
r-cnn学习(二)
faster r-cnn
1、问题
在fast r-cnn中,proposals已经成为速度提高的瓶颈。在本文中,使用深度网络来计算proposals,
使得与检测网络的计算量相比,proposals的计算量可忽略不计。为此,本文提出了RPN网络(Region Proposal Network),
与目标检测网络共享卷积层,大大减少了计算proposals的时间。
2、方案
在fast r-cnn中,region-based detectors可以使用卷积特征图,那么这些特征图也可以用来生成region proposals。
在这些卷积特征上,通过增加两个卷积层来构造RPN:一个将每个位置的卷积图编码成短的特征向量,另一个在每个卷积图的位
置上,输出objectness score和k个region proposals的regression bounds。
因此,本文的RPN可以看作是fully-convolutional network (FCN),对于生成detecting proposals这种任务,是
end-to-end的。为了使RPN和fast r-cnn相统一,我们提出了一个简单的训练框架,在region proposal task和object detection
的微调中依次交替(保持proposals固定)。
小结:设计RPN,利用卷积特征图生成region proposals(而不是selective search等),提升了速度;训练RPN和fast r-cnn(检测网络)
共享卷积层,提高检测速度。

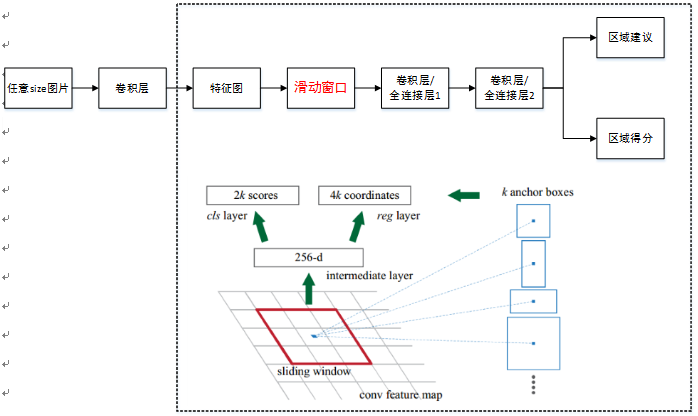
上图为[1]博友给出的faster r-cnn的网络结构图,非常清晰,包括fast r-cnn+RPN网络。原博认为不是
所有卷积层都参与共享。其流程为:
(1)向CNN网络(ZF或VGG-16)中输入任意大小的图片;
(2)经前向传播至最后共享卷积层,一方面成为RPN的输入特征图,另一方面前向传播至特有卷积层,
产生更高维特征;
(3)供RPN输入的特征图经过RPN网络,得到region proposals和objectness scores。对objectness scores采用
非极大值抑制,输出top-N(文中为300)的region proposals 给RoI池化层。
(4)第2步得到的高维特征图和第3步得到的region proposals同时输入RoI池化层,提取对应region proposals的特征
(5)由第4步得到的region proposals特征图输入全连接层,输出cls scores和regressors bounding-box。
3、具体介绍
Region Proposal Networks
RPN的输入为一张图像,输出为一系列的矩形框(proposals),每一个会带有objectness score。本文使用fcn模型来处理
这个过程。因为我们的目标是与fast r-cnn的检测网络共享计算,因此我们假设这些网络共享卷积层。
为了生成region proposals,在最后一个共享卷积层中,我们对其输出滑动使用小的网络。这个网络与n*n的空间窗口(输入为卷积特征图)
全连接。每个滑动窗口被映射为低维的向量,然后将其输入两个独立的全连接层中,一个是回归层,一个是分类层。

这个小网络是以滑窗的方式操作的,因此全连接层共享所有空间位置。
小结:RPN在CNN输入特征图后,增加滑动窗口操作以及两个卷积层完成region proposals。其中第一个卷积层将特征图的每个滑窗位置
编码成一个特征向量;第二个卷积层对应每个滑窗位置输出k个objectness scores和k个回归后region proposals,同时使用非极大值抑制。
上图为[1]给出的PRN网络流程图,其流程为:
(1)套用ImageNet上常用的图像分类网络(ZF或VGG-16),利用这两种网络的部分卷积层产生原始图像的特征图;
(2)对于(1)中的特征图,用3*3的滑窗滑动扫描,通过1映射为低维的特征向量后采用ReLU。每个滑窗位置对应k
个anchors;
(3)将低维特征向量输入两个并行连接的卷积层2,分别用于回归region proposals产生bounding-box和对是否为前景
或背景打分。
Translation-Invariant Anchors
在每个滑窗位置上,同时预测k个proposals和4k个reg相应的输出,以及2k个cls scores(每个proposal为目标/非目标的概率),这k
个proposals相对k个reference boxes,称为anchors。在每个滑动位置上,使用3个scales和3个aspect ratios,共生成9个anchors。对于
一个W*H的特征图,共有W*H*k个anchors,这种方法的好处就是translation invariant。
Anchors:表示RPN网络中对特征图滑窗时每个滑窗位置所对应的原图区域中9种可能的大小。根据图像大小计算滑窗中心点对应原图区域的
中心点,通过中心点和size就可以得到滑窗位置和原图位置的映射关系,由此原图位置并根据与Ground Truth重复率贴上正负标签,让RPN
学习该Anchors是否有物体即可。
A Loss Function for Learning Region Proposals
为了训练RPN,为每个anchor赋一个类别标签(是否是object)。我们为两类anchors赋于正值:(1)anchor与ground_truth box有最大的
IoU重叠;(2)IoU重叠超过0.7。 IoU小于0.3则为negative。损失函数定义如下:
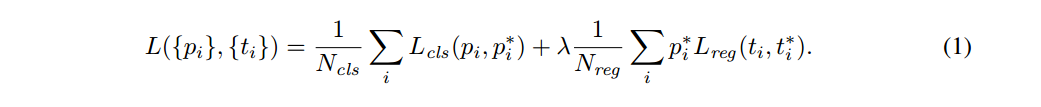
其中i为一个mini batch的一个anchor的索引,pi预测某anchor i是目标的概率,带星号表示相应的标签。
此外,本文采用的bounding-box regression与之前的基于特征图的方式不同。在fast r-cnn中,bounding-box regression是在任意大小的区域上
,经过pool后的特征上进行的,所有大小的区域上的回归权重是共享的。在本文中,用于regression的特征在特征图上有着共同的空间大小。
为了处理不同尺寸,需要学习k个bounding-box regressors,每个regressors对应一个scale和一个aspect ratio,并且k个回归器不共享权重。
bounding-box regression的理解
回归公式如下:

