C基础篇 数据类型,变量和常量
变量及赋值#
变量就是可以变化的量,而每个变量都会有一个名字(标识符)。变量占据内存中一定的存储单元。使用变量之前必须先定义变量,要区分变量名和变量值是两个不同的概念。
1 | 变量定义的一般形式为:数据类型 变量名;<br>多个类型相同的变量:数据类型 变量名, 变量名, 变量名...; |
运用实例#
1 2 3 4 5 6 7 8 9 10 11 12 | #include<stdio.h>int main(){ int num; //定义了一个整数变量,变量名字叫num num=99; //给num变量赋值为99 int a,b,c; //同时声明多个变量,然后分别赋值 a=5; b=2; c=0; printf("%d\n",num); //打印整型变量num return 0;} |
注意:在定义中不允许连续赋值,如int a=b=c=5;是不合法的,和python不同
变量的赋值两种方式
1 2 | 先声明再赋值声明的同时赋值 |
基本数据类型#
C语言中,数据类型可分为
1 2 3 4 | 基本数据类型构造数据类型指针类型空类型四大类 |

最常用的整型, 实型与字符型(char,int,float,double):

整型数据是指不带小数的数字

注:
1 2 3 4 | int short int long int是根据编译环境的不同,所取范围不同。而其中short int和long int至少是表中所写范围, 但是int在表中是以16位编译环境写的取值范围。另外 c语言int的取值范围在于他占用的字节数 ,不同的编译器,规定是不一样。ANSI标准定义int是占2个字节,TC是按ANSI标准的,它的int是占2个字节的。但是在VC里,一个int是占4个字节的 |
浮点数据是指带小数的数字
1 | 生活中有很多信息适合使用浮点型数据来表示,比如:人的体重(单位:公斤)、商品价格、圆周率等等 |
因为精度的不同又分为3种

注:C语言中不存在字符串变量,字符串只能存在字符数组中,这个后面会讲。
| 类型 | 描述 |
|---|---|
| char | 通常是一个字节(八位)。这是一个整数类型。 |
| int | 对机器而言,整数的最自然的大小。二进制反码形式存储 |
| float |
单精度浮点值。单精度是这样的格式,1位符号,8位指数,23位小数。
|
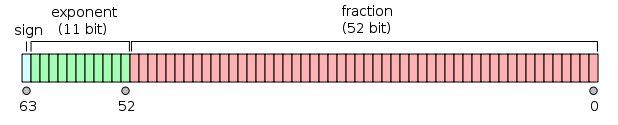
| double |
双精度浮点值。双精度是1位符号,11位指数,52位小数。
|
| void | 表示类型的缺失。 |

C 语言也允许定义各种其他类型的变量,比如枚举、指针、数组、结构、共用体等等,这将会在后续的章节中进行讲解
格式化输出语句#
格式化输出语句,也可以说是占位输出,是将各种类型的数据按照格式化后的类型及指定的位置从计算机上显示。
其格式为:printf("输出格式符",输出项);

当输出语句中包含普通字符时,可以采用一下格式:
1 | printf("普通字符 输出格式符", 输出项); |
运用实例
1 2 3 4 5 6 7 8 9 10 | #include<stdio.h>int main(){ int a=10; float b=7.56; char x = 'c'; printf("整数:%d,小数:%f,字符:%c",a,b,x); }//整数:10,小数:7.560000,字符:c |
注意:格式符的个数要与变量、常量或者表达式的个数一一对应
不可改变的常量#
在程序执行过程中,值不发生改变的量称为常量
C语言的常量可以分为直接常量和符号常量
1 2 3 4 5 | 直接常量也称为字面量,是可以直接拿来使用,无需说明的量,比如整型常量:13、0、-13;实型常量:13.33、-24.4;字符常量:‘a’、‘M’字符串常量:”I love you!” |
在C语言中,可以用一个标识符来表示一个常量,称之为符号常量。符号常量在使用之前必须先定义,其一般形式为
1 2 3 4 5 6 7 8 9 | #define 标识符 常量值 <br>#include <stdio.h>#define POCKETMONEY 10 //定义常量及常量值int main(){ // POCKETMONEY = 12; //小明私自增加零花钱对吗? printf("小明今天又得到%d元零花钱\n", POCKETMONEY); return 0; } |
符号常量不可以被改变
自动类型转换#
数据类型存在自动转换的情况.
