
Linux收包之数据从网卡到协议栈是如何流转的
一、环境说明
内核版本:Linux 3.10
内核源码地址:https://elixir.bootlin.com/linux/v3.10/source (包含各个版本内核源码,且王页可全局搜索函数)
网卡:Intel的igb网卡
网卡驱动源码目录:drivers/net/ethernet/intel/igb/
二、Linux收包依赖组件的初始化
Linux驱动,内核协议栈等等模块在具备接收网卡数据包之前,要做很多的准备工作才行。
比如要提前创建好ksoftirqd内核线程,要注册好各个协议对应的处理函数,网络设备子系统要提前初始化好,网卡要启动好等等。
1.创建软中断ksoftirqd内核进程
每个CPU负责执行一个ksoftirq内核进程,比如ksoftirqd/0运行在CPU 0上,这些内核进程执行不同软中断注册的中断处理函数。
执行硬中断的处理函数的 CPU 核心,也会执行该硬中断后续的软中断处理函数。
ksoftirqd 内核进程通过 spawn_ksoftirqd 函数初始化:

// file: kernel/softirq.c static struct smp_hotplug_thread softirq_threads = { .store = &ksoftirqd, .thread_should_run = ksoftirqd_should_run, .thread_fn = run_ksoftirqd, .thread_comm = "ksoftirqd/%u", }; static __init int spawn_ksoftirqd(void) { register_cpu_notifier(&cpu_nfb); BUG_ON(smpboot_register_percpu_thread(&softirq_threads)); return 0; } early_initcall(spawn_ksoftirqd);
当ksoftirqd被创建出来以后,它就会进入自己的线程循环函数ksoftirqd_should_run和run_ksoftirqd了。不停地判断有没有软中断需要被处理。
2.网络子系统初始化
网络子系统通过net_dev_init函数进行初始化:
// file: net/core/dev.c static int __init net_dev_init(void) { ...... // 为每个CPU都申请一个softnet_data数据结构 for_each_possible_cpu(i) { struct softnet_data *sd = &per_cpu(softnet_data, i); memset(sd, 0, sizeof(*sd)); skb_queue_head_init(&sd->input_pkt_queue); skb_queue_head_init(&sd->process_queue); sd->completion_queue = NULL; INIT_LIST_HEAD(&sd->poll_list); sd->output_queue = NULL; sd->output_queue_tailp = &sd->output_queue; #ifdef CONFIG_RPS sd->csd.func = rps_trigger_softirq; sd->csd.info = sd; sd->csd.flags = 0; sd->cpu = i; #endif sd->backlog.poll = process_backlog; sd->backlog.weight = weight_p; sd->backlog.gro_list = NULL; sd->backlog.gro_count = 0; } ...... // 注册软中断处理函数,用于处理接收和发送的数据包 open_softirq(NET_TX_SOFTIRQ, net_tx_action); open_softirq(NET_RX_SOFTIRQ, net_rx_action); ...... } subsys_initcall(net_dev_init);
内核通过open_softirq函数来注册软中断处理函数:
// file: kernel/softirq.c void open_softirq(int nr, void (*action)(struct softirq_action *)) { softirq_vec[nr].action = action; }
