
Python 爬取异步加载的数据
在我们的工作中,可能会遇到这样的情况:我们需要爬取的数据是通过ajax异步加载的,这样的话通过requests得到的只是一个静态页面,而我们需要的是ajax动态加载的数据!
那我们应该怎么办呢???
思路是这样的:F12,查看网络,筛选XHR,点击下拉菜单,等待异步加载的文件 ,得到异步加载url,在通过这个url请求得到我们想要的数据。
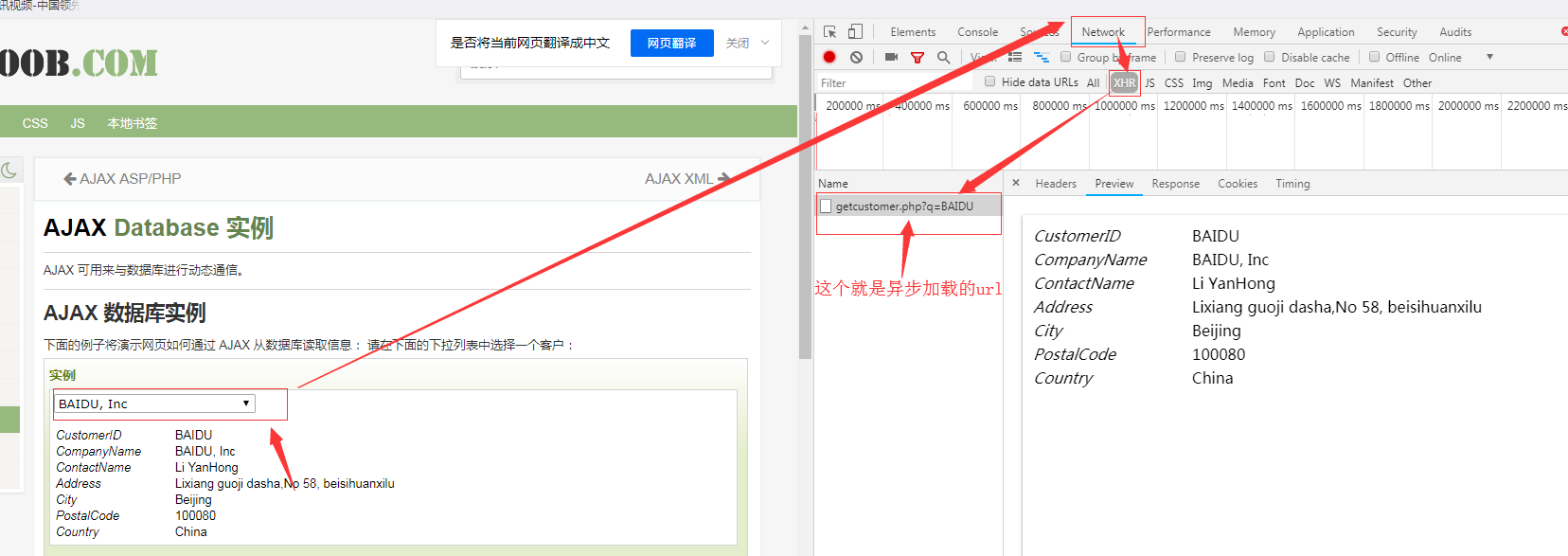
以下为实战代码,可以供大家参考。
import requests from lxml import etree # 浏览器伪装 ua = 'Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko' header = {"User-Agent": ua} # GET请求 url = 'http://www.runoob.com/ajax/ajax-database.html' r = requests.get(url, headers=header) r.encoding = 'urf-8' text = r.text # xpath提取信息 element = etree.HTML(text) options = element.xpath('/html/body/div[3]/div/div[2]/div/div[3]/div/div[1]/div/form/select/option/@value') print(options) # 提取异步加载的信息 for option in options: url = 'http://www.runoob.com/try/ajax/getcustomer.php?q='+option.strip() r = requests.get(url, headers=header) r.encoding = 'GBK' text = r.text # xpath提取信息 element = etree.HTML(text) em = element.xpath('/html/body/table/tr[1]/td[1]/em/text()') td = element.xpath('/html/body/table/tr[1]/td[2]/text()') for e, t in zip(em, td): print(e, ' | ', t) print('-' * 55, options.index(option) + 1)
希望能够帮到有需要的朋友。(如果没有安装requests和lxml 模块的话,需要在命令行pip install request、pip install lxml,不然会报错)