自动转换发生在不同数据类型运算时,在编译的时候自动完成。

char类型数据转换为int类型数据遵循ASCII码中的对应值.
注意:
1 2 | 字节小的可以向字节大的自动转换,但字节大的不能向字节小的自动转换char可以转换为int,int可以转换为double,char可以转换为double。但是不可以反向 |
强制类型转换#
强制类型转换是通过定义类型转换运算来实现的。其一般形式为:
1 | (数据类型) (表达式) |
其作用是把表达式的运算结果强制转换成类型说明符所表示的类型
在使用强制转换时应注意以下问题
1 2 3 | 数据类型和表达式都必须加括号, 如把(int)(x/2+y)写成(int)x/2+y则成了把x转换成int型之后再除2再与y相加了转换后不会改变原数据的类型及变量值,只在本次运算中临时性转换强制转换后的运算结果不遵循四舍五入原则 |
C 中的变量定义#
变量定义就是告诉编译器在何处创建变量的存储,以及如何创建变量的存储。变量定义指定一个数据类型,并包含了该类型的一个或多个变量的列表,如下
1 | type variable_list; |
在这里,type 必须是一个有效的 C 数据类型,可以是 char、w_char、int、float、double 或任何用户自定义的对象,variable_list 可以由一个或多个标识符名称组成,多个标识符之间用逗号分隔。下面列出几个有效的声明
1 2 3 4 | int i, j, k;char c, ch;float f, salary;double d; |
行 int i, j, k; 声明并定义了变量 i、j 和 k,这指示编译器创建类型为 int 的名为 i、j、k 的变量。
变量可以在声明的时候被初始化(指定一个初始值)。初始化器由一个等号,后跟一个常量表达式组成,如下
1 | type variable_name = value; |
下面列举几个实例
1 2 3 4 | extern int d = 3, f = 5; // d 和 f 的声明与初始化int d = 3, f = 5; // 定义并初始化 d 和 fbyte z = 22; // 定义并初始化 zchar x = 'x'; // 变量 x 的值为 'x' |
不带初始化的定义:带有静态存储持续时间的变量会被隐式初始化为 NULL(所有字节的值都是 0),其他所有变量的初始值是未定义的
C 中的变量声明#
变量声明向编译器保证变量以指定的类型和名称存在,这样编译器在不需要知道变量完整细节的情况下也能继续进一步的编译。变量声明只在编译时有它的意义,在程序连接时编译器需要实际的变量声明。
变量的声明有两种情况
1 2 3 4 5 | 1、一种是需要建立存储空间的。例如:int a 在声明的时候就已经建立了存储空间。2、另一种是不需要建立存储空间的,通过使用extern关键字声明变量名而不定义它。 例如:extern int a 其中变量 a 可以在别的文件中定义的。除非有extern关键字,否则都是变量的定义extern int i; //声明,不是定义int i; //声明,也是定义 |
C 中的左值(Lvalues)和右值(Rvalues)#
C 中有两种类型的表达式
1 2 | 左值(lvalue):指向内存位置的表达式被称为左值(lvalue)表达式。左值可以出现在赋值号的左边或右边右值(rvalue):术语右值(rvalue)指的是存储在内存中某些地址的数值。右值是不能对其进行赋值的表达式,也就是说,右值可以出现在赋值号的右边,但不能出现在赋值号的左边 |
变量是左值,因此可以出现在赋值号的左边。数值型的字面值是右值,因此不能被赋值,不能出现在赋值号的左边。下面是一个有效的语句
1 | int g = 20; |
但是下面这个就不是一个有效的语句,会生成编译时错误
1 | 10 = 20; |
常量是固定值,在程序执行期间不会改变。这些固定的值,又叫做字面量
常量可以是任何的基本数据类型,比如整数常量、浮点常量、字符常量,或字符串字面值,也有枚举常量。
常量就像是常规的变量,只不过常量的值在定义后不能进行修改
整数常量#
整数常量可以是十进制、八进制或十六进制的常量。前缀指定基数:0x 或 0X 表示十六进制,0 表示八进制,不带前缀则默认表示十进制。