相关联的softnet_data和napi_struct结构体:
struct softnet_data { struct Qdisc *output_queue; struct Qdisc **output_queue_tailp; struct list_head poll_list; //设备轮询列表 struct sk_buff *completion_queue; struct sk_buff_head process_queue; /* 统计数据 */ unsigned int processed; unsigned int time_squeeze; unsigned int cpu_collision; unsigned int received_rps; unsigned dropped; //被丢弃的包的数量 struct sk_buff_head input_pkt_queue; //收包队列 struct napi_struct backlog; //处理积压队列的napi结构 }; struct napi_struct { struct list_head poll_list; //链表指针,用于挂在softnet_data上 unsigned long state; //此NAPI设备当前的状态 int weight; //一个权重值,每次调度NAPI可处理数据包个数的限制 int (*poll)(structnapi_struct *, int); //poll函数,用于实际来处理数据包 …… };
3.协议栈注册
linux通过inet_init将TCP、UDP和ICMP的接收函数注册到了inet_protos数组中,将IP的接收函数注册到了ptype_base哈希表中。
// file: net/ipv4/af_inet.c static int __init inet_init(void) { ...... // 添加基础网络协议到inet_protos数组中 if (inet_add_protocol(&icmp_protocol, IPPROTO_ICMP) < 0) pr_crit("%s: Cannot add ICMP protocol\n", __func__); if (inet_add_protocol(&udp_protocol, IPPROTO_UDP) < 0) pr_crit("%s: Cannot add UDP protocol\n", __func__); if (inet_add_protocol(&tcp_protocol, IPPROTO_TCP) < 0) pr_crit("%s: Cannot add TCP protocol\n", __func__); ...... // 将IP的接收函数ip_rcv注册到ptype_base列表里 dev_add_pack(&ip_packet_type); ...... } fs_initcall(inet_init);
TCP、UDP、ICMP和IP协议的处理函数:
//file: net/ipv4/af_inet.c static const struct net_protocol tcp_protocol = { .early_demux = tcp_v4_early_demux, .handler = tcp_v4_rcv, .err_handler = tcp_v4_err, .no_policy = 1, .netns_ok = 1, } static const struct net_protocol udp_protocol = { .handler = udp_rcv, .err_handler = udp_err, .no_policy = 1, .netns_ok = 1, }; static const struct net_protocol icmp_protocol = { .handler = icmp_rcv, .err_handler = icmp_err, .no_policy = 1, .netns_ok = 1, }; static struct packet_type ip_packet_type __read_mostly = { .type = cpu_to_be16(ETH_P_IP), .func = ip_rcv, };
4.网卡驱动程序初始化以及网卡启动
详细说明见:网卡驱动程序初始化文档
