对象保存起来,这样就能成功存入数据库中 |
查询表纪录#
查询API
1 2 3 4 5 6 7 8 9 10 11 12 13 | <1> all(): 查询所有结果<2> filter(**kwargs): 它包含了与所给筛选条件相匹配的对象<3> get(**kwargs): 返回与所给筛选条件相匹配的对象,返回结果有且只有一个,如果符合筛选条件的对象超过一个或者没有都会抛出错误。<4> exclude(**kwargs): 它包含了与所给筛选条件不匹配的对象<5> order_by(*field): 对查询结果排序('-id')<6> reverse(): 对查询结果反向排序<8> count(): 返回数据库中匹配查询(QuerySet)的对象数量。<9> first(): 返回第一条记录<10> last(): 返回最后一条记录<11> exists(): 如果QuerySet包含数据,就返回True,否则返回False <12> values(*field): 返回一个ValueQuerySet——一个特殊的QuerySet,运行后得到的并不是一系列model的实例化对象,而是一个可迭代的字典序列<13> values_list(*field): 它与values()非常相似,它返回的是一个元组序列,values返回的是一个字典序列<14> distinct(): 从返回结果中剔除重复纪录 |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 | def index(request): # 添加表记录++++++++++++++++++++++++++++++++++ # 方式一 # book=Book(name='红楼梦',pub_data='2015-10-12',price=88,publish='老男孩出版社') # book.save() # 方式二 # Book.objects.create(name='Python红宝书',pub_data='2010-10-12',price=100,publish='人民出版社') # 查询表记录++++++++++++++++++++++++++++++++++ # QUerySet数据类型(类似于一个列表,里面放着一些对象) # 1 方法的返回值是什么 # 2 方法的调用者 # (1) all方法 返回一个QuerySet对象 # book_list=Book.objects.all() # print(book_list[1].name) # print(book_list) # for obj in book_list: # print(obj.name) # (2)first last:调用者是queryset对象,返回值是对象 # book=Book.objects.all().first() # book2=Book.objects.all().last() # print(book) # print(book2) # (3) filter 返回值是queryset对象(相当于where语句) # 可以加多个过滤条件 # book=Book.objects.filter(name='红楼梦').first() # print(book) # (4)get方法 有且只有一个查询结果才有意义 返回值是一个对象 # book=Book.objects.get(name='红楼梦') # print(book) # 直接报错 # book = Book.objects.get(name='红楼梦eee') # --------------最常用----------------- # (5)exclude 除了查询之外的 返回值也是queryset # ret=Book.objects.exclude(name='红楼梦') # print(ret) # (6)order_by(默认升序,加个- 就是降序),可以多个过滤条件调用者是queryset返回值也是queryset # book_list=Book.objects.all().order_by('id') # book_list=Book.objects.all().order_by('-id','price') # print(book_list) # (7)count() 调用者是queryset,返回值是int # ret=Book.objects.all().count() # print(ret) # (8)exist()判断是是否有值,不能传参数, # ret=Book.objects.all().exists() # print(ret) # (9)values方法 # 查询所有书籍的名称(里面传的值,前提是表有这个字段)也是queryset但是里面放的是字典 ''' values原理 temp=[] for obj in Book.objects.all(): temp.append({'name':obj.name}) ''' # ret=Book.objects.all().values('name') # print(ret) # 不加.all()也可以,调用是queryset返回值也是queryset # ret=Book.objects.values('price') # print(ret) # (10)value_list # ret=Book.objects.all().values_list('price','name') # print(ret) # (11) distinct seletc * 的时候没有意义 # SELECT DISTINCT name from app01_book; # 没有任何意义,不要这样么用 # Book.objects.all().distinct() # ret=Book.objects.all().values('name').distinct() # print(ret) # 双下划线模糊查询----------------------- # 查询价格大于100的书 # ret=Book.objects.filter(price__gt=100) # print(ret) # 查询大于50小于100的书 # ret=Book.objects.filter(price__gt=50,price__lt=100) # print(ret) # 查询已红楼开头的书 # ret=Book.objects.filter(name__startswith='红楼') # print(ret) # 查询包含‘红’的书 # ret= Book.objects.filter(name__contains='红') # print(ret) # icontains 不区分大小写 # 价格在50,88,100 中的 # ret=Book.objects.filter(price__in=[50,88,100]) # print(ret) # 出版日期在2018年的 # ret=Book.objects.filter(pub_data__year=2015,pub_data__month=2) # print(ret) # 删除,修改------------------------ # delete:调用者可以是queryset也可以是model对象 # 删除价格为188的书有返回值 (1, {'app01.Book': 1}) 删除的个数,那张表,记录数 # ret=Book.objects.filter(price=188).delete() # print(ret) # ret=Book.objects.filter(price=100).first().delete() # print(ret) # 修改 update只能queryset来调用 返回值为int # ret=Book.objects.filter(name='红楼梦1').update(name='红楼梦') # print(ret) # 报错 # Book.objects.filter(name='红楼梦').first().update(name='红楼梦1') # ret=Book.objects.filter(name='红楼梦1').first() # print(ret.delete()) # aa=Publish.objects.filter(name='人民出版社') # print(type(aa)) # aa.delete() return HttpResponse('ok') |
基于双下划线的模糊查询 #
1 2 3 4 5 6 7 8 9 10 | Book.objects.filter(price__in=[100,200,300]) #在列表中的值Book.objects.filter(price__gt=100) #大于Book.objects.filter(price__lt=100) #小于Book.objects.filter(price__gte=100) #大于等于Book.objects.filter(price__lte=100) #小于等于Book.objects.filter(price__range=[100,200]) #在100与200之间Book.objects.filter(title__contains="python") #包含pythonBook.objects.filter(title__icontains="python") #不区分大小写的包含Book.objects.filter(title__startswith="py") #以py开头Book.objects.filter(pub_date__year=2012) #在2012年之间<br>Book.objects.filter(pub_data__year='2017',pub_data__month='08') #在2017年的8月份中 |
删除表纪录#
删除方法就是 delete()。它运行时立即删除对象而不返回任何值。例如:
1 2 3 4 | pk代指主键<br>法一ret=models.Book.objects.filter(pk=1).delete()<br>法二<br>book=models.Book.objects.filter(pk=1).first()book.delete() |
你也可以一次性删除多个对象。每个 QuerySet 都有一个 delete() 方法,它一次性删除 QuerySet 中所有的对象。
例如,下面的代码将删除 pub_date 是2005年的 Entry 对象:
Entry.objects.filter(pub_date__year=2005).delete()
在 Django 删除对象时,会模仿 SQL 约束 ON DELETE CASCADE 的行为,换句话说,删除一个对象时也会删除与它相关联的外键对象。例如:
b = Blog.objects.get(pk=1) # This will delete the Blog and all of its Entry objects. b.delete()
要注意的是: delete() 方法是 QuerySet 上的方法,但并不适用于 Manager 本身。这是一种保护机制,是为了避免意外地调用 Entry.objects.delete() 方法导致 所有的 记录被误删除。如果你确认要删除所有的对象,那么你必须显式地调用:
Entry.objects.all().delete()
如果不想级联删除,可以设置为:
pubHouse = models.ForeignKey(to='Publisher', on_delete=models.SET_NULL, blank=True, null=True)
修改表纪录#
1 2 3 4 5 6 7 8 | # ret = models.Book.objects.filter(pk=2).update(name='ddd')# book=models.Book.objects.filter(pk=2).first()# book.name='XXX' # book这个对象是没有update这个方法的# book.update() 会报错,没有这个方法<br># 既可以保存,又可以更新# book.save() |
此外,update()方法对于任何结果集(QuerySet)均有效,这意味着你可以同时更新多条记录update()方法会返回一个整型数值,表示受影响的记录条数。
在Python脚本中调用Django环境#
1 2 3 4 5 6 7 8 9 10 | import osif __name__ == '__main__':<br> #加载项目环境 项目配置文件 os.environ.setdefault("DJANGO_SETTINGS_MODULE", "untitled15.settings") import django #加载django django.setup() #启动django <br> <br> #开始运行你的脚本文件 from app01 import models books = models.Book.objects.all() print(books) |
Django终端打印SQL语句#
借助日志文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | LOGGING = { 'version': 1, 'disable_existing_loggers': False, 'handlers': { 'console':{ 'level':'DEBUG', 'class':'logging.StreamHandler', }, }, 'loggers': { 'django.db.backends': { 'handlers': ['console'], 'propagate': True, 'level':'DEBUG', }, }} |


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架