整数常量也可以带一个后缀,后缀是 U 和 L 的组合,U 表示无符号整数(unsigned),L 表示长整数(long)。后缀可以是大写,也可以是小写,U 和 L 的顺序任意。
下面列举几个整数常量的实例:
1 2 3 4 5 | 212 /* 合法的 */215u /* 合法的 */0xFeeL /* 合法的 */078 /* 非法的:8 不是八进制的数字 */032UU /* 非法的:不能重复后缀 */ |
以下是各种类型的整数常量的实例:
1 2 3 4 5 6 7 | 85 /* 十进制 */0213 /* 八进制 */0x4b /* 十六进制 */30 /* 整数 */30u /* 无符号整数 */30l /* 长整数 */30ul /* 无符号长整数 */ |
浮点常量#
浮点常量由整数部分、小数点、小数部分和指数部分组成。您可以使用小数形式或者指数形式来表示浮点常量。
当使用小数形式表示时,必须包含整数部分、小数部分,或同时包含两者。当使用指数形式表示时, 必须包含小数点、指数,或同时包含两者。带符号的指数是用 e 或 E 引入的。
下面列举几个浮点常量的实例:
1 2 3 4 5 | 3.14159 /* 合法的 */314159E-5L /* 合法的 */510E /* 非法的:不完整的指数 */210f /* 非法的:没有小数或指数 */.e55 /* 非法的:缺少整数或分数 */ |
字符常量#
字符常量是括在单引号中,例如,'x' 可以存储在 char 类型的简单变量中。
字符常量可以是一个普通的字符(例如 'x')、一个转义序列(例如 '\t'),或一个通用的字符(例如 '\u02C0')。
在 C 中,有一些特定的字符,当它们前面有反斜杠时,它们就具有特殊的含义,被用来表示如换行符(\n)或制表符(\t)等。下表列出了一些这样的转义序列码:
| 转义序列 | 含义 |
|---|---|
| \\ | \ 字符 |
| \' | ' 字符 |
| \" | " 字符 |
| \? | ? 字符 |
| \a | 警报铃声 |
| \b | 退格键 |
| \f | 换页符 |
| \n | 换行符 |
| \r | 回车 |
| \t | 水平制表符 |
| \v | 垂直制表符 |
| \ooo | 一到三位的八进制数 |
| \xhh . . . | 一个或多个数字的十六进制数 |
实例#
1 2 3 4 5 6 | #include <stdio.h>int main() { printf("Hello\tWorld\n\n"); return 0; }//Hello World |
字符串常量#
字符串字面值或常量是括在双引号 "" 中的。一个字符串包含类似于字符常量的字符:普通的字符、转义序列和通用的字符
您可以使用空格做分隔符,把一个很长的字符串常量进行分行
下面的实例显示了一些字符串常量,下面这三种形式所显示的字符串是相同的
1 2 3 4 5 6 | "hello, dear""hello, \dear""hello, " "d" "ear" |
定义常量#
在 C 中,有两种简单的定义常量的方式
1 2 | 使用 #define 预处理器使用 const 关键字 |
#define 预处理器#
下面是使用 #define 预处理器定义常量的形式
1 | #define identifier value |
实例#
1 2 3 4 5 6 7 8 9 10 11 12 13 | #include <stdio.h>#define LENGTH 10#define WIDTH 5#define NEWLINE '\n'int main(){ int area; area = LENGTH * WIDTH; printf("value of area : %d", area); printf("%c", NEWLINE); return 0; } //value of area : 50 |
const 关键字#
您可以使用 const 前缀声明指定类型的常量,如下
1 | const type variable = value; |
实例#