三、驱动程序接收并建立数据包
1.概述
数据包在本层主要处理流程有:
网卡收到数据包,DMA方式写入Ring Buffer,发出硬中断;
内核收到硬中断,NAPI加入本CPU的轮询列表,发出软中断;
内核收到软中断,轮询NAPI并执行poll函数从Ring Buffer取数据;
GRO操作(默认开启),合并多个数据包为一个数据包,如果RPS关闭,则把数据包递交到协议栈;
RPS操作(默认关闭),如果开启,使数据包通过别的(也可能是当前的)CPU递交到协议栈;
流程图:
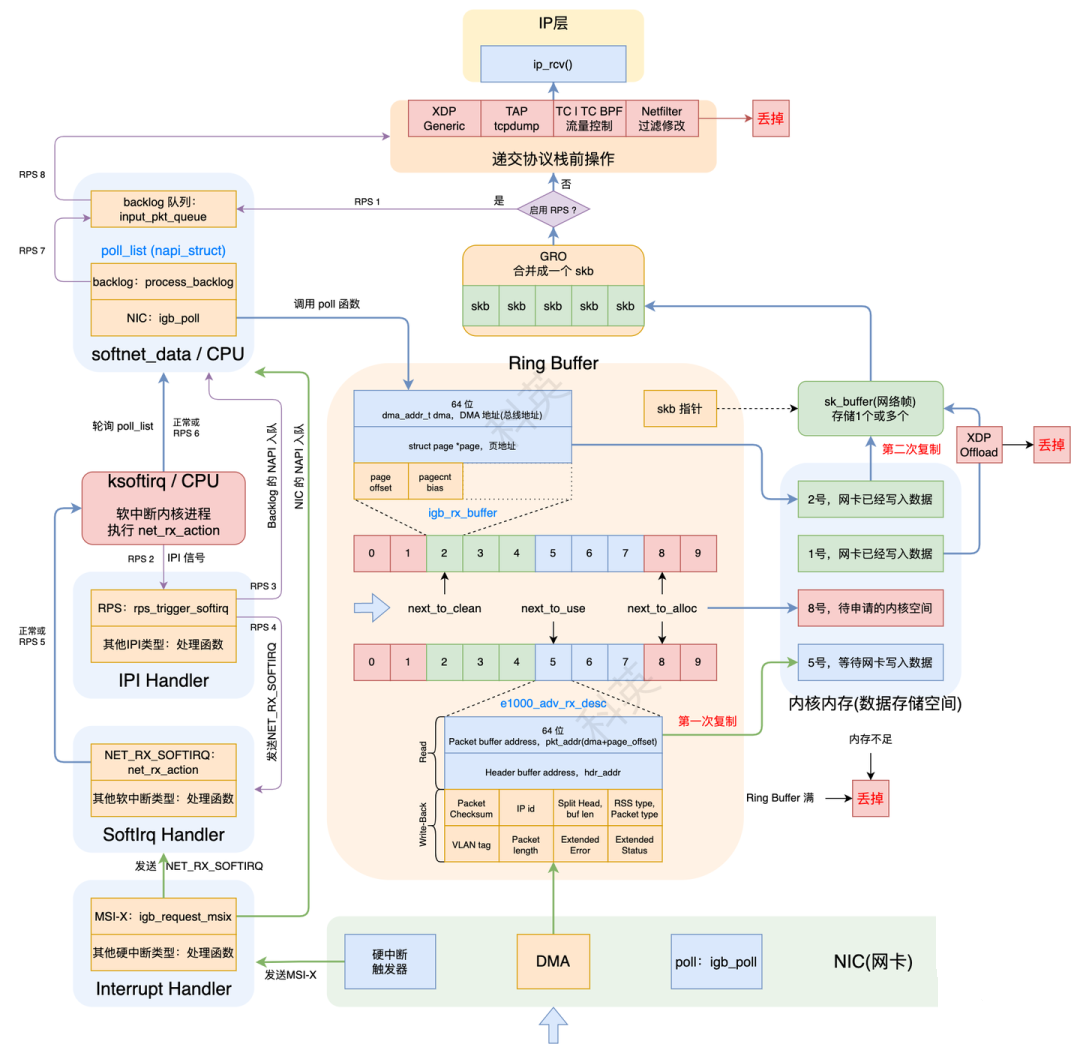
调用链:
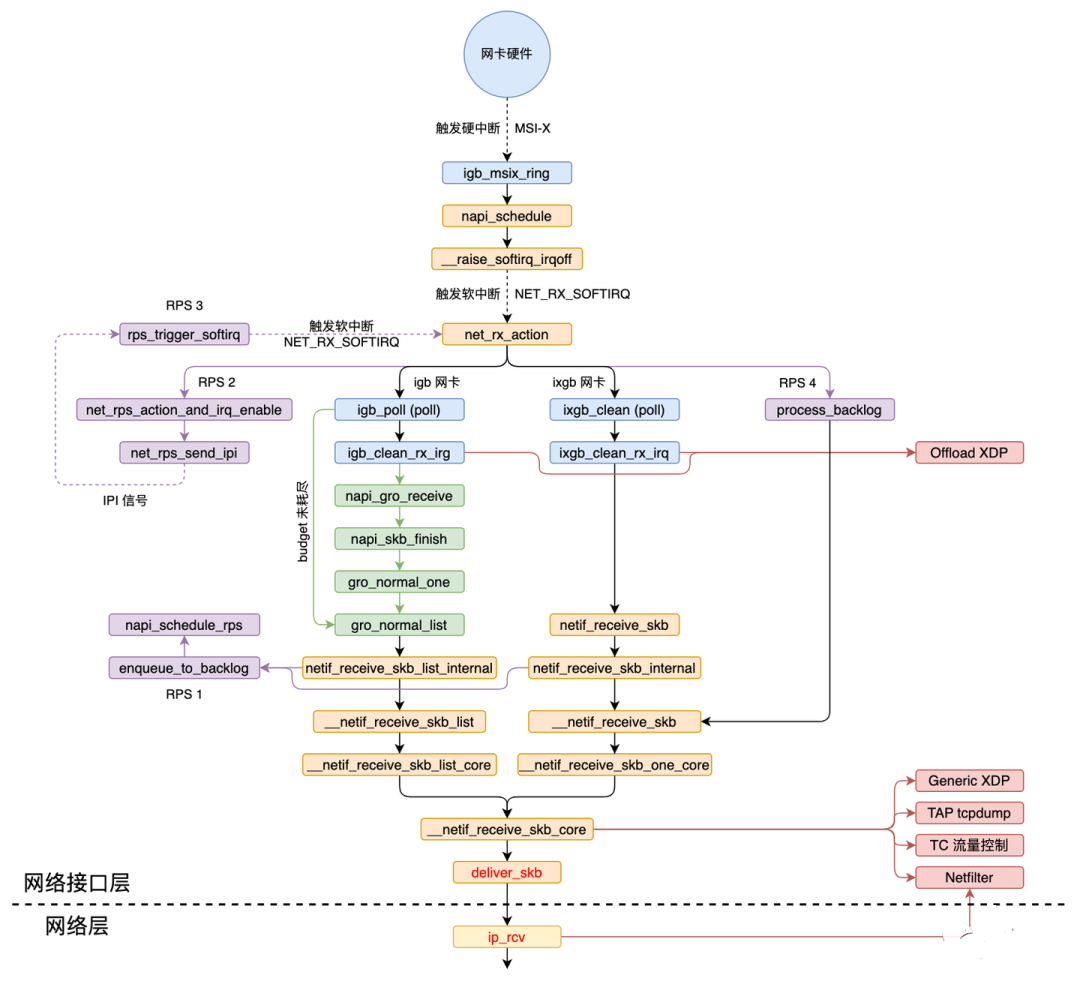
2.网卡收到数据包
网卡收到数据包后,通过DMA写入Ring Buffer(rx_ring)内rx_buffer_info数组的下一个可用元素(igb_rx_buffer)的dma指向的内核内存。当DMA操作完成以后,网卡会像CPU发起一个硬中断,通知CPU有数据到达。
一个网络帧可能占用多个igb_rx_buffer。
3.硬中断处理
假设启动时硬中断类型选择的是MSI-X,那么硬中断注册的函数就igb_msix_ring。
// file: drivers/net/ethernet/intel/igb/igb_main.c static irqreturn_t igb_msix_ring(int irq, void *data) { struct igb_q_vector *q_vector = data; // 更新特定的硬件中的寄存器,记录一下硬件中断频率 igb_write_itr(q_vector); // 调度NAPI napi_schedule(&q_vector->napi); return IRQ_HANDLED; } // file: include/linux/netdevice.h static inline void napi_schedule(struct napi_struct *n) { if (napi_schedule_prep(n)) __napi_schedule(n); } // file: net/core/dev.c void __napi_schedule(struct napi_struct *n) { ...... ____napi_schedule(&__get_cpu_var(softnet_data), n); ...... } // file: net/core/dev.c static inline void ____napi_schedule(struct softnet_data *sd, struct napi_struct *napi) { list_add_tail(&napi->poll_list, &sd->poll_list); __raise_softirq_irqoff(NET_RX_SOFTIRQ); }
硬中断主要做了两件事:
把napi_struct结构体的poll_list添加到当前CPU所关联的softnet_data结构体的poll_list链表尾部;
调用__raise_softirq_irqoff函数触发NET_RX_SOFTIRQ软中断,从而内核执行网络子系统初始化时注册的net_rx_action软中断处理函数。
// file: kernel/softirq.c void __raise_softirq_irqoff(unsigned int nr) { trace_softirq_raise(nr); or_softirq_pending(1UL << nr); } // include/linux/interrupt.h #define or_softirq_pending(x) (local_softirq_pending() |= (x))
4.软中断处理
处理硬中断的CPU同样也会执行该硬中断触发的软中断注册的处理函数。
ksoftirqd内核进程处理软中断是在run_ksoftirqd函数中:
// file: source/kernel/softirq.c static void run_ksoftirqd(unsigned int cpu) { local_irq_disable(); if (local_softirq_pending()) { __do_softirq(); rcu_note_context_switch(cpu); local_irq_enable(); cond_resched(); return; } local_irq_enable(); }
