
(二)序列构成的数组
1、序列类型包括两类,容器序列和扁平序列
(1)容器序列:list、tuple 和 collections.deque 这些序列能存放不同类型的数据
(2)扁平序列:str、bytes、bytearray、memoryview 和 array.array,这类序列只能容纳一种类型。
2、也可分为可变类型和不可变类型
(1)可变序列:list、bytearray、array.array、collections.deque 和 memoryview。
(2)不可变序列:tuple、str 和 bytes。
3、列表推导(list comprehension)
原则:只用列表推导创建新的列表,列表推导代码超过两行,考虑用for循环重写。

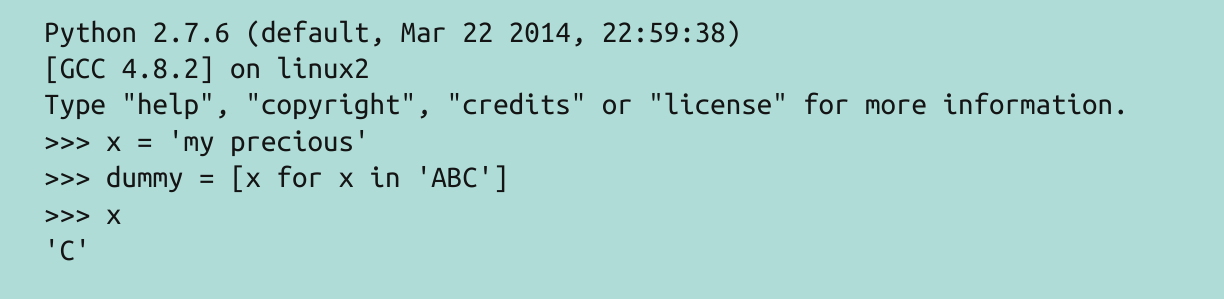
4、列表推导不会再有变量泄露的问题
列表推导在python2和python3中有所不同
python3

5、列表推导同filter和map的比较
filter和map合起来能做的事情,列表推导同样可以做,并且更容易理解,效率上后者并不一定比前者慢。

6、列表推导例子(笛卡尔积)
(1) 这里得到的结果是先以颜色排列,再以尺码排列
(2) 这里两个循环的嵌套关系和上面列表推导中 for 从句的先后顺序一样
(3)如果想依照先尺码后颜色的顺序来排列,只需要调整从句的顺序
(4)列表推导的作用只有一个:生成列表。如果想生成其他类型的序列,生成器表达式就派上了用场

7、生成器表达式
(1)生成器表达式的语法跟列表推导差不多,只不过把方括号换成圆括号而已。
(2) 虽然也可以用列表推导来初始化元组、数组或其他序列类型,但是生成器表达式是更好的
选择。这是因为生成器表达式背后遵守了迭代器协议,可以逐个地产出元素,而不是先建
立一个完整的列表,然后再把这个列表传递到某个构造函数里。前面那种方式显然能够节
省内存。
8、元组
元组不仅可以作为不可变列表,还可以作为没有字段名的记录。
8.1 元组和记录
元组中的元素,不仅记录了数据,还记录了数据的位置,拆包可以让元组完美地被当作记录来使用。
8.1.1 元组拆包
1、元组拆包可以用到任意可迭代对象上
2、用*运算符可把一个可迭代对象拆开作为函数的参数
>>> divmod(20, 8)
(2, 4)
>>> t = (20, 8)
>>> divmod(*t)
3、函数返回时,用元组可以返回多个值
4、用*处理剩下的元素
>>> a, *body, c, d = range(5)
>>> a, body, c, d
(0, [1, 2], 3, 4)
>>> *head, b, c, d = range(5)
>>> head, b, c, d
([0, 1], 2, 3, 4)
5、在 Python 3 之前,元组可以作为形参放在函数声明中,例如 def fn(a, (b,c), d):。然而 Python 3 不再支持这种格式 。
8.1.2 具名元组
有时需要给记录中的字段命名,namedtuple函数可解决这个问题。collections.namedtuple 是一个工厂函数,它可以用来构建一个带字段名的元组和一个有名字的类 。

具名元组的其他属性

8.2 不可变列表
除了记录,元组还可以当作不可变列表。
除了跟增减元素相关的方法外,元组支持列表的所有方法。
8.3 切片
1、对对象进行切片

2、多维切片和省略
[] 运算符里还可以使用以逗号分开的多个索引或者是切片,外部库 NumPy 里就用到了这个特性,二维的 numpy.ndarray 就可以用 a[i, j] 这种形式来获取,抑或是用 a[m:n, k:l]
的方式来得到二维切片。
在 NumPy 中, ... 用作多维数组切片的快捷方式。如果 x 是四维数组,那么 x[i, ...] 就是 x[i, :, :, :] 的缩写。
3、给切片赋值

4、序列的拼接:使用+和*

注意:

例如:

5、序列的增量赋值: += 和 *=
对于可变是象, +=实现了就地加法,对于不可变对象,则会创建一个新对象。

6、一个关于+=的谜题


8.4、排序
list.sort就地排序,返回值None;sorted则会创建一个新的列表作为返回值。两个方法都有两个参数,reverse(True则为降序)和key(只有一个参数的函数)

8.5 用bisect来管理已排序的序列
已排序的序列可以快速用来查找和插入,bisect使用二分查找算法。
bisect模块包含两个主要函数,bisect和insort,两个函数都是利用二分查找算法在有序序列中查找或插入元素。
bisect(haystack, needle) 在 haystack(干草垛)里搜索 needle(针)的位置 。

insort(seq, item) 把变量 item 插入到序列 seq 中,并能保持 seq 的升序顺序
9、可替换列表的数据结构
当要存放100万个float数据时,数组(array)比列表效率要高;当包含操作使用较多时,用集合(set)更适合。
(1)数组
如果只包含数字,array比list更高效,array支持list的所有操作,此外,数组还提供从文件读取和存入文件的更快的方法(.frombytes和.tofile)


从 Python 3.4 开始,数组类型不再支持诸如 list.sort() 这种就地排序方法。要给数组排序的话,得用 sorted 函数新建一个数组:
a = array.array(a.typecode, sorted(a))
想要在不打乱次序的情况下为数组添加新的元素, bisect.insort 还是能派上用场
(2)内存视图(memoryview)
memoryview是一个内置类,它可以在不复制内容的情况下,操作同一个数组的不同切片。
memoryview.cast 的概念跟数组模块类似,能用不同的方式读写同一块内存数据,而且内容字节不会随意移动。

(3)numpy


10、另一种可替代列表的数据结构:队列
使用append和pop方法,可以把列表当作栈或队列来使用,但删除或增加第一个元素的操作很耗时(移动元素)。
collections.deque 类(双向队列)是一个线程安全、可以快速从两端添加或者删除元素的数据类型。而且如果想要有一种数据类型来存放“最近用到的几个元素”, deque 也是一个很好的选择。
新建双向队列时,可以指 定队列的大小,当队列满员时,可以从反向端删除过期元素,然后在尾端添加新的元素。

双向队列从中间删除元素会慢一些,append 和 popleft 都是原子操作,也就说是 deque 可以在多线程程序中安全地当作先进先出的栈使用,而使用者不需要担心资源锁的问题 。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号