1 2 3 4 5 6 7 8 9 10 11 12 13 | #include <stdio.h>int main(){ const int LENGTH = 10; const int WIDTH = 5; const char NEWLINE = '\n'; int area; area = LENGTH * WIDTH; printf("value of area : %d", area); printf("%c", NEWLINE); return 0; } //value of area : 50 |
请注意,把常量定义为大写字母形式,是一个很好的编程规范
整数的取值范围以及数值溢出#
关于数据溢出,当类型的运算超出类型的取值范围,便会出现数据溢出。数据溢出得到的结果往往不是我们想要的。下面继续以byte类型为例来进行讨论。
1 2 3 4 5 6 7 8 | byte(5+125)5 原码【0000 0101】 反码 【0000 0101】 补码【0000 0101】125 原码【0111 1101】 反码【0111 1101】 补码【0111 1101】130=5+125 补码【1000 0010】 反码【1000 0001】 原码【1111 1110】5和125的补码相加为【1000 0010】 130超出了非符号位的表示范围,因此符号位被改变了,【1000 0010】对应的原码为【1111 1110】,这是-126对应的原码。因此byte(125+5)的值为-126注:计算机里数据的运算是通过数据对应的补码进行的,将运算后的出的补码转化成对应原码,而原码对应的数就是运算的结果,如此得出的结果与数本身的运算结果是一致的。但如果出现了数据溢出,补码的符号位就会改变,从而不能得出我们想要的结果 |
在C语言中使用中文字符#
待补充
C语言到底使用什么编码#
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 | 一、编码编码是用预先规定的方法将文字、数字或其它对象编成数码。为保证编码的正确性,编码要规范化、标准化,即需有标准的编码格式。我们都知道文本在计算机中是以二进制来进行存储,这就需要把文字通过一定的规则转换成二进制来存储。这种规则就是编码。每个不同的国家,不同的地区都有自己不同的语言文字,这些文字通过不同的编码,转换成二进制信息进行存储。使用什么编码格式编码,就需要使用相同的格式解码。为了便于文件全球化交换与使用,有一些编码规则支持了很多语言的转换规则。通过这种编码规则,就可以支持多种语言。常见的编码格式有ASCII、ANSI、GBK、GB2312、UTF-8、GB2312-80和Unicode等。二、C语言的编码C语言是 70 年代的产物,那个时候只有ASCII,各个国家的字符编码都还未成熟,所以C语言不可能从底层支持 GB2312、GBK、Big5、Shift-JIS等国家编码,也不可能支持 Unicode 字符集。在C语言中字符有两种,一种是窄字符,另一种是宽字符。只有 char 类型的窄字符才使用 ASCII 编码char 类型的窄字符串、宽字符和宽字符串都不使用 ASCII 编码!可以肯定的说,在现代计算机中,窄字符串已经不再使用 ASCII 编码了,因为 ASCII 编码只能显示字母、数字等英文字符,对汉语、日语、韩语等其它地区的字符无能为力。对于窄字符串,C语言并没有规定使用哪一种特定的编码,只要选用的编码能够适应当前的环境即可,所以,窄字符串的编码与操作系统和编译器有关。三、程序的编码源文件使用什么编码 源文件用来保存我们编写的代码,它最终会被存储到本地硬盘,或者远程服务器,这个时候就要尽量压缩文件体积,以节省硬盘空间或者网络流量,而代码中大部分的字符都是 ASCII 编码中的字符,用一个字节足以容纳,所以 UTF-8 编码是一个不错的选择。UTF-8 兼容 ASCII,代码中的大部分字符可以用一个字节保存;另外 UTF-8 基于 Unicode,支持全世界的字符,我们编写的代码可以给全球的程序员使用,真正做到技术无国界。常见的 IDE 或者编辑器使用的编码 绝大多数的编译器,如:Xcode、Sublime、Text、Gedit、Vim等,在创建源文件时一般也默认使用 UTF-8 编码。奇葩 Visual Studio 它默认使用本地编码来创建源文件。 