在__do_softirq中,判断根据当前CPU的软中断类型,调用其注册的action方法。
// file: kernel/softirq.c asmlinkage void __do_softirq(void) { ...... h = softirq_vec; //软中断静态变量数组 do { if (pending & 1) { unsigned int vec_nr = h - softirq_vec; int prev_count = preempt_count(); kstat_incr_softirqs_this_cpu(vec_nr); trace_softirq_entry(vec_nr); h->action(h); trace_softirq_exit(vec_nr); ...... } h++; pending >>= 1; } while (pending); ...... }
在网络子系统初始化中,为NET_RX_SOFTIRQ注册了处理函数net_rx_action。所以net_rx_action函数就会被执行到了。
net_rx_action的核心逻辑:
获取到当前CPU变量softnet_data,对其poll_list进行遍历,然后执行网卡驱动注册到的poll函数。
// file: net/core/dev.c static void net_rx_action(struct softirq_action *h) { // 获取到当前CPU变量softnet_data struct softnet_data *sd = &__get_cpu_var(softnet_data); // time_limit和budget是用来控制net_rx_action函数主动退出的,目的是保证网络包的接收不霸占CPU不放 unsigned long time_limit = jiffies + 2; int budget = netdev_budget; void *have; local_irq_disable(); //禁用中断 // 对其poll_list进行遍历 while (!list_empty(&sd->poll_list)) { struct napi_struct *n; int work, weight; local_irq_enable(); //启用中断 n = list_first_entry(&sd->poll_list, struct napi_struct, poll_list); //获取队列中的一个NAPI结构 have = netpoll_poll_lock(n); //加锁 weight = n->weight; //获取单次读取最大报文个数 work = 0; if (test_bit(NAPI_STATE_SCHED, &n->state)) { work = n->poll(n, weight); //执行网卡驱动注册到的poll函数(eg:igb驱动的igb_poll函数),返回处理后的压力值 trace_napi_poll(n); } WARN_ON_ONCE(work > weight); //是否超过结构的压力 budget -= work; //剩余压力值 local_irq_disable(); //禁用中断 if (unlikely(work == weight)) { //处理的压力已经达到结构的压力 if (unlikely(napi_disable_pending(n))) { //将NAPI结构设置为关闭状态 local_irq_enable(); napi_complete(n); //NAPI结构从队列中脱链 local_irq_disable(); } else { ...... list_move_tail(&n->poll_list, &sd->poll_list); //将NAPI结构链入队列尾部 } } netpoll_poll_unlock(have); //解锁 } ...... }
igb驱动程序对应的poll函数为igb_poll,其核心逻辑:
(1)如果内核支持DCA(Direct Cache Access),CPU缓存命中率将会提升;
(2)调用igb_clean_rx_irq循环处理数据包,直到处理完毕或者budget耗尽;