x,y,w,h分别表示窗口中心位置和宽、高。x,xa,x*分别表示预测窗口、anchor窗口和ground truth的坐标,这可以认为是从anchor窗口到ground truth
的bounding-box回归。
Optimization
RPN由FCN实现,可通过end-to-end的BP算法和SGD进行训练。采用image-centric的采样方法训练网络,每个mini-batch从单张图像中获得,包含
正、负anchors。可以将所有的anchors loss放在一起训练,但这样会偏向于负anchors(负类鑫)。本文在一张图上随机采样256个anchors来计算一个
mini-batch的损失函数,正、负anchors的比例为1:1.
Sharing Convolutional Features for Region Proposal and Object Detection
至此我们已经描述了如何训练一个region proposal generation的网络,但没有考虑region-based 的目标检测CNN将利用这些proposals。采用fast r-cnn
的检测网络,接下来将描述一个学习卷积层的算法,这个卷积层被RPN和fast r-cnn共享。
RPN和fast r-cnn的训练时独立的,通过不同的方式来修改它们的卷积层。因此我们需要提出一个技术,考虑在两个网络间共享卷积层,而不是独立的两个网
络。注意这不是仅仅简单定义一个包括RPN和fast r-cnn的网络,然后用BP算法联合优化。原因是fast r-cnn依赖于固定大小的object proposals,这是一个不清楚
的先验,如果学习fast r-cnn同时改变proposals的机制是否收敛。
本文通过交替优化,采用4步训练算法来学习共享特征:
第一步,按照上述方式训练RPN,这个网络由ImageNet预训练模式初始化,对region proposal task采用end-to-end微调。
第二步,使用fast r-cnn训练独立的检测网络,使用第一步中生成的proposals。它的初始化也是用ImageNet预训练模式,此时两个
网络不共享卷积特征。
第三步,使用(2)中微调后的fast r-cnn检测网络重新初始化RPN网络,但固定共享卷积层(学习率为0,不更新),只对RPN进行微调(共享卷积层)。
第四步,保持(3)中共享卷积层固定,由(3)中得到的region proposals微调fast r-cnn中的fc layers,至此形成一个统一的网络,如下图所示。
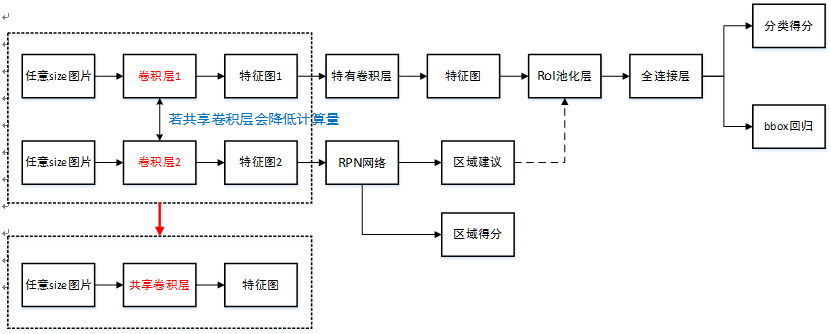
RPN和faster r-cnn联合训练。
Implementation Details
我们训练和测试region proposal和目标检测网络在单一尺度的图像上,re-scale图像让短边为600像素。
网上关于Faster R-CNN中三种尺度解释:
原始尺度:原始输入的大小,不受任何限制,不影响性能;
归一化尺度:输入特征提取网络的大小,在测试时设置,源码中opts.test_scale=600。anchor在这个尺度上设定,
这个参数和anchor的相对大小决定了想要检测的目标范围;
网络输入尺度:输入特征检测网络的大小,在训练时设置,源码中为224×224。
对于anchors,使用3种尺度(128,256,512),以及3种aspect ratios(1:1,1:2,2:1)。
清理anchors数目:
文中提到对于1000×600的一张图像,大约有20000(~60×40×9)个anchors,忽略超出边界的anchors,
剩下6000个anchors,利用非极大值抑制去掉重叠区域,剩2000个region proposals用于训练; 测试时在2000个区域建议中选择
Top-N(文中为300)个region proposals用于Fast R-CNN检测。
文中的三种共享特征网络的训练方式?
(1) 交替训练
训练RPN,得到的region proposals来训练fast r-cnn进行微调;此时网络用来初始化RPN网络,迭代此过程;
(2) 近似联合训练
合并两个网络进行训练。 前向计算的region proposals被固定以训练fast r-cnn;反向计算到共享卷积层时,RPN
网络损失和fast r-cnn网络损失叠加进行优化,但此时把region proposals当作固定值看待,忽视了fast r-cnn一个输入:
region proposals的导数,则无法更新训练,所以称之为近似联合训练。
(3) 联合训练
需要RoI池化层对区域建议可微,需要RoI变形层实现。
参考[1]:http://blog.csdn.net/WoPawn/article/details/52223282