所谓本地编码,就是像 GBK、Big5、Shift-JIS 等这样的国家编码(地区编码);针对不同国家发行的操作系统,默认的本地编码一般不同。简体中文本的 Windows 默认的本地编码是 GBK。 这就导致 Visual Studio在上传github时,出现中文乱码的现象。<br>需要将文件强制转换成utf-8的编码模式。再进行上传。ps :对于使用 Visual Studio 上传github的用户。可以使用本地代码转换器,将GBK->UTF-8,便于在github Desktop中查看(github Desktop 不会转码,中文会出现乱码情况)。不过github网页的代码会自动转码,不会出现乱码。程序编译时的编码1) 微软编译器使用本地编码来保存这些字符。不同地区的 Windows 版本默认的本地编码不一样,所以,同样的窄字符串在不同的 Windows 版本下使用的编码也不一样。对于简体中文版的 Windows,使用的是 GBK 编码。2) GCC、LLVM/Clang 编译器使用和源文件相同的编码来保存这些字符:如果源文件使用的是 UTF-8 编码,那么这些字符也使用 UTF-8 编码;如果源文件使用的是 GBK 编码,那么这些字符也使用 GBK 编码。<br>你看,对于代码中需要被处理的窄字符串,不同的编译器差别还是挺大的。不过可以肯定的是,这些字符始终都使用窄字符(多字节字符)编码。对于 char 类型的窄字符串,微软编译器使用本地编码,GCC、LLVM/Clang 使用和源文件编码相同的编码。四、编码字符集和运行字符集站在专业的角度讲,源文件使用的字符集被称为编码字符集,也就是写代码的时候使用的字符集;程序中的字符或者字符串使用的字符集被称为运行字符集,也就是程序运行后使用的字符集。 源文件需要保存到硬盘,或者在网络上传输,使用的编码要尽量节省存储空间,同时要方便跨国交流,所以一般使用 UTF-8,这就是选择编码字符集的标准。程序中的字符或者字符串,在程序运行后必须被载入到内存,才能进行后续的处理,对于这些字符来说,要尽量选用能够提高处理速度的编码,例如 UTF-16 和 UTF-32 编码就能够快速定位(查找)字符。ps :编码字符集是站在存储和传输的角度,运行字符集是站在处理或者操作的角度,所以它们并不一定相同。 |
表达式(Expression)和语句(Statement)#
1 2 3 4 5 6 7 | 其实前面我们已经多次提到了「表达式」和「语句」这两个概念,相信读者在耳濡目染之中也已经略知一二了,本节我们不妨再重点介绍一下。表达式(Expression)和语句(Statement)的概念在C语言中并没有明确的定义:表达式可以看做一个计算的公式,往往由数据、变量、运算符等组成,例如3*4+5、a=c=d等,表达式的结果必定是一个值;语句的范围更加广泛,不一定是计算,不一定有值,可以是某个操作、某个函数、选择结构、循环等。赶紧划重点:表达式必须有一个执行结果,这个结果必须是一个值,例如3*4+5的结果 17,a=c=d=10的结果是 10,printf("hello")的结果是 5(printf 的返回值是成功打印的字符的个数)。以分号;结束的往往称为语句,而不是表达式,例如3*4+5;、a=c=d;等。 |
C语言自增(++)和自减(--)#
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 | 一个整数类型的变量自身加 1 可以这样写: a = a + 1;或者 a += 1;不过,C语言还支持另外一种更加简洁的写法,就是: a++;或者 ++a;这种写法叫做自加或自增,意思很明确,就是每次自身加 1。相应的,也有a--和--a,它们叫做自减,表示自身减 1。++和--分别称为自增运算符和自减运算符,它们在循环结构(后续章节会讲解)中使用很频繁。自增和自减的示例: #include <stdio.h>int main(){ int a = 10, b = 20; printf("a=%d, b=%d\n", a, b); ++a; --b; printf("a=%d, b=%d\n", a, b); a++; b--; printf("a=%d, b=%d\n", a, b); return 0;}运行结果:a=10, b=20a=11, b=19a=12, b=18自增自减完成后,会用新值替换旧值,将新值保存在当前变量中。