(3)检查clean_complete判断是否所有的工作已经完成?如果是,返回剩下的budget值;否则调用napi_complete_done关闭NAPI,然后通过igb_ring_irq_enable重新打开硬中断,以保证下次中断会重新打开NAPI。
// file: drivers/net/ethernet/intel/igb/igb_main.c static int igb_poll(struct napi_struct *napi, int budget) { struct igb_q_vector *q_vector = container_of(napi, struct igb_q_vector, napi); bool clean_complete = true; #ifdef CONFIG_IGB_DCA if (q_vector->adapter->flags & IGB_FLAG_DCA_ENABLED) igb_update_dca(q_vector); #endif ...... if (q_vector->rx.ring) clean_complete &= igb_clean_rx_irq(q_vector, budget); //处理数据包 /* If all work not completed, return budget and keep polling */ if (!clean_complete) return budget; /* If not enough Rx work done, exit the polling mode */ napi_complete(napi); igb_ring_irq_enable(q_vector); return 0; }
igb_clean_rx_irq处理数据包的核心逻辑:
// file: drivers/net/ethernet/intel/igb/igb_main.c static bool igb_clean_rx_irq(struct igb_q_vector *q_vector, const int budget) { struct igb_ring *rx_ring = q_vector->rx.ring; struct sk_buff *skb = rx_ring->skb; unsigned int total_bytes = 0, total_packets = 0; // ring->count就是desc num,cleaned_count就是hw没有使用、需要clean的desc数目 // next_to_use的use是指没有填充过数据包即将使用的desc // next_to_clean的clean是指已经填充过数据包,并且已经将数据送往协议栈后,需要处理的desc u16 cleaned_count = igb_desc_unused(rx_ring); do { union e1000_adv_rx_desc *rx_desc; // 1.如果需要clean的desc超过了阈值,那么先clean一下,返还一些buffer给hw if (cleaned_count >= IGB_RX_BUFFER_WRITE) { igb_alloc_rx_buffers(rx_ring, cleaned_count); cleaned_count = 0; } // 2.从Ring Buffer中取出下一个可读位置(next_to_clean)的rx_desc,检查它状态是否正常 rx_desc = IGB_RX_DESC(rx_ring, rx_ring->next_to_clean); if (!igb_test_staterr(rx_desc, E1000_RXD_STAT_DD)) break; /* This memory barrier is needed to keep us from reading * any other fields out of the rx_desc until we know the * RXD_STAT_DD bit is set */ rmb(); // 3.从RX中取buffer,保存到一个skb_buff中 skb = igb_fetch_rx_buffer(rx_ring, rx_desc, skb); /* exit if we failed to retrieve a buffer */ if (!skb) break; cleaned_count++; //每用完一个desc,要cleaned_count++。 // 4.判断这个buffer是不是一个包的最后一个buffer?如果是,继续处理;如果不是,继续从buffer列表中拿出下一个buffer,加到skb。当数据帧的大小比一个buffer大的时候,会出现这种情况。 if (igb_is_non_eop(rx_ring, rx_desc)) continue; // 5.检查数据的layout和header信息是正确的 if (igb_cleanup_headers(rx_ring, rx_desc, skb)) { skb = NULL; continue; } // 6.把skb的长度累计到total_bytes,用于统计数据 total_bytes += skb->len; // 7.设置skb的hash,checksum,timestamp,VLAN id,protocol 字段。这些信息是硬件提供的。 // 如果硬件报告checksum error,csum_error统计就会增加。如果checksum通过了,数据是UDP或者TCP数据,skb就会被标记成CHECKSUM_UNNECESSARY igb_process_skb_fields(rx_ring, rx_desc, skb); // 8.GRO,合并数据包,将构建好的skb送入协议栈 napi_gro_receive(&q_vector->napi, skb); /* reset skb pointer */ skb = NULL; // 更新处理过的包的统计信息 total_packets++; } while (likely(total_packets < budget)); //循环直至处理的包数量达到 budget /* place incomplete frames back on ring for completion */ rx_ring->skb = skb; // 更新统计信息 u64_stats_update_begin(&rx_ring->rx_syncp); rx_ring->rx_stats.packets += total_packets; rx_ring->rx_stats.bytes += total_bytes; u64_stats_update_end(&rx_ring->rx_syncp); q_vector->rx.total_packets += total_packets; q_vector->rx.total_bytes += total_bytes; if (cleaned_count) igb_alloc_rx_buffers(rx_ring, cleaned_count); return (total_packets < budget); }
5.GRO
GRO(Generic Receive Offloading)是LGO的一种软件实现,从而能让所有NIC都支持这个功能。
通过合并(足够类似)的包来减少传送给网络协议栈的包数,有助于减少CPU的使用量。
GRO使协议层只需处理一个header,而将包含大量数据的整个大包送到用户程序。
napi_gro_receive就是实现GRO机制的函数:
在dev_gro_receive函数中,具体地执行多个数据包合并操作;当合并完成后会调用napi_skb_finish函数。
// file: net/core/dev.c gro_result_t napi_gro_receive(struct napi_struct *napi, struct sk_buff *skb) { skb_gro_reset_offset(skb); return napi_skb_finish(dev_gro_receive(napi, skb), skb); } static gro_result_t napi_skb_finish(gro_result_t ret, struct sk_buff *skb) { switch (ret) { case GRO_NORMAL: if (netif_receive_skb(skb)) ret = GRO_DROP; break; ...... }
四、查找数据包类型且调用其处理函数
netif_receive_skb代表的是设备驱动程序和L3协议处理例程间的边界,它有三个主要任务:
把帧的副本传给每个协议分流器(如果正在运行的话);
把帧的副本传给skb->protocol所关联的L3协议处理函数;
负责此层必须处理的一些功能,例如桥接;