自增自减的结果必须得有变量来接收,所以自增自减只能针对变量,不能针对数字,例如10++就是错误的。需要重点说明的是,++ 在变量前面和后面是有区别的: ++ 在前面叫做前自增(例如 ++a)。前自增先进行自增运算,再进行其他操作。++ 在后面叫做后自增(例如 a++)。后自增先进行其他操作,再进行自增运算。自减(--)也一样,有前自减和后自减之分。下面的例子能更好地说明前自增(前自减)和后自增(后自减)的区别: #include <stdio.h>int main(){ int a = 10, b = 20, c = 30, d = 40; int a1 = ++a, b1 = b++, c1 = --c, d1 = d--; printf("a=%d, a1=%d\n", a, a1); printf("b=%d, b1=%d\n", b, b1); printf("c=%d, c1=%d\n", c, c1); printf("d=%d, d1=%d\n", d, d1); return 0;}输出结果:a=11, a1=11b=21, b1=20c=29, c1=29d=39, d1=40a、b、c、d 的输出结果相信大家没有疑问,下面重点分析a1、b1、c1、d1:1) 对于a1=++a,先执行 ++a,结果为 11,再将 11 赋值给 a1,所以 a1 的最终值为11。而 a 经过自增,最终的值也为 11。2) 对于b1=b++,b 的值并不会立马加 1,而是先把 b 原来的值交给 b1,然后再加 1。b 原来的值为 20,所以 b1 的值也就为 20。而 b 经过自增,最终值为 21。3) 对于c1=--c,先执行 --c,结果为 29,再将 29 赋值给c1,所以 c1 的最终值为 29。而 c 经过自减,最终的值也为 29。4) 对于d1=d--,d 的值并不会立马减 1,而是先把 d 原来的值交给 d1,然后再减 1。d 原来的值为 40,所以 d1 的值也就为 40。而 d 经过自减,最终值为 39。可以看出:a1=++a;会先进行自增操作,再进行赋值操作;而b1=b++;会先进行赋值操作,再进行自增操作。c1=--c;和d1=d--;也是如此。为了强化记忆,我们再来看一个自增自减的综合示例: #include <stdio.h>int main(){ int a = 12, b = 1; int c = a - (b--); // ① int d = (++a) - (--b); // ② printf("c=%d, d=%d\n", c, d); return 0;}输出结果:c=11, d=14我们来分析一下:1) 执行语句①时,因为是后自减,会先进行a-b运算,结果是 11,然后 b 再自减,就变成了 0;最后再将a-b的结果(也就是11)交给 c,所以 c 的值是 11。2) 执行语句②之前,b 的值已经变成 0。对于d=(++a)-(--b),a 会先自增,变成 13,然后 b 再自减,变成 -1,最后再计算13-(-1),结果是 14,交给 d,所以 d 最终是 14。 |
变量的定义位置以及初始值#
在c语言中变量的定义必须放在所有执行语句的前面,而c++中则是任意的
顺着这个思路想了一下,为什么C语言的全局变量(global)就算不赋值会被自动初始化位默认值,但是局部变量(local)不会呢? 学习了一下C语言的内存布局结构,然后自己验证了一下然后明白了这个原因。
首先我们得知道C语言的内存布局结构
全局变量是存放在data段内存的。data段分为uninitialized data(bss)段和initalized data,未初始化的变量是放在bss段的,这部分内存存放的变量是会被自动初始化的(这是C语言的特性)局部变量是存放在stack段的。这部分内存是被runtime时期动态分配的。(其实局部变量在代码编译之后就是一个地址,接下来会演示出来)
一般变量看不出什么区别,对于静态变量就很明显了,如:
int func(){static int a = 10; //初始化static int b;b = 10; //赋值a++;b++;printf("%d\n", a); //第一次调用函数func,a 的值为 11,第二次调用时为 12,……printf("%d\n", b); //第一次调用函数func,b 的值为 11,第二次调用时为 11,……}从上例可以看出,静态变量只初始化一次,所以 a 的值会随调用的次数递增;而 b 由于重新赋值,所以他的值始终是 11。
运算符的优先级和结合性#
C语言的运算符和结合性主要还是要记住一个表,不明白的时候我们就翻看一下。C语言的运算符众多,具有不同的优先级和结合性,将它们全部列了出来,方便大家对比和记忆:
注:同一优先级的运算符,运算次序由结合方向所决定。上面的表无需死记硬背,很多运算符的规则和数学中是相同的,用得多,看得多自然就记得了。如果你是在记不住,可以使用( )。
从一个例子入手讲解
请看下面的代码:
#include<stdio.h>intmain(){int a =16, b =4, c =2;int d = a + b * c;int e = a / b * c;printf("d=%d, e=%d\n", d, e);return0;}运行结果:d=24, e=8
1) 对于表达式a + b * c,如果按照数学规则推导,应该先计算乘法,再计算加法;b * c的结果为 8,a + 8的结果为 24,所以 d 最终的值也是 24。从运行结果可以看出,我们的推论得到了证实,C语言也是先计算乘法再计算加法,和数学中的规则一样。先计算乘法后计算加法,说明乘法运算符的优先级比加法运算符的优先级高。所谓优先级,就是当多个运算符出现在同一个表达式中时,先执行哪个运算符。C语言有几十种运算符,被分成十几个级别,有的运算符优先级不同,有的运算符优先级相同,C语言运算符很多,大家可以查看上面的表格,有C语言书籍的也可以查看后面的附录,一般也是有的。一下子记住所有运算符的优先级并不容易,还好C语言中大部分运算符的优先级和数学中是一样的,大家在以后的编程过程中也会逐渐熟悉起来。如果实在搞不清,可以加括号,就像下面这样:
int d = a + (b * c);括号的优先级是最高的,括号中的表达式会优先执行,这样各个运算符的执行顺序就一目了然了。2) 对于表达式a / b * c,除法和乘法的优先级是相同的,这个时候到底该先执行哪一个呢?按照数学规则应该从左到右,先计算除法,在计算乘法;a / b的结果是 4,4 * c的结果是 8,所以 e 最终的值也是 8。这个推论也从运行结果中得到了证实,C语言的规则和数学的规则是一样的。当乘法和除法的优先级相同时,编译器很明显知道先执行除法,再执行乘法,这是根据运算符的结合性来判定的。所谓结合性,就是当一个表达式中出现多个优先级相同的运算符时,先执行哪个运算符:先执行左边的叫左结合性,先执行右边的叫右结合性。/和*的优先级相同,又都具有左结合性,所以先执行左边的除法,再执行右边的乘法。3) 像 +、-、*、/ 这样的运算符,它的两边都有要计算的数据,每份这样的数据都称作一个操作数,一个运算符需要 n 个操作数就称为 n 目运算符。例如:
+、-、*、/、= 是双目运算符;++、-- 是单目运算符;? : 是三目运算符(这是C语言里唯一的一个三目元算符,这个就必须强行记住了呀)。一些容易出错的优先级问题
上表中,优先级同为1 的几种运算符如果同时出现,那怎么确定表达式的优先级呢?这是很多初学者迷糊的地方。下表就整理了这些容易出错的情况:
这些容易出错的情况,好好在编译器上调试调试,这样印象会深一些。一定要多调试,光靠看代码,水平是很难提上来的。调试代码才是最长水平的。
当一个表达式中出现多个运算符时,C语言会先比较各个运算符的优先级,按照优先级从高到低的顺序依次执行;当遇到优先级相同的运算符时,再根据结合性决定先执行哪个运算符:如果是左结合性就先执行左边的运算符,如果是右结合性就先执行右边的运算符。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 基于Microsoft.Extensions.AI核心库实现RAG应用
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架