// file: net/core/dev.c int netif_receive_skb(struct sk_buff *skb) { ...... //RPS处理逻辑 return __netif_receive_skb(skb); } static int __netif_receive_skb(struct sk_buff *skb) { ...... ret = __netif_receive_skb_core(skb, false); return ret; }
最终通过__netif_receive_skb_core函数调用deliver_skb将skb交到网络协议栈继续处理。
static int __netif_receive_skb_core(struct sk_buff *skb, bool pfmemalloc) { ...... orig_dev = skb->dev; //数据包绑定主设备,返回原来的接收设备指针 skb_reset_network_header(skb); //数据包链路层头部指针指向数据块开始地址 if (!skb_transport_header_was_set(skb)) skb_reset_transport_header(skb); //数据包传输层头部指针指向数据块开始地址 skb_reset_mac_len(skb); ...... list_for_each_entry_rcu(ptype, &ptype_all, list) { //在队列中查找设备相同的结构(tcpdump就是从这个入口获取包的) if (!ptype->dev || ptype->dev == skb->dev) { if (pt_prev) //找到了数据包类型结构 ret = deliver_skb(skb, pt_prev, orig_dev); //传递数据包 pt_prev = ptype; //记录找到的数据包类型结构 } } ...... //与数据包分类器/网桥相关 type = skb->protocol; //取得数据包的协议类型 list_for_each_entry_rcu(ptype, &ptype_base[ntohs(type) & PTYPE_HASH_MASK], list) { //在队列数组中查找设备相同的数据包类型结构 if (ptype->type == type && //对比协议类型和设备 (ptype->dev == null_or_dev || ptype->dev == skb->dev || ptype->dev == orig_dev)) { //如果没有指定设备或者指定了设备并且相同 if (pt_prev) /找到了数据包类型结构 ret = deliver_skb(skb, pt_prev, orig_dev); //传递数据包 pt_prev = ptype; //记录找到的数据包类型结构 } } if (pt_prev) { //如果找到了数据包类型结构 if (unlikely(skb_orphan_frags(skb, GFP_ATOMIC))) goto drop; else ret = pt_prev->func(skb, skb->dev, pt_prev, orig_dev); //调用它的处理函数 } else { drop: atomic_long_inc(&skb->dev->rx_dropped); kfree_skb(skb); ret = NET_RX_DROP; } ...... } static inline int deliver_skb(struct sk_buff *skb, struct packet_type *pt_prev, struct net_device *orig_dev) { ...... return pt_prev->func(skb, skb->dev, pt_prev, orig_dev); //调用协议的处理函数(对于ip包来讲,就会进入到ip_rcv) }
至此,数据包被送到了网络协议栈中。下一步就是L3层协议处理函数进行处理。


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 25岁的心里话
· 闲置电脑爆改个人服务器(超详细) #公网映射 #Vmware虚拟网络编辑器
· 零经验选手,Compose 一天开发一款小游戏!
· 因为Apifox不支持离线,我果断选择了Apipost!
· 通过 API 将Deepseek响应流式内容